

Validazione delle prestazioni del database vettoriale
 Suggerisci modifiche
Suggerisci modifiche
Questa sezione evidenzia la convalida delle prestazioni eseguita sul database vettoriale.
Validazione delle prestazioni
La convalida delle prestazioni svolge un ruolo fondamentale sia nei database vettoriali che nei sistemi di archiviazione, fungendo da fattore chiave per garantire un funzionamento ottimale e un utilizzo efficiente delle risorse. I database vettoriali, noti per la gestione di dati ad alta dimensionalità e l'esecuzione di ricerche di similarità, devono mantenere elevati livelli di prestazioni per elaborare query complesse in modo rapido e accurato. La convalida delle prestazioni aiuta a identificare i colli di bottiglia, a perfezionare le configurazioni e a garantire che il sistema possa gestire i carichi previsti senza degradazione del servizio. Allo stesso modo, nei sistemi di archiviazione, la convalida delle prestazioni è essenziale per garantire che i dati vengano archiviati e recuperati in modo efficiente, senza problemi di latenza o colli di bottiglia che potrebbero influire sulle prestazioni complessive del sistema. Aiuta inoltre a prendere decisioni consapevoli sugli aggiornamenti o le modifiche necessarie all'infrastruttura di storage. Pertanto, la convalida delle prestazioni è un aspetto cruciale della gestione del sistema, contribuendo in modo significativo al mantenimento di un'elevata qualità del servizio, dell'efficienza operativa e dell'affidabilità complessiva del sistema.
In questa sezione, ci proponiamo di approfondire la convalida delle prestazioni dei database vettoriali, come Milvus e pgvecto.rs, concentrandoci sulle caratteristiche delle prestazioni di storage, come il profilo I/O e il comportamento del controller di storage NetApp a supporto dei carichi di lavoro RAG e di inferenza all'interno del ciclo di vita LLM. Valuteremo e identificheremo eventuali fattori differenzianti nelle prestazioni quando questi database saranno combinati con la soluzione di archiviazione ONTAP . La nostra analisi si baserà su indicatori chiave di prestazione, come il numero di query elaborate al secondo (QPS).
