

Creare un piano di replica in NetApp Disaster Recovery
 Suggerisci modifiche
Suggerisci modifiche
Dopo aver aggiunto risorse e siti, crea un piano di replica per gestire la protezione dei dati. La creazione del piano di replica comporta la designazione dei siti di origine e di destinazione, la selezione dei gruppi di risorse e la scelta di come ripristinare e accendere le applicazioni. Ad esempio, potresti raggruppare le macchine virtuali (VM) associate a un'applicazione o raggruppare le applicazioni che hanno tier simili.
Quando crei un piano di replica, puoi anche modificare le pianificazioni per la conformità e i test, eseguendo failover di prova senza influire sui dati di produzione.
Ruolo della console NetApp richiesto Per eseguire questa attività è necessario il ruolo di Super amministratore, Amministratore del ripristino di emergenza, Amministratore del failover del ripristino di emergenza o Amministratore dell'applicazione di ripristino di emergenza. "Scopri di più sui ruoli utente e sulle autorizzazioni in NetApp Disaster Recovery". "Scopri di più sui ruoli di accesso NetApp Console per tutti i servizi".
Informazioni sui piani di replica
È possibile proteggere più VM su più datastore. NetApp Disaster Recovery crea gruppi di coerenza ONTAP per tutti i volumi ONTAP che ospitano datastore VM protetti.
È possibile abilitare la protezione solo se il piano di replica si trova in uno dei seguenti stati:
-
Pronto
-
Failback eseguito
-
Test failover eseguito
Snapshot del piano di replica
Disaster Recovery mantiene lo stesso numero di snapshot sui cluster di origine e di destinazione. Per impostazione predefinita, il servizio esegue un processo di riconciliazione degli snapshot ogni 24 ore per garantire che il numero di snapshot sui cluster di origine e di destinazione sia lo stesso.
Le seguenti situazioni possono causare una differenza nel numero di snapshot tra i cluster di origine e di destinazione:
-
In alcune situazioni, le operazioni ONTAP esterne al Disaster Recovery possono aggiungere o rimuovere snapshot dal volume:
-
Se mancano snapshot sul sito di origine, gli snapshot corrispondenti sul sito di destinazione potrebbero essere eliminati, a seconda del criterio SnapMirror predefinito per la relazione.
-
Se mancano snapshot sul sito di destinazione, il servizio potrebbe eliminare gli snapshot corrispondenti sul sito di origine durante il successivo processo di riconciliazione degli snapshot pianificato, a seconda del criterio SnapMirror predefinito per la relazione.
-
-
Una riduzione del numero di snapshot conservati nel piano di replica può far sì che il servizio elimini gli snapshot più vecchi sia sul sito di origine che su quello di destinazione per soddisfare il numero di snapshot di conservazione appena ridotto.
In questi casi, Disaster Recovery rimuove gli snapshot più vecchi dai cluster di origine e di destinazione al successivo controllo di coerenza. In alternativa, l'amministratore può eseguire una pulizia immediata dello snapshot selezionando Azioni*![]() sull'icona del piano di replica e selezionando *Pulisci snapshot.
sull'icona del piano di replica e selezionando *Pulisci snapshot.
Disaster Recovery esegue controlli di simmetria degli snapshot ogni 24 ore.
Prima di iniziare
-
Prima di creare una relazione SnapMirror , configurare il cluster e il peering SVM al di fuori del Disaster Recovery.
-
Se configuri le mappature di rete a livello di vCenter, Disaster Recovery riconosce queste mappature quando crei il piano di replica. Se modifichi o aggiungi la mappatura di rete a livello di vCenter dopo aver creato il piano di replica, Disaster Recovery riconosce queste mappature quando modifichi manualmente il piano di replica.
-
Con Google Cloud, puoi aggiungere un solo volume o datastore a un piano di replica.

|
Organizza le tue VM o i cluster Kubernetes prima di implementare NetApp Disaster Recovery per ridurre al minimo la proliferazione. Posiziona le risorse che necessitano di protezione su un sottoinsieme di datastore e le risorse che non devono essere protette su un sottoinsieme diverso di datastore. Per organizzare i gruppi di risorse prima di creare il piano di replica, consulta "Crea un gruppo di risorse". |
Creare il piano di replicazione
Una procedura guidata ti guiderà attraverso questi passaggi:
-
Selezionare i server vCenter.
-
Seleziona le risorse (VM, datastore, namespace) che desideri replicare e assegna i gruppi di risorse.
-
Illustra il modo in cui le risorse dall'ambiente di origine vengono mappate alla destinazione.
-
Imposta la frequenza di esecuzione del piano, esegui uno script ospitato da guest, imposta l'ordine di avvio e seleziona l'obiettivo del punto di ripristino.
-
Rivedi il piano.
Quando create il piano, seguite queste linee guida:
-
Utilizza le stesse credenziali per tutte le VM o i cluster Kubernetes inclusi nel piano.
-
Utilizza lo stesso script per tutte le macchine virtuali o i cluster Kubernetes inclusi nel piano.
-
Utilizza la stessa sottorete, DNS e gateway per tutte le macchine virtuali o i cluster Kubernetes inclusi nel piano.
Seleziona i server vCenter
Per prima cosa, seleziona il vCenter di origine e poi quello di destinazione.
-
Dal menu di navigazione a sinistra NetApp Console , selezionare Protezione > Disaster recovery.
-
Dal menu NetApp Disaster Recovery , selezionare Piani di replica.
-
Nel menu a tendina, scegli il tipo di risorsa per cui desideri creare un piano di replica: Kubernetes o vCenter.
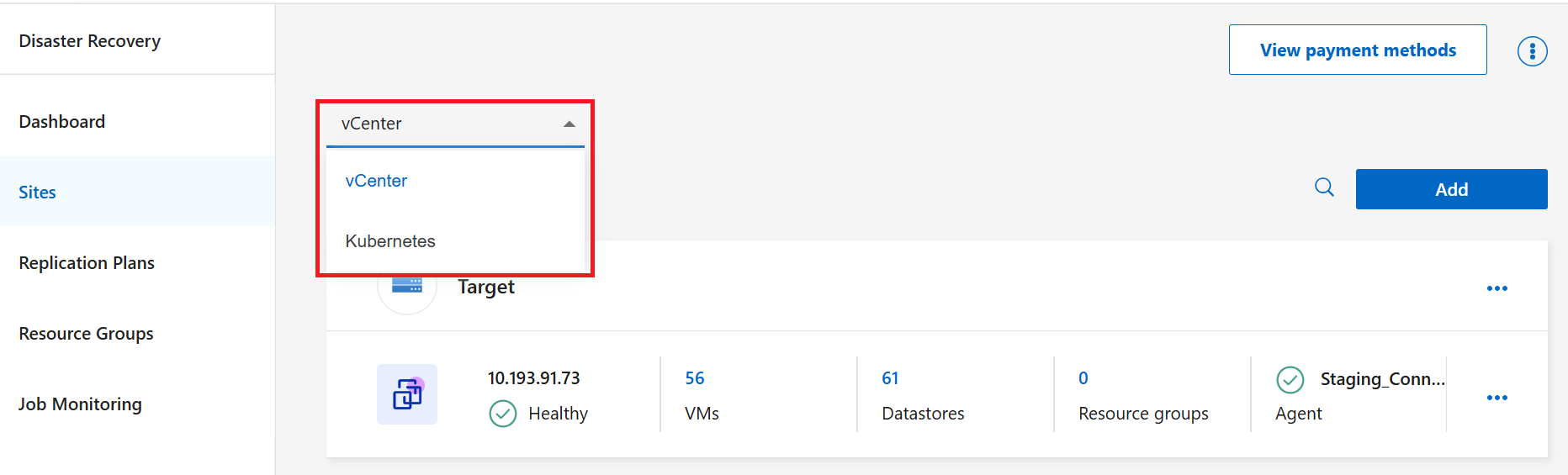
-
Selezionare Aggiungi.
