

Raggiungimento di un RPO pari a zero con StorageGRID: Una guida completa alla replica multisito
 Suggerisci modifiche
Suggerisci modifiche
Questo rapporto tecnico fornisce una guida completa all'implementazione di strategie di replica StorageGRID per raggiungere un Recovery Point Objective (RPO) pari a zero in caso di guasto del sito. Il documento descrive in dettaglio varie opzioni di distribuzione per StorageGRID, tra cui la replica sincrona multi-sito e la replica asincrona multi-griglia. Spiega come configurare le policy StorageGRID Information Lifecycle Management (ILM) per garantire la durabilità e la disponibilità dei dati in più sedi. Inoltre, il rapporto affronta considerazioni sulle prestazioni, scenari di errore e processi di ripristino per garantire la continuità delle operazioni dei clienti. L'obiettivo di questo documento è fornire informazioni per garantire che i dati rimangano accessibili e coerenti, anche in caso di un guasto completo del sito, sfruttando tecniche di replica sia sincrona che asincrona.
Panoramica di StorageGRID
NetApp StorageGRID è un sistema storage basato su oggetti che supporta l'API Amazon Simple Storage Service (Amazon S3) standard di settore.
StorageGRID offre un namespace singolo in siti multipli con livelli di servizio variabili determinati da policy di Information Lifecycle Management (ILM). Grazie a queste policy sul ciclo di vita puoi ottimizzare la collocazione dei tuoi dati durante tutto il loro ciclo di vita.
StorageGRID garantisce durata e disponibilità configurabili dei tuoi dati in soluzioni locali e geodistribuito. Che i tuoi dati siano in locale o in un cloud pubblico, i flussi di lavoro cloud ibridi integrati consentono alla tua azienda di sfruttare servizi cloud come Amazon Simple Notification Service (Amazon SNS), Google Cloud, Microsoft Azure Blob, Amazon S3 Glacier, Elasticsearch e molti altri.
Scala StorageGRID
Una distribuzione StorageGRID minima è composta da un nodo di amministrazione e 3 nodi di archiviazione in un unico sito. Una singola griglia può crescere fino a 220 nodi. StorageGRID può essere distribuito come un singolo sito o esteso a 16 siti.
Il nodo Admin contiene l'interfaccia di gestione, un punto centrale per le metriche e la registrazione e gestisce la configurazione dei componenti StorageGRID . Il nodo Admin contiene anche un bilanciatore del carico integrato per l'accesso all'API S3.
StorageGRID può essere distribuito solo come software, come appliance per macchine virtuali VMware o come appliance appositamente progettate.
Un nodo di archiviazione può essere distribuito come:
-
Un nodo solo metadati che massimizza il conteggio degli oggetti
-
Un nodo di archiviazione di soli oggetti che massimizza lo spazio degli oggetti
-
Un nodo combinato di metadati e archiviazione di oggetti che aggiunge sia il conteggio degli oggetti che lo spazio degli oggetti
Ogni nodo di archiviazione può raggiungere una capacità di archiviazione di oggetti di diversi petabyte, consentendo un singolo namespace di centinaia di petabyte. StorageGRID fornisce anche un bilanciatore del carico integrato per le operazioni API S3 denominato nodo gateway.
StorageGRID è costituito da una raccolta di nodi posizionati in una topologia di sito. Un sito in StorageGRID può essere una posizione fisica unica oppure risiedere in una posizione fisica condivisa come altri siti nella griglia come costrutto logico. Un sito StorageGRID non dovrebbe estendersi su più sedi fisiche. Un sito rappresenta un'infrastruttura di rete locale (LAN) condivisa e un dominio di errore.
StorageGRID e domini di errore
StorageGRID contiene diversi livelli di domini di errore da prendere in considerazione per decidere come progettare la soluzione, come archiviare i dati e dove archiviare i dati per mitigare i rischi di guasti.
-
Livello griglia - Una griglia costituita da più siti può presentare guasti o isolamento del sito e i siti accessibili possono continuare a funzionare come rete.
-
Livello sito - i guasti all'interno di un sito possono influire sulle operazioni del sito, ma non sul resto della griglia.
-
Livello nodo - il guasto di Un nodo non influisce sul funzionamento del sito.
-
Livello disco - un guasto del disco non influisce sul funzionamento del nodo.
