

Controllare il flusso e la conservazione dei messaggi
 Suggerisci modifiche
Suggerisci modifiche
Tutti i servizi StorageGRID generano messaggi di audit durante il normale funzionamento del sistema. È necessario comprendere in che modo questi messaggi di audit vengono spostati nel sistema StorageGRID audit.log file.
Controllare il flusso dei messaggi
I messaggi di audit vengono elaborati dai nodi di amministrazione e dai nodi di storage che dispongono di un servizio ADC (Administrative Domain Controller).
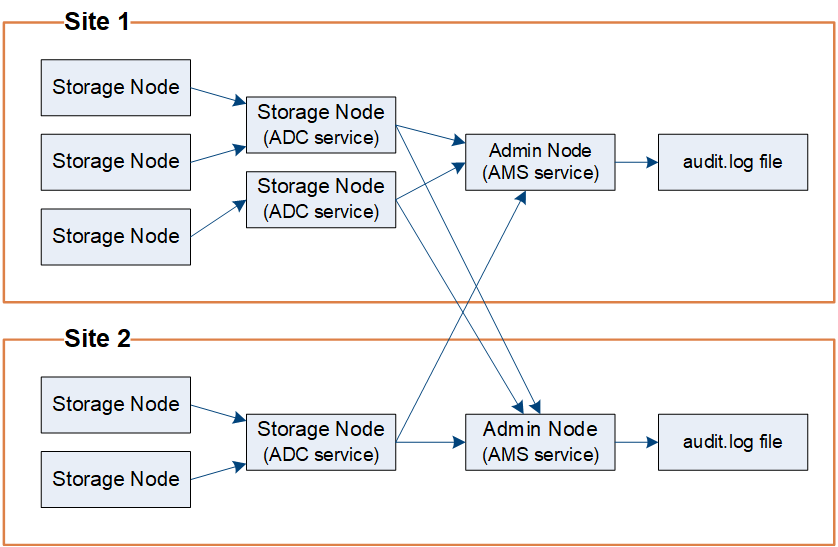
Come mostrato nel diagramma di flusso dei messaggi di audit, ciascun nodo StorageGRID invia i propri messaggi di audit a uno dei servizi ADC nel sito del data center. Il servizio ADC viene attivato automaticamente per i primi tre nodi di storage installati in ogni sito.
A sua volta, ogni servizio ADC agisce come un relay e invia la propria raccolta di messaggi di audit a ogni nodo amministrativo nel sistema StorageGRID, che fornisce a ciascun nodo amministrativo un record completo dell'attività del sistema.
Ogni nodo amministrativo memorizza i messaggi di audit in file di log di testo; il file di log attivo viene denominato audit.log.
Controllare la conservazione dei messaggi
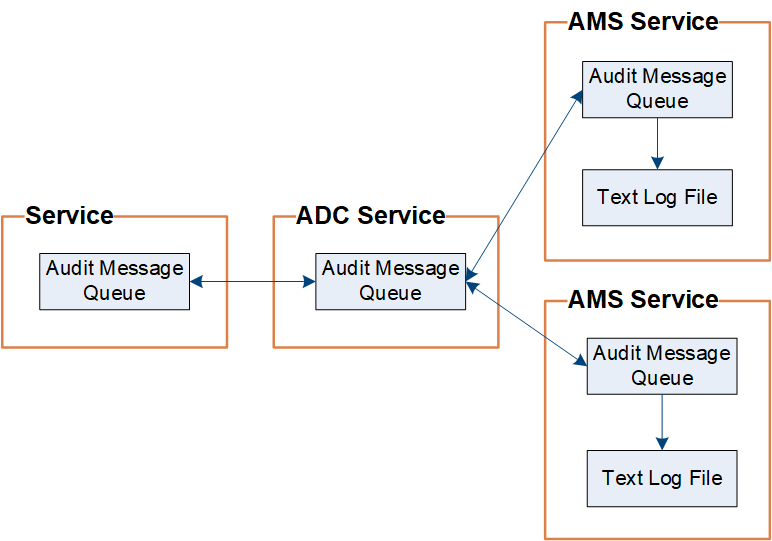
StorageGRID utilizza un processo di copia e cancellazione per garantire che non vengano persi messaggi di controllo prima di poter essere scritti nel registro di controllo.
