

Eseguire un carico di lavoro di intelligenza artificiale distribuito sincrono
 Suggerisci modifiche
Suggerisci modifiche
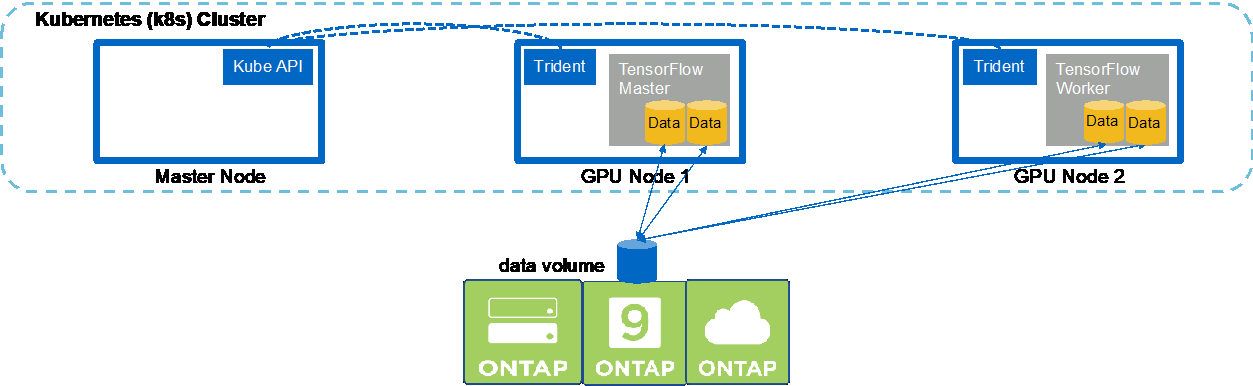
Per eseguire un processo di intelligenza artificiale e apprendimento automatico multinodo sincrono nel cluster Kubernetes, eseguire le seguenti attività sull'host di jump di distribuzione. Questo processo consente di sfruttare i dati archiviati su un volume NetApp e di utilizzare più GPU di quelle che un singolo nodo worker può fornire. Per una rappresentazione di un lavoro di intelligenza artificiale distribuita sincrona, vedere la figura seguente.

|
I lavori distribuiti sincroni possono contribuire ad aumentare le prestazioni e la precisione della formazione rispetto ai lavori distribuiti asincroni. Una discussione sui pro e contro dei lavori sincroni rispetto a quelli asincroni esula dallo scopo di questo documento. |
-
I seguenti comandi di esempio mostrano la creazione di un worker che partecipa all'esecuzione sincrona distribuita dello stesso lavoro di benchmark TensorFlow eseguito su un singolo nodo nell'esempio nella sezione"Eseguire un carico di lavoro AI a nodo singolo" . In questo esempio specifico, viene distribuito un solo worker perché il lavoro viene eseguito su due nodi worker.
Questa distribuzione di worker di esempio richiede otto GPU e può quindi essere eseguita su un singolo nodo worker GPU che dispone di otto o più GPU. Se i nodi worker GPU dispongono di più di otto GPU, per massimizzare le prestazioni potresti voler aumentare questo numero in modo che corrisponda al numero di GPU presenti nei nodi worker. Per ulteriori informazioni sulle distribuzioni di Kubernetes, vedere "documentazione ufficiale di Kubernetes" .
In questo esempio viene creata una distribuzione Kubernetes perché questo specifico worker containerizzato non verrebbe mai completato da solo. Pertanto, non ha senso distribuirlo utilizzando la struttura dei job di Kubernetes. Se il tuo worker è progettato o scritto per completarsi da solo, allora potrebbe essere sensato utilizzare la struttura del lavoro per distribuire il tuo worker.
Al pod specificato in questa specifica di distribuzione di esempio viene assegnato un
hostNetworkvalore ditrue. Questo valore indica che il pod utilizza lo stack di rete del nodo worker host anziché lo stack di rete virtuale che Kubernetes crea solitamente per ogni pod. Questa annotazione viene utilizzata in questo caso perché il carico di lavoro specifico si basa su Open MPI, NCCL e Horovod per eseguire il carico di lavoro in modo sincrono e distribuito. Pertanto, richiede l'accesso allo stack di rete host. Una discussione su Open MPI, NCCL e Horovod esula dallo scopo di questo documento. Che questo sia o menohostNetwork: truel'annotazione è necessaria a seconda dei requisiti del carico di lavoro specifico che si sta eseguendo. Per maggiori informazioni sulhostNetworkcampo, vedere il "documentazione ufficiale di Kubernetes" .$ cat << EOF > ./netapp-tensorflow-multi-imagenet-worker.yaml apiVersion: apps/v1 kind: Deployment metadata: name: netapp-tensorflow-multi-imagenet-worker spec: replicas: 1 selector: matchLabels: app: netapp-tensorflow-multi-imagenet-worker template: metadata: labels: app: netapp-tensorflow-multi-imagenet-worker spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["bash", "/netapp/scripts/start-slave-multi.sh", "22122"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-worker.yaml deployment.apps/netapp-tensorflow-multi-imagenet-worker created $ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 4s -
Verifica che la distribuzione del worker creata nel passaggio 1 sia stata avviata correttamente. I seguenti comandi di esempio confermano che è stato creato un singolo pod worker per la distribuzione, come indicato nella definizione di distribuzione, e che questo pod è attualmente in esecuzione su uno dei nodi worker GPU.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 60s 10.61.218.154 10.61.218.154 <none> $ kubectl logs netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 22122
-
Creare un job Kubernetes per un master che avvia, partecipa e monitora l'esecuzione del job multinodo sincrono. I seguenti comandi di esempio creano un master che avvia, partecipa e tiene traccia dell'esecuzione sincrona distribuita dello stesso processo di benchmark TensorFlow eseguito su un singolo nodo nell'esempio nella sezione"Eseguire un carico di lavoro AI a nodo singolo" .
