

Reinstallazione e riformattazione dei volumi di storage ("procedure manuali")
 Suggerisci modifiche
Suggerisci modifiche
È necessario eseguire manualmente due script per rimontare volumi di storage conservati e riformattare eventuali volumi di storage guasti. Il primo script consente di eseguire il remontaggio dei volumi correttamente formattati come volumi di storage StorageGRID. Il secondo script riformatta tutti i volumi non montati, ricostruisce Cassandra, se necessario, e avvia i servizi.
-
L'hardware è già stato sostituito per tutti i volumi di storage guasti che è necessario sostituire.
Esecuzione di
sn-remount-volumeslo script può aiutare a identificare altri volumi di storage guasti. -
È stato verificato che non è in corso la decommissionamento di un nodo di storage oppure che la procedura di decommissionamento del nodo è stata sospesa. (In Grid Manager, selezionare manutenzione > attività di manutenzione > smantellamento).
-
Hai verificato che non è in corso un'espansione. (In Grid Manager, selezionare manutenzione > attività di manutenzione > espansione).
-
Sono state esaminate le avvertenze relative al ripristino del disco di sistema di Storage Node.

Contattare il supporto tecnico se più di un nodo di storage non è in linea o se un nodo di storage in questa griglia è stato ricostruito negli ultimi 15 giorni. Non eseguire sn-recovery-postinstall.shscript. La ricostruzione di Cassandra su due o più nodi di storage entro 15 giorni l'uno dall'altro potrebbe causare la perdita di dati.
Per completare questa procedura, eseguire le seguenti attività di alto livello:
-
Accedere al nodo di storage recuperato.
-
Eseguire
sn-remount-volumesscript per il remount di volumi di storage correttamente formattati. Quando viene eseguito, lo script esegue le seguenti operazioni:-
Consente di montare e rimuovere ciascun volume di storage per riprodurre il journal XFS.
-
Esegue un controllo di coerenza del file XFS.
-
Se il file system è coerente, determina se il volume di storage è un volume di storage StorageGRID formattato correttamente.
-
Se il volume di storage è formattato correttamente, esegue il remontaggio del volume di storage. Tutti i dati esistenti sul volume rimangono intatti.
-
-
Esaminare l'output dello script e risolvere eventuali problemi.
-
Eseguire
sn-recovery-postinstall.shscript. Quando viene eseguito, lo script esegue le seguenti operazioni.
Non riavviare un nodo di storage durante il ripristino prima dell'esecuzione sn-recovery-postinstall.sh(vedere la fase per script post-installazione) per riformattare i volumi di storage guasti e ripristinare i metadati degli oggetti. Riavviare il nodo di storage primasn-recovery-postinstall.shIl completamento causa errori per i servizi che tentano di avviarsi e fa uscire i nodi dell'appliance StorageGRID dalla modalità di manutenzione.-
Consente di riformattare tutti i volumi di storage di
sn-remount-volumesimpossibile eseguire il montaggio dello script o che è stato trovato formattato in modo errato.
Se un volume di storage viene riformattato, tutti i dati presenti in tale volume andranno persi. È necessario eseguire un'ulteriore procedura per ripristinare i dati degli oggetti da altre posizioni nella griglia, supponendo che le regole ILM siano state configurate per memorizzare più copie di un oggetto. -
Ricostruisce il database Cassandra sul nodo, se necessario.
-
Avvia i servizi sul nodo di storage.
-
-
Accedere al nodo di storage recuperato:
-
Immettere il seguente comando:
ssh admin@grid_node_IP -
Immettere la password elencata in
Passwords.txtfile. -
Immettere il seguente comando per passare a root:
su - -
Immettere la password elencata in
Passwords.txtfile.
Una volta effettuato l'accesso come root, il prompt cambia da
$a.#. -
-
Eseguire il primo script per rimontare eventuali volumi di storage correttamente formattati.
Se tutti i volumi di storage sono nuovi e devono essere formattati, o se tutti i volumi di storage sono guasti, è possibile saltare questa fase ed eseguire il secondo script per riformattare tutti i volumi di storage non montati. -
Eseguire lo script:
sn-remount-volumesQuesto script potrebbe richiedere ore per essere eseguito su volumi di storage che contengono dati.
-
Durante l'esecuzione dello script, esaminare l'output e rispondere alle richieste.
