

Scopri di più sulla NetApp Data Classification
 Suggerisci modifiche
Suggerisci modifiche
NetApp Data Classification è un servizio di governance dei dati per NetApp Console che analizza le fonti di dati aziendali on-premise e cloud per mappare e classificare i dati e identificare le informazioni private. Ciò può contribuire a ridurre i rischi per la sicurezza e la conformità, a diminuire i costi di archiviazione e ad agevolare i progetti di migrazione dei dati.

|
A partire dalla versione 1.31, la classificazione dei dati è disponibile come funzionalità principale nella NetApp Console. Non ci sono costi aggiuntivi. Non è richiesta alcuna licenza o abbonamento di classificazione. + Se hai utilizzato la versione legacy 1.30 o una versione precedente, tale versione sarà disponibile fino alla scadenza dell'abbonamento. |
NetApp Console
La classificazione dei dati è accessibile tramite la NetApp Console.
NetApp Console offre una gestione centralizzata dei servizi di storage e dati NetApp in ambienti on-premise e cloud di livello aziendale. La console è necessaria per accedere e utilizzare i servizi dati NetApp . In quanto interfaccia di gestione, consente di gestire numerose risorse di archiviazione da un'unica interfaccia. Gli amministratori della console possono controllare l'accesso allo storage e ai servizi per tutti i sistemi all'interno dell'azienda.
Per iniziare a utilizzare NetApp Console non è necessaria una licenza o un abbonamento e verranno addebitati costi solo quando sarà necessario distribuire gli agenti della console nel cloud per garantire la connettività ai sistemi di storage o ai servizi dati NetApp . Tuttavia, alcuni servizi dati NetApp accessibili dalla Console sono concessi in licenza o basati su abbonamento.
Scopri di più su"NetApp Console" .
Caratteristiche
La classificazione dei dati utilizza l'intelligenza artificiale (IA), l'elaborazione del linguaggio naturale (NLP) e l'apprendimento automatico (ML) per comprendere il contenuto che analizza, al fine di estrarre entità e categorizzare il contenuto di conseguenza. Ciò consente alla classificazione dei dati di fornire le seguenti aree di funzionalità.
Data Classification fornisce diversi strumenti che possono aiutarti a raggiungere la conformità. È possibile utilizzare la classificazione dei dati per:
-
Identificare le informazioni personali identificabili (PII).
-
Identificare un'ampia gamma di informazioni personali sensibili come richiesto dalle normative sulla privacy GDPR, CCPA, PCI e HIPAA.
-
Rispondere alle richieste di accesso ai dati personali (DSAR) in base al nome o all'indirizzo e-mail.
La classificazione dei dati può identificare i dati potenzialmente a rischio di accesso per scopi criminali. È possibile utilizzare la classificazione dei dati per:
-
Identifica tutti i file e le directory (condivisioni e cartelle) con autorizzazioni aperte che sono accessibili all'intera organizzazione o al pubblico.
-
Identificare i dati sensibili che risiedono al di fuori della posizione iniziale dedicata.
-
Rispettare le policy di conservazione dei dati.
-
Utilizzare Policies per rilevare automaticamente nuovi problemi di sicurezza, in modo che il personale addetto alla sicurezza possa intervenire immediatamente.
La classificazione dei dati fornisce strumenti che possono aiutarti a ridurre il costo totale di proprietà (TCO) del tuo storage. È possibile utilizzare la classificazione dei dati per:
-
Aumenta l'efficienza di archiviazione identificando i dati duplicati o non correlati all'attività aziendale.
-
Risparmia sui costi di archiviazione identificando i dati inattivi che puoi spostare in un archivio di oggetti meno costoso. "Scopri di più sulla suddivisione in livelli dai sistemi Cloud Volumes ONTAP" . "Scopri di più sulla suddivisione in livelli dai sistemi ONTAP locali" .
Sistemi supportati e fonti di dati
La classificazione dei dati può analizzare e scansionare dati strutturati e non strutturati provenienti dai seguenti tipi di sistemi e fonti di dati:
Sistemi
-
Gestione Amazon FSx for NetApp ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP (distribuito in AWS, Azure o GCP)
-
Google Cloud NetApp Volumes
-
Cluster ONTAP on-premise
-
StorageGRID
Fonti dei dati
-
Condivisioni file NetApp
-
Banche dati:
-
Servizio di database relazionale Amazon (Amazon RDS)
-
MongoDB
-
MySQL
-
Oracolo
-
PostgreSQL
-
SAP HANA
-
SQL Server (MSSQL)
-
Data Classification supporta le versioni NFS 3.x, 4.0 e 4.1 e le versioni CIFS 1.x, 2.0, 2.1 e 3.0.
Costo
L'utilizzo della classificazione dei dati è gratuito. Non è richiesta alcuna licenza di classificazione o abbonamento a pagamento.
