

Tracciabilità tra set di dati e modelli con NetApp e MLflow
 Suggerisci modifiche
Suggerisci modifiche
https://github.com/NetApp/netapp-dataops-toolkit/tree/main/netapp_dataops_k8s["NetApp DataOps Toolkit per Kubernetes"^]Può essere utilizzato insieme alle funzionalità di tracciamento degli esperimenti di MLflow per implementare la tracciabilità da codice a set di dati, da set di dati a modello o da spazio di lavoro a modello.
Nel notebook di esempio sono state utilizzate le seguenti librerie:
Prerequisiti
Per implementare la tracciabilità tra modello e set di dati di codice o spazio di lavoro e modello, è sufficiente creare uno snapshot del set di dati o del volume dell'area di lavoro utilizzando DataOps Toolkit come parte dell'esecuzione della formazione, come illustrato nel seguente frammento di codice di esempio. Questo codice salverà il nome del volume di dati e il nome dello snapshot come tag associati alla sequenza di training specifica che si sta accedendo al server di tracciamento degli esperimenti MLflow.
...
from netapp_dataops.k8s import cloneJupyterLab, createJupyterLab, deleteJupyterLab, \
listJupyterLabs, createJupyterLabSnapshot, listJupyterLabSnapshots, restoreJupyterLabSnapshot, \
cloneVolume, createVolume, deleteVolume, listVolumes, createVolumeSnapshot, \
deleteVolumeSnapshot, listVolumeSnapshots, restoreVolumeSnapshot
mlflow.set_tracking_uri("<your_tracking_server_uri>>:<port>>")
os.environ['MLFLOW_HTTP_REQUEST_TIMEOUT'] = '500' # Increase to 500 seconds
mlflow.set_experiment(experiment_id)
with mlflow.start_run() as run:
latest_run_id = run.info.run_id
start_time = datetime.now()
# Preprocess the data
preprocess(input_pdf_file_path, to_be_cleaned_input_file_path)
# Print out sensitive data (passwords, SECRET_TOKEN, API_KEY found)
check_pretrain(to_be_cleaned_input_file_path)
# Tokenize the input file
pretrain_tokenization(to_be_cleaned_input_file_path, model_name, tokenized_output_file_path)
# Load the tokenizer and model
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name)
# Set the pad token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_special_tokens({'pad_token': '[PAD]'})
# Encode, generate, and decode the text
with open(tokenized_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
encode_generate_decode(content, decoded_output_file_path, tokenizer=tokenizer, model=model)
# Save the model
model.save_pretrained(model_save_path)
tokenizer.save_pretrained(model_save_path)
# Finetuning here
with open(decoded_output_file_path, 'r', encoding='utf-8') as file:
content = file.read()
model.finetune(content, tokenizer=tokenizer, model=model)
# Evaluate the model using NLTK
output_set = Dataset.from_dict({"text": [content]})
test_set = Dataset.from_dict({"text": [content]})
scores = nltk_evaluation_gpt(output_set, test_set, model=model, tokenizer=tokenizer)
print(f"Scores: {scores}")
# End time and elapsed time
end_time = datetime.now()
elapsed_time = end_time - start_time
elapsed_minutes = elapsed_time.total_seconds() // 60
elapsed_seconds = elapsed_time.total_seconds() % 60
# Create DOTK snapshots for code, dataset, and model
snapshot = createVolumeSnapshot(pvcName="model-pvc", namespace="default", printOutput=True)
#Log snapshot IDs to MLflow
mlflow.log_param("code_snapshot_id", snapshot)