Se necessario, è possibile utilizzare tail -fper monitorare il contenuto del file di log dello script (/var/local/log/sn-remount-volumes.log) . Il file di log contiene informazioni più dettagliate rispetto all'output della riga di comando.root@SG:~ # sn-remount-volumes The configured LDR noid is 12632740 ====== Device /dev/sdb ====== Mount and unmount device /dev/sdb and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sdb: Mount device /dev/sdb to /tmp/sdb-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12632740, volume number 0 in the volID file Attempting to remount /dev/sdb Device /dev/sdb remounted successfully ====== Device /dev/sdc ====== Mount and unmount device /dev/sdc and checking file system consistency: Error: File system consistency check retry failed on device /dev/sdc. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID Webscale will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policy. Do not continue to the next step if you believe that the data remaining on this volume cannot be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sdd ====== Mount and unmount device /dev/sdd and checking file system consistency: Failed to mount device /dev/sdd This device could be an uninitialized disk or has corrupted superblock. File system check might take a long time. Do you want to continue? (y or n) [y/N]? y Error: File system consistency check retry failed on device /dev/sdd. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID Webscale will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policy. Do not continue to the next step if you believe that the data remaining on this volume cannot be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sde ====== Mount and unmount device /dev/sde and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sde: Mount device /dev/sde to /tmp/sde-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12000078, volume number 9 in the volID file Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
Nell'output di esempio, un volume di storage è stato rimontato correttamente e tre volumi di storage hanno avuto errori.
-
/dev/sdbHa superato il controllo di coerenza del file system XFS e disponeva di una struttura di volume valida, quindi è stato rimontato correttamente. I dati sui dispositivi che vengono rimontati dallo script vengono conservati. -
/dev/sdcVerifica della coerenza del file system XFS non riuscita perché il volume di storage era nuovo o corrotto. -
/dev/sddimpossibile montare perché il disco non è stato inizializzato o il superblocco del disco è stato danneggiato. Quando lo script non riesce a montare un volume di storage, chiede se si desidera eseguire il controllo di coerenza del file system.-
Se il volume di storage è collegato a un nuovo disco, rispondere N alla richiesta. Non è necessario controllare il file system su un nuovo disco.
-
Se il volume di storage è collegato a un disco esistente, rispondere Y alla richiesta. È possibile utilizzare i risultati del controllo del file system per determinare l'origine del danneggiamento. I risultati vengono salvati in
/var/local/log/sn-remount-volumes.logfile di log.
-
-
/dev/sdeHa superato la verifica di coerenza del file system XFS e disponeva di una struttura di volume valida; tuttavia, l'ID del nodo LDR nel file volID non corrisponde all'ID per questo nodo di storage (laconfigured LDR noidvisualizzato nella parte superiore). Questo messaggio indica che questo volume appartiene a un altro nodo di storage.
-
-
-
Esaminare l'output dello script e risolvere eventuali problemi.
Se un volume di storage non ha superato il controllo di coerenza del file system XFS o non è stato possibile montarlo, esaminare attentamente i messaggi di errore nell'output. È necessario comprendere le implicazioni dell'esecuzione di sn-recovery-postinstall.shcreare script su questi volumi.-
Verificare che i risultati includano una voce per tutti i volumi previsti. Se alcuni volumi non sono elencati, eseguire nuovamente lo script.
-
Esaminare i messaggi per tutti i dispositivi montati. Assicurarsi che non vi siano errori che indichino che un volume di storage non appartiene a questo nodo di storage.
Nell'esempio, l'output per
/dev/sdeinclude il seguente messaggio di errore:Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
Se un volume di storage viene segnalato come appartenente a un altro nodo di storage, contattare il supporto tecnico. Se si esegue sn-recovery-postinstall.shscript, il volume di storage verrà riformattato, causando la perdita di dati. -
Se non è stato possibile montare alcun dispositivo di storage, annotare il nome del dispositivo e riparare o sostituire il dispositivo.
È necessario riparare o sostituire i dispositivi di storage che non possono essere montati. Il nome del dispositivo viene utilizzato per cercare l'ID del volume, che è necessario immettere quando si esegue
repair-datascript per ripristinare i dati dell'oggetto nel volume (la procedura successiva). -
Dopo aver riparato o sostituito tutti i dispositivi non montabili, eseguire
sn-remount-volumeseseguire nuovamente lo script per confermare che tutti i volumi di storage che possono essere rimontati sono stati rimontati.