-
Inserisci un nome per il piano di replica.
-
Per Origine, selezionare il vCenter o il cluster Kubernetes da designare come origine.
-
In Origine vCenter, seleziona il vCenter in cui si trovano i dati dal menu a tendina. In Destinazione, seleziona il vCenter o il cluster Kubernetes da utilizzare come destinazione per il disaster recovery.
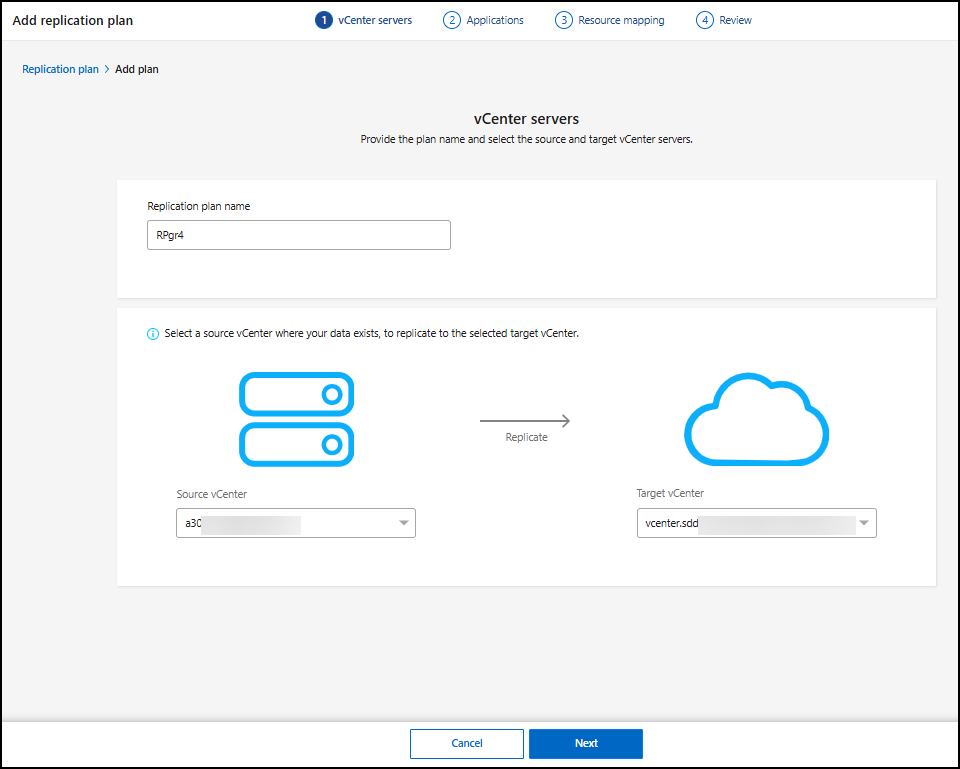
-
Selezionare Avanti.
Selezionare le applicazioni da replicare e assegnare gruppi di risorse
Il passo successivo consiste nel raggruppare le VM, i datastore o i cluster Kubernetes necessari in gruppi di risorse funzionali. I gruppi di risorse consentono di proteggere un insieme di risorse, come un cluster Kubernetes o una VM, con uno snapshot comune.
Quando si creano gruppi di risorse, tenere presente i seguenti aspetti:
-
Prima di aggiungere risorse ai gruppi di risorse, avvia prima una discovery manuale o una discovery pianificata. In questo modo si garantisce che le risorse vengano individuate e visualizzate nel gruppo di risorse.
-
Assicurati che sia presente almeno una macchina virtuale (VM) nel datastore. Se non sono presenti VM nel datastore, il datastore non verrà rilevato.
-
Un singolo datastore non dovrebbe ospitare VM protette da più di un piano di replica.
-
Non ospitare risorse protette e non protette sullo stesso datastore. Se risorse protette e non protette sono ospitate sullo stesso datastore, potrebbero verificarsi i seguenti problemi:
-
La capacità utilizzata di quel volume può contribuire al calcolo della licenza perché il Disaster Recovery utilizza SnapMirror, il che significa che il sistema replica interi volumi ONTAP. In questo caso, lo spazio del volume occupato sia dalle risorse protette che da quelle non protette verrebbe incluso in questo calcolo.
-
Se il gruppo di risorse e le risorse associate devono essere trasferite al sito di ripristino di emergenza, tutte le risorse non protette non saranno più presenti nel sito di origine a seguito del processo di failover, con conseguente interruzione del servizio per tali risorse non protette nel sito di origine. Inoltre, NetApp Disaster Recovery non avvierà tali risorse non protette nel sito di failover.
-
|
|
Crea un set separato di mappature dedicate per i tuoi test di failover, in modo da impedire che le risorse vengano connesse alle reti di produzione utilizzando gli stessi indirizzi IP. |
-
Se disponi già di gruppi di risorse, seleziona Resource groups, scegli il gruppo di risorse e poi Next.
Se non si dispone di gruppi di risorse esistenti o è necessario aggiungere risorse a uno, selezionare Macchine virtuali o Archivi dati.
-
Seleziona le macchine virtuali o i datastore che desideri aggiungere al piano di replica dall'elenco generato automaticamente. Per le macchine virtuali, puoi filtrare per datastore. Quando selezioni un datastore o una macchina virtuale, viene aggiunto automaticamente a un gruppo di risorse.
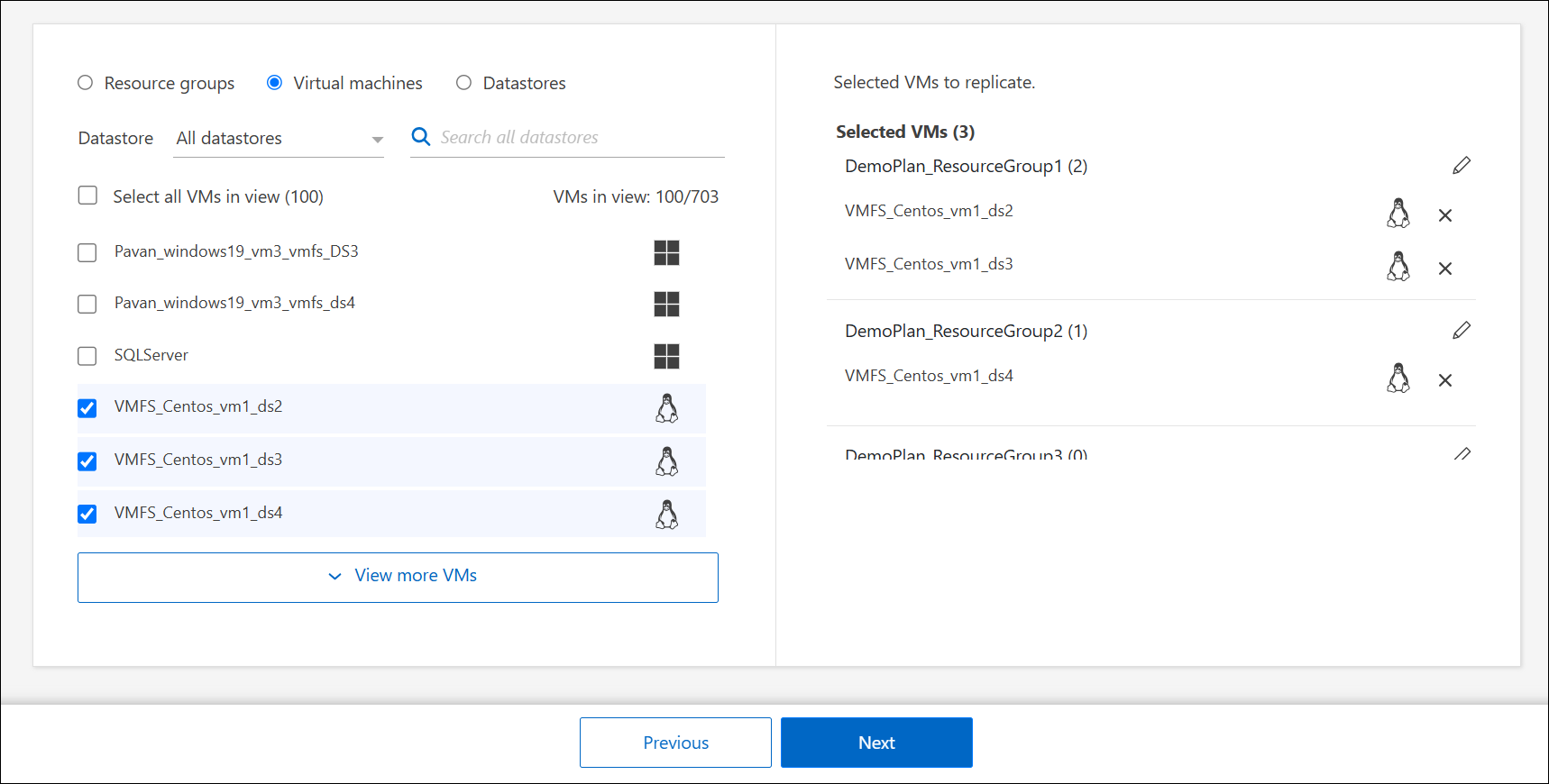
-
Nella metà destra della pagina, rivedere le macchine virtuali o i datastore selezionati.
