Principali casi d'uso e architetture di intelligenza artificiale, apprendimento automatico e apprendimento automatico (DL)
 Suggerisci modifiche
Suggerisci modifiche
I principali casi d'uso e la metodologia di intelligenza artificiale, apprendimento automatico e apprendimento digitale possono essere suddivisi nelle seguenti sezioni:
Pipeline Spark NLP e inferenza distribuita TensorFlow
L'elenco seguente contiene le librerie NLP open source più diffuse, adottate dalla comunità della scienza dei dati a diversi livelli di sviluppo:
-
"Kit di strumenti per il linguaggio naturale (NLTK)" . Il kit completo per tutte le tecniche di PNL. È stato mantenuto fin dai primi anni del 2000.
-
"TextBlob" . Un'API Python di strumenti NLP di facile utilizzo, basata su NLTK e Pattern.
-
"Stanford Core NLP" . Servizi e pacchetti NLP in Java sviluppati dallo Stanford NLP Group.
-
"Gensim" . Topic Modelling for Humans è nato come una raccolta di script Python per il progetto Czech Digital Mathematics Library.
-
"SpaCy" . Flussi di lavoro NLP industriali end-to-end con Python e Cython con accelerazione GPU per trasformatori.
-
"Testo veloce" . Una libreria NLP gratuita, leggera e open source per l'apprendimento di incorporamenti di parole e la classificazione di frasi, creata dal laboratorio AI Research (FAIR) di Facebook.
Spark NLP è una soluzione unica e unificata per tutte le attività e i requisiti NLP che consente di realizzare un software NLP scalabile, ad alte prestazioni e ad alta precisione per casi d'uso di produzione reali. Sfrutta l'apprendimento per trasferimento e implementa gli algoritmi e i modelli più all'avanguardia nella ricerca e in tutti i settori. A causa della mancanza di supporto completo da parte di Spark per le librerie di cui sopra, Spark NLP è stato costruito su "Spark ML" per sfruttare il motore di elaborazione dati distribuito in memoria di Spark per uso generico come libreria NLP di livello aziendale per flussi di lavoro di produzione mission-critical. I suoi annotatori utilizzano algoritmi basati su regole, apprendimento automatico e TensorFlow per potenziare le implementazioni di deep learning. Ciò comprende attività NLP comuni, tra cui, a titolo esemplificativo ma non esaustivo, tokenizzazione, lemmatizzazione, stemming, tagging delle parti del discorso, riconoscimento di entità denominate, controllo ortografico e analisi del sentiment.
BERT (Bidirectional Encoder Representations from Transformers) è una tecnica di apprendimento automatico basata sui trasformatori per l'elaborazione del linguaggio naturale. Ha reso popolare il concetto di pre-addestramento e messa a punto. L'architettura del trasformatore in BERT ha avuto origine dalla traduzione automatica, che modella le dipendenze a lungo termine meglio dei modelli linguistici basati sulle reti neurali ricorrenti (RNN). Ha inoltre introdotto il task Masked Language Modelling (MLM), in cui un numero casuale del 15% di tutti i token viene mascherato e il modello li prevede, consentendo una vera bidirezionalità.
L'analisi del sentiment finanziario è complessa a causa del linguaggio specialistico e della mancanza di dati specifici in tale ambito. FinBERT, un modello linguistico basato su BERT preaddestrato, è stato adattato al dominio "Reuters TRC2" , un corpus finanziario, e perfezionato con dati etichettati ( "Financial PhraseBank" ) per la classificazione del sentiment finanziario. I ricercatori hanno estratto 4.500 frasi da articoli di giornale contenenti termini finanziari. Successivamente, 16 esperti e studenti magistrali con formazione in finanza hanno etichettato le frasi come positive, neutre e negative. Abbiamo creato un flusso di lavoro Spark end-to-end per analizzare il sentiment delle trascrizioni delle call sugli utili delle 10 principali società del NASDAQ dal 2016 al 2020 utilizzando FinBERT e altre due pipeline pre-addestrate, "Spiega il documento DL" ) da Spark NLP.
Il motore di apprendimento profondo alla base di Spark NLP è TensorFlow, una piattaforma end-to-end open source per l'apprendimento automatico che consente una facile creazione di modelli, una solida produzione di ML ovunque e una potente sperimentazione per la ricerca. Pertanto, quando eseguiamo le nostre pipeline in Spark yarn cluster modalità, stavamo essenzialmente eseguendo TensorFlow distribuito con parallelizzazione di dati e modelli su un master e più nodi worker, nonché storage collegato alla rete montato sul cluster.