Se un volume di storage non può essere montato o non è formattato correttamente e si passa alla fase successiva, il volume e i dati presenti nel volume verranno eliminati. Se si dispone di due copie di dati oggetto, si disporrà di una sola copia fino al completamento della procedura successiva (ripristino dei dati oggetto).
Non eseguire sn-recovery-postinstall.shEseguire uno script se si ritiene che i dati rimanenti su un volume di storage guasto non possano essere ricostruiti da un'altra parte della griglia (ad esempio, se il criterio ILM utilizza una regola che esegue una sola copia o se i volumi sono guasti su più nodi). Contattare invece il supporto tecnico per determinare come ripristinare i dati. -
-
Eseguire
sn-recovery-postinstall.shscript:sn-recovery-postinstall.shQuesto script riformatta tutti i volumi di storage che non possono essere montati o che sono stati trovati per essere formattati in modo non corretto; ricostruisce il database Cassandra sul nodo, se necessario; avvia i servizi sul nodo di storage.
Tenere presente quanto segue:
-
L'esecuzione dello script potrebbe richiedere ore.
-
In generale, si consiglia di lasciare la sessione SSH da sola mentre lo script è in esecuzione.
-
Non premere Ctrl+C mentre la sessione SSH è attiva.
-
Lo script viene eseguito in background se si verifica un'interruzione della rete e termina la sessione SSH, ma è possibile visualizzarne l'avanzamento dalla pagina Recovery (Ripristino).
-
Se Storage Node utilizza il servizio RSM, lo script potrebbe sembrare bloccato per 5 minuti quando i servizi del nodo vengono riavviati. Questo ritardo di 5 minuti è previsto ogni volta che il servizio RSM viene avviato per la prima volta.
Il servizio RSM è presente sui nodi di storage che includono il servizio ADC.
Alcune procedure di ripristino StorageGRID utilizzano Reaper gestire le riparazioni Cassandra. Le riparazioni vengono eseguite automaticamente non appena vengono avviati i servizi correlati o richiesti. Si potrebbe notare un output di script che menziona “reaper” o “Cassandra repair”. Se viene visualizzato un messaggio di errore che indica che la riparazione non è riuscita, eseguire il comando indicato nel messaggio di errore. -
-
come
sn-recovery-postinstall.shViene eseguito lo script, monitorare la pagina Recovery in Grid Manager.La barra di avanzamento e la colonna fase della pagina di ripristino forniscono uno stato di alto livello di
sn-recovery-postinstall.shscript.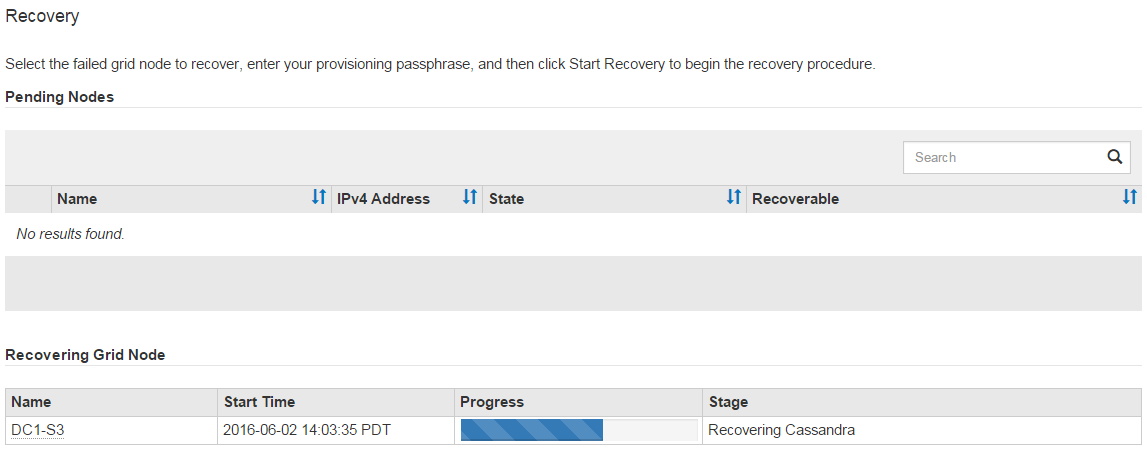
Dopo il sn-recovery-postinstall.sh lo script ha avviato i servizi sul nodo, è possibile ripristinare i dati degli oggetti in qualsiasi volume di storage formattato dallo script, come descritto in tale procedura.
"Revisione degli avvisi per il ripristino del disco di sistema di Storage Node"