

Protezione del database vettoriale tramite SnapCenter
 Suggerisci modifiche
Suggerisci modifiche
Questa sezione descrive come fornire protezione dei dati per il database vettoriale utilizzando NetApp SnapCenter.
Protezione del database vettoriale tramite NetApp SnapCenter.
Ad esempio, nel settore della produzione cinematografica, i clienti spesso possiedono dati critici incorporati, come file video e audio. La perdita di questi dati, dovuta a problemi come guasti al disco rigido, può avere un impatto significativo sulle loro attività, mettendo potenzialmente a repentaglio iniziative multimilionarie. Ci siamo imbattuti in casi in cui contenuti di inestimabile valore sono andati persi, causando notevoli disagi e perdite finanziarie. Garantire la sicurezza e l'integrità di questi dati essenziali è quindi di fondamentale importanza in questo settore. In questa sezione approfondiamo il modo in cui SnapCenter salvaguarda i dati del database vettoriale e i dati Milvus residenti in ONTAP. Per questo esempio, abbiamo utilizzato un bucket NAS (milvusdbvol1) derivato da un volume NFS ONTAP (vol1) per i dati dei clienti e un volume NFS separato (vectordbpv) per i dati di configurazione del cluster Milvus. Si prega di controllare"Qui" per il flusso di lavoro di backup di SnapCenter
-
Impostare l'host che verrà utilizzato per eseguire i comandi SnapCenter .
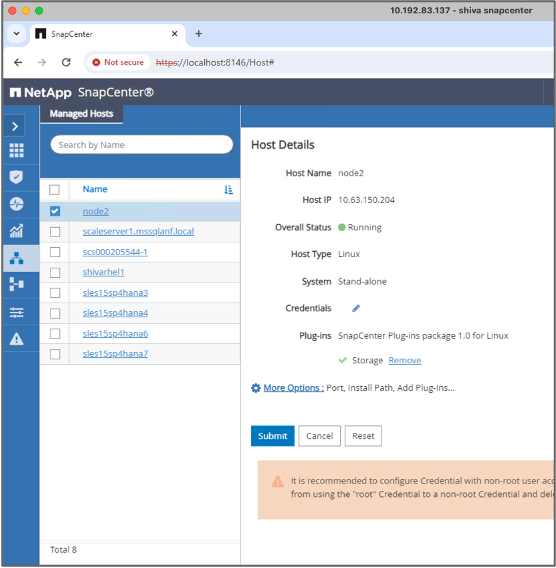
-
Installa e configura il plugin di archiviazione. Dall'host aggiunto, seleziona "Altre opzioni". Passare e selezionare il plug-in di archiviazione scaricato da"Negozio di automazione NetApp" . Installa il plugin e salva la configurazione.
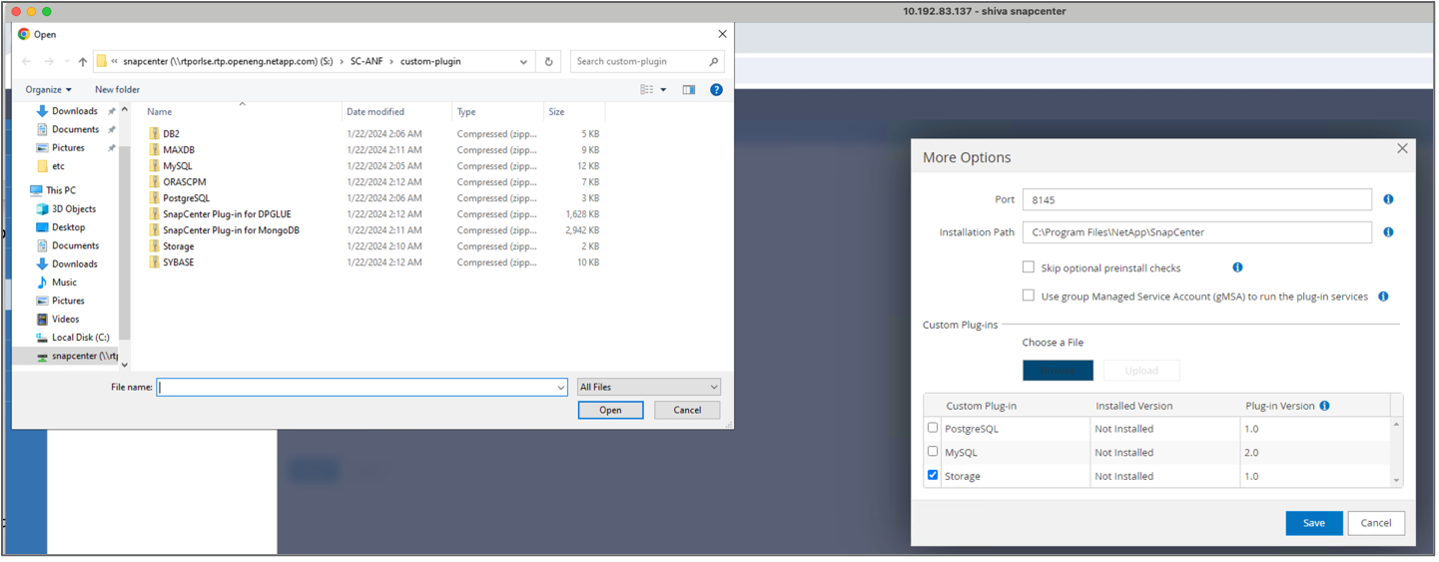
-
Impostare il sistema di archiviazione e il volume: aggiungere il sistema di archiviazione in "Sistema di archiviazione" e selezionare SVM (Storage Virtual Machine). In questo esempio abbiamo scelto "vs_nvidia".