-
Per rimuovere una VM o un datastore, posiziona il puntatore del mouse sul nome della data source e seleziona X.
-
Per organizzare le risorse in più gruppi di risorse, seleziona Fai clic per aggiungere un altro gruppo di risorse. Dopo aver aggiunto il gruppo di risorse, puoi trascinare e rilasciare le risorse tra i gruppi. Seleziona l'icona della matita* per modificare il nome del gruppo di risorse.
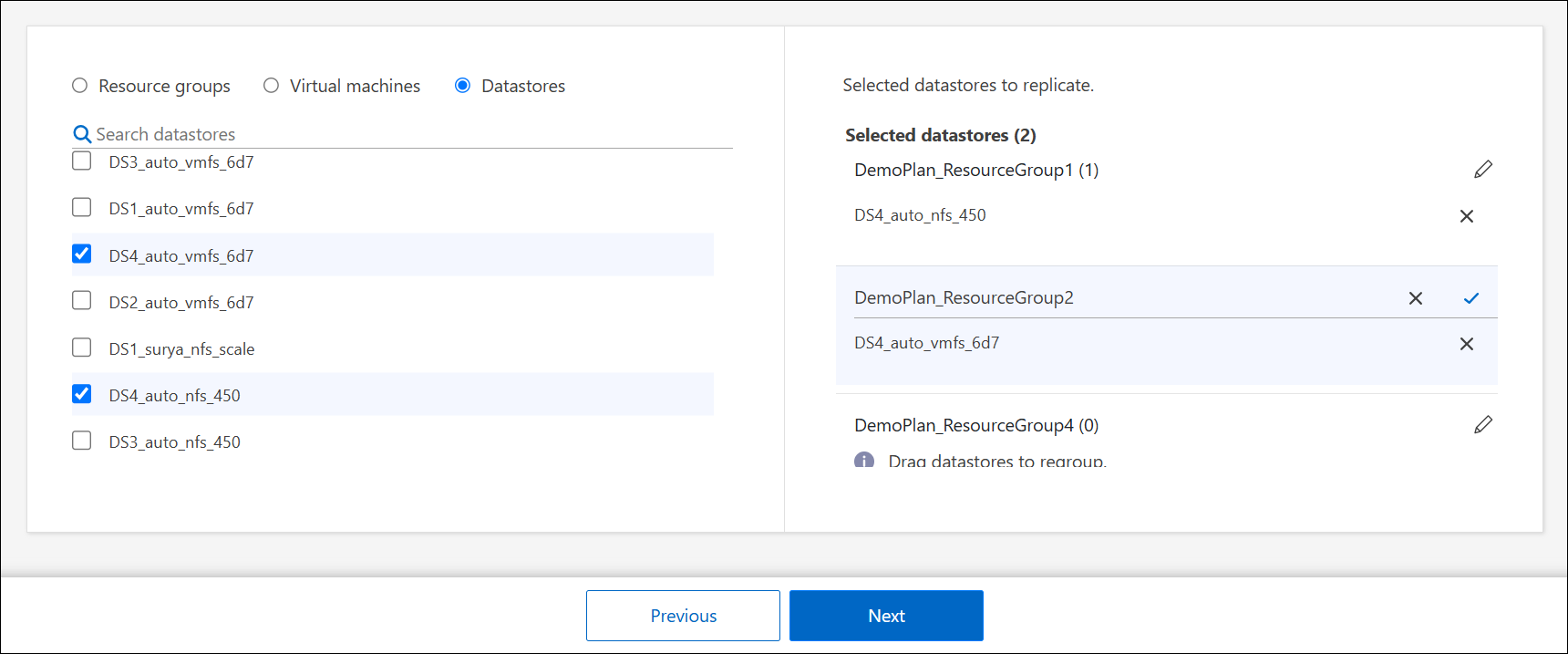
-
-
Selezionare Avanti.
Quando si crea un piano di replica per i cluster Kubernetes, gli spazi dei nomi Kubernetes in un gruppo di risorse devono appartenere allo stesso cluster ONTAP.
-
Se disponi già di gruppi di risorse, seleziona i gruppi dall'elenco.
Se non disponi di gruppi di risorse esistenti o devi aggiungere risorse a uno, seleziona + Crea nuovo gruppo di risorse. Segui le istruzioni per "aggiungere spazi dei nomi a un gruppo di risorse".
Quando si assegna un nome a un gruppo di risorse, gli unici caratteri supportati sono lettere minuscole e numeri.
-
Nella colonna alternata, esaminare i gruppi di risorse selezionati.
-
Seleziona Avanti.