Dati e metadati di oggetti
Con lo storage a oggetti, l'unità di storage è un oggetto, piuttosto che un file o un blocco. A differenza della gerarchia ad albero di un file system o di uno storage a blocchi, lo storage a oggetti organizza i dati in un layout piatto e non strutturato. Lo storage a oggetti separa la posizione fisica dei dati dal metodo utilizzato per memorizzare e recuperare tali dati.
Ogni oggetto in un sistema di storage basato su oggetti ha due parti: Dati oggetto e metadati oggetto.
-
I dati oggetto rappresentano i dati sottostanti effettivi, ad esempio una fotografia, un filmato o una cartella clinica.
-
I metadati degli oggetti sono informazioni che descrivono un oggetto.
StorageGRID utilizza i metadati degli oggetti per tenere traccia delle posizioni di tutti gli oggetti nella griglia e gestire il ciclo di vita di ciascun oggetto nel tempo.
I metadati dell'oggetto includono informazioni come:
-
Metadati di sistema, tra cui un ID univoco per ciascun oggetto, il nome dell'oggetto, il nome del bucket S3, il nome o l'ID dell'account tenant, la dimensione logica dell'oggetto, la data e l'ora in cui l'oggetto è stato creato per la prima volta e la data e l'ora dell'ultima modifica dell'oggetto.
-
Posizione di archiviazione corrente della copia replicata o del frammento con codice di cancellazione di ciascun oggetto.
-
Qualsiasi coppia di valori chiave metadati utente personalizzata associata all'oggetto.
-
Per gli oggetti S3, qualsiasi coppia chiave-valore tag oggetto associata all'oggetto
-
Per oggetti segmentati e oggetti multiparte, identificatori di segmento e dimensioni dei dati.
I metadati degli oggetti sono personalizzabili ed espandibili, il che lo rende flessibile per l'utilizzo da parte delle applicazioni. Per informazioni dettagliate su come e dove StorageGRID archivia i metadati degli oggetti, visitare il sito "Gestire lo storage dei metadati degli oggetti".
Il sistema Information Lifecycle management (ILM) di StorageGRID viene utilizzato per orchestrare il posizionamento, la durata e il comportamento di acquisizione per tutti i dati degli oggetti nel sistema StorageGRID. Le regole ILM determinano il modo in cui StorageGRID archivia gli oggetti nel tempo utilizzando repliche degli oggetti o erasure coding dell'oggetto nei nodi e nei siti. Questo sistema ILM è responsabile della coerenza dei dati degli oggetti all'interno di una griglia.
Erasure coding
StorageGRID offre la possibilità di cancellare i dati del codice a livello di nodo e a livello di unità. Con gli apparecchi StorageGRID cancelliamo tramite codice i dati memorizzati su ciascun nodo su tutte le unità presenti nel nodo, garantendo protezione locale contro guasti di più dischi che causano perdite o interruzioni di dati. Le ricostruzioni in seguito a guasti delle unità sono locali al nodo e non richiedono la replica dei dati sulla rete.
Inoltre, gli apparecchi StorageGRID utilizzano schemi di codifica di cancellazione per archiviare i dati degli oggetti nei nodi all'interno di un sito o distribuiti su 3 o più siti nel sistema StorageGRID tramite le regole ILM di StorageGRID che proteggono dai guasti dei nodi.
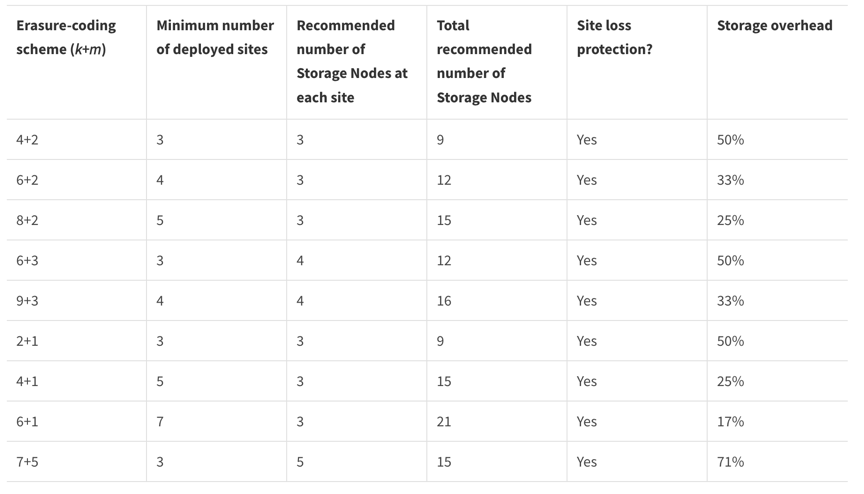
La codifica di cancellazione fornisce un layout di archiviazione resiliente ai guasti dei nodi e dei siti con un overhead inferiore rispetto alla replica. Tutti gli schemi di codifica di cancellazione StorageGRID possono essere implementati in un singolo sito, a condizione che venga raggiunto il numero minimo di nodi necessari per archiviare i blocchi di dati. Ciò significa che per uno schema EC 4+2 devono essere disponibili almeno 6 nodi per ricevere i dati.