mlflow.log_param("dataset_snapshot_id", snapshot)
mlflow.log_param("model_snapshot_id", snapshot)
# Log parameters and metrics to MLflow
mlflow.log_param("wf_start_time", start_time)
mlflow.log_param("wf_end_time", end_time)
mlflow.log_param("wf_elapsed_time_minutes", elapsed_minutes)
mlflow.log_param("wf_elapsed_time_seconds", elapsed_seconds)
mlflow.log_artifact(decoded_output_file_path.rsplit('/', 1)[0]) # Remove the filename to log the directory
mlflow.log_artifact(model_save_path) # log the model save path
print(f"Experiment ID: {experiment_id}")
print(f"Run ID: {latest_run_id}")
print(f"Elapsed time: {elapsed_minutes} minutes and {elapsed_seconds} seconds")Il frammento di codice sopra riportato registra gli ID snapshot nel server di tracciamento degli esperimenti MLflow, che può essere utilizzato per risalire al dataset e al modello specifici utilizzati per addestrare il modello. In questo modo è possibile risalire al dataset e al modello specifici utilizzati per addestrare il modello, nonché al codice specifico utilizzato per pre-elaborare i dati, eseguire il token del file di input, caricare il token e il modello, codificare, generare e decodificare il testo, salvare il modello, rifinire il modello, valutare il modello utilizzando "NLTK"i punteggi di perplessità e registrare gli iperparametri e le metriche in MLflow. Per esempio, la figura seguente mostra l'errore medio-quadrato (MSE) di un modello di scikit-apprendimento per diverse esecuzioni di esperimenti:

È semplice per l'analisi dei dati, per i proprietari delle line-of-business e per i dirigenti capire e capire quale modello funziona al meglio in particolari vincoli, impostazioni, periodi di tempo e altre circostanze. Per ulteriori dettagli su come preelaborare, tokenizzare, caricare, codificare, generare, decodificare, salvare, finetune e valutare il modello, fare riferimento all' dotk-mlflow`esempio Python nel `netapp_dataops.k8s repository.
Per ulteriori informazioni su come creare istantanee del dataset o dell'area di lavoro JupyterLab, fare riferimento alla "Pagina del toolkit DataOps NetApp".
Per quanto riguarda i modelli che sono stati addestrati, i seguenti modelli sono stati utilizzati nel notebook dotk-mlflow:
Modelli
-
"GPT2LMHeadModel": Il trasformatore modello GPT2 con una testa di modellazione del linguaggio in alto (strato lineare con pesi legati alle incisioni di ingresso). Si tratta di un modello di trasformatore che è stato preformato su un grande corpus di dati di testo e sottoposto a finetuning su un set di dati specifico. Abbiamo utilizzato il modello GPT2 predefinito "maschera di attenzione"per batch di sequenze di input con il token corrispondente per il modello scelto.
-
"Phi-2": Phi-2 è un trasformatore con 2,7 miliardi di parametri. È stato addestrato usando le stesse fonti di dati di Phi-1,5, aumentato con una nuova fonte di dati che consiste di vari testi sintetici di NLP e siti web filtrati (per la sicurezza e il valore educativo).
-
"XLNet (modello basato sulle dimensioni)": Modello XLNet preformato in lingua inglese. Fu introdotto nel documento "XLNet: Preformazione autoregressiva generalizzata per la comprensione delle lingue" da Yang et al. E pubblicato per la prima volta in questo "repository".