Formazione distribuita Horovod
La convalida principale di Hadoop per le prestazioni correlate a MapReduce viene eseguita con TeraGen, TeraSort, TeraValidate e DFSIO (lettura e scrittura). I risultati della convalida TeraGen e TeraSort sono presentati in "Soluzione NetApp E-Series per Hadoop" e nella sezione "Storage Tiering" per AFF.
In base alle richieste dei clienti, riteniamo che la formazione distribuita con Spark sia uno dei casi d'uso più importanti. In questo documento abbiamo utilizzato il "Hovorod su Spark" per convalidare le prestazioni di Spark con soluzioni NetApp on-premise, cloud-native e cloud ibride utilizzando i controller di archiviazione NetApp All Flash FAS (AFF), Azure NetApp Files e StorageGRID.
Il pacchetto Horovod su Spark fornisce un comodo wrapper attorno a Horovod che semplifica l'esecuzione di carichi di lavoro di formazione distribuiti nei cluster Spark, consentendo un ciclo di progettazione del modello rigoroso in cui l'elaborazione dei dati, la formazione del modello e la valutazione del modello vengono eseguite tutte in Spark, dove risiedono i dati di formazione e inferenza.
Sono disponibili due API per eseguire Horovod su Spark: un'API Estimator di alto livello e un'API Run di basso livello. Sebbene entrambi utilizzino lo stesso meccanismo di base per avviare Horovod sugli esecutori Spark, l'API Estimator astrae l'elaborazione dei dati, il ciclo di addestramento del modello, il checkpointing del modello, la raccolta delle metriche e l'addestramento distribuito. Abbiamo utilizzato Horovod Spark Estimators, TensorFlow e Keras per una preparazione dei dati end-to-end e un flusso di lavoro di formazione distribuito basato su "Vendite del negozio Kaggle Rossmann" concorrenza.
La sceneggiatura keras_spark_horovod_rossmann_estimator.py può essere trovato nella sezione"Script Python per ogni caso d'uso principale." Si compone di tre parti:
-
La prima parte esegue vari passaggi di pre-elaborazione dei dati su un set iniziale di file CSV forniti da Kaggle e raccolti dalla community. I dati di input vengono separati in un set di addestramento con un
Validationsottoinsieme e un set di dati di test. -
La seconda parte definisce un modello Keras Deep Neural Network (DNN) con funzione di attivazione sigmoide logaritmica e un ottimizzatore Adam, ed esegue l'addestramento distribuito del modello utilizzando Horovod su Spark.
-
La terza parte esegue una previsione sul set di dati di test utilizzando il modello migliore che riduce al minimo l'errore assoluto medio complessivo del set di convalida. Quindi crea un file CSV di output.
Vedi la sezione"Apprendimento automatico" per vari risultati di confronto in fase di esecuzione.
Apprendimento approfondito multi-worker con Keras per la previsione del CTR
Grazie ai recenti progressi nelle piattaforme e nelle applicazioni di apprendimento automatico, molta attenzione è ora rivolta all'apprendimento su larga scala. Il tasso di clic (CTR) è definito come il numero medio di clic per cento impressioni di annunci online (espresso in percentuale). È ampiamente adottato come metrica chiave in vari settori verticali e casi d'uso, tra cui marketing digitale, vendita al dettaglio, e-commerce e fornitori di servizi. Per maggiori dettagli sulle applicazioni di CTR e sui risultati delle prestazioni di formazione distribuita, vedere"Modelli di apprendimento profondo per le prestazioni di previsione del CTR" sezione.
In questo rapporto tecnico abbiamo utilizzato una variante del "Set di dati Criteo Terabyte Click Logs" (vedere TR-4904) per l'apprendimento profondo distribuito multi-worker utilizzando Keras per creare un flusso di lavoro Spark con modelli Deep e Cross Network (DCN), confrontando le sue prestazioni in termini di funzione di errore di perdita del registro con un modello di regressione logistica Spark ML di base. DCN cattura in modo efficiente interazioni di caratteristiche efficaci di gradi limitati, apprende interazioni altamente non lineari, non richiede alcuna progettazione manuale delle caratteristiche o ricerche esaustive e ha un basso costo computazionale.
