

Risolvere i problemi di rete, hardware e piattaforma
 Suggerisci modifiche
Suggerisci modifiche
È possibile eseguire diverse attività per determinare l'origine dei problemi relativi a problemi di rete, hardware e piattaforma StorageGRID.
“422: Unprocessable Entity”
L'errore 422: Unprocessable Entity può verificarsi per diversi motivi. Controllare il messaggio di errore per determinare la causa del problema.
Se viene visualizzato uno dei messaggi di errore elencati, eseguire l'azione consigliata.
| Messaggio di errore | Causa principale e azione correttiva |
|---|---|
422: Unprocessable Entity Validation failed. Please check the values you entered for errors. Test connection failed. Please verify your configuration. Unable to authenticate, please verify your username and password: LDAP Result Code 8 "Strong Auth Required": 00002028: LdapErr: DSID-0C090256, comment: The server requires binds to turn on integrity checking if SSL\TLS are not already active on the connection, data 0, v3839 |
Questo messaggio potrebbe essere visualizzato se si seleziona l'opzione non utilizzare TLS per Transport Layer Security (TLS) durante la configurazione della federazione delle identità utilizzando Windows Active Directory (ad). L'utilizzo dell'opzione non utilizzare TLS non è supportato per l'utilizzo con i server ad che applicano la firma LDAP. Selezionare l'opzione Use STARTTLS (Usa STARTTLS*) o l'opzione Use LDAPS (Usa LDAPS* per TLS). |
422: Unprocessable Entity
Validation failed. Please check
the values you entered for
errors. Test connection failed.
Please verify your
configuration.Unable to
begin TLS, verify your
certificate and TLS
configuration: LDAP Result
Code 200 "Network Error":
TLS handshake failed
(EOF)
|
Questo messaggio viene visualizzato se si tenta di utilizzare una crittografia non supportata per stabilire una connessione TLS (Transport Layer Security) da StorageGRID a un sistema esterno utilizzato per identificare la federazione o i pool di storage cloud. Controllare le cifre offerte dal sistema esterno. Il sistema deve utilizzare uno dei "Crittografia supportata da StorageGRID" Per le connessioni TLS in uscita, come mostrato nelle istruzioni per l'amministrazione di StorageGRID. |
Avviso di mancata corrispondenza MTU della rete griglia
L'avviso Grid Network MTU mismatch (mancata corrispondenza MTU rete griglia) viene attivato quando l'impostazione Maximum Transmission Unit (MTU) per l'interfaccia Grid Network (eth0) differisce significativamente tra i nodi della griglia.
Le differenze nelle impostazioni MTU potrebbero indicare che alcune, ma non tutte, reti eth0 sono configurate per i frame jumbo. Una mancata corrispondenza delle dimensioni MTU superiore a 1000 potrebbe causare problemi di performance di rete.
-
Elencare le impostazioni MTU per eth0 su tutti i nodi.
-
Utilizzare la query fornita in Grid Manager.
-
Selezionare
primary Admin Node IP address/metrics/graphe immettere la seguente query:node_network_mtu_bytes{interface='eth0'}
-
-
"Modificare le impostazioni MTU" Come necessario per garantire che siano gli stessi per l'interfaccia Grid Network (eth0) su tutti i nodi.
-
Per i nodi basati su Linux e VMware, utilizzare il seguente comando:
/usr/sbin/change-ip.py [-h] [-n node] mtu network [network...]Esempio:
change-ip.py -n node 1500 grid adminNota: Nei nodi basati su Linux, se il valore MTU desiderato per la rete nel container supera il valore già configurato sull'interfaccia host, è necessario prima configurare l'interfaccia host in modo che abbia il valore MTU desiderato, quindi utilizzare
change-ip.pyScript per modificare il valore MTU della rete nel container.Utilizzare i seguenti argomenti per modificare la MTU su nodi basati su Linux o VMware.
Argomenti di posizione Descrizione mtuMTU da impostare. Deve essere compreso tra 1280 e 9216.
networkLe reti a cui applicare la MTU. Includere uno o più dei seguenti tipi di rete:
-
griglia
-
amministratore
-
client
+
Argomenti facoltativi Descrizione -h, – helpVisualizzare il messaggio della guida e uscire.
-n node, --node nodeIl nodo. L'impostazione predefinita è il nodo locale.
-
Allarme NRER (Network Receive Error)
Gli allarmi NRER (Network Receive Error) possono essere causati da problemi di connettività tra StorageGRID e l'hardware di rete. In alcuni casi, gli errori NRER possono essere corretti senza l'intervento manuale. Se gli errori non vengono corretti, eseguire le azioni consigliate.