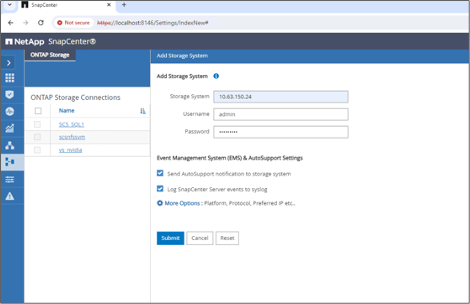
-
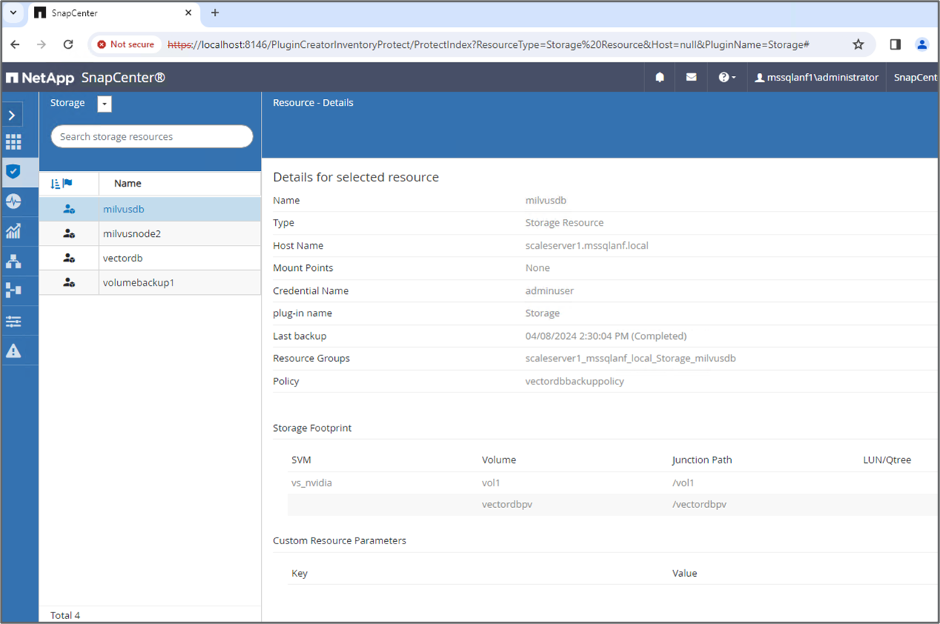
Stabilire una risorsa per il database vettoriale, incorporando una politica di backup e un nome di snapshot personalizzato.
-
Abilita il backup del gruppo di coerenza con i valori predefiniti e abilita SnapCenter senza coerenza del file system.
-
Nella sezione Impronta di archiviazione, selezionare i volumi associati ai dati dei clienti del database vettoriale e ai dati del cluster Milvus. Nel nostro esempio, si tratta di "vol1" e "vectordbpv".
-
Creare una policy per la protezione del database vettoriale e proteggere le risorse del database vettoriale utilizzando la policy.