Si prega di controllare la metodologia utilizzata per milvus e i progressi di seguito.
Dettagli |
Milvus (autonomo e cluster) |
Postgres(pgvecto.rs) # |
versione |
2.3.2 |
0.2.0 |
File system |
XFS su LUN iSCSI |
|
Generatore di carico di lavoro |
"VectorDB-Bench"– v0.0.5 |
|
Set di dati |
Dataset LAION * 10 milioni di incorporamenti * 768 dimensioni * dimensione del dataset ~300 GB |
|
Controllore di archiviazione |
AFF 800 * Versione – 9.14.1 * 4 x 100GbE – per milvus e 2x 100GbE per postgres * iscsi |
VectorDB-Bench con cluster autonomo Milvus
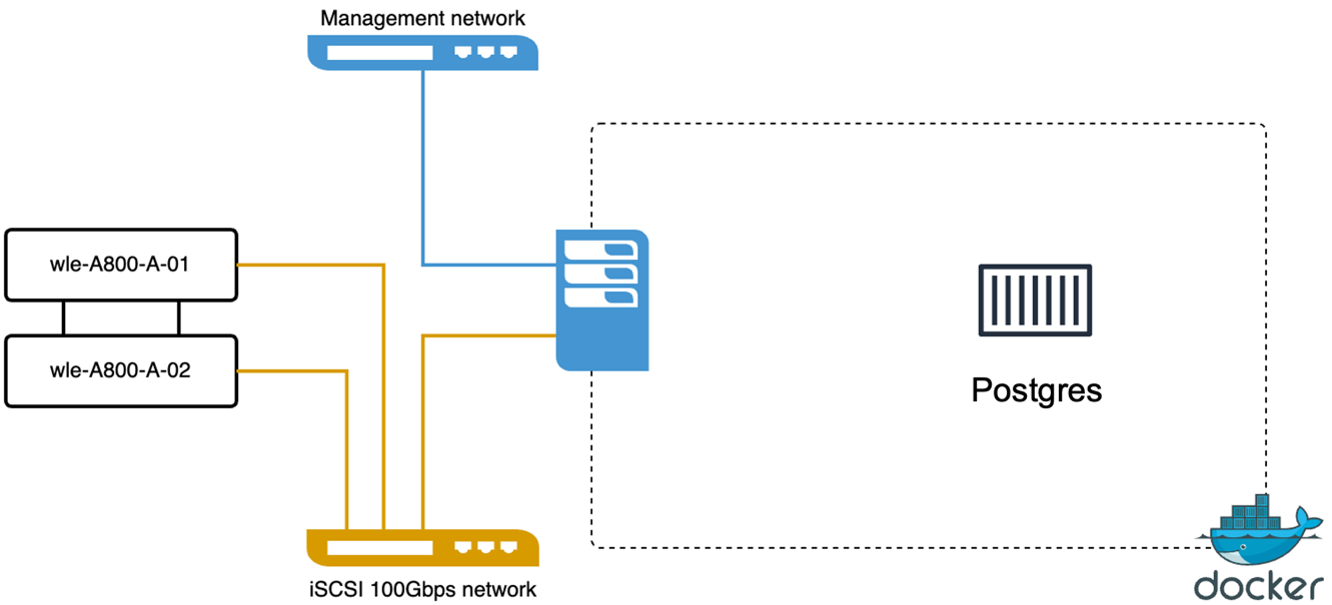
abbiamo eseguito la seguente convalida delle prestazioni sul cluster autonomo Milvus con vectorDB-Bench. Di seguito è riportata la connettività di rete e server del cluster autonomo Milvus.
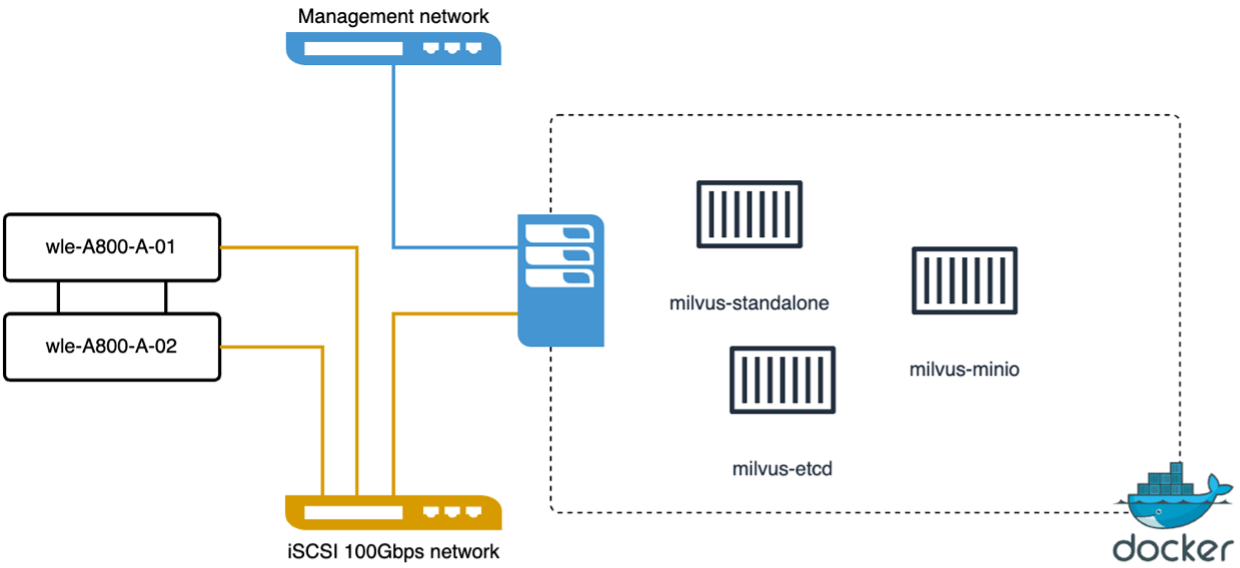
In questa sezione condividiamo le nostre osservazioni e i risultati ottenuti testando il database autonomo Milvus. . Abbiamo selezionato DiskANN come tipo di indice per questi test. . L'acquisizione, l'ottimizzazione e la creazione di indici per un set di dati di circa 100 GB hanno richiesto circa 5 ore. Per la maggior parte di questa durata, il server Milvus, dotato di 20 core (che equivalgono a 40 vCPU quando Hyper-Threading è abilitato), ha funzionato alla massima capacità della CPU, pari al 100%. Abbiamo scoperto che DiskANN è particolarmente importante per i set di dati di grandi dimensioni che superano le dimensioni della memoria di sistema. . Nella fase di query, abbiamo osservato un tasso di query al secondo (QPS) pari a 10,93 con un richiamo pari a 0,9987. La latenza del 99° percentile per le query è stata misurata a 708,2 millisecondi.