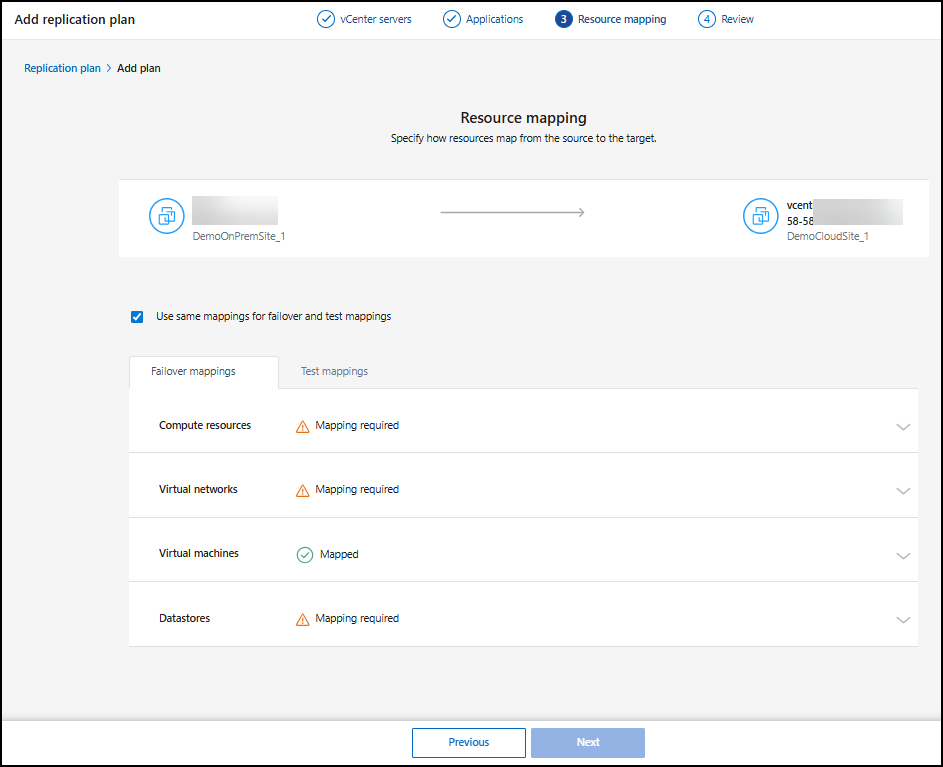
Mappare le risorse di origine sulla destinazione
Nella fase di mappatura delle risorse, specificare in che modo le risorse dall'ambiente di origine devono essere mappate alla destinazione. Quando si crea un piano di replica, è possibile impostare un ritardo e un ordine di avvio per ogni macchina virtuale nel piano. Ciò consente di impostare una sequenza per l'avvio delle VM.
Se si prevede di eseguire failover di prova come parte del piano di ripristino di emergenza, è necessario fornire un set di mapping di failover di prova per garantire che le VM avviate durante il test di failover non interferiscano con le VM di produzione. È possibile ottenere questo risultato fornendo alle VM di prova indirizzi IP diversi oppure mappando le schede di rete virtuali delle VM di prova a una rete diversa, isolata dalla produzione ma con la stessa configurazione IP (denominata bubble o rete di prova).
Se si desidera creare una relazione SnapMirror in questo servizio, il cluster e il relativo peering SVM devono essere già stati configurati al di fuori di NetApp Disaster Recovery.
-
Nella pagina Mappatura risorse, seleziona la casella per utilizzare le stesse mappature sia per le operazioni di failover che per quelle di test.
-
Nella scheda Mapping failover, seleziona la freccia rivolta verso il basso a destra di ogni risorsa e mappa le risorse in ogni sezione:
-
Risorse di calcolo
-
Reti virtuali
-
Macchine virtuali
-
Datastore
-
-
Scegli le mappature degli spazi dei nomi per ogni spazio dei nomi in ogni gruppo di risorse. Per impostazione predefinita, Disaster Recovery seleziona come destinazione lo stesso dell'origine. Puoi scegliere uno spazio dei nomi diverso nel cluster di destinazione.
-
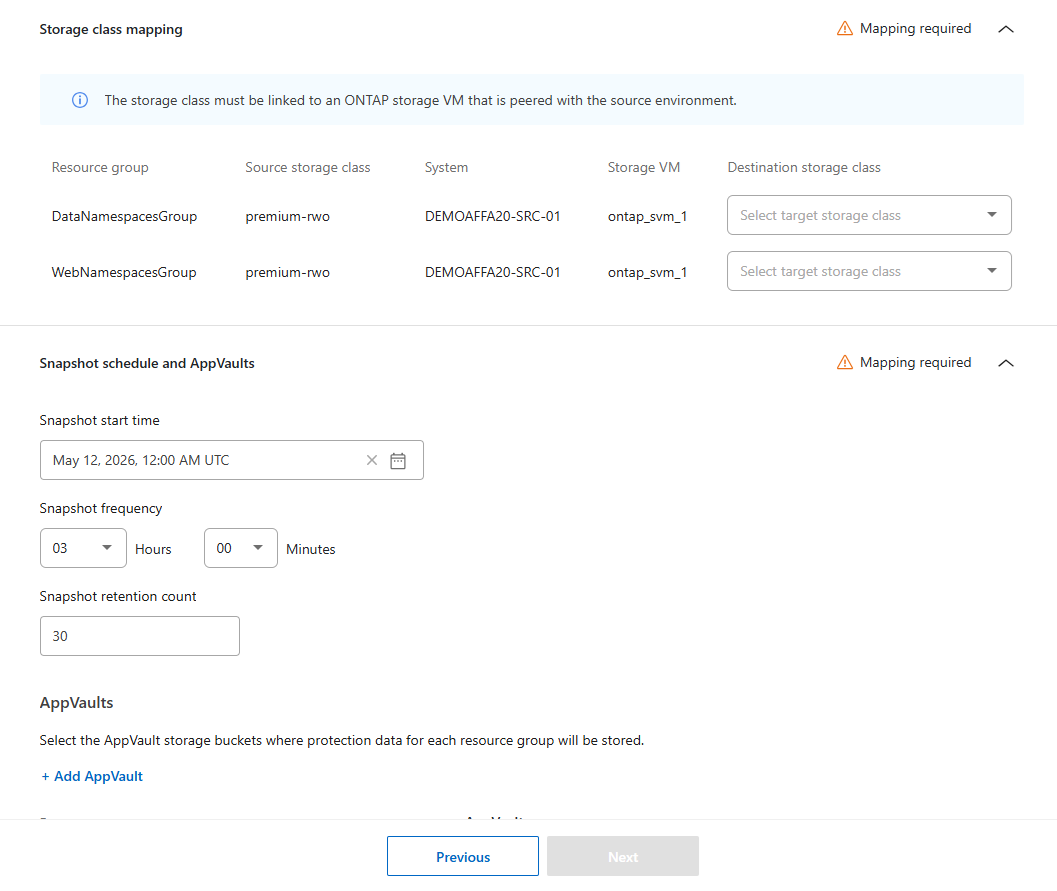
Specificare la mappatura della classe di archiviazione per ciascun gruppo di risorse. La classe di archiviazione deve essere collegata a una storage VM ONTAP connessa tramite peering all'ambiente di origine. La classe di archiviazione predefinita sul cluster viene utilizzata se non se ne specifica una.
Eseguire il comando CLI kubectl get pvc -n <namespace>sul namespace per visualizzare la storage class. -
Imposta la pianificazione degli snapshot:
Scegli l’Ora di inizio degli Snapshot e della conservazione (data e ora del calendario), la Frequenza degli Snapshot e della conservazione (con quale frequenza vengono avviati gli snapshot) e il Numero di Snapshot da conservare (quanti snapshot vengono salvati).
Quando si imposta la frequenza degli snapshot, il minimo consentito è di cinque minuti.
-
Seleziona Aggiungi AppVault per creare la AppVault in cui verranno salvati i dati di protezione.
-
Inserisci un Nome e seleziona l'agente della console a cui deve essere connesso AppVault.
-
Seleziona il cloud Provider per l'hosting del AppVault.
-
In base alla selezione del provider, Disaster Recovery popola gli abbonamenti cloud configurati in precedenza. Scegli Subscription, Resource group e Storage account per il cloud provider.
-
Seleziona Aggiungi.
-
-
Seleziona Avanti.
-
Esamina le mappature di failover, quindi seleziona Aggiungi per creare il piano di replica.
Dopo aver selezionato Aggiungi, è possibile monitorare i diversi job in Job monitoring.

|
Per Kubernetes, questo è il passaggio finale per la creazione di una replica. Per vCenters, continuare con Sezione risorse di calcolo. |
Sezione risorse di calcolo
La sezione Risorse di calcolo definisce dove verranno ripristinate le VM dopo un failover. Mappare il data center e il cluster vCenter di origine su un data center e un cluster di destinazione.