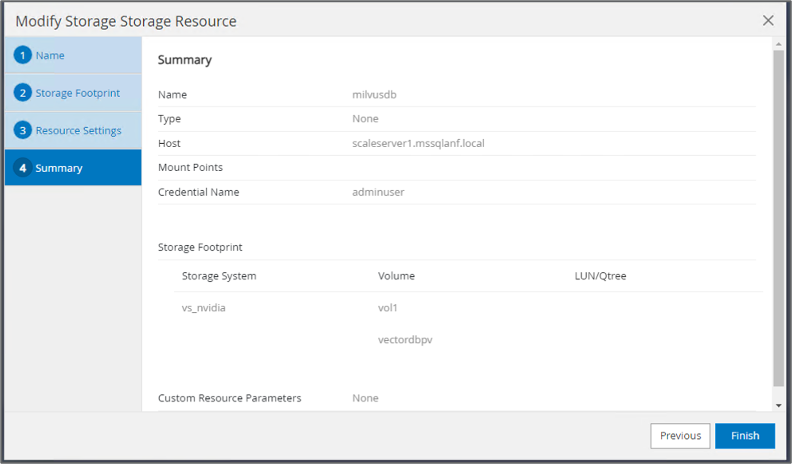
-
-
Inserire i dati nel bucket NAS S3 utilizzando uno script Python. Nel nostro caso, abbiamo modificato lo script di backup fornito da Milvus, ovvero 'prepare_data_netapp.py', ed eseguito il comando 'sync' per eliminare i dati dal sistema operativo.
root@node2:~# python3 prepare_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_test exist in Milvus: False === Create collection `hello_milvus_netapp_sc_test` === === Start inserting entities === Number of entities in hello_milvus_netapp_sc_test: 3000 === Create collection `hello_milvus_netapp_sc_test2` === Number of entities in hello_milvus_netapp_sc_test2: 6000 root@node2:~# for i in 2 3 4 5 6 ; do ssh node$i "hostname; sync; echo 'sync executed';" ; done node2 sync executed node3 sync executed node4 sync executed node5 sync executed node6 sync executed root@node2:~# -
Verificare i dati nel bucket NAS S3. Nel nostro esempio, i file con timestamp '2024-04-08 21:22' sono stati creati dallo script 'prepare_data_netapp.py'.
root@node2:~# aws s3 ls --profile ontaps3 s3://milvusdbvol1/ --recursive | grep '2024-04-08' <output content removed to save page space> 2024-04-08 21:18:14 5656 stats_log/448950615991000809/448950615991000810/448950615991001854/100/1 2024-04-08 21:18:12 5654 stats_log/448950615991000809/448950615991000810/448950615991001854/100/448950615990800869 2024-04-08 21:18:17 5656 stats_log/448950615991000809/448950615991000810/448950615991001872/100/1 2024-04-08 21:18:15 5654 stats_log/448950615991000809/448950615991000810/448950615991001872/100/448950615990800876 2024-04-08 21:22:46 5625 stats_log/448950615991003377/448950615991003378/448950615991003385/100/1 2024-04-08 21:22:45 5623 stats_log/448950615991003377/448950615991003378/448950615991003385/100/448950615990800899 2024-04-08 21:22:49 5656 stats_log/448950615991003408/448950615991003409/448950615991003416/100/1 2024-04-08 21:22:47 5654 stats_log/448950615991003408/448950615991003409/448950615991003416/100/448950615990800906 2024-04-08 21:22:52 5656 stats_log/448950615991003408/448950615991003409/448950615991003434/100/1 2024-04-08 21:22:50 5654 stats_log/448950615991003408/448950615991003409/448950615991003434/100/448950615990800913 root@node2:~# -
Avvia un backup utilizzando lo snapshot del gruppo di coerenza (CG) dalla risorsa 'milvusdb'
-
Per testare la funzionalità di backup, abbiamo aggiunto una nuova tabella dopo il processo di backup oppure abbiamo rimosso alcuni dati dall'NFS (bucket NAS S3).
Per questo test, immagina uno scenario in cui qualcuno ha creato una nuova raccolta non necessaria o inappropriata dopo il backup. In tal caso, dovremmo ripristinare il database vettoriale allo stato in cui si trovava prima dell'aggiunta della nuova raccolta. Ad esempio, sono state inserite nuove raccolte come 'hello_milvus_netapp_sc_testnew' e 'hello_milvus_netapp_sc_testnew2'.