Dal punto di vista dell'archiviazione, il database ha eseguito circa 1.000 operazioni al secondo durante le fasi di acquisizione, ottimizzazione post-inserimento e creazione dell'indice. Nella fase di query, sono state richieste 32.000 operazioni al secondo.
Nella sezione seguente vengono presentate le metriche delle prestazioni di archiviazione.
| Fase di carico di lavoro | Metrico | Valore |
|---|---|---|
Inserimento dei dati e ottimizzazione post-inserimento |
IOPS |
< 1.000 |
Latenza |
< 400 usecs |
|
Carico di lavoro |
Mix di lettura/scrittura, per lo più scrive |
|
dimensione IO |
64 KB |
|
Domanda |
IOPS |
Picco a 32.000 |
Latenza |
< 400 usecs |
|
Carico di lavoro |
Lettura cache al 100% |
|
dimensione IO |
Principalmente 8 KB |
Di seguito è riportato il risultato di vectorDB-bench.
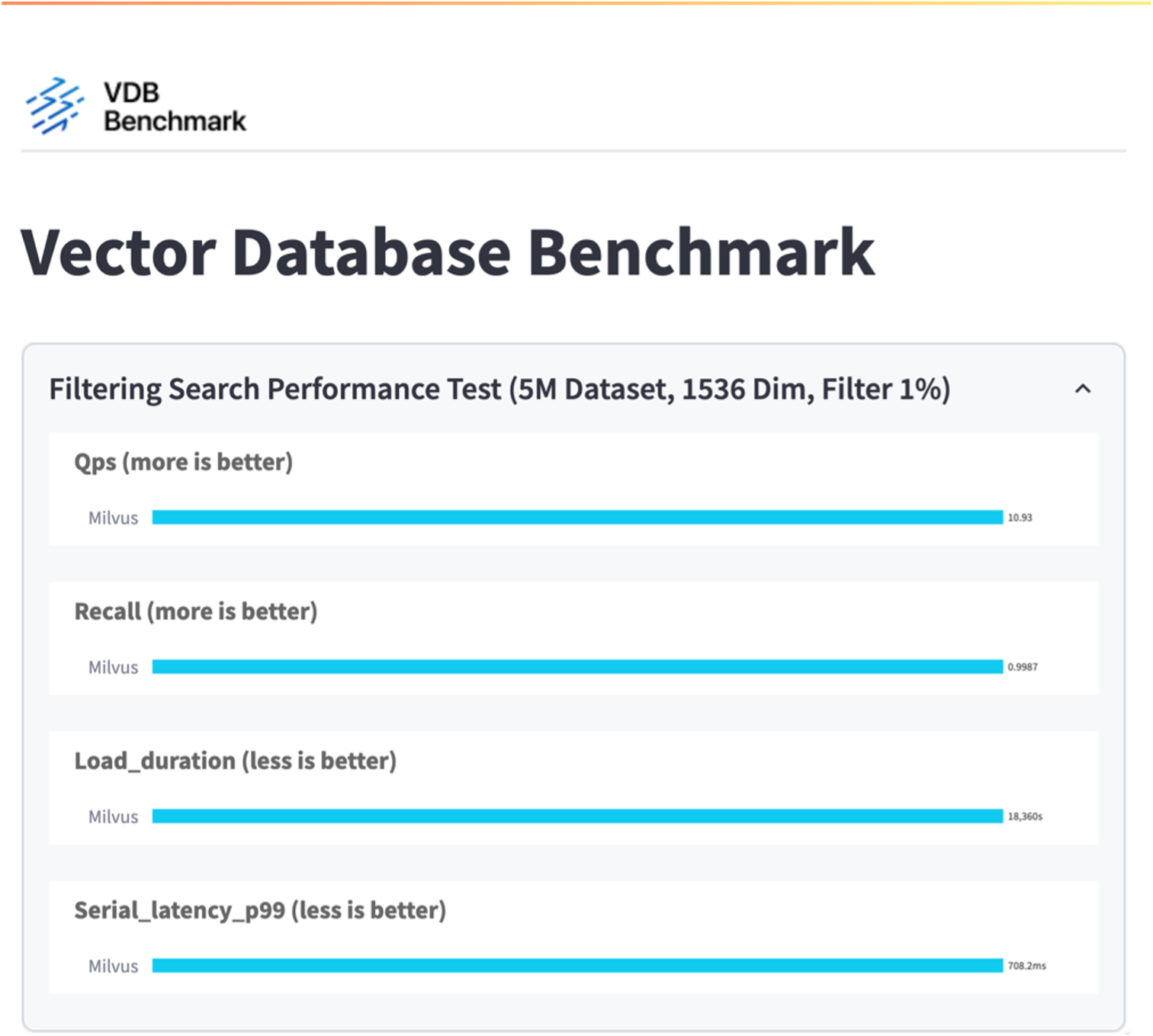
Dalla convalida delle prestazioni dell'istanza Milvus autonoma, è evidente che la configurazione attuale non è sufficiente a supportare un set di dati di 5 milioni di vettori con una dimensionalità di 1536. Abbiamo stabilito che lo storage dispone di risorse adeguate e non costituisce un collo di bottiglia nel sistema.
VectorDB-Bench con cluster Milvus
In questa sezione, discuteremo l'implementazione di un cluster Milvus all'interno di un ambiente Kubernetes. Questa configurazione di Kubernetes è stata realizzata su una distribuzione VMware vSphere, che ospitava i nodi master e worker di Kubernetes.
I dettagli delle distribuzioni VMware vSphere e Kubernetes sono presentati nelle sezioni seguenti.
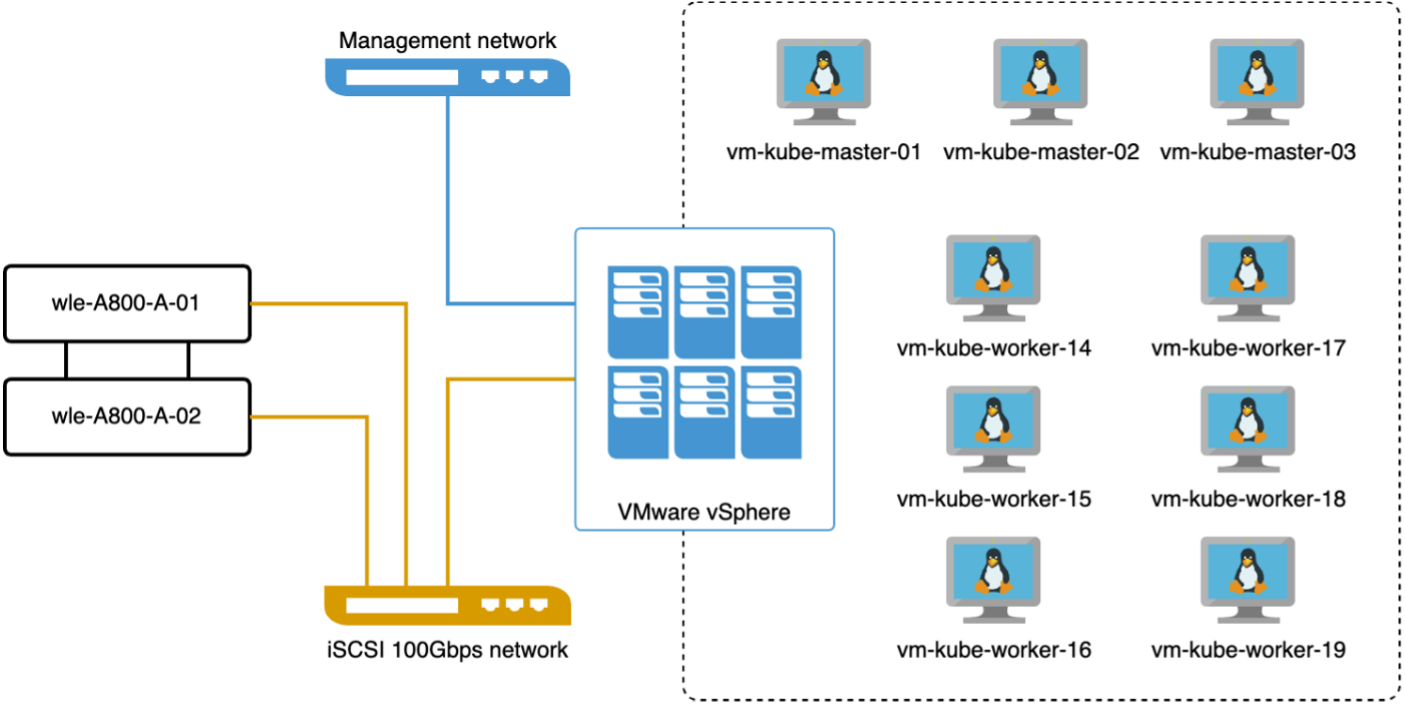