Questo esempio di master job richiede otto GPU e può quindi essere eseguito su un singolo nodo worker GPU dotato di otto o più GPU. Se i nodi worker GPU dispongono di più di otto GPU, per massimizzare le prestazioni potresti voler aumentare questo numero in modo che corrisponda al numero di GPU presenti nei nodi worker.
Al pod master specificato in questa definizione di lavoro di esempio viene assegnato un
hostNetworkvalore ditrue, proprio come è stato dato al pod dei lavoratori unhostNetworkvalore ditruenel passaggio 1. Per maggiori dettagli sul motivo per cui questo valore è necessario, vedere il passaggio 1.$ cat << EOF > ./netapp-tensorflow-multi-imagenet-master.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-tensorflow-multi-imagenet-master spec: backoffLimit: 5 template: spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["python", "/netapp/scripts/run.py", "--dataset_dir=/mnt/mount_0/dataset/imagenet", "--port=22122", "--num_devices=16", "--dgx_version=dgx1", "--nodes=10.61.218.152,10.61.218.154"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true restartPolicy: Never EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-master.yaml job.batch/netapp-tensorflow-multi-imagenet-master created $ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 0/1 25s 25s -
Verificare che il processo master creato nel passaggio 3 sia in esecuzione correttamente. Il seguente comando di esempio conferma che è stato creato un singolo pod master per il job, come indicato nella definizione del job, e che questo pod è attualmente in esecuzione su uno dei nodi worker GPU. Dovresti anche vedere che il pod worker che hai visto originariamente nel passaggio 1 è ancora in esecuzione e che i pod master e worker sono in esecuzione su nodi diversi.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-master-ppwwj 1/1 Running 0 45s 10.61.218.152 10.61.218.152 <none> netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 26m 10.61.218.154 10.61.218.154 <none>
-
Verificare che il processo master creato nel passaggio 3 venga completato correttamente. I seguenti comandi di esempio confermano che il lavoro è stato completato correttamente.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 9m18s $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 9m38s netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 35m $ kubectl logs netapp-tensorflow-multi-imagenet-master-ppwwj [10.61.218.152:00008] WARNING: local probe returned unhandled shell:unknown assuming bash rm: cannot remove '/lib': Is a directory [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 Total images/sec = 12881.33875 ================ Clean Cache !!! ================== mpirun -allow-run-as-root -np 2 -H 10.61.218.152:1,10.61.218.154:1 -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" bash -c 'sync; echo 1 > /proc/sys/vm/drop_caches' ========================================= mpirun -allow-run-as-root -np 16 -H 10.61.218.152:8,10.61.218.154:8 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -x NCCL_IB_HCA=mlx5 -x NCCL_NET_GDR_READ=1 -x NCCL_IB_SL=3 -x NCCL_IB_GID_INDEX=3 -x NCCL_SOCKET_IFNAME=enp5s0.3091,enp12s0.3092,enp132s0.3093,enp139s0.3094 -x NCCL_IB_CUDA_SUPPORT=1 -mca orte_base_help_aggregate 0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" python /netapp/tensorflow/benchmarks_190205/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=256 --device=gpu --force_gpu_compatible=True --num_intra_threads=1 --num_inter_threads=48 --variable_update=horovod --batch_group_size=20 --num_batches=500 --nodistortions --num_gpus=1 --data_format=NCHW --use_fp16=True --use_tf_layers=False --data_name=imagenet --use_datasets=True --data_dir=/mnt/mount_0/dataset/imagenet --datasets_parallel_interleave_cycle_length=10 --datasets_sloppy_parallel_interleave=False --num_mounts=2 --mount_prefix=/mnt/mount_%d --datasets_prefetch_buffer_size=2000 -- datasets_use_prefetch=True --datasets_num_private_threads=4 --horovod_device=gpu > /tmp/20190814_161609_tensorflow_horovod_rdma_resnet50_gpu_16_256_b500_imagenet_nodistort_fp16_r10_m2_nockpt.txt 2>&1
-
Elimina la distribuzione del worker quando non ti serve più. I seguenti comandi di esempio mostrano l'eliminazione dell'oggetto di distribuzione del worker creato nel passaggio 1.
Quando elimini l'oggetto di distribuzione del worker, Kubernetes elimina automaticamente tutti i pod worker associati.
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 43m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 17m netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 43m $ kubectl delete deployment netapp-tensorflow-multi-imagenet-worker deployment.extensions "netapp-tensorflow-multi-imagenet-worker" deleted $ kubectl get deployments No resources found. $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 18m
-
Facoltativo: ripulisci gli artefatti del lavoro master. I seguenti comandi di esempio mostrano l'eliminazione dell'oggetto master del processo creato nel passaggio 3.
Quando elimini l'oggetto master job, Kubernetes elimina automaticamente tutti i master pod associati.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 19m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 19m $ kubectl delete job netapp-tensorflow-multi-imagenet-master job.batch "netapp-tensorflow-multi-imagenet-master" deleted $ kubectl get jobs No resources found. $ kubectl get pods No resources found.