Facoltativamente, le VM possono essere riavviate su uno specifico host vCenter ESXi. Se VMWare DRS è abilitato, è possibile spostare automaticamente la VM su un host alternativo, se necessario, per soddisfare i criteri DR configurati.
Facoltativamente, è possibile posizionare tutte le VM in questo piano di replica in una cartella univoca con vCenter. Ciò fornisce un modo semplice per organizzare rapidamente le VM sottoposte a failover all'interno di vCenter.
Selezionare la freccia rivolta verso il basso accanto a Risorse di calcolo.
-
Data center di origine e di destinazione
-
Cluster di destinazione
-
Host di destinazione (facoltativo): dopo aver selezionato il cluster, è possibile impostare queste informazioni.
-
Cartella (facoltativa)
|
|
Se un vCenter dispone di un Distributed Resource Scheduler (DRS) configurato per gestire più host in un cluster, non è necessario selezionare un host. Se selezioni un host, NetApp Disaster Recovery posizionerà tutte le VM sull'host selezionato. * Cartella VM di destinazione (facoltativa): crea una nuova cartella radice per archiviare le VM selezionate. |
Reti virtuali
Le VM utilizzano schede di rete virtuali connesse a reti virtuali. Nel processo di failover, il servizio collega queste schede di rete virtuali alle reti virtuali definite nell'ambiente VMware di destinazione. Per ogni rete virtuale di origine utilizzata dalle VM nel gruppo di risorse, il servizio richiede l'assegnazione di una rete virtuale di destinazione.
|
|
Questa sezione è richiesta solo per vCenters. Non è necessario completarla per Kubernetes. |
|
|
È possibile assegnare più reti virtuali di origine alla stessa rete virtuale di destinazione. Ciò potrebbe tuttavia creare conflitti nella configurazione della rete IP. È possibile mappare più reti di origine su una singola rete di destinazione per garantire che tutte le reti di origine abbiano la stessa configurazione. |
Nella scheda Mapping failover, seleziona la freccia rivolta verso il basso accanto a Reti virtuali. Selezionare la LAN virtuale di origine e la LAN virtuale di destinazione.
Selezionare la mappatura di rete sulla LAN virtuale appropriata. Le LAN virtuali dovrebbero essere già predisposte, quindi selezionare la LAN virtuale appropriata per mappare la VM.
Macchine virtuali
È possibile configurare ciascuna VM nel gruppo di risorse protetto dal piano di replica in modo che si adatti all'ambiente virtuale vCenter di destinazione impostando una delle seguenti opzioni:
-
Il numero di CPU virtuali
-
La quantità di DRAM virtuale
-
La configurazione dell'indirizzo IP
-
La possibilità di eseguire script shell del sistema operativo guest come parte del processo di failover
-
La possibilità di modificare i nomi delle VM sottoposte a failover utilizzando un prefisso e un suffisso univoci
-
La possibilità di impostare l'ordine di riavvio durante il failover della VM
Nella scheda Mapping failover, seleziona la freccia rivolta verso il basso accanto a Macchine virtuali.
L'impostazione predefinita per le VM è mappata. La mappatura predefinita utilizza le stesse impostazioni utilizzate dalle VM nell'ambiente di produzione (stesso indirizzo IP, subnet mask e gateway).
Se si apportano modifiche alle impostazioni predefinite, è necessario modificare il campo IP di destinazione in "Diverso dall'origine".
|
|
Se modifichi le impostazioni in "Diverso dall'origine", devi fornire le credenziali del sistema operativo guest della VM. |
Questa sezione potrebbe visualizzare campi diversi a seconda della selezione effettuata.
È possibile aumentare o diminuire il numero di CPU virtuali assegnate a ciascuna VM sottoposta a failover. Tuttavia, ogni VM richiede almeno una CPU virtuale. È possibile modificare il numero di CPU virtuali e di DRAM virtuale assegnate a ciascuna VM. Il motivo più comune per cui potresti voler modificare le impostazioni predefinite della CPU virtuale e della DRAM virtuale è se i nodi del cluster vCenter di destinazione non dispongono di tante risorse disponibili quanto il cluster vCenter di origine.
|
|
Attiva le impostazioni avanzate per aggiungere le impostazioni Scripts e coerente con l'applicazione. |
Impostazioni di rete Disaster Recovery supporta un'ampia gamma di opzioni di configurazione per le reti di macchine virtuali. Potrebbe essere necessario modificarle se il sito di destinazione dispone di reti virtuali che utilizzano impostazioni TCP/IP diverse rispetto alle reti virtuali di produzione del sito di origine.
Al livello più basilare (e predefinito), le impostazioni utilizzano semplicemente le stesse impostazioni di rete TCP/IP per ogni VM sul sito di destinazione utilizzate sul sito di origine. Ciò richiede la configurazione delle stesse impostazioni TCP/IP sulle reti virtuali di origine e di destinazione.
Il servizio supporta le impostazioni di rete della configurazione IP statica o Dynamic Host Configuration Protocol (DHCP) per le VM. DHCP fornisce un metodo basato su standard per configurare dinamicamente le impostazioni TCP/IP di una porta di rete host. DHCP deve fornire, come minimo, un indirizzo TCP/IP e può anche fornire un indirizzo gateway predefinito (per il routing verso una connessione Internet esterna), una subnet mask e un indirizzo del server DNS. DHCP è comunemente utilizzato per i dispositivi informatici degli utenti finali, come i computer desktop, i laptop e le connessioni dei telefoni cellulari dei dipendenti, ma può essere utilizzato anche per qualsiasi dispositivo informatico di rete, come i server.
-
Opzione Utilizza le stesse impostazioni di subnet mask, DNS e gateway: poiché queste impostazioni sono in genere le stesse per tutte le VM connesse alle stesse reti virtuali, potrebbe essere più semplice configurarle una volta e lasciare che Disaster Recovery utilizzi le impostazioni per tutte le VM nel gruppo di risorse protetto dal piano di replica. Se alcune VM utilizzano impostazioni diverse, è necessario deselezionare questa casella e specificare tali impostazioni per ciascuna VM.
-
Tipo di indirizzo IP: riconfigurare la configurazione delle VM in modo che corrisponda ai requisiti della rete virtuale di destinazione. NetApp Disaster Recovery offre due opzioni: DHCP o IP statico. Per gli IP statici, configurare la subnet mask, il gateway e i server DNS. Inoltre, immettere le credenziali per le VM.
-
DHCP: selezionare questa impostazione se si desidera che le VM ottengano le informazioni sulla configurazione di rete da un server DHCP. Se si sceglie questa opzione, si forniscono solo le credenziali per la VM.
-
IP statico: selezionare questa impostazione se si desidera specificare manualmente le informazioni di configurazione IP. È possibile selezionare una delle seguenti opzioni: uguale all'origine, diverso dall'origine o mappatura della subnet. Se si sceglie lo stesso della fonte, non è necessario immettere le credenziali. D'altro canto, se si sceglie di utilizzare informazioni diverse dalla fonte, è possibile fornire le credenziali, l'indirizzo IP della VM, la subnet mask, il DNS e le informazioni sul gateway. Le credenziali del sistema operativo guest della VM devono essere fornite a livello globale o a livello di ciascuna VM.
Ciò può essere molto utile quando si ripristinano ambienti di grandi dimensioni in cluster di destinazione più piccoli o per eseguire test di disaster recovery senza dover predisporre un'infrastruttura VMware fisica uno a uno.
-
-
Script: è possibile includere script personalizzati ospitati dal sistema operativo guest in formato .sh, .bat o .ps1 come processi post. Grazie agli script personalizzati, Disaster Recovery può eseguire lo script dopo un failover, un failback e processi di migrazione. Ad esempio, è possibile utilizzare uno script personalizzato per riprendere tutte le transazioni del database una volta completato il failover. Il servizio può eseguire script all'interno di VM che eseguono Microsoft Windows o qualsiasi variante Linux supportata con parametri della riga di comando supportati. È possibile assegnare uno script a singole VM o a tutte le VM nel piano di replica.