Costi delle infrastrutture
-
L'installazione di Data Classification nel cloud richiede la distribuzione di un'istanza cloud, che comporta l'addebito di costi da parte del provider cloud presso cui viene distribuita. Vedere il tipo di istanza distribuita per ciascun provider cloud . Non ci sono costi se si installa Data Classification su un sistema locale.
-
Per la classificazione dei dati è necessario aver distribuito un agente Console. In molti casi si dispone già di un agente Console perché si utilizzano altri servizi e risorse di archiviazione nella Console. L'istanza dell'agente Console comporta addebiti da parte del provider cloud presso cui è distribuita. Vedi il "tipo di istanza distribuita per ciascun provider cloud" . Non ci sono costi se si installa l'agente Console su un sistema locale.
Costi di trasferimento dati
I costi di trasferimento dati dipendono dalla configurazione. Se l'istanza di Data Classification e l'origine dati si trovano nella stessa zona di disponibilità e regione, non vi sono costi di trasferimento dati. Tuttavia, se la fonte dei dati, ad esempio un sistema Cloud Volumes ONTAP , si trova in una zona di disponibilità o regione diversa, il tuo provider cloud ti addebiterà i costi di trasferimento dei dati. Per maggiori dettagli consultare questi link:
L'istanza di classificazione dei dati
Quando si distribuisce Data Classification nel cloud, la Console distribuisce l'istanza nella stessa subnet dell'agente della Console. "Scopri di più sull'agente Console."
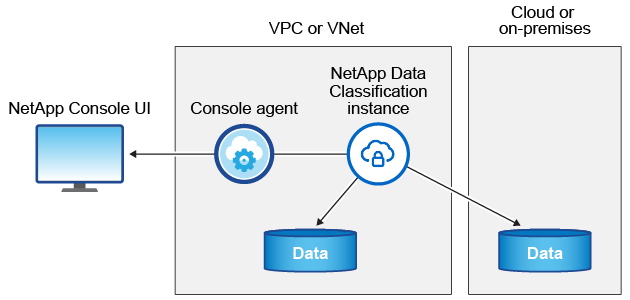
Si noti quanto segue riguardo all'istanza predefinita:
-
In AWS, Data Classification viene eseguito su un "istanza m6i.4xlarge" con un disco GP2 da 500 GiB. L'immagine del sistema operativo è Amazon Linux 2.
-
In Azure, la classificazione dei dati viene eseguita su un"Standard_D16s_v3 VM" con un disco da 500 GiB. L'immagine del sistema operativo è Ubuntu 22.04.
-
In GCP, la classificazione dei dati viene eseguita su un"VM n2-standard-16" con un disco persistente Standard da 500 GiB. L'immagine del sistema operativo è Ubuntu 22.04.
-
Nelle regioni in cui l'istanza predefinita non è disponibile, Data Classification viene eseguito su un'istanza alternativa. "Vedi i tipi di istanza alternativi" .
-
L'istanza è denominata CloudCompliance con un hash generato (UUID) concatenato ad essa. Ad esempio: CloudCompliance-16bb6564-38ad-4080-9a92-36f5fd2f71c7
-
Per ogni agente console viene distribuita una sola istanza di classificazione dei dati.
Puoi anche distribuire Data Classification su un host Linux nella tua sede o su un host del tuo provider cloud preferito. Il software funziona esattamente allo stesso modo, indipendentemente dal metodo di installazione scelto. Gli aggiornamenti del software di classificazione dei dati sono automatizzati finché l'istanza ha accesso a Internet.

|
L'istanza deve rimanere sempre in esecuzione perché la classificazione dei dati esegue continuamente la scansione dei dati. |
Distribuisci su diversi tipi di istanza
Esaminare le seguenti specifiche per i tipi di istanza:
| Dimensioni del sistema | Specifiche | Limitazioni |
|---|---|---|
Extra Large |
32 CPU, 128 GB di RAM, 1 TiB SSD |
Può scansionare fino a 500 milioni di file. |
Grande (predefinito) |
16 CPU, 64 GB di RAM, SSD da 500 GiB |
Può scansionare fino a 250 milioni di file. |
Come funziona la scansione della classificazione dei dati
Ad alto livello, la scansione della classificazione dei dati funziona in questo modo:
-
Distribuisci un'istanza di Data Classification nella Console.
-
È possibile abilitare le scansioni su una o più origini dati.
-
La classificazione dei dati analizza i dati utilizzando un processo di apprendimento basato sull'intelligenza artificiale.
-
Puoi utilizzare i dashboard e gli strumenti di reporting forniti per aiutarti nei tuoi sforzi di conformità e governance.
Dopo aver abilitato la classificazione dei dati e selezionato i repository che si desidera analizzare (volumi, schemi di database o altri dati utente), la scansione dei dati inizia immediatamente per identificare i dati personali e sensibili. Nella maggior parte dei casi, dovresti concentrarti sulla scansione dei dati di produzione in tempo reale anziché su backup, mirror o siti DR. Quindi Data Classification mappa i dati della tua organizzazione, categorizza ogni file e identifica ed estrae entità e modelli predefiniti nei dati. Il risultato della scansione è un indice di informazioni personali, informazioni personali sensibili, categorie di dati e tipi di file.