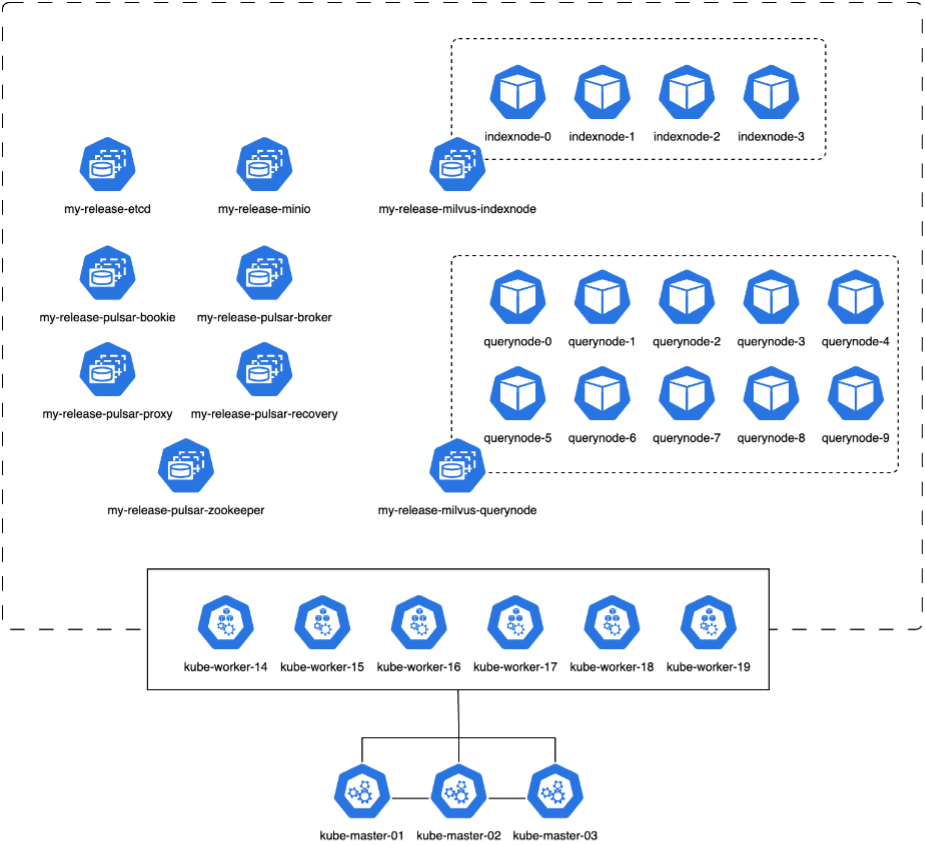
In questa sezione presentiamo le nostre osservazioni e i risultati ottenuti testando il database Milvus. * Il tipo di indice utilizzato era DiskANN. * La tabella seguente fornisce un confronto tra le distribuzioni standalone e cluster quando si lavora con 5 milioni di vettori con una dimensionalità di 1536. Abbiamo osservato che il tempo impiegato per l'acquisizione dei dati e l'ottimizzazione post-inserimento era inferiore nella distribuzione del cluster. La latenza del 99° percentile per le query è stata ridotta di sei volte nella distribuzione del cluster rispetto alla configurazione autonoma. * Sebbene la frequenza delle query al secondo (QPS) fosse più elevata nella distribuzione del cluster, non era al livello desiderato.