Gli allarmi NRER possono essere causati dai seguenti problemi relativi all'hardware di rete che si collega a StorageGRID:
-
La funzione FEC (Forward Error Correction) è obbligatoria e non in uso
-
Mancata corrispondenza tra porta dello switch e MTU della scheda NIC
-
Elevati tassi di errore di collegamento
-
Buffer di anello NIC scaduto
-
Seguire i passaggi per la risoluzione dei problemi relativi a tutte le potenziali cause dell'allarme NRER in base alla configurazione di rete.
-
A seconda della causa dell'errore, attenersi alla seguente procedura:
Mancata corrispondenza FEC
Questi passaggi sono applicabili solo agli errori NRER causati da mancata corrispondenza FEC sulle appliance StorageGRID. -
Controllare lo stato FEC della porta dello switch collegato all'appliance StorageGRID.
-
Controllare l'integrità fisica dei cavi che collegano l'apparecchio allo switch.
-
Se si desidera modificare le impostazioni FEC per tentare di risolvere l'allarme NRER, assicurarsi innanzitutto che l'appliance sia configurata per la modalità auto nella pagina di configurazione del collegamento del programma di installazione dell'appliance StorageGRID (consultare le istruzioni relative all'appliance:
-
Modificare le impostazioni FEC sulle porte dello switch. Le porte dell'appliance StorageGRID regoleranno le impostazioni FEC in modo che corrispondano, se possibile.
Non è possibile configurare le impostazioni FEC sulle appliance StorageGRID. Le appliance tentano invece di rilevare e duplicare le impostazioni FEC sulle porte dello switch a cui sono collegate. Se i collegamenti sono forzati a velocità di rete 25-GbE o 100-GbE, lo switch e la NIC potrebbero non riuscire a negoziare un'impostazione FEC comune. Senza un'impostazione FEC comune, la rete torna alla modalità “no-FEC”. Quando la funzione FEC non è attivata, le connessioni sono più soggette a errori causati da disturbi elettrici.
Le appliance StorageGRID supportano Firecode (FC) e Reed Solomon (RS) FEC, oltre che FEC.
Mancata corrispondenza tra porta dello switch e MTU della scheda NICSe l'errore è causato da una mancata corrispondenza tra la porta dello switch e la MTU della NIC, verificare che le dimensioni MTU configurate sul nodo corrispondano all'impostazione MTU per la porta dello switch.
La dimensione MTU configurata sul nodo potrebbe essere inferiore all'impostazione sulla porta dello switch a cui è connesso il nodo. Se un nodo StorageGRID riceve un frame Ethernet più grande del relativo MTU, cosa possibile con questa configurazione, potrebbe essere segnalato l'allarme NRER. Se si ritiene che questo sia quanto accade, modificare la MTU della porta dello switch in modo che corrisponda alla MTU dell'interfaccia di rete StorageGRID oppure modificare la MTU dell'interfaccia di rete StorageGRID in modo che corrisponda alla porta dello switch, in base agli obiettivi o ai requisiti della MTU end-to-end.

Per ottenere le migliori performance di rete, tutti i nodi devono essere configurati con valori MTU simili sulle interfacce Grid Network. L'avviso Grid Network MTU mismatch (mancata corrispondenza MTU rete griglia) viene attivato se si verifica una differenza significativa nelle impostazioni MTU per Grid Network su singoli nodi. I valori MTU non devono essere uguali per tutti i tipi di rete. Vedere Risolvere i problemi relativi all'avviso di mancata corrispondenza MTU della rete griglia per ulteriori informazioni.
Vedere anche "Modificare l'impostazione MTU". Elevati tassi di errore di collegamento-
Attivare FEC, se non è già attivato.
-
Verificare che il cablaggio di rete sia di buona qualità e non sia danneggiato o collegato in modo errato.
-
Se i cavi non sembrano essere il problema, contattare il supporto tecnico.
In un ambiente con elevati livelli di rumore elettrico, potrebbero verificarsi errori elevati.
Buffer di anello NIC scadutoSe l'errore è un buffer di anello della scheda di rete in eccesso, contattare il supporto tecnico.
Il buffer circolare può essere sovraccarico quando il sistema StorageGRID è sovraccarico e non è in grado di elaborare gli eventi di rete in modo tempestivo.
-
-
Dopo aver risolto il problema sottostante, reimpostare il contatore degli errori.
-
Selezionare SUPPORT > Tools > Grid topology.