Coerenza dei metadati
In StorageGRID, i metadati vengono generalmente archiviati con tre repliche per sito, per garantire coerenza e disponibilità. Questa ridondanza contribuisce a mantenere l'integrità e l'accessibilità dei dati anche in caso di errore.
La coerenza predefinita è definita a livello di griglia. Gli utenti possono modificare la coerenza a livello del bucket in qualsiasi momento.
Le opzioni di coerenza delle benne disponibili in StorageGRID sono:
-
Tutti: Offre il massimo livello di coerenza. Tutti i nodi nella griglia ricevono i dati immediatamente, altrimenti la richiesta non riesce.
-
Forte-globale:
-
Legacy Strong Global: garantisce la coerenza di lettura e scrittura per tutte le richieste dei clienti su tutti i siti.
-
Questo è il comportamento predefinito per tutti i sistemi aggiornati dalla versione 11.9 o precedente alla versione 12.0 senza passare manualmente al nuovo Quorum Strong Global.
-
-
Quorum Strong-global: garantisce la coerenza di lettura e scrittura per tutte le richieste dei client su tutti i siti. Offre coerenza per più nodi o persino in caso di errore del sito se è possibile raggiungere il quorum di replica dei metadati.
-
Questo è il comportamento predefinito per tutti i sistemi appena installati alla versione 12.0 o successiva.
-
La coerenza del QUORUM è definita come un quorum di repliche di metadati del nodo di archiviazione, in cui ogni sito ha 3 repliche di metadati. Può essere calcolato come segue: 1+((N*3)/2) dove N è il numero totale di siti
-
Ad esempio, è necessario effettuare almeno 5 repliche da una griglia a 3 siti, con un massimo di 3 repliche all'interno di un sito.
-
-
-
Strong-Site: Garantisce la coerenza di lettura dopo scrittura per tutte le richieste dei client all'interno di un sito.
-
Read-after-new-write(default): Fornisce coerenza lettura-dopo-scrittura per nuovi oggetti ed eventuale coerenza per gli aggiornamenti degli oggetti. Offre alta disponibilità e garanzie di protezione dei dati. Consigliato per la maggior parte dei casi.
-
Available: Fornisce una coerenza finale sia per i nuovi oggetti che per gli aggiornamenti degli oggetti. Per i bucket S3, utilizzare solo se necessario (ad esempio, per un bucket che contiene valori di log che vengono raramente letti o per operazioni HEAD o GET su chiavi che non esistono). Non supportato per i bucket S3 FabricPool.
Coerenza dei dati degli oggetti
Mentre i metadati vengono replicati automaticamente all'interno e tra i siti, spetta a te prendere decisioni sul posizionamento dello storage dei dati a oggetti. I dati degli oggetti possono essere memorizzati in repliche all'interno e tra i siti, con erasure coding all'interno o tra i siti, o in una combinazione o repliche e schemi di storage con erasure coding. Le regole ILM possono essere applicate a tutti gli oggetti o filtrate per applicarsi solo a determinati oggetti, bucket o tenant. Le regole ILM definiscono il modo in cui gli oggetti vengono memorizzati, le repliche e/o il erasure coding, la durata della memorizzazione degli oggetti in tali posizioni, se il numero di repliche o lo schema di erasure coding deve cambiare o se le posizioni devono cambiare nel tempo.
Ogni regola ILM verrà configurata con uno dei tre comportamenti di acquisizione per la protezione degli oggetti: Dual commit, balanced o Strict.