I dati per i sistemi di raccomandazione su scala web sono per lo più discreti e categoriali, il che determina uno spazio di funzionalità ampio e sparso, che risulta difficile da esplorare. Ciò ha limitato la maggior parte dei sistemi su larga scala a modelli lineari come la regressione logistica. Tuttavia, per fare buone previsioni è fondamentale identificare le caratteristiche frequentemente predittive e allo stesso tempo esplorare le caratteristiche incrociate invisibili o rare. I modelli lineari sono semplici, interpretabili e facili da scalare, ma hanno un potere espressivo limitato.
D'altro canto, è stato dimostrato che le caratteristiche incrociate sono significative nel migliorare l'espressività dei modelli. Purtroppo, spesso è necessario un'ingegneria manuale delle funzionalità o una ricerca esaustiva per identificarle. Generalizzare le interazioni tra caratteristiche invisibili è spesso difficile. Utilizzando una rete neurale incrociata come DCN si evita l'ingegneria delle caratteristiche specifiche per un'attività, applicando esplicitamente l'incrocio delle caratteristiche in modo automatico. La rete incrociata è composta da più strati, in cui il grado più elevato di interazioni è determinato in modo dimostrabile dalla profondità dello strato. Ogni livello produce interazioni di ordine superiore basate su quelle esistenti e mantiene le interazioni dei livelli precedenti.
Una rete neurale profonda (DNN) promette di catturare interazioni molto complesse tra le caratteristiche. Tuttavia, rispetto a DCN, richiede quasi un ordine di grandezza in più di parametri, non è in grado di formare esplicitamente le caratteristiche incrociate e potrebbe non riuscire ad apprendere in modo efficiente alcuni tipi di interazioni delle caratteristiche. La rete incrociata è efficiente in termini di memoria e facile da implementare. L'addestramento congiunto dei componenti cross e DNN cattura in modo efficiente le interazioni delle caratteristiche predittive e garantisce prestazioni all'avanguardia sul set di dati Criteo CTR.
Un modello DCN inizia con uno strato di incorporamento e di impilamento, seguito da una rete incrociata e da una rete profonda in parallelo. A loro volta, seguono uno strato di combinazione finale che unisce gli output delle due reti. I dati di input possono essere un vettore con caratteristiche sparse e dense. In Spark, le librerie contengono il tipo SparseVector . È quindi importante che gli utenti distinguano tra i due e facciano attenzione quando chiamano le rispettive funzioni e metodi. Nei sistemi di raccomandazione su scala web come la previsione CTR, gli input sono per lo più caratteristiche categoriali, ad esempio 'country=usa' . Tali caratteristiche sono spesso codificate come vettori one-hot, ad esempio, '[0,1,0, …]' . Codifica one-hot (OHE) con SparseVector è utile quando si ha a che fare con set di dati del mondo reale con vocabolari in continua evoluzione e crescita. Abbiamo modificato gli esempi in "DeepCTR" per elaborare vocabolari di grandi dimensioni, creando vettori di incorporamento nello strato di incorporamento e impilamento del nostro DCN.
IL "Set di dati sugli annunci display di Criteo" prevede il tasso di clic degli annunci. Presenta 13 caratteristiche intere e 26 caratteristiche categoriali, in cui ogni categoria ha un'elevata cardinalità. Per questo set di dati, un miglioramento di 0,001 nel logloss è praticamente significativo a causa delle grandi dimensioni dell'input. Un piccolo miglioramento nella precisione delle previsioni per una vasta base di utenti può potenzialmente portare a un notevole aumento del fatturato di un'azienda. Il set di dati contiene 11 GB di registri utente relativi a un periodo di 7 giorni, pari a circa 41 milioni di record. Abbiamo usato Spark dataFrame.randomSplit()function per suddividere casualmente i dati per l'addestramento (80%), la convalida incrociata (10%) e il restante 10% per i test.
DCN è stato implementato su TensorFlow con Keras. L'implementazione del processo di addestramento del modello con DCN si basa su quattro componenti principali:
-
Elaborazione e incorporamento dei dati. Le caratteristiche a valore reale vengono normalizzate applicando una trasformata logaritmica. Per le caratteristiche categoriali, incorporiamo le caratteristiche in vettori densi di dimensione 6×(cardinalità di categoria)1/4. Concatenando tutti gli embedding si ottiene un vettore di dimensione 1026.
-
Ottimizzazione. Abbiamo applicato l'ottimizzazione stocastica mini-batch con l'ottimizzatore Adam. La dimensione del lotto è stata impostata su 512. La normalizzazione batch è stata applicata alla rete profonda e la norma di clip del gradiente è stata impostata a 100.