Il risultato "Registro del modello in MLflow"conterrà i seguenti modelli, versioni e tag di foresta casuali:
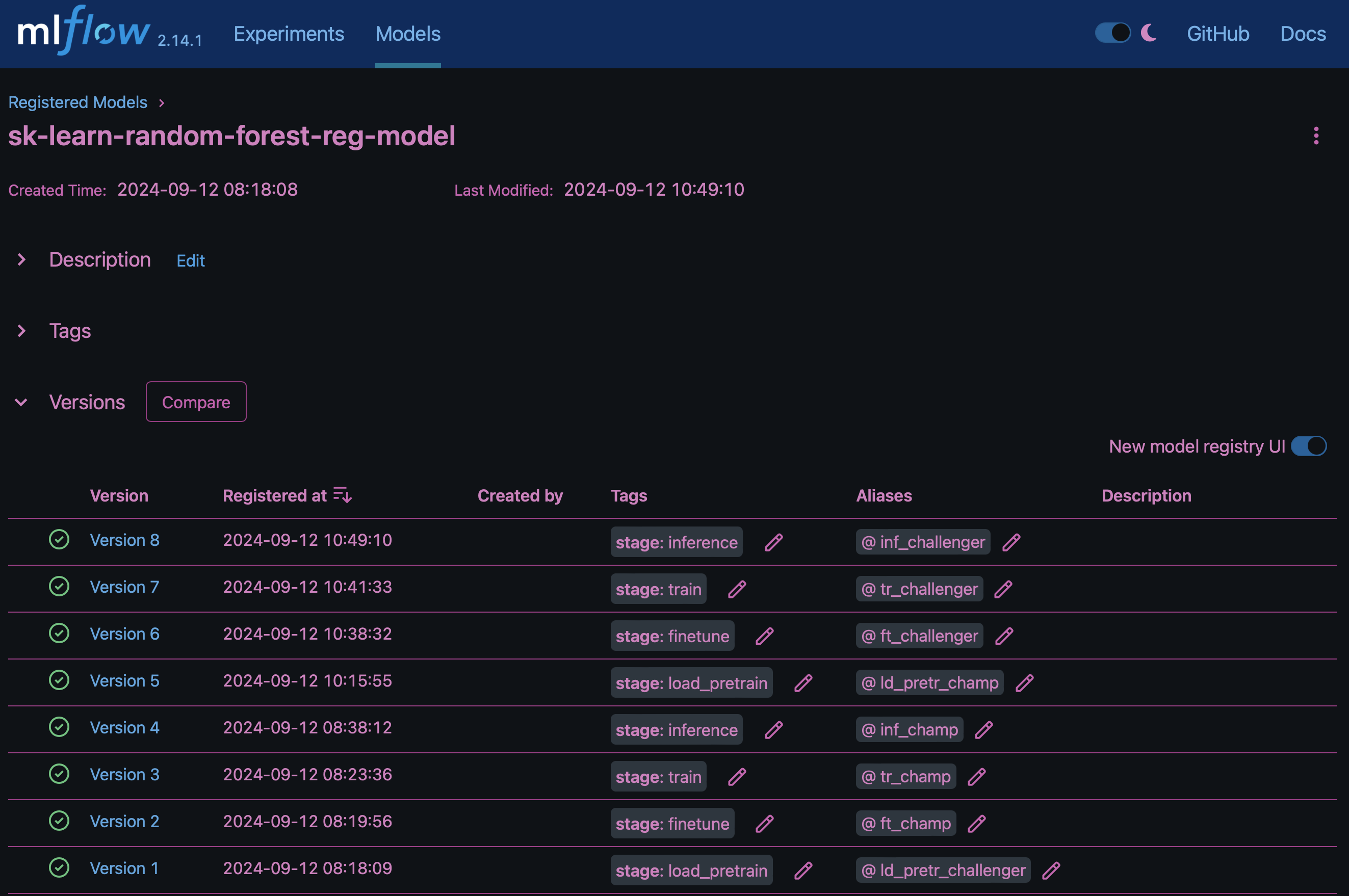
Per implementare il modello in un server di inferenza tramite Kubernetes, esegui semplicemente il seguente notebook Jupyter. Si noti che in questo esempio dotk-mlflow, invece di utilizzare il pacchetto, si sta modificando l'architettura del modello di regressione della foresta casuale per ridurre al minimo l'errore MSE (Mean-Squared Error) nel modello iniziale, e quindi si creano più versioni di tale modello nel Registro dei modelli.
from mlflow.models import Model
mlflow.set_tracking_uri("http://<tracking_server_URI_with_port>")
experiment_id='<your_specified_exp_id>'
# Alternatively, you can load the Model object from a local MLmodel file
# model1 = Model.load("~/path/to/my/MLmodel")
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
from mlflow.models import infer_signature
# Create a new experiment and get its ID
experiment_id = mlflow.create_experiment(experiment_id)
# Or fetch the ID of the existing experiment
# experiment_id = mlflow.get_experiment_by_name("<your_specified_exp_id>").experiment_id
with mlflow.start_run(experiment_id=experiment_id) as run:
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
params = {"max_depth": 2, "random_state": 42}
model = RandomForestRegressor(**params)
model.fit(X_train, y_train)
# Infer the model signature
y_pred = model.predict(X_test)
signature = infer_signature(X_test, y_pred)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
mlflow.log_metrics({"mse": mean_squared_error(y_test, y_pred)})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=model,
artifact_path="sklearn-model",
signature=signature,
registered_model_name="sk-learn-random-forest-reg-model",
)Il risultato dell'esecuzione della cella del notebook Jupyter deve essere simile al seguente, con il modello registrato come versione 3 nel Registro di modello:
Registered model 'sk-learn-random-forest-reg-model' already exists. Creating a new version of this model... 2024/09/12 15:23:36 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: sk-learn-random-forest-reg-model, version 3 Created version '3' of model 'sk-learn-random-forest-reg-model'.