L'opzione di doppio commit eseguirà immediatamente due copie su due nodi di archiviazione diversi nella griglia e restituirà al client la richiesta di esito positivo. La selezione del nodo verrà tentata all'interno del sito della richiesta, ma in alcune circostanze potrebbe utilizzare nodi di un altro sito. L'oggetto viene aggiunto alla coda ILM per essere valutato e posizionato in base alle regole ILM.
L'opzione bilanciata valuta immediatamente l'oggetto in base alla policy ILM e lo posiziona in modo sincrono prima di restituire la richiesta di esito positivo al client. Se la regola ILM non può essere rispettata immediatamente a causa di un'interruzione o di uno spazio di archiviazione inadeguato per soddisfare i requisiti di posizionamento, verrà utilizzato il doppio commit. Una volta risolto il problema, ILM posizionerà automaticamente l'oggetto in base alla regola definita.
L'opzione strict valuta immediatamente l'oggetto in base alla policy ILM e lo posiziona in modo sincrono prima di restituire la richiesta di esito positivo al client. Se la regola ILM non può essere soddisfatta immediatamente a causa di un'interruzione o di uno spazio di archiviazione inadeguato per soddisfare i requisiti di posizionamento, la richiesta non andrà a buon fine e il client dovrà riprovare.
Bilanciamento del carico
StorageGRID può essere implementato con accesso client tramite i nodi gateway integrati, un bilanciatore di carico esterno di 3e parti, round robin DNS o direttamente in un nodo storage. È possibile implementare diversi nodi di gateway in un sito e configurarli in gruppi a disponibilità elevata per offrire failover e failback automatici in caso di black-out di un nodo di gateway. È possibile combinare metodi di bilanciamento del carico in una soluzione per fornire un unico punto di accesso per tutti i siti in una soluzione.
Per impostazione predefinita, i nodi gateway bilanciano il carico tra i nodi di archiviazione nel sito in cui risiede il nodo gateway. StorageGRID può essere configurato per consentire ai nodi gateway di bilanciare il carico utilizzando nodi provenienti da più siti. Questa configurazione aggiungerebbe la latenza tra quei siti alla latenza di risposta alle richieste del client. Questa impostazione dovrebbe essere configurata solo se la latenza totale è accettabile per i client.
È possibile garantire un RTO pari a zero combinando il bilanciamento del carico locale e globale. Per garantire un accesso client ininterrotto è necessario bilanciare il carico delle richieste client. Una soluzione StorageGRID può contenere molti nodi gateway e gruppi ad alta disponibilità in ogni sito. Per garantire un accesso ininterrotto ai client in qualsiasi sito, anche in caso di guasto del sito, è necessario configurare una soluzione di bilanciamento del carico esterno in combinazione con i nodi StorageGRID Gateway. Configurare gruppi ad alta disponibilità del nodo Gateway che gestiscono il carico all'interno di ciascun sito e utilizzare il bilanciatore del carico esterno per bilanciare il carico tra i gruppi ad alta disponibilità. Il bilanciatore del carico esterno deve essere configurato per eseguire un controllo dello stato di integrità per garantire che le richieste vengano inviate solo ai siti operativi. Per ulteriori informazioni sul bilanciamento del carico con StorageGRID , consultare "Report tecnico per il bilanciamento del carico di StorageGRID".
Requisiti per Zero RPO con StorageGRID
Per raggiungere l'obiettivo RPO (Recovery Point Objective) zero in un sistema storage a oggetti, è fondamentale che al momento del guasto:
-
Sia i metadati che i contenuti degli oggetti sono sincronizzati e considerati coerenti
-
I contenuti degli oggetti rimangono accessibili nonostante il guasto.
Per una distribuzione multi-sito, Quorum Strong Global è il modello di coerenza preferito per garantire che i metadati siano sincronizzati su tutti i siti, rendendolo essenziale per soddisfare il requisito RPO zero.
Gli oggetti nel sistema di archiviazione vengono archiviati in base alle regole di Information Lifecycle Management (ILM), che stabiliscono come e dove i dati vengono archiviati durante il loro ciclo di vita. Per la replica sincrona, è possibile prendere in considerazione l'esecuzione rigorosa o l'esecuzione bilanciata.