root@node2:~# python3 prepare_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_testnew exist in Milvus: False === Create collection `hello_milvus_netapp_sc_testnew` === === Start inserting entities === Number of entities in hello_milvus_netapp_sc_testnew: 3000 === Create collection `hello_milvus_netapp_sc_testnew2` === Number of entities in hello_milvus_netapp_sc_testnew2: 6000 root@node2:~# -
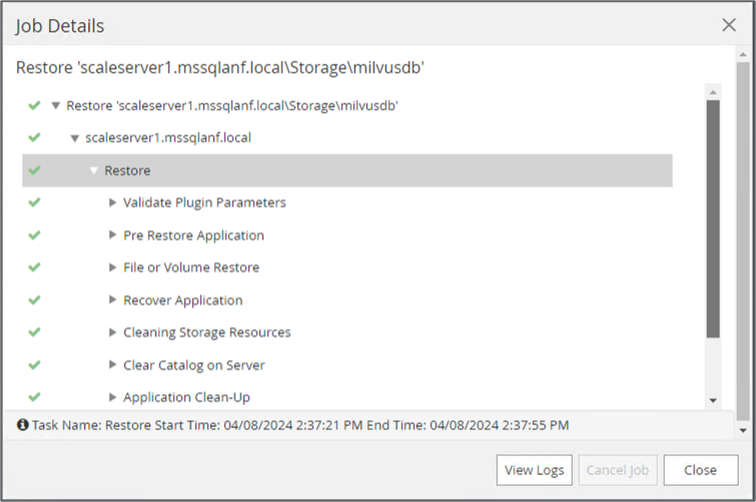
Eseguire un ripristino completo del bucket NAS S3 dallo snapshot precedente.
-
Utilizzare uno script Python per verificare i dati dalle raccolte 'hello_milvus_netapp_sc_test' e 'hello_milvus_netapp_sc_test2'.
root@node2:~# python3 verify_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_test exist in Milvus: True {'auto_id': False, 'description': 'hello_milvus_netapp_sc_test', 'fields': [{'name': 'pk', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': False}, {'name': 'random', 'description': '', 'type': <DataType.DOUBLE: 11>}, {'name': 'var', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535}}, {'name': 'embeddings', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 8}}]} Number of entities in Milvus: hello_milvus_netapp_sc_test : 3000 === Start Creating index IVF_FLAT === === Start loading === === Start searching based on vector similarity === hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911 hit: id: 1262, distance: 0.08883658051490784, entity: {'random': 0.2978858685751561}, random field: 0.2978858685751561 hit: id: 1265, distance: 0.09590047597885132, entity: {'random': 0.3042039939240304}, random field: 0.3042039939240304 hit: id: 2999, distance: 0.0, entity: {'random': 0.02316334456872482}, random field: 0.02316334456872482 hit: id: 1580, distance: 0.05628091096878052, entity: {'random': 0.3855988746044062}, random field: 0.3855988746044062 hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368 search latency = 0.2832s === Start querying with `random > 0.5` === query result: -{'random': 0.6378742006852851, 'embeddings': [0.20963514, 0.39746657, 0.12019053, 0.6947492, 0.9535575, 0.5454552, 0.82360446, 0.21096309], 'pk': 0} search latency = 0.2257s === Start hybrid searching with `random > 0.5` === hit: id: 2998, distance: 0.0, entity: {'random': 0.9728033590489911}, random field: 0.9728033590489911 hit: id: 747, distance: 0.14606499671936035, entity: {'random': 0.5648774800635661}, random field: 0.5648774800635661 hit: id: 2527, distance: 0.1530652642250061, entity: {'random': 0.8928974315571507}, random field: 0.8928974315571507 hit: id: 2377, distance: 0.08096685260534286, entity: {'random': 0.8745922204004368}, random field: 0.8745922204004368 hit: id: 2034, distance: 0.20354536175727844, entity: {'random': 0.5526117606328499}, random field: 0.5526117606328499 hit: id: 958, distance: 0.21908017992973328, entity: {'random': 0.6647383716417955}, random field: 0.6647383716417955 search latency = 0.5480s Does collection hello_milvus_netapp_sc_test2 exist in Milvus: True {'auto_id': True, 'description': 'hello_milvus_netapp_sc_test2', 'fields': [{'name': 'pk', 'description': '', 'type': <DataType.INT64: 5>, 'is_primary': True, 'auto_id': True}, {'name': 'random', 'description': '', 'type': <DataType.DOUBLE: 11>}, {'name': 'var', 'description': '', 'type': <DataType.VARCHAR: 21>, 'params': {'max_length': 65535}}, {'name': 'embeddings', 'description': '', 'type': <DataType.FLOAT_VECTOR: 101>, 'params': {'dim': 8}}]} Number of entities in Milvus: hello_milvus_netapp_sc_test2 : 6000 === Start Creating index IVF_FLAT === === Start loading === === Start searching based on vector similarity === hit: id: 448950615990642008, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990645009, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990640618, distance: 0.13562293350696564, entity: {'random': 0.7864676926688837}, random field: 0.7864676926688837 hit: id: 448950615990642314, distance: 0.10414951294660568, entity: {'random': 