Per abilitare l'esecuzione degli script con il sistema operativo guest della macchina virtuale, è necessario che siano soddisfatte le seguenti condizioni:
-
VMware Tools deve essere installato sulla VM.
-
Per eseguire lo script è necessario fornire credenziali utente appropriate con privilegi adeguati sul sistema operativo guest.
-
Facoltativamente, includi un valore di timeout in secondi per lo script.
VM che eseguono Microsoft Windows: possono eseguire script batch di Windows (.bat) o PowerShell (ps1). Gli script di Windows possono utilizzare argomenti della riga di comando. Formatta ogni argomento nel
arg_name$valueformato, dovearg_nameè il nome dell'argomento e$valueè il valore dell'argomento e un punto e virgola separa ciascunoargument$valuepaio.
VM che eseguono Linux: possono eseguire qualsiasi script shell (.sh) supportato dalla versione di Linux utilizzata dalla VM. Gli script Linux possono utilizzare argomenti della riga di comando. Fornire gli argomenti in un elenco di valori separati da punto e virgola. Gli argomenti denominati non sono supportati. Aggiungi ogni argomento al
Arg[x]elenco degli argomenti e fare riferimento a ciascun valore utilizzando un puntatore inArg[x]matrice, ad esempio,value1;value2;value3. -
-
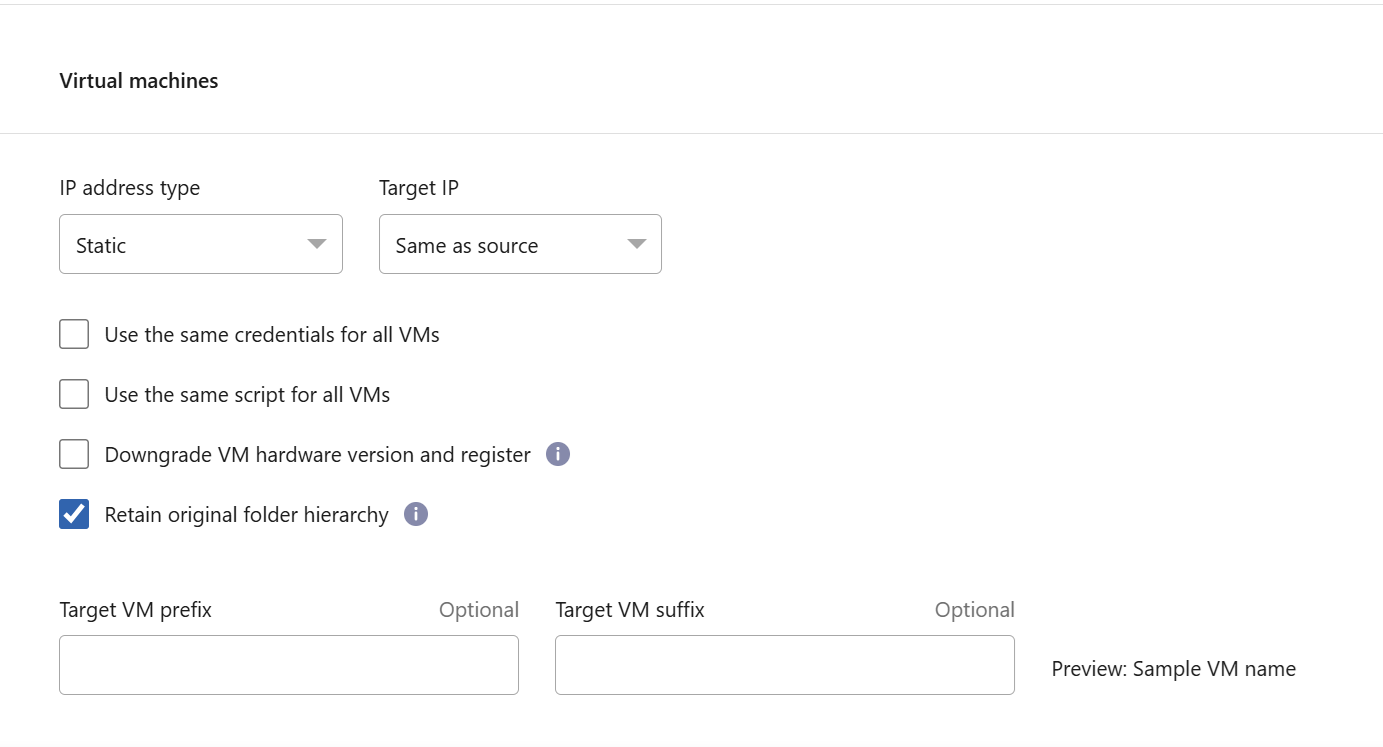
Esegui il downgrade della versione hardware della VM e registra: seleziona questa opzione se la versione dell'host ESX di destinazione è precedente a quella di origine, in modo che corrispondano durante la registrazione.
-
Mantieni la gerarchia delle cartelle originale: per impostazione predefinita, Disaster Recovery conserva la gerarchia dell'inventario delle VM (struttura delle cartelle) in caso di failover. Se la destinazione di ripristino non ha la gerarchia di cartelle originale, Disaster Recovery la crea.
Deselezionare questa casella per ignorare la gerarchia delle cartelle originale.
-
Prefisso e suffisso della VM di destinazione: nei dettagli delle macchine virtuali, è possibile aggiungere facoltativamente un prefisso e un suffisso a ciascun nome di VM sottoposto a failover. Ciò può essere utile per differenziare le VM sottoposte a failover dalle VM di produzione in esecuzione sullo stesso cluster vCenter. Ad esempio, è possibile aggiungere il prefisso "DR-" e il suffisso "-failover" al nome della VM. In caso di emergenza, alcune persone aggiungono un secondo vCenter di produzione per ospitare temporaneamente le VM in un sito diverso. L'aggiunta di un prefisso o di un suffisso può aiutare a identificare rapidamente le VM sottoposte a failover. È possibile utilizzare il prefisso o il suffisso anche negli script personalizzati.
È possibile utilizzare il metodo alternativo di impostazione della cartella VM di destinazione nella sezione Risorse di calcolo.
-
CPU e Memoria (GB): Nei dettagli della macchina virtuale, è possibile ridimensionare facoltativamente la CPU e la memoria della VM.
È possibile configurare la DRAM in gigabyte (GiB) o megabyte (MiB). Sebbene ogni VM richieda almeno un MiB di RAM, la quantità effettiva deve garantire che il sistema operativo guest della VM e tutte le applicazioni in esecuzione possano funzionare in modo efficiente. -
Ordine di avvio: è possibile modificare l'ordine di avvio dopo un failover per tutte le macchine virtuali selezionate nei gruppi di risorse. Per impostazione predefinita, tutte le VM vengono avviate insieme in parallelo; tuttavia, è possibile apportare modifiche in questa fase. Ciò è utile per garantire che tutte le VM con priorità uno siano in esecuzione prima che vengano avviate le VM con priorità successiva.
Disaster Recovery avvia in parallelo tutte le VM con lo stesso numero di ordine di avvio.
-
Avvio sequenziale: assegna a ciascuna VM un numero univoco per avviarla nell'ordine assegnato, ad esempio 1, 2, 3, 4, 5.
-
Avvio simultaneo: assegna lo stesso numero a tutte le VM per avviarle contemporaneamente, ad esempio 1,1,1,1,2,2,3,4,4.