Nel Registro dei modelli, dopo aver salvato i modelli, le versioni e i tag desiderati, è possibile risalire al dataset, al modello e al codice specifici utilizzati per addestrare il modello, nonché al codice specifico utilizzato per elaborare i dati, caricare il token e il modello, codificare, generare e decodificare il testo, salvare il modello, finetune il modello, valutare il modello utilizzando NLTK Jperplexity e altri parametri snapshot_id's and your chosen metrics to MLflow by choosing the corerct experiment under `mlrun a discesa Hub:
Analogamente, per i nostri phi-2_finetuned_model i cui pesi quantizzati sono stati calcolati tramite GPU o vGPU utilizzando la torch libreria, possiamo esaminare i seguenti artefatti intermedi, che consentirebbero l'ottimizzazione delle prestazioni, la scalabilità (throughput/SLA gaurantee) e la riduzione dei costi dell'intero flusso di lavoro:
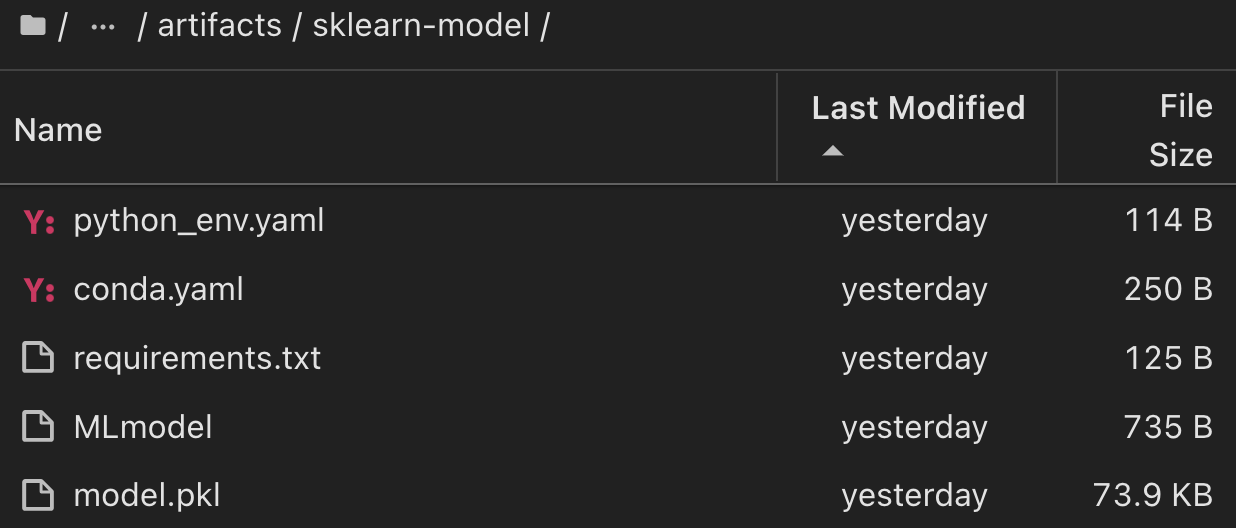
Per un singolo esperimento eseguito utilizzando Scikit-learn e MLflow, la figura seguente mostra gli artefatti generati, conda l'ambiente, MLmodel il file e la MLmodel directory:
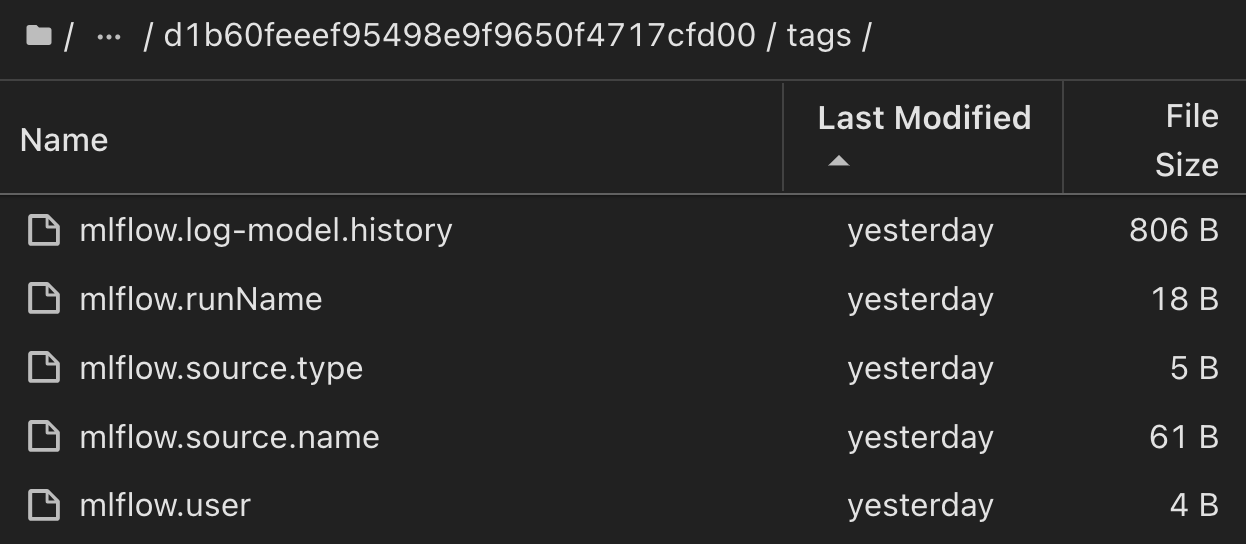