0.2209597460821181}, random field: 0.2209597460821181 hit: id: 448950615990645315, distance: 0.10414951294660568, entity: {'random': 0.2209597460821181}, random field: 0.2209597460821181 hit: id: 448950615990640004, distance: 0.11571306735277176, entity: {'random': 0.7765521996186631}, random field: 0.7765521996186631 search latency = 0.2381s === Start querying with `random > 0.5` === query result: -{'embeddings': [0.15983285, 0.72214717, 0.7414838, 0.44471496, 0.50356466, 0.8750043, 0.316556, 0.7871702], 'pk': 448950615990639798, 'random': 0.7820620141382767} search latency = 0.3106s === Start hybrid searching with `random > 0.5` === hit: id: 448950615990642008, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990645009, distance: 0.07805602252483368, entity: {'random': 0.5326684390871348}, random field: 0.5326684390871348 hit: id: 448950615990640618, distance: 0.13562293350696564, entity: {'random': 0.7864676926688837}, random field: 0.7864676926688837 hit: id: 448950615990640004, distance: 0.11571306735277176, entity: {'random': 0.7765521996186631}, random field: 0.7765521996186631 hit: id: 448950615990643005, distance: 0.11571306735277176, entity: {'random': 0.7765521996186631}, random field: 0.7765521996186631 hit: id: 448950615990640402, distance: 0.13665105402469635, entity: {'random': 0.9742541034109935}, random field: 0.9742541034109935 search latency = 0.4906s root@node2:~# -
Verificare che la raccolta non necessaria o inappropriata non sia più presente nel database.
root@node2:~# python3 verify_data_netapp.py === start connecting to Milvus === === Milvus host: localhost === Does collection hello_milvus_netapp_sc_testnew exist in Milvus: False Traceback (most recent call last): File "/root/verify_data_netapp.py", line 37, in <module> recover_collection = Collection(recover_collection_name) File "/usr/local/lib/python3.10/dist-packages/pymilvus/orm/collection.py", line 137, in __init__ raise SchemaNotReadyException( pymilvus.exceptions.SchemaNotReadyException: <SchemaNotReadyException: (code=1, message=Collection 'hello_milvus_netapp_sc_testnew' not exist, or you can pass in schema to create one.)> root@node2:~#
In conclusione, l'utilizzo di SnapCenter di NetApp per salvaguardare i dati del database vettoriale e i dati Milvus residenti in ONTAP offre notevoli vantaggi ai clienti, in particolare nei settori in cui l'integrità dei dati è fondamentale, come la produzione cinematografica. La capacità di SnapCenter di creare backup coerenti ed eseguire ripristini completi dei dati garantisce che i dati critici, come i file video e audio incorporati, siano protetti da perdite dovute a guasti del disco rigido o altri problemi. Ciò non solo previene interruzioni operative, ma tutela anche da perdite finanziarie sostanziali.
In questa sezione abbiamo dimostrato come configurare SnapCenter per proteggere i dati residenti in ONTAP, inclusa la configurazione degli host, l'installazione e la configurazione dei plugin di archiviazione e la creazione di una risorsa per il database vettoriale con un nome snapshot personalizzato. Abbiamo anche mostrato come eseguire un backup utilizzando lo snapshot del Consistency Group e verificare i dati nel bucket NAS S3.
Inoltre, abbiamo simulato uno scenario in cui è stata creata una raccolta non necessaria o inappropriata dopo il backup. In questi casi, la capacità di SnapCenter di eseguire un ripristino completo da uno snapshot precedente garantisce che il database vettoriale possa essere ripristinato allo stato in cui si trovava prima dell'aggiunta della nuova raccolta, mantenendo così l'integrità del database. Questa capacità di ripristinare i dati a un punto specifico nel tempo è di inestimabile valore per i clienti, poiché fornisce loro la garanzia che i loro dati non solo sono protetti, ma anche correttamente mantenuti. Pertanto, il prodotto SnapCenter di NetApp offre ai clienti una soluzione solida e affidabile per la protezione e la gestione dei dati.