

Flusso e conservazione dei messaggi di audit
 Suggerisci modifiche
Suggerisci modifiche
Tutti i servizi StorageGRID generano messaggi di audit durante il normale funzionamento del sistema. Dovresti capire come questi messaggi di controllo si spostano attraverso il sistema StorageGRID verso audit.log file.
Flusso dei messaggi di audit
I messaggi di controllo vengono elaborati dai nodi di amministrazione e dai nodi di archiviazione che dispongono di un servizio di controller di dominio amministrativo (ADC).
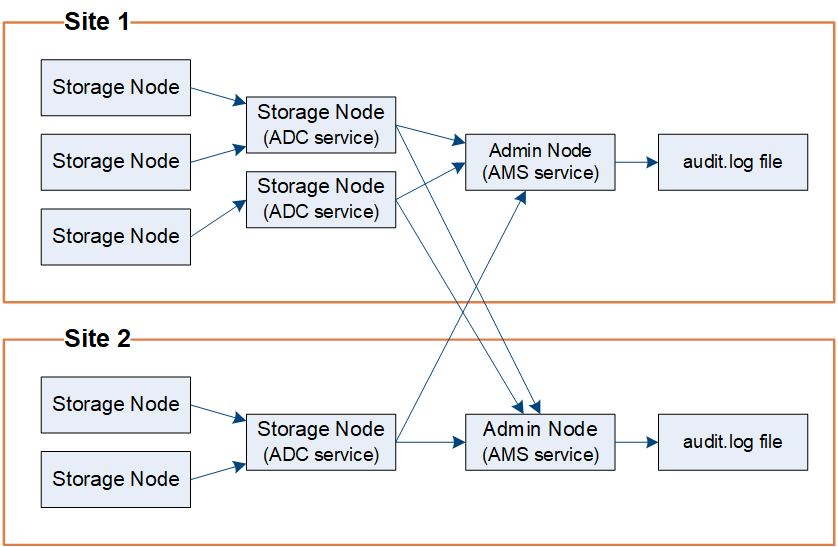
Come mostrato nel diagramma del flusso dei messaggi di controllo, ogni nodo StorageGRID invia i propri messaggi di controllo a uno dei servizi ADC presso il sito del data center. Il servizio ADC viene abilitato automaticamente per i primi tre nodi di archiviazione installati in ciascun sito.
A sua volta, ogni servizio ADC funge da relay e invia la propria raccolta di messaggi di audit a ogni nodo amministrativo nel sistema StorageGRID , il che fornisce a ciascun nodo amministrativo un record completo dell'attività del sistema.
Ogni nodo di amministrazione memorizza i messaggi di controllo in file di registro di testo; il file di registro attivo è denominato audit.log .
Conservazione dei messaggi di controllo
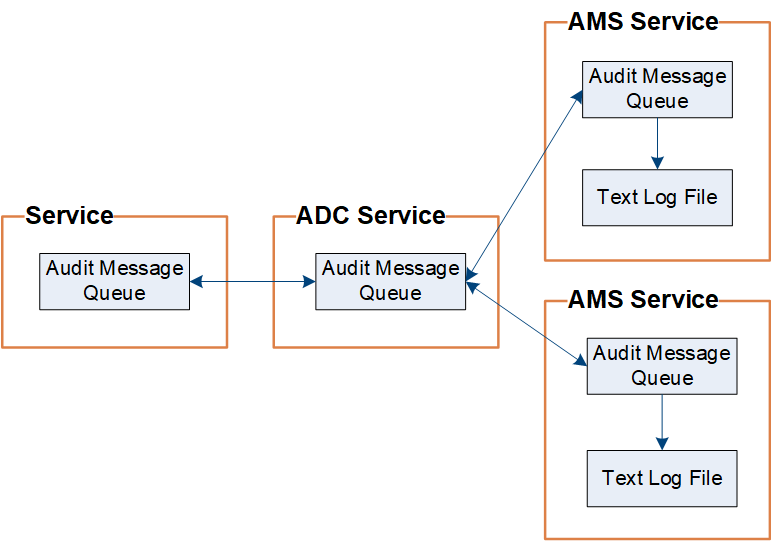
StorageGRID utilizza un processo di copia ed eliminazione per garantire che nessun messaggio di controllo venga perso prima che possa essere scritto nel registro di controllo.