Le immagini sottostanti forniscono una panoramica di varie metriche di archiviazione, tra cui la latenza del cluster di archiviazione e gli IOPS totali (operazioni di input/output al secondo).
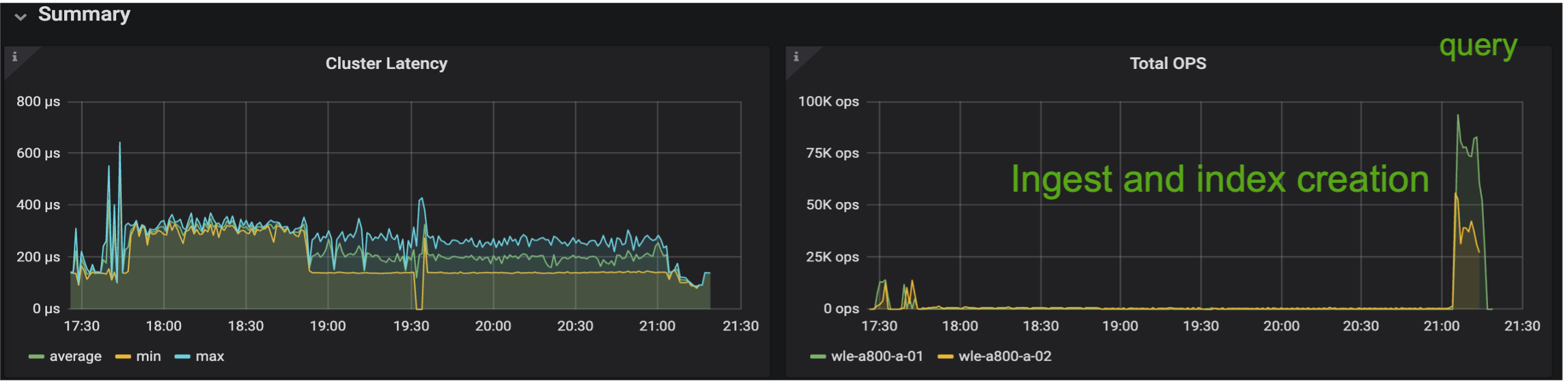
Nella sezione seguente vengono presentate le principali metriche relative alle prestazioni di archiviazione.
| Fase di carico di lavoro | Metrico | Valore |
|---|---|---|
Inserimento dei dati e ottimizzazione post-inserimento |
IOPS |
< 1.000 |
Latenza |
< 400 usecs |
|
Carico di lavoro |
Mix di lettura/scrittura, per lo più scrive |
|
dimensione IO |
64 KB |
|
Domanda |
IOPS |
Picco a 147.000 |
Latenza |
< 400 usecs |
|
Carico di lavoro |
Lettura cache al 100% |
|
dimensione IO |
Principalmente 8 KB |
Sulla base della convalida delle prestazioni sia del Milvus autonomo che del cluster Milvus, presentiamo i dettagli del profilo I/O di archiviazione. * Abbiamo osservato che il profilo I/O rimane coerente sia nelle distribuzioni autonome che in quelle cluster. * La differenza osservata nei picchi di IOPS può essere attribuita al numero maggiore di client nella distribuzione del cluster.