-
Per un RPO pari a zero è necessaria un'esecuzione rigorosa di queste regole ILM, in quanto assicura che gli oggetti vengano posizionati nelle posizioni definite senza alcun ritardo o fallback, mantenendo la disponibilità e la coerenza dei dati.
-
Il comportamento di acquisizione ILM di StorageGRID offre un equilibrio tra alta disponibilità e resilienza, consentendo agli utenti di continuare ad acquisire i dati anche in caso di guasto del sito.
Implementazioni sincrone in siti multipli
Soluzioni multi-sito: StorageGRID consente di replicare oggetti su più siti all'interno della griglia in modo sincrono. Impostando regole di Information Lifecycle Management (ILM) con comportamento bilanciato o rigoroso, gli oggetti vengono posizionati immediatamente nelle posizioni specificate. Anche la configurazione del livello di coerenza del bucket su Quorum Strong Global garantirà la replica sincrona dei metadati. StorageGRID utilizza un singolo namespace globale, memorizzando le posizioni di posizionamento degli oggetti come metadati, in modo che ogni nodo sappia dove si trovano tutte le copie o i pezzi codificati per la cancellazione. Se un oggetto non può essere recuperato dal sito in cui è stata effettuata la richiesta, verrà recuperato automaticamente da un sito remoto senza bisogno di procedure di failover.
Una volta risolto il problema, non è necessario alcun intervento di failback manuale. Le performance di replica dipendono dal sito con il throughput di rete più basso, la latenza più alta e le performance più basse. Le prestazioni di un sito si basano sul numero di nodi, sul numero di core della CPU e sulla velocità, sulla memoria, sulla quantità di unità e sui tipi di unità.
Soluzioni multi-grid: StorageGRID è in grado di replicare tenant, utenti e bucket tra più sistemi StorageGRID utilizzando la replica cross-grid (CGR, Cross-Grid Replication). CGR può estendere i dati selezionati a più di 16 siti, aumentare la capacità utilizzabile dell'archivio di oggetti e fornire il disaster recovery. La replica dei bucket con CGR include oggetti, versioni degli oggetti e metadati e può essere bidirezionale o unidirezionale. L'RPO (Recovery Point Objective) dipende dalle prestazioni di ogni sistema StorageGRID e dalle connessioni di rete tra di essi.
Sommario:
-
La replica intra-grid include una replica sincrona e asincrona, configurabile tramite comportamento di acquisizione ILM e controllo della coerenza dei metadati.
-
La replica inter-grid è solo asincrona.
Distribuzione multisito Single Grid
Negli scenari seguenti, le soluzioni StorageGRID sono configurate con un bilanciatore del carico esterno opzionale che gestisce le richieste ai gruppi ad alta disponibilità del bilanciatore del carico integrato. In questo modo si otterrà un RTO pari a zero, oltre a un RPO pari a zero. ILM è configurato con protezione di ingestione bilanciata per il posizionamento sincrono. Ogni bucket è configurato con la versione Quorum del modello di coerenza Strong Global per griglie di 3 o più siti e con la versione Legacy del modello di coerenza Strong Global per 2 siti.
Scenario 1:
In una soluzione StorageGRID a due siti, sono presenti almeno due repliche di ogni oggetto e 6 repliche di tutti i metadati. In caso di ripristino dopo un errore, gli aggiornamenti dall'interruzione verranno sincronizzati automaticamente con il sito/nodi ripristinati. Con solo 2 siti, è improbabile che si riesca a raggiungere un RPO pari a zero in scenari di guasto che vanno oltre la perdita completa del sito.