-
Regolarizzazione. Abbiamo utilizzato l'interruzione anticipata, poiché la regolarizzazione o l'abbandono della L2 non si sono rivelati efficaci.
-
Iperparametri. Riportiamo i risultati basati su una ricerca a griglia sul numero di livelli nascosti, sulla dimensione dei livelli nascosti, sul tasso di apprendimento iniziale e sul numero di livelli incrociati. Il numero di livelli nascosti variava da 2 a 5, con dimensioni dei livelli nascosti che andavano da 32 a 1024. Per DCN, il numero di strati incrociati era compreso tra 1 e 6. Il tasso di apprendimento iniziale è stato regolato da 0,0001 a 0,001 con incrementi di 0,0001. Tutti gli esperimenti sono stati applicati in anticipo, fermandosi al passo di addestramento 150.000, oltre il quale ha iniziato a verificarsi un overfitting.
Architetture utilizzate per la convalida
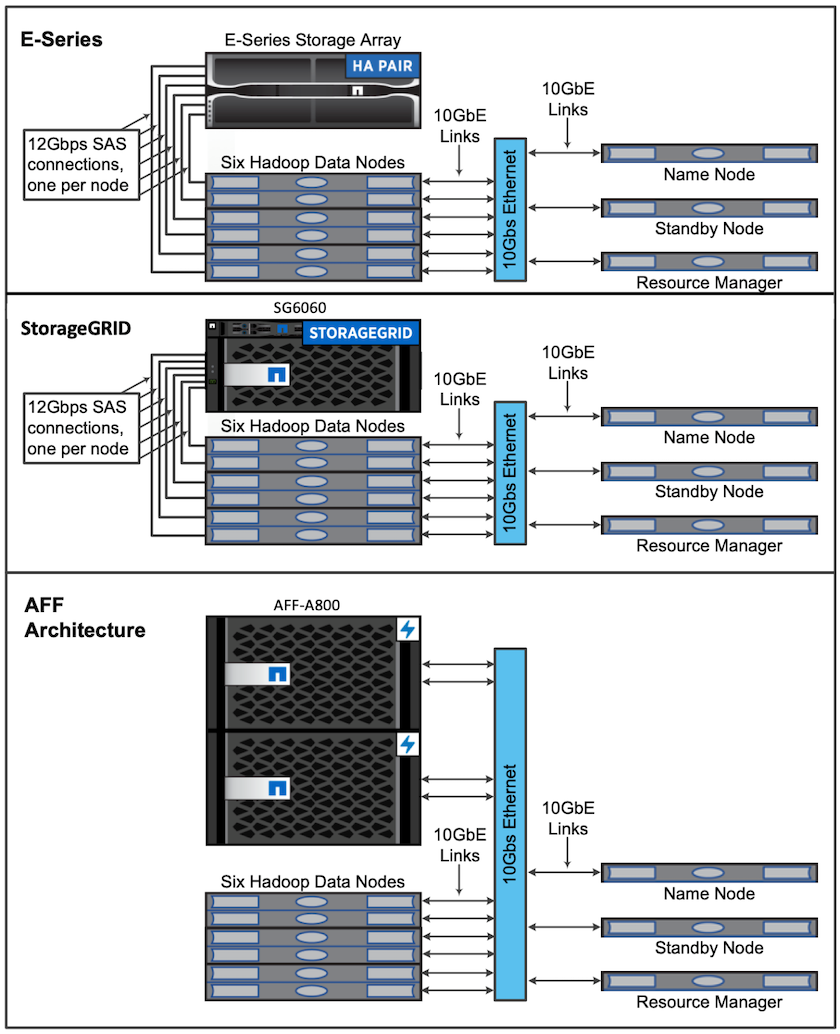
Per questa convalida, abbiamo utilizzato quattro nodi worker e un nodo master con una coppia AFF-A800 HA. Tutti i membri del cluster erano connessi tramite switch di rete 10GbE.
Per la convalida della soluzione NetApp Spark, abbiamo utilizzato tre diversi controller di storage: E5760, E5724 e AFF-A800. I controller di archiviazione della serie E sono stati collegati a cinque nodi dati con connessioni SAS da 12 Gbps. Il controller di archiviazione AFF HA-pair fornisce volumi NFS esportati tramite connessioni 10GbE ai nodi worker Hadoop. I membri del cluster Hadoop erano connessi tramite connessioni 10GbE nelle soluzioni Hadoop E-Series, AFF e StorageGRID .