-
-
Ritardo di avvio: regola il ritardo in minuti dell'azione di avvio, indicando la quantità di tempo che la VM attenderà prima di avviare il processo di accensione. Inserisci un valore compreso tra 0 e 10 minuti.
-
Coerente con l'applicazione: indica se creare copie snapshot coerenti con l'applicazione. Il servizio metterà in pausa l'applicazione e quindi creerà uno snapshot per ottenere uno stato coerente dell'applicazione. Questa funzionalità è supportata con Oracle in esecuzione su Windows e Linux e SQL Server in esecuzione su Windows. Vedere maggiori dettagli di seguito.
È necessario attivare l'interruttore Advance settings per questa opzione. Se si abilita la coerenza con l'applicazione, è necessario fornire le credenziali sotto forma di username e password.
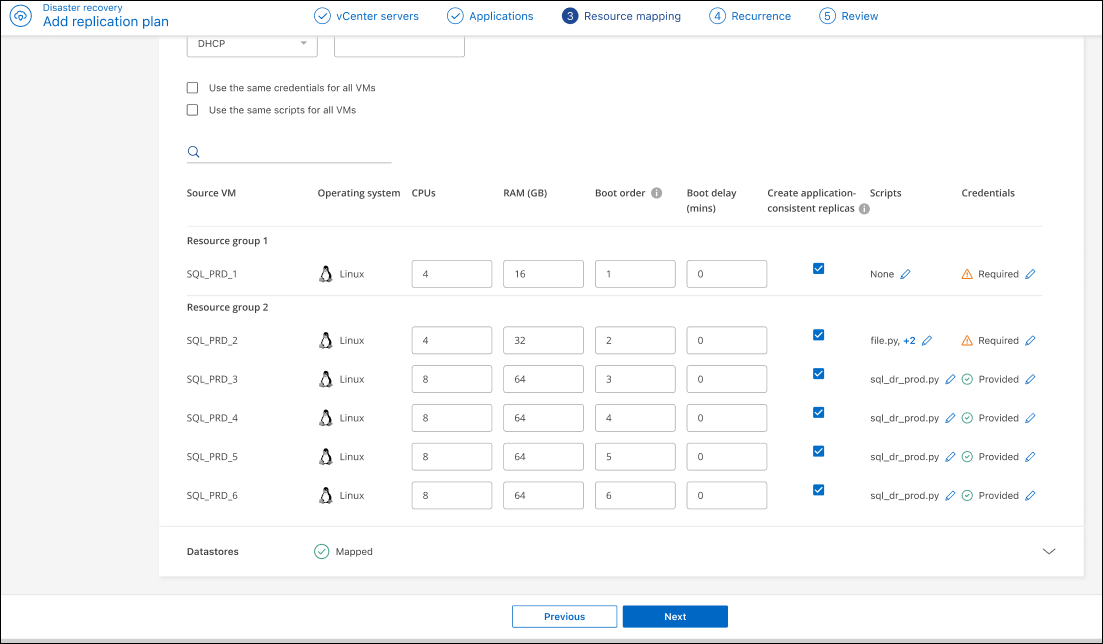
Creare repliche coerenti con l'applicazione
Molte VM ospitano server di database come Oracle o Microsoft SQL Server. Questi server di database richiedono snapshot coerenti con l'applicazione per garantire che il database sia in uno stato coerente quando viene eseguito lo snapshot.
Gli snapshot coerenti con l'applicazione garantiscono che il database si trovi in uno stato coerente quando viene eseguito lo snapshot. Questo è importante perché garantisce che il database possa essere ripristinato a uno stato coerente dopo un'operazione di failover o failback.
I dati gestiti dal server del database potrebbero essere ospitati sullo stesso datastore della macchina virtuale che ospita il server del database oppure su un datastore diverso. Nella tabella seguente sono illustrate le configurazioni supportate per gli snapshot coerenti con l'applicazione in Disaster Recovery:
| Posizione dei dati | Supportato | Note |
|---|---|---|
All'interno dello stesso datastore vCenter della VM |
SÌ |
Poiché il server del database e il database risiedono entrambi nello stesso datastore, sia il server che i dati saranno sincronizzati in caso di failover. |
All'interno di un datastore vCenter diverso dalla VM |
NO |
Disaster Recovery non è in grado di identificare quando i dati di un server di database si trovano su un diverso datastore vCenter. Il servizio non può replicare i dati, ma può replicare la VM del server del database. Sebbene i dati del database non possano essere replicati, il servizio garantisce che il server del database esegua tutti i passaggi necessari per garantire che il database sia inattivo al momento del backup della VM. |
All'interno di una fonte dati esterna |
NO |
Se i dati risiedono su una LUN montata su guest o su una condivisione NFS, Disaster Recovery non può replicare i dati, ma può replicare la VM del server del database. Sebbene i dati del database non possano essere replicati, il servizio garantisce che il server del database esegua tutti i passaggi necessari per garantire che il database sia inattivo al momento del backup della VM. |
Durante un backup pianificato, Disaster Recovery mette in pausa il server del database e quindi esegue uno snapshot della macchina virtuale che ospita il server del database. Ciò garantisce che il database sia in uno stato coerente quando viene eseguito lo snapshot.
-
Per le VM Windows, il servizio utilizza il servizio Microsoft Volume Shadow Copy (VSS) per coordinarsi con uno dei due server di database.
-
Per le VM Linux, il servizio utilizza un set di script per impostare il server Oracle in modalità di backup.
Per abilitare repliche coerenti con l'applicazione delle VM e dei relativi datastore di hosting, selezionare la casella accanto a Crea repliche coerenti con l'applicazione per ogni VM e fornire le credenziali di accesso guest con i privilegi appropriati.
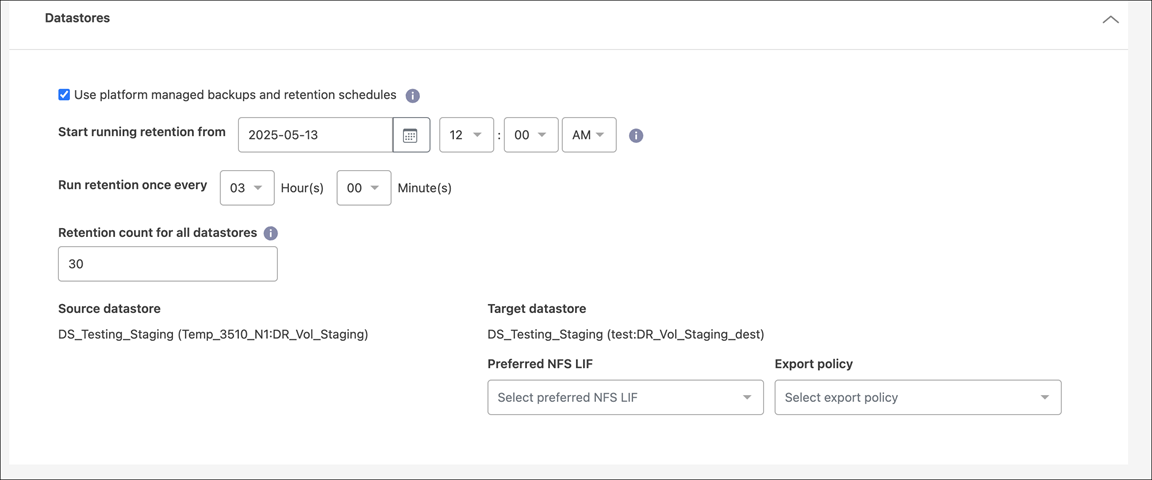
Sezione Datastores
Gli archivi dati VMware sono ospitati su volumi ONTAP FlexVol o su LUN iSCSI o FC ONTAP tramite VMware VMFS. Utilizzare la sezione Datastore per definire il cluster ONTAP di destinazione, la macchina virtuale di archiviazione (SVM) e il volume o LUN per replicare i dati su disco nella destinazione.