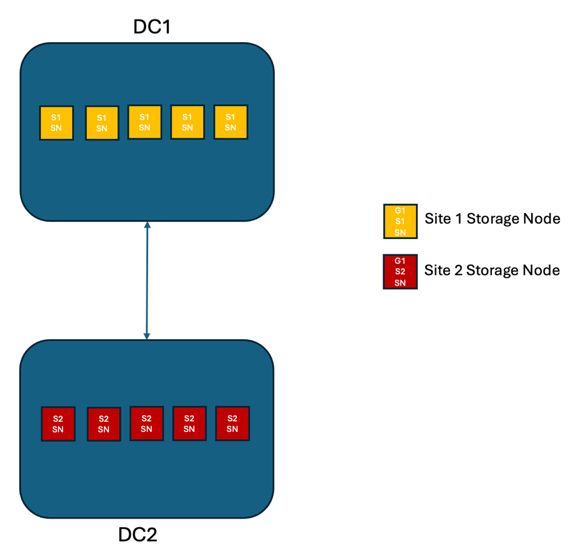
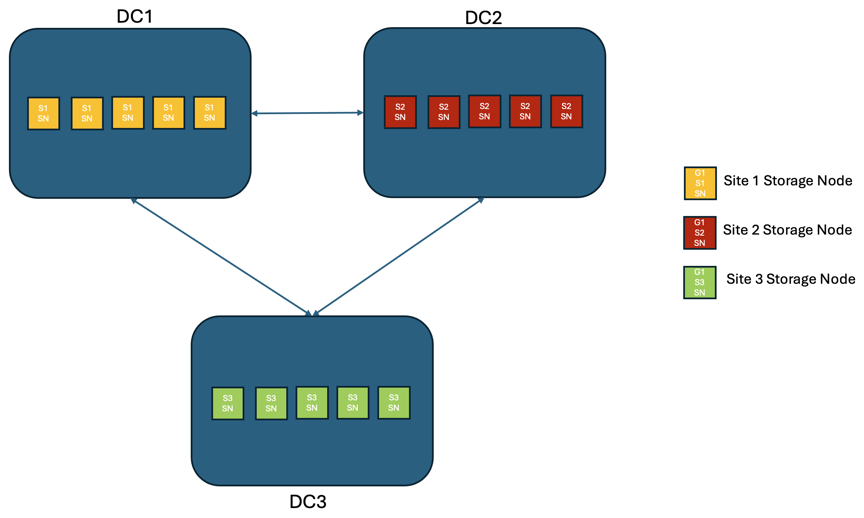
Scenario 2:
In una soluzione StorageGRID di tre o più siti, sono presenti almeno 3 repliche o 3 blocchi EC di ogni oggetto e 9 repliche di tutti i metadati. In caso di ripristino dopo un errore, gli aggiornamenti dall'interruzione verranno sincronizzati automaticamente con il sito/nodi ripristinati. Con tre o più siti è possibile raggiungere un RPO pari a zero.
Scenari di guasti su più siti
| Guasto | Risultato a 2 siti + Legacy Strong Global | 3 o più siti risultato + Quorum Strong Global |
|---|---|---|
Guasto al disco a nodo singolo |
Ogni appliance utilizza gruppi di dischi multipli e può sostenere almeno 1 dischi per gruppo di guasti senza interruzioni o perdita di dati. |
Ogni appliance utilizza gruppi di dischi multipli e può sostenere almeno 1 dischi per gruppo di guasti senza interruzioni o perdita di dati. |
Guasto a un singolo nodo in un sito |
Nessuna interruzione delle operazioni o perdita di dati. |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasto a più nodi in un solo sito |
Interruzione delle operazioni dei client dirette a questo sito senza perdita di dati. Le operazioni dirette all'altro sito rimangono senza interruzioni e non perdono dati. |
Le operazioni vengono dirette a tutti gli altri siti mantenendo interruzioni e senza perdita di dati. |
Guasto a nodo singolo in più siti |
Nessuna interruzione o perdita di dati se:
Operazioni interrotte e rischio di perdita di dati se:
|
Nessuna interruzione o perdita di dati se:
Operazioni interrotte e rischio di perdita di dati se:
|
Guasto a un singolo sito |
Alcune operazioni del client verranno interrotte finché il problema non verrà risolto. Le operazioni GET e HEAD continueranno senza interruzioni. Ridurre la coerenza del bucket a lettura dopo nuova scrittura o inferiore per continuare le operazioni senza interruzioni in questo stato di errore. |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasti a un singolo sito e a un nodo singolo |
Alcune operazioni del client verranno interrotte finché il problema non verrà risolto. Le operazioni HEAD continueranno senza interruzioni. Le operazioni GET continueranno senza interruzioni se esiste una copia replicata o un numero sufficiente di blocchi EC. Ridurre la coerenza del bucket a lettura dopo nuova scrittura o inferiore per continuare le operazioni senza interruzioni in questo stato di errore. |
Nessuna interruzione delle operazioni o perdita di dati. Possibile perdita di dati a seconda del numero di copie replicate. La codifica Local Erasure può impedire la perdita di dati. |
Singolo sito più un nodo da ciascun sito rimanente |
Esistono solo due siti. Vedere: Singolo sito più un singolo nodo. |
Le operazioni verranno interrotte se non sarà possibile raggiungere il quorum della replica dei metadati. Ridurre la coerenza del bucket a lettura dopo nuova scrittura o inferiore per continuare le operazioni senza interruzioni in questo stato di errore. Possibile perdita di dati per guasto permanente a seconda del numero di copie replicate. La codifica Local Erasure può impedire la perdita di dati. |
