

Casi d'uso del database vettoriale
 Suggerisci modifiche
Suggerisci modifiche
Questa sezione fornisce una panoramica dei casi d'uso per la soluzione di database vettoriale NetApp .
Casi d'uso del database vettoriale
In questa sezione, discuteremo di due casi d'uso quali Retrieval Augmented Generation con modelli linguistici di grandi dimensioni e NetApp IT chatbot.
Generazione aumentata del recupero (RAG) con modelli linguistici di grandi dimensioni (LLM)
Retrieval-augmented generation, or RAG, is a technique for enhancing the accuracy and reliability of Large Language Models, or LLMs, by augmenting prompts with facts fetched from external sources. In a traditional RAG deployment, vector embeddings are generated from an existing dataset and then stored in a vector database, often referred to as a knowledgebase. Whenever a user submits a prompt to the LLM, a vector embedding representation of the prompt is generated, and the vector database is searched using that embedding as the search query. This search operation returns similar vectors from the knowledgebase, which are then fed to the LLM as context alongside the original user prompt. In this way, an LLM can be augmented with additional information that was not part of its original training dataset.
NVIDIA Enterprise RAG LLM Operator è uno strumento utile per implementare RAG in azienda. Questo operatore può essere utilizzato per distribuire una pipeline RAG completa. La pipeline RAG può essere personalizzata per utilizzare Milvus o pgvecto come database vettoriale per l'archiviazione degli incorporamenti della knowledge base. Per i dettagli, fare riferimento alla documentazione.
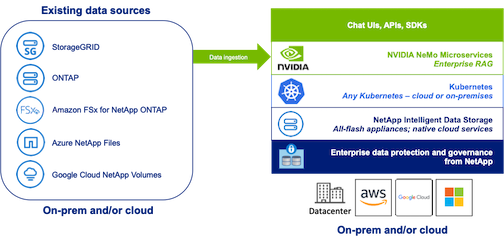
NetApp has validated an enterprise RAG architecture powered by the NVIDIA Enterprise RAG LLM Operator alongside NetApp storage. Refer to our blog post for more information and to see a demo. Figure 1 provides an overview of this architecture.
Figura 1) Enterprise RAG basato su NVIDIA NeMo Microservices e NetApp
Caso d'uso del chatbot IT NetApp
Il chatbot di NetApp rappresenta un ulteriore caso d'uso in tempo reale per il database vettoriale. In questo caso, NetApp Private OpenAI Sandbox fornisce una piattaforma efficace, sicura ed efficiente per la gestione delle query degli utenti interni di NetApp. Integrando rigorosi protocolli di sicurezza, efficienti sistemi di gestione dei dati e sofisticate capacità di elaborazione dell'intelligenza artificiale, garantisce risposte precise e di alta qualità agli utenti in base ai loro ruoli e responsabilità nell'organizzazione tramite autenticazione SSO. Questa architettura mette in luce il potenziale dell'unione di tecnologie avanzate per creare sistemi intelligenti e incentrati sull'utente.