vectorDB-Bench con Postgres (pgvecto.rs)
Abbiamo eseguito le seguenti azioni su PostgreSQL (pgvecto.rs) utilizzando VectorDB-Bench: i dettagli riguardanti la connettività di rete e del server di PostgreSQL (in particolare, pgvecto.rs) sono i seguenti:
In questa sezione condividiamo le nostre osservazioni e i risultati ottenuti testando il database PostgreSQL, in particolare utilizzando pgvecto.rs. * Abbiamo selezionato HNSW come tipo di indice per questi test perché al momento del test, DiskANN non era disponibile per pgvecto.rs. * Durante la fase di acquisizione dei dati, abbiamo caricato il dataset Cohere, composto da 10 milioni di vettori con una dimensionalità di 768. Questo processo ha richiesto circa 4,5 ore. * Nella fase di query, abbiamo osservato un tasso di query al secondo (QPS) di 1.068 con un richiamo di 0,6344. La latenza del 99° percentile per le query è stata misurata a 20 millisecondi. Per la maggior parte del tempo di esecuzione, la CPU del client ha funzionato al 100% della sua capacità.
Le immagini sottostanti forniscono una panoramica di varie metriche di archiviazione, tra cui la latenza totale del cluster di archiviazione IOPS (operazioni di input/output al secondo).

The following section presents the key storage performance metrics. image:pgvecto-storage-perf-metrics.png["Figura che mostra il dialogo di input/output o che rappresenta il contenuto scritto"]
Confronto delle prestazioni tra Milvus e Postgres su Vector DB Bench
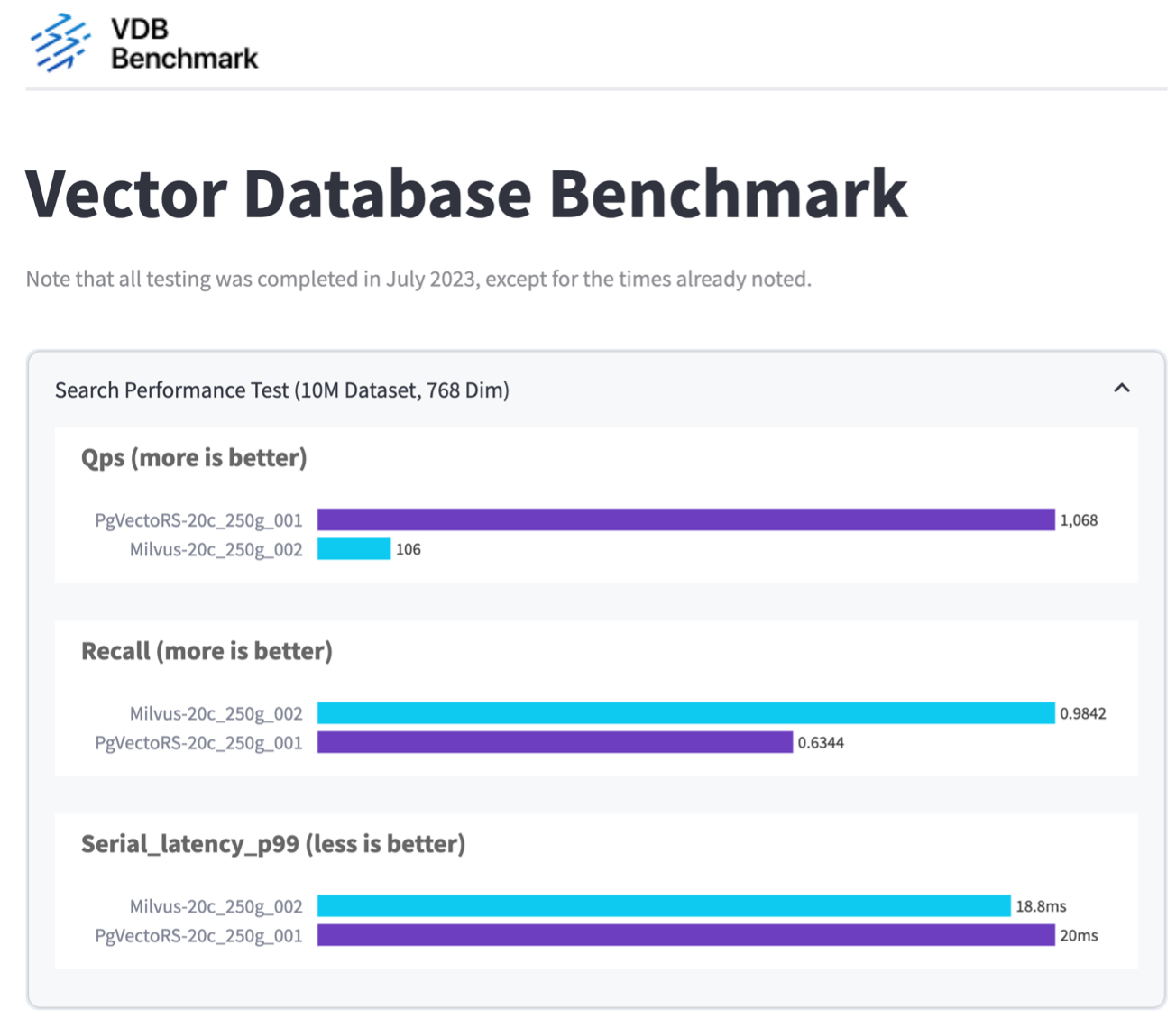
Sulla base della nostra convalida delle prestazioni di Milvus e PostgreSQL utilizzando VectorDBBench, abbiamo osservato quanto segue:
-
Tipo di indice: HNSW
-
Dataset: Cohere con 10 milioni di vettori a 768 dimensioni
Abbiamo scoperto che pgvecto.rs ha raggiunto un tasso di query al secondo (QPS) di 1.068 con un richiamo di 0,6344, mentre Milvus ha raggiunto un tasso di QPS di 106 con un richiamo di 0,9842.