Selezionare la freccia rivolta verso il basso accanto a Datastore. In base alla selezione delle VM, vengono selezionate automaticamente le mappature dei datastore.
Questa sezione potrebbe essere abilitata o disabilitata a seconda della selezione effettuata.
-
Utilizza backup gestiti dalla piattaforma e pianificazioni di conservazione: se utilizzi una soluzione di gestione degli snapshot esterna, seleziona questa casella. NetApp Disaster Recovery supporta l'uso di soluzioni di gestione degli snapshot esterni, come lo scheduler di policy nativo ONTAP SnapMirror o integrazioni di terze parti. Se ogni datastore (volume) nel piano di replicazione ha già una relazione SnapMirror gestita altrove, è possibile utilizzare tali snapshot come punti di ripristino in NetApp Disaster Recovery.
Se si seleziona questa opzione, NetApp Disaster Recovery non configura una pianificazione di backup. Tuttavia, è comunque necessario configurare una pianificazione di conservazione perché potrebbero essere comunque acquisiti snapshot per operazioni di test, failover e failback.
Dopo aver configurato questa funzionalità, il servizio non esegue snapshot programmati regolarmente, ma si affida all'entità esterna per l'esecuzione e l'aggiornamento di tali snapshot.
-
Ora di inizio dei backup e della conservazione: Inserisci la data e l'ora in cui desideri che i backup e la conservazione inizino.
-
Frequenza di backup e conservazione: Inserire l'intervallo di tempo in ore e minuti. Ad esempio, se si inserisce 1 ora, il servizio creerà un'istantanea ogni ora.
-
Retention count for all datastores: Inserire il numero di snapshot che si desidera conservare.
Il numero di snapshot conservati, insieme alla frequenza di modifica dei dati tra ogni snapshot, determina la quantità di spazio di archiviazione consumato sia sull'origine che sulla destinazione. Più snapshot si conservano, più spazio di archiviazione viene consumato. -
Datastore di origine e di destinazione: se esistono più relazioni SnapMirror (fan-out), è possibile selezionare la destinazione da utilizzare. Se per un volume è già stata stabilita una relazione SnapMirror , vengono visualizzati i datastore di origine e di destinazione corrispondenti. Se si tratta di un volume che non ha una relazione SnapMirror , è possibile crearne una ora selezionando un cluster di destinazione, selezionando una SVM di destinazione e specificando un nome per il volume. Il servizio creerà il volume e la relazione SnapMirror .
Se si desidera creare una relazione SnapMirror in questo servizio, il cluster e il relativo peering SVM devono essere già stati configurati al di fuori di NetApp Disaster Recovery. -
Se le VM provengono dallo stesso volume e dallo stesso SVM, il servizio esegue uno snapshot ONTAP standard e aggiorna le destinazioni secondarie.
-
Se le VM provengono da volumi diversi e dallo stesso SVM, il servizio crea uno snapshot del gruppo di coerenza includendo tutti i volumi e aggiorna le destinazioni secondarie.
-
Se le VM provengono da volumi diversi e da SVM diversi, il servizio esegue una fase di avvio del gruppo di coerenza e uno snapshot della fase di commit includendo tutti i volumi nello stesso cluster o in cluster diversi e aggiorna le destinazioni secondarie.
-
Durante il failover, è possibile selezionare qualsiasi snapshot. Se si seleziona lo snapshot più recente, il servizio crea un backup su richiesta, aggiorna la destinazione e utilizza tale snapshot per il failover.
-
Aggiungere mapping di failover di test
-
Per impostare mapping diversi per l'ambiente di test, deselezionare la casella e selezionare la scheda Mapping test.
-
Procedere come in precedenza per ogni scheda, ma questa volta per l'ambiente di test.
Nella scheda Test mapping, i mapping Macchine virtuali e Datastore sono disabilitati.
Successivamente potrai testare l'intero piano. In questo momento stai configurando le mappature per l'ambiente di test.
Rivedere il piano di replicazione
Infine, prenditi qualche minuto per rivedere il piano di replicazione.
|
|
Successivamente è possibile disattivare o eliminare il piano di replica. |
-
Esaminare le informazioni in ogni scheda: Dettagli del piano, Mapping del failover e VM.
-
Seleziona Aggiungi piano.
Il piano viene aggiunto all'elenco dei piani.
Modificare un piano di replicazione
È possibile modificare una pianificazione del piano di replica per testare la conformità e garantire che i test di failover vengano completati correttamente.
-
Impatto sui tempi di conformità: quando viene creato un piano di replica, il servizio crea per impostazione predefinita una pianificazione di conformità. Il tempo di conformità predefinito è di 30 minuti. Per modificare questo orario, è possibile modificare la pianificazione nel piano di replica.
-
Impatto del failover di prova: è possibile testare un processo di failover su richiesta o in base a una pianificazione. Ciò consente di testare il failover delle macchine virtuali su una destinazione specificata in un piano di replica.
Un failover di test crea un volume FlexClone , monta il datastore e sposta il carico di lavoro su tale datastore. Un'operazione di failover di prova non ha alcun impatto sui carichi di lavoro di produzione, sulla relazione SnapMirror utilizzata sul sito di prova e sui carichi di lavoro protetti che devono continuare a funzionare normalmente.
In base alla pianificazione, viene eseguito il test di failover, che garantisce che i carichi di lavoro vengano spostati verso la destinazione specificata dal piano di replica.
-
Dal menu NetApp Disaster Recovery , selezionare Piani di replica.
-
Seleziona Azioni*
 icona e seleziona *Modifica pianificazioni.
icona e seleziona *Modifica pianificazioni. -
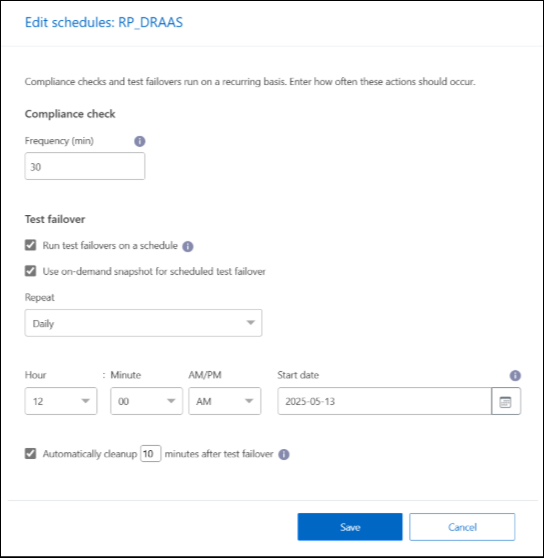
Inserisci la frequenza in minuti con cui desideri che NetApp Disaster Recovery verifichi la conformità dei test.
-
Per verificare che i test di failover siano integri, seleziona Esegui failover con una pianificazione mensile.
-
Seleziona il giorno del mese e l'ora in cui desideri che vengano eseguiti i test.
-
Inserisci la data in formato aaaa-mm-gg in cui desideri che inizi il test.
-
-
Utilizza snapshot su richiesta per il failover di test pianificato: per acquisire un nuovo snapshot prima di avviare il failover di test automatico, selezionare questa casella.
-
Per ripulire l'ambiente di test al termine del test di failover, selezionare Pulizia automatica dopo il failover del test e immettere il numero di minuti che si desidera attendere prima che venga avviata la pulizia.
Questo processo annulla la registrazione delle VM temporanee dalla posizione di test, elimina il volume FlexClone creato e smonta i datastore temporanei. -
Seleziona Salva.