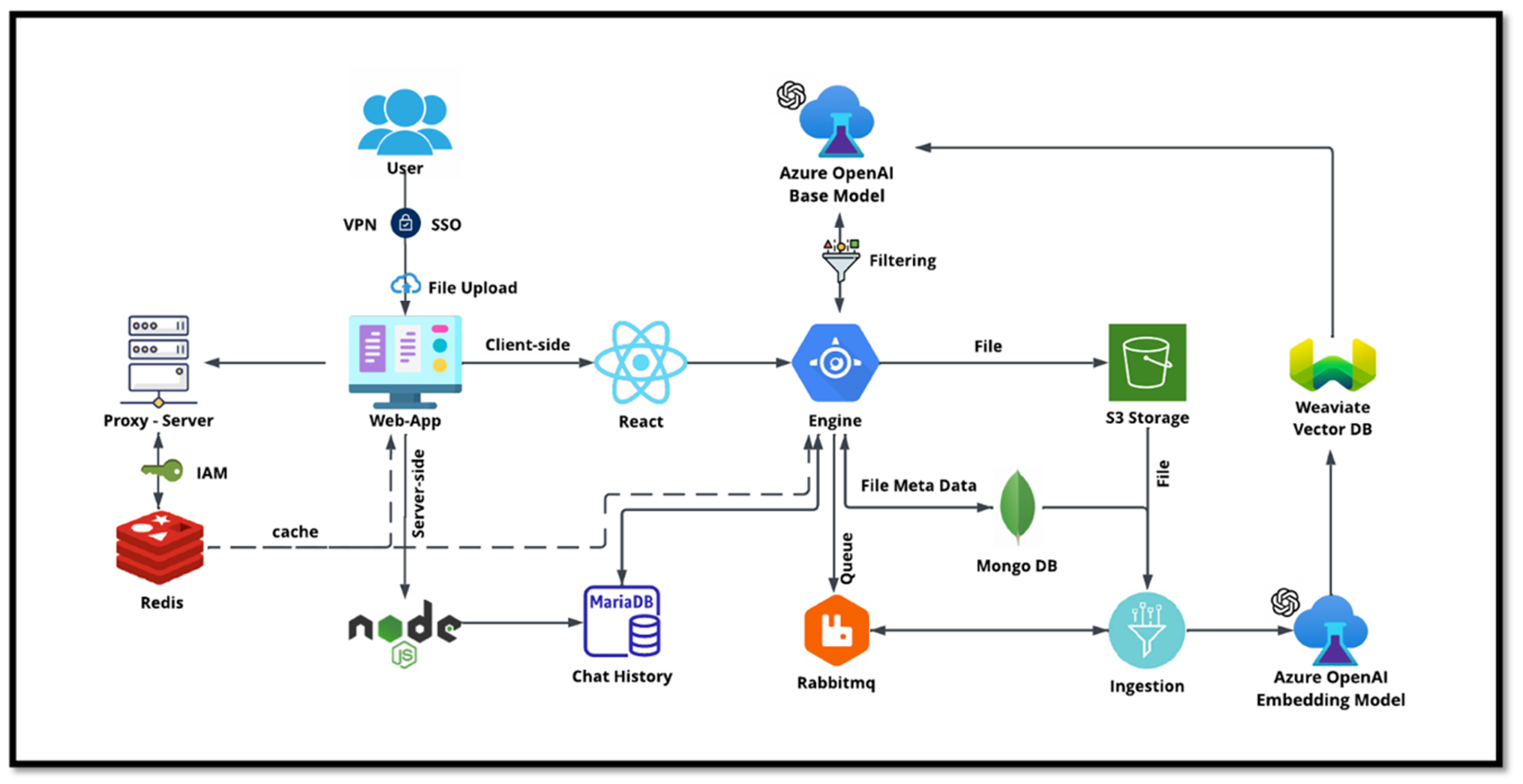
Il caso d'uso può essere suddiviso in quattro sezioni principali.
Autenticazione e verifica dell'utente:
-
Le query degli utenti vengono prima sottoposte al processo NetApp Single Sign-On (SSO) per confermare l'identità dell'utente.
-
Dopo l'autenticazione avvenuta con successo, il sistema controlla la connessione VPN per garantire una trasmissione sicura dei dati.
Trasmissione ed elaborazione dei dati:
-
Una volta convalidata la VPN, i dati vengono inviati a MariaDB tramite le applicazioni web NetAIChat o NetAICreate. MariaDB è un sistema di database veloce ed efficiente utilizzato per gestire e archiviare i dati degli utenti.
-
MariaDB invia quindi le informazioni all'istanza NetApp Azure, che collega i dati dell'utente all'unità di elaborazione AI.
Interazione con OpenAI e filtraggio dei contenuti:
-
L'istanza di Azure invia le domande dell'utente a un sistema di filtraggio dei contenuti. Questo sistema pulisce la query e la prepara per l'elaborazione.
-
L'input ripulito viene quindi inviato al modello base di Azure OpenAI, che genera una risposta in base all'input.
Generazione e moderazione delle risposte:
-
La risposta del modello base viene prima verificata per garantire che sia accurata e soddisfi gli standard di contenuto.
-
Dopo aver superato il controllo, la risposta viene inviata all'utente. Questo processo garantisce che l'utente riceva una risposta chiara, accurata e appropriata alla sua domanda.