-
Selezionare site > grid node > SSM > Resources > Configuration > Main.
-
Selezionare Ripristina conteggio errori di ricezione e fare clic su Applica modifiche.
-
Errori di sincronizzazione dell'ora
Potrebbero verificarsi problemi con la sincronizzazione dell'ora nella griglia.
Se si verificano problemi di sincronizzazione dell'ora, verificare di aver specificato almeno quattro origini NTP esterne, ciascuna con uno strato 3 o un riferimento migliore, e che tutte le origini NTP esterne funzionino normalmente e siano accessibili dai nodi StorageGRID.
|
|
Quando "Specifica dell'origine NTP esterna" Per un'installazione StorageGRID a livello di produzione, non utilizzare il servizio Windows Time (W32Time) su una versione di Windows precedente a Windows Server 2016. Il servizio Time sulle versioni precedenti di Windows non è sufficientemente accurato e non è supportato da Microsoft per l'utilizzo in ambienti ad alta precisione, come StorageGRID. |
Linux: Problemi di connettività di rete
Potrebbero verificarsi problemi con la connettività di rete per i grid node StorageGRID ospitati su host Linux.
Clonazione indirizzo MAC
In alcuni casi, i problemi di rete possono essere risolti utilizzando la clonazione dell'indirizzo MAC. Se si utilizzano host virtuali, impostare il valore della chiave di clonazione dell'indirizzo MAC per ciascuna rete su "true" nel file di configurazione del nodo. Questa impostazione fa in modo che l'indirizzo MAC del container StorageGRID utilizzi l'indirizzo MAC dell'host. Per creare i file di configurazione del nodo, consultare le istruzioni per "Red Hat Enterprise Linux o CentOS" oppure "Ubuntu o Debian".
|
|
Creare interfacce di rete virtuali separate per l'utilizzo da parte del sistema operativo host Linux. L'utilizzo delle stesse interfacce di rete per il sistema operativo host Linux e per il container StorageGRID potrebbe rendere il sistema operativo host irraggiungibile se la modalità promiscua non è stata attivata sull'hypervisor. |
Per ulteriori informazioni sull'attivazione della clonazione MAC, consultare le istruzioni per "Red Hat Enterprise Linux o CentOS" oppure "Ubuntu o Debian".
Modalità promiscua
Se non si desidera utilizzare la clonazione dell'indirizzo MAC e si desidera consentire a tutte le interfacce di ricevere e trasmettere dati per indirizzi MAC diversi da quelli assegnati dall'hypervisor, Assicurarsi che le proprietà di sicurezza a livello di switch virtuale e gruppo di porte siano impostate su Accept per modalità promiscuous, modifiche indirizzo MAC e trasmissione forgiata. I valori impostati sullo switch virtuale possono essere sovrascritti dai valori a livello di gruppo di porte, quindi assicurarsi che le impostazioni siano le stesse in entrambe le posizioni.
Per ulteriori informazioni sull'utilizzo della modalità promiscua, consultare le istruzioni di "Red Hat Enterprise Linux o CentOS" oppure "Ubuntu o Debian".
Linux: Stato del nodo “orfano”
Un nodo Linux in uno stato orfano di solito indica che il servizio StorageGRID o il daemon del nodo StorageGRID che controlla il contenitore del nodo sono morti inaspettatamente.
Se un nodo Linux segnala che si trova in uno stato orfano, è necessario:
-
Controllare i registri per verificare la presenza di errori e messaggi.
-
Tentare di riavviare il nodo.
-
Se necessario, utilizzare i comandi del motore dei container per arrestare il contenitore di nodi esistente.
-
Riavviare il nodo.
-
Controllare i log sia per il daemon di servizio che per il nodo orfano per verificare la presenza di errori evidenti o messaggi relativi all'uscita imprevista.
-
Accedere all'host come root o utilizzando un account con autorizzazione sudo.
-
Tentare di riavviare il nodo eseguendo il seguente comando:
$ sudo storagegrid node start node-name$ sudo storagegrid node start DC1-S1-172-16-1-172
Se il nodo è orfano, la risposta è
Not starting ORPHANED node DC1-S1-172-16-1-172
-
Da Linux, arrestare il motore dei container e qualsiasi processo di controllo del nodo storagegrid. Ad esempio:
sudo docker stop --time secondscontainer-namePer
seconds, immettere il numero di secondi che si desidera attendere per l'arresto del container (in genere 15 minuti o meno). Ad esempio:sudo docker stop --time 900 storagegrid-DC1-S1-172-16-1-172
-
Riavviare il nodo:
storagegrid node start node-namestoragegrid node start DC1-S1-172-16-1-172
Linux: Risoluzione dei problemi relativi al supporto IPv6
Potrebbe essere necessario abilitare il supporto IPv6 nel kernel se sono stati installati nodi StorageGRID su host Linux e si nota che gli indirizzi IPv6 non sono stati assegnati ai contenitori di nodi come previsto.