Quando un nodo genera o inoltra un messaggio di controllo, il messaggio viene memorizzato in una coda di messaggi di controllo sul disco di sistema del nodo della griglia. Una copia del messaggio viene sempre conservata in una coda di messaggi di controllo finché il messaggio non viene scritto nel file di registro di controllo nel nodo di amministrazione /var/local/log elenco. Ciò aiuta a prevenire la perdita di un messaggio di controllo durante il trasporto.
La coda dei messaggi di controllo può aumentare temporaneamente a causa di problemi di connettività di rete o di capacità di controllo insufficiente. Man mano che le code aumentano, consumano più spazio disponibile in ciascun nodo /var/local/ elenco. Se il problema persiste e la directory dei messaggi di controllo di un nodo diventa troppo piena, i singoli nodi daranno priorità all'elaborazione del loro arretrato e diventeranno temporaneamente non disponibili per nuovi messaggi.
Nello specifico, potresti riscontrare i seguenti comportamenti:
-
Se il
/var/local/logSe la directory utilizzata da un nodo di amministrazione diventa piena, il nodo di amministrazione verrà contrassegnato come non disponibile per nuovi messaggi di controllo finché la directory non sarà più piena. Le richieste del client S3 non sono interessate. L'allarme XAMS (Unreachable Audit Repositories) viene attivato quando un repository di audit non è raggiungibile. -
Se il
/var/local/Quando la directory utilizzata da un nodo di archiviazione con il servizio ADC è piena al 92%, il nodo verrà contrassegnato come non disponibile per i messaggi di controllo finché la directory non sarà piena solo all'87%. Le richieste del client S3 ad altri nodi non sono interessate. L'allarme NRLY (Available Audit Relays) viene attivato quando i relay di audit non sono raggiungibili.
Se non sono disponibili nodi di archiviazione con il servizio ADC, i nodi di archiviazione archiviano i messaggi di controllo localmente nel /var/local/log/localaudit.logfile. -
Se il
/var/local/la directory utilizzata da un nodo di archiviazione diventa piena all'85%, il nodo inizierà a rifiutare le richieste del client S3 con503 Service Unavailable.
I seguenti tipi di problemi possono causare un aumento notevole delle dimensioni delle code dei messaggi di controllo:
-
Interruzione di un nodo di amministrazione o di un nodo di archiviazione con il servizio ADC. Se uno dei nodi del sistema è inattivo, i nodi rimanenti potrebbero accumulare arretrati.
-
Un tasso di attività sostenuto che supera la capacità di audit del sistema.
-
IL
/var/local/spazio su un nodo di archiviazione ADC che si riempie per motivi non correlati ai messaggi di controllo. Quando ciò accade, il nodo smette di accettare nuovi messaggi di audit e dà priorità al suo arretrato attuale, il che può causare arretrati su altri nodi.
Avviso di coda di controllo di grandi dimensioni e allarme di messaggi di controllo in coda (AMQS)
Per aiutarti a monitorare le dimensioni delle code dei messaggi di controllo nel tempo, l'avviso Coda di controllo di grandi dimensioni e l'allarme AMQS legacy vengono attivati quando il numero di messaggi in una coda del nodo di archiviazione o in una coda del nodo di amministrazione raggiunge determinate soglie.
Se viene attivato l'avviso Coda di controllo di grandi dimensioni o l'allarme AMQS legacy, iniziare controllando il carico sul sistema: se si è verificato un numero significativo di transazioni recenti, l'avviso e l'allarme dovrebbero risolversi nel tempo e possono essere ignorati.
Se l'avviso o l'allarme persiste e aumenta di gravità, visualizza un grafico delle dimensioni della coda. Se il numero aumenta costantemente nel corso di ore o giorni, è probabile che il carico di controllo abbia superato la capacità di controllo del sistema. Ridurre la frequenza operativa del client o diminuire il numero di messaggi di controllo registrati modificando il livello di controllo per Scritture client e Letture client su Errore o Disattivato. Vedere "Configurare i messaggi di controllo e le destinazioni dei registri" .
Messaggi duplicati
Il sistema StorageGRID adotta un approccio conservativo in caso di guasto della rete o del nodo. Per questo motivo potrebbero esserci messaggi duplicati nel registro di controllo.