Se l'elevata precisione nelle tue query è una priorità, Milvus supera pgvecto.rs in quanto recupera una percentuale maggiore di elementi pertinenti per query. Tuttavia, se il numero di query al secondo è un fattore più cruciale, pgvecto.rs supera Milvus. È importante notare, tuttavia, che la qualità dei dati recuperati tramite pgvecto.rs è inferiore, con circa il 37% dei risultati di ricerca costituiti da elementi irrilevanti.
Osservazione basata sulle nostre convalide delle prestazioni:
Sulla base delle nostre convalide delle prestazioni, abbiamo fatto le seguenti osservazioni:
In Milvus, il profilo I/O assomiglia molto a un carico di lavoro OLTP, come quello visto con Oracle SLOB. Il benchmark è composto da tre fasi: acquisizione dei dati, post-ottimizzazione e query. Le fasi iniziali sono caratterizzate principalmente da operazioni di scrittura da 64 KB, mentre la fase di query prevede prevalentemente letture da 8 KB. Ci aspettiamo che ONTAP gestisca in modo efficiente il carico I/O Milvus.
Il profilo I/O di PostgreSQL non presenta un carico di lavoro di archiviazione impegnativo. Considerata l'implementazione in memoria attualmente in corso, non abbiamo osservato alcun I/O su disco durante la fase di query.
DiskANN emerge come una tecnologia cruciale per la differenziazione dello storage. Consente di ridimensionare in modo efficiente la ricerca nel database vettoriale oltre i limiti della memoria di sistema. Tuttavia, è improbabile che si possa stabilire una differenziazione delle prestazioni di archiviazione con indici DB vettoriali in memoria come HNSW.
Vale anche la pena notare che l'archiviazione non gioca un ruolo critico durante la fase di query quando il tipo di indice è HSNW, che è la fase operativa più importante per i database vettoriali che supportano le applicazioni RAG. Ciò implica che le prestazioni di archiviazione non hanno un impatto significativo sulle prestazioni complessive di queste applicazioni.