Data Classification si connette ai dati come qualsiasi altro client montando volumi NFS e CIFS. Ai volumi NFS si accede automaticamente in sola lettura, mentre per analizzare i volumi CIFS è necessario fornire le credenziali di Active Directory.
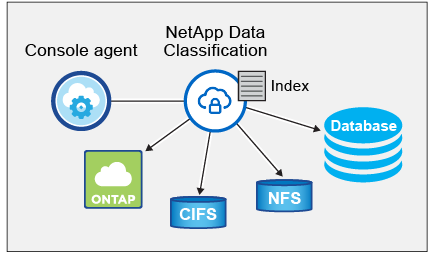
Dopo la scansione iniziale, Data Classification analizza continuamente i dati in modalità round-robin per rilevare modifiche incrementali. Ecco perché è importante mantenere l'istanza in esecuzione.
È possibile abilitare e disabilitare le scansioni a livello di volume o a livello di schema del database.

|
La classificazione dei dati non impone limiti alla quantità di dati che può analizzare. Ogni agente della console supporta la scansione e la visualizzazione di 500 TiB di dati. Per scansionare più di 500 TiB di dati,"installare un altro agente Console" Poi"distribuire un'altra istanza di classificazione dei dati" . + L'interfaccia utente della console visualizza i dati da un singolo connettore. Per suggerimenti sulla visualizzazione dei dati da più agenti della console, vedere"Lavora con più agenti della console" . |
Mappatura e scansioni complete
È possibile eseguire due tipi di scansioni nella classificazione dei dati:
-
Le scansioni di sola mappatura forniscono solo una panoramica high-level dei dati e vengono eseguite su fonti di dati selezionate. Le scansioni di sola mappatura richiedono meno tempo rispetto alle scansioni complete perché non accedono ai file per visualizzarne i dati. Potrebbe essere utile eseguirle inizialmente per identificare aree di ricerca e poi effettuare una scansione completa su tali aree.
-
Le scansioni complete offrono un'analisi approfondita dei tuoi dati. Una scansione completa include una scansione di sola mappatura e una classificazione dei dati all'interno dei file.
Per una ripartizione delle differenze tra scansioni solo mappa e scansioni complete, vedere "Qual è la differenza tra le scansioni di mappatura e di classificazione?".
Informazioni che la classificazione dei dati categorizza
La classificazione dei dati raccoglie, indicizza e assegna categorie ai seguenti dati:
-
Metadati standard sui file: tipo di file, dimensioni, date di creazione e modifica, ecc.
-
Dati personali: informazioni di identificazione personale (PII), come indirizzi e-mail, numeri di identificazione o numeri di carte di credito, che Data Classification identifica utilizzando parole, stringhe e modelli specifici nei file. "Scopri di più sui dati personali" .
-
Dati personali sensibili: tipologie particolari di informazioni personali sensibili (SPII), come dati sanitari, origine etnica o opinioni politiche, come definito dal Regolamento generale sulla protezione dei dati (GDPR) e da altre normative sulla privacy. "Scopri di più sui dati personali sensibili" .
-
Categorie: la classificazione dei dati prende i dati scansionati e li divide in diversi tipi di categorie. Le categorie sono argomenti basati sull'analisi AI del contenuto e dei metadati di ciascun file. "Scopri di più sulle categorie".
-
Riconoscimento dell'entità del nome: la classificazione dei dati utilizza l'intelligenza artificiale per estrarre i nomi naturali delle persone dai documenti. "Scopri come rispondere alle richieste di accesso ai dati personali" .
Panoramica della rete
Data Classification distribuisce un singolo server, o cluster, ovunque tu scelga: nel cloud o in sede. I server si connettono tramite protocolli standard alle fonti dati e indicizzano i risultati in un cluster Elasticsearch, anch'esso distribuito sugli stessi server. Ciò consente il supporto per ambienti multi-cloud, cross-cloud, cloud privati e on-premise.
La Console distribuisce l'istanza di classificazione dei dati con un gruppo di sicurezza che abilita le connessioni HTTP in entrata dall'agente della Console.
Quando si utilizza la Console in modalità SaaS, la connessione alla Console viene fornita tramite HTTPS e i dati privati inviati tra il browser e l'istanza di Data Classification sono protetti tramite crittografia end-to-end tramite TLS 1.2, il che significa che NetApp e terze parti non possono leggerli.
Le regole in uscita sono completamente aperte. Per installare e aggiornare il software di classificazione dei dati e per inviare le metriche di utilizzo è necessario l'accesso a Internet.
Se hai requisiti di rete rigorosi,"Scopri gli endpoint contattati da Data Classification" .