È possibile visualizzare l'indirizzo IPv6 assegnato a un nodo Grid nelle seguenti posizioni in Grid Manager:
-
Selezionare NODI e selezionare il nodo. Quindi, selezionare Mostra altri accanto a indirizzi IP nella scheda Panoramica.
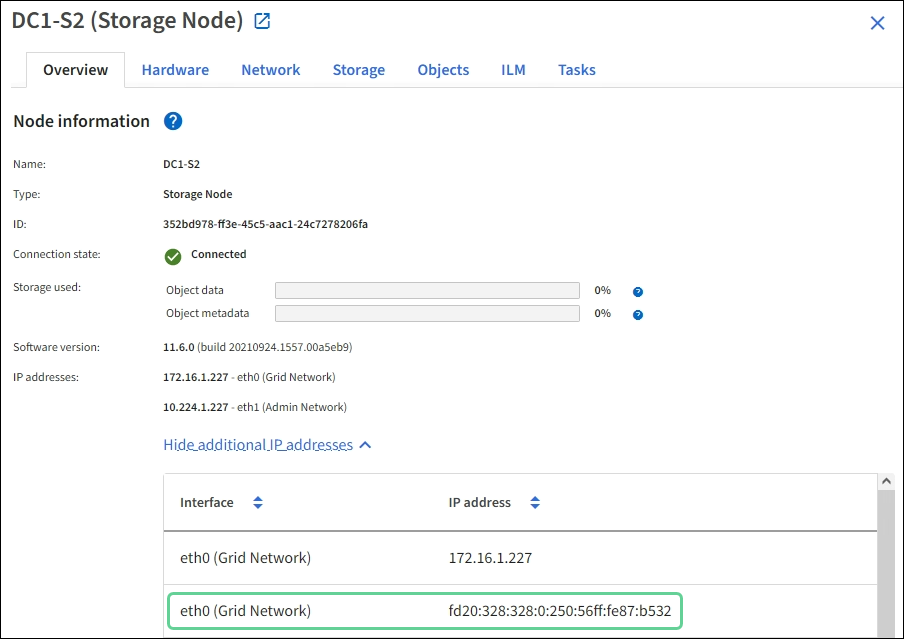
-
Selezionare SUPPORT > Tools > Grid topology. Quindi, selezionare node > SSM > risorse. Se è stato assegnato un indirizzo IPv6, questo viene elencato sotto l'indirizzo IPv4 nella sezione indirizzi di rete.
Se l'indirizzo IPv6 non viene visualizzato e il nodo è installato su un host Linux, seguire questa procedura per abilitare il supporto IPv6 nel kernel.
-
Accedere all'host come root o utilizzando un account con autorizzazione sudo.
-
Eseguire il seguente comando:
sysctl net.ipv6.conf.all.disable_ipv6root@SG:~ # sysctl net.ipv6.conf.all.disable_ipv6
Il risultato deve essere 0.
net.ipv6.conf.all.disable_ipv6 = 0
Se il risultato non è 0, consultare la documentazione relativa al sistema operativo in uso per le modifiche sysctlimpostazioni. Quindi, modificare il valore su 0 prima di continuare. -
Inserire il contenitore di nodi StorageGRID:
storagegrid node enter node-name -
Eseguire il seguente comando:
sysctl net.ipv6.conf.all.disable_ipv6root@DC1-S1:~ # sysctl net.ipv6.conf.all.disable_ipv6
Il risultato deve essere 1.
net.ipv6.conf.all.disable_ipv6 = 1
Se il risultato non è 1, questa procedura non si applica. Contattare il supporto tecnico. -
Uscire dal container:
exitroot@DC1-S1:~ # exit
-
Come root, modificare il seguente file:
/var/lib/storagegrid/settings/sysctl.d/net.conf.sudo vi /var/lib/storagegrid/settings/sysctl.d/net.conf
-
Individuare le due righe seguenti e rimuovere i tag di commento. Quindi, salvare e chiudere il file.
net.ipv6.conf.all.disable_ipv6 = 0
net.ipv6.conf.default.disable_ipv6 = 0
-
Eseguire questi comandi per riavviare il container StorageGRID:
storagegrid node stop node-name
storagegrid node start node-name