Guasto multi-sito |
Non rimangono siti operativi. I dati andranno persi se almeno un sito non potrà essere recuperato nella sua interezza. |
Le operazioni verranno interrotte se non sarà possibile raggiungere il quorum della replica dei metadati. Ridurre la coerenza del bucket a lettura dopo nuova scrittura o inferiore per continuare le operazioni senza interruzioni in questo stato di errore. Possibile perdita di dati per guasto permanente se non rimangono sufficienti blocchi codificati per la cancellazione. La codifica di cancellazione locale o le copie replicate possono impedire la perdita di dati. |
Isolamento della rete di un sito |
le operazioni del client saranno interrotte finché il problema non sarà risolto. Ridurre la coerenza del bucket a lettura dopo nuova scrittura o inferiore per continuare le operazioni senza interruzioni in questo stato di errore. Nessuna perdita di dati |
Le operazioni saranno interrotte per il sito isolato, ma non si verificherà alcuna perdita di dati. Ridurre la coerenza del bucket a lettura dopo nuova scrittura o inferiore per continuare le operazioni senza interruzioni in questo stato di errore. Nessuna interruzione delle operazioni nei siti rimanenti e nessuna perdita di dati. |
Distribuzione multi-sito multi-grid
Per aggiungere un ulteriore livello di ridondanza, questo scenario impiegherà due cluster StorageGRID e utilizzerà la replica tra griglie per mantenerli sincronizzati. Per questa soluzione, ogni cluster StorageGRID avrà tre siti. Due siti saranno utilizzati per l'archiviazione degli oggetti e dei metadati, mentre il terzo sito sarà utilizzato esclusivamente per i metadati. Entrambi i sistemi saranno configurati con una regola ILM bilanciata per archiviare in modo sincrono gli oggetti utilizzando la codifica di cancellazione in ciascuno dei due siti dati. I bucket saranno configurati con il modello di coerenza globale Quorum Strong. Ogni griglia sarà configurata con replica bidirezionale tra griglie su ogni bucket. Ciò garantisce la replicazione asincrona tra le regioni. Facoltativamente, è possibile implementare un bilanciatore del carico globale per gestire le richieste ai gruppi ad alta disponibilità del bilanciatore del carico integrato di entrambi i sistemi StorageGRID per ottenere un RPO pari a zero.
La soluzione utilizzerà quattro posizioni equamente suddivise in due regioni. La regione 1 conterrà i 2 siti di memorizzazione della griglia 1 come griglia primaria della regione e il sito di metadati della griglia 2. La regione 2 conterrà i 2 siti di memorizzazione della griglia 2 come griglia primaria della regione e il sito di metadati della griglia 1. In ogni regione la stessa posizione può ospitare il sito di archiviazione della griglia primaria della regione e il sito di sola metadati della griglia delle altre regioni. L'utilizzo dei soli nodi di metadati come il terzo sito fornirà la coerenza richiesta per i metadati, non duplicando lo storage degli oggetti in tale posizione.