Quando un nodo genera o inoltra un messaggio di audit, il messaggio viene memorizzato in una coda di messaggi di audit sul disco di sistema del nodo Grid. Una copia del messaggio viene sempre mantenuta in una coda di messaggi di audit fino a quando il messaggio non viene scritto nel file di log di audit nel nodo di amministrazione /var/local/audit/export directory. In questo modo si evita la perdita di un messaggio di audit durante il trasporto.
La coda dei messaggi di audit può aumentare temporaneamente a causa di problemi di connettività di rete o di capacità di audit insufficiente. Man mano che le code aumentano, consumano più spazio disponibile in ogni nodo /var/local/ directory. Se il problema persiste e la directory dei messaggi di controllo di un nodo diventa troppo piena, i singoli nodi assegneranno la priorità all'elaborazione del proprio backlog e diventeranno temporaneamente non disponibili per i nuovi messaggi.
In particolare, potrebbero verificarsi i seguenti comportamenti:
-
Se il
/var/local/audit/exportLa directory utilizzata da un nodo amministratore diventa piena, il nodo amministratore viene contrassegnato come non disponibile per i nuovi messaggi di audit fino a quando la directory non è più piena. Le richieste dei client S3 e Swift non sono interessate. L'allarme XAMS (Unreachable Audit Repository) viene attivato quando un repository di audit non è raggiungibile. -
Se il
/var/local/La directory utilizzata da un nodo di storage con il servizio ADC diventa piena al 92%, il nodo viene contrassegnato come non disponibile per i messaggi di controllo fino a quando la directory non è piena al 87%. Le richieste dei client S3 e Swift ad altri nodi non sono interessate. L'allarme NRLY (Available Audit Relay) viene attivato quando i relè di audit non sono raggiungibili.
Se non sono disponibili nodi di storage con il servizio ADC, i nodi di storage memorizzano i messaggi di audit in locale in /var/local/log/localaudit.logfile. -
Se il
/var/local/La directory utilizzata da un nodo di storage diventa piena al 85%, il nodo inizia a rifiutare le richieste dei client S3 e Swift con503 Service Unavailable.
I seguenti tipi di problemi possono causare un aumento delle code dei messaggi di audit:
-
Interruzione di un nodo amministrativo o di un nodo di storage con il servizio ADC. Se uno dei nodi del sistema non è attivo, i nodi rimanenti potrebbero diventare backlogged.
-
Tasso di attività sostenuta che supera la capacità di audit del sistema.
-
Il
/var/local/Lo spazio su un nodo di storage ADC diventa pieno per motivi non correlati ai messaggi di audit. In questo caso, il nodo smette di accettare nuovi messaggi di audit e assegna la priorità al backlog corrente, che può causare backlog su altri nodi.
Avviso di coda di audit estesa e allarme di messaggi di audit in coda (AMQS)
Per facilitare il monitoraggio delle dimensioni delle code dei messaggi di controllo nel tempo, l'avviso Large audit queue e l'allarme AMQS legacy vengono attivati quando il numero di messaggi in una coda Storage Node o Admin Node raggiunge determinate soglie.
Se viene attivato l'avviso Large audit queue o l'allarme AMQS legacy, iniziare controllando il carico sul sistema. Se si è verificato un numero significativo di transazioni recenti, l'avviso e l'allarme devono essere risolti nel tempo e possono essere ignorati.
Se l'avviso o l'allarme persiste e aumenta di severità, visualizzare un grafico delle dimensioni della coda. Se il numero aumenta costantemente nel corso di ore o giorni, il carico di audit ha probabilmente superato la capacità di audit del sistema. Ridurre la velocità di funzionamento del client o diminuire il numero di messaggi di audit registrati modificando il livello di audit per le scritture del client e le letture del client su Error (errore) o Off. Vedere "Configurare i messaggi di audit e le destinazioni dei log."
Messaggi duplicati
Il sistema StorageGRID adotta un approccio conservativo in caso di guasto di rete o nodo. Per questo motivo, nel registro di controllo potrebbero essere presenti messaggi duplicati.