I clienti possono specificare tag, ad esempio "default", "stage", "process", "colli di bottiglia" per organizzare diverse caratteristiche delle esecuzioni del flusso di lavoro ai, prendere nota dei risultati più recenti o impostare contributors per tenere traccia dei progressi degli sviluppatori del team di data science. Se per il tag predefinito " ", la mlflow.log-model.history mlflow.runName mlflow.source.type mlflow.source.name mlflow.user scheda di navigazione file salvata, , , e in JupyterHub correntemente attiva:
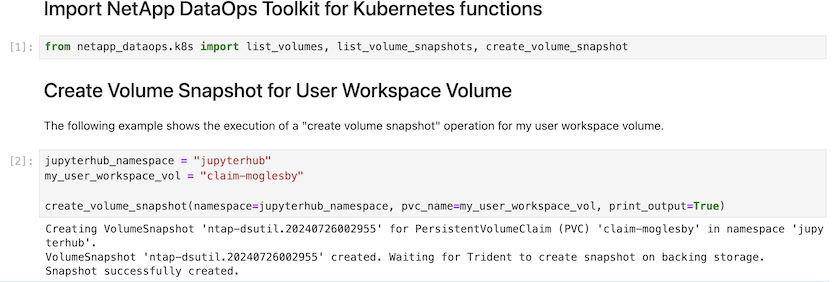
Infine, gli utenti dispongono del proprio Jupyter Workspace specificato, con versione e memorizzato in una dichiarazione di volume persistente (PVC) nel cluster Kubernetes. La figura seguente mostra l'area di lavoro di Jupyter, che contiene il netapp_dataops.k8s pacchetto Python, e i risultati di un creato correttamente VolumeSnapshot :
Le nostre tecnologie Snapshot® e altre tecnologie, comprovate nel settore, sono state utilizzate per garantire protezione dei dati, spostamento e compressione efficiente di livello aziendale. Per altri casi di utilizzo ai, fai riferimento alla "FlexPod NetApp"documentazione.