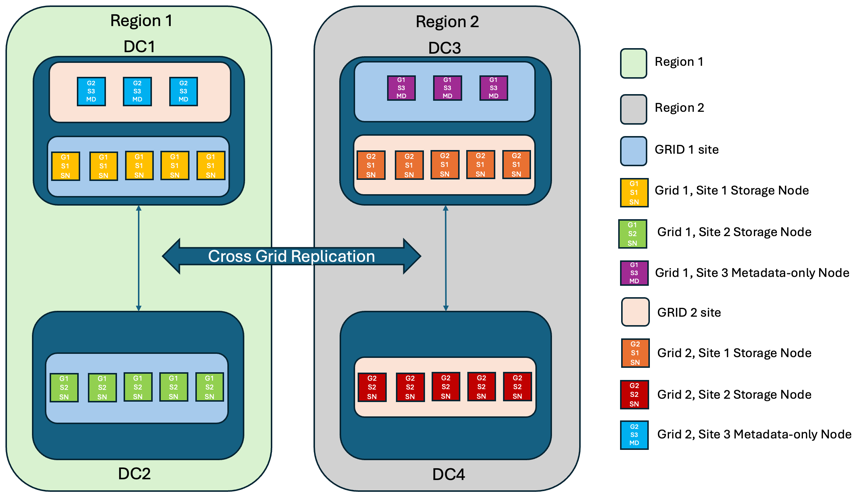
Questa soluzione con quattro ubicazioni separate offre ridondanza completa di due sistemi StorageGRID separati che mantengono un RPO di 0 e sfrutteranno sia la replica sincrona multi-sito che la replica asincrona multi-grid. È possibile guastare qualsiasi sito mantenendo operazioni client senza interruzioni su entrambi i sistemi StorageGRID.
Questa soluzione prevede quattro copie sottoposte a erasure coding per ciascun oggetto e 18 repliche di tutti i metadati. Ciò consente più scenari di errore senza impatto sulle operazioni dei client. In caso di errore, gli aggiornamenti del ripristino dal black-out verranno sincronizzati automaticamente con il sito/i nodi guasti.
Scenari di guasto multisito e multi-grid
| Guasto | Risultato |
|---|---|
Guasto al disco a nodo singolo |
Ogni appliance utilizza gruppi di dischi multipli e può sostenere almeno 1 dischi per gruppo di guasti senza interruzioni o perdita di dati. |
Guasto a un singolo nodo in un sito in un grid |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasto a un singolo nodo in un sito in ciascun grid |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasto di più nodi in un sito in una griglia |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasto a più nodi in un sito in ciascun grid |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasto a un singolo nodo in più siti in un grid |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasto a un singolo nodo in più siti in ciascun grid |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasto a un singolo sito in una griglia |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasto a un singolo sito in ciascun grid |
Nessuna interruzione delle operazioni o perdita di dati. |
Guasti a un singolo sito e a un nodo in un grid |
Nessuna interruzione delle operazioni o perdita di dati. |
Singolo sito più un nodo da ciascun sito rimanente in un singolo grid |
Nessuna interruzione delle operazioni o perdita di dati. |
Errore di singola posizione |
Nessuna interruzione delle operazioni o perdita di dati. |
Errore di singola posizione in ciascuna griglia DC1 e DC3 |
Le operazioni verranno interrotte fino a quando il guasto non verrà risolto o la coerenza del bucket non verrà ridotta; ogni grid avrà perso 2 siti Tutti i dati sono ancora presenti in 2 postazioni |
Errore di singola posizione in ciascuna griglia DC1 e DC4 o DC2 e DC3 |
Nessuna interruzione delle operazioni o perdita di dati. |
Errore di singola posizione in ciascuna griglia DC2 e DC4 |
Nessuna interruzione delle operazioni o perdita di dati. |
Isolamento della rete di un sito |
Le operazioni per il sito isolato verranno interrotte, ma nessun dato andrà perso Nessuna interruzione delle operazioni nei siti rimanenti o perdita di dati. |
Conclusione
L'obiettivo di zero recovery point objective (RPO) con StorageGRID è un obiettivo critico per garantire la conservazione e la disponibilità dei dati in caso di guasti del sito. Sfruttando le solide strategie di replica di StorageGRID, tra cui la replica sincrona multisito e la replica asincrona multi-grid, le organizzazioni possono mantenere operazioni ininterrotte dei client e garantire la coerenza dei dati in più posizioni. L'implementazione delle policy ILM (Information Lifecycle Management) e l'utilizzo di nodi basati solo sui metadati migliorano ulteriormente la resilienza e le prestazioni del sistema. Con StorageGRID, le aziende possono gestire con sicurezza i propri dati, sapendo che rimangono accessibili e coerenti anche in caso di complessi scenari di guasto. Questo approccio completo alla gestione e alla replica dei dati sottolinea l'importanza di una pianificazione e di un'esecuzione meticolose per il raggiungimento di un RPO pari a zero e la salvaguardia di informazioni preziose.