

NetApp StorageGRID e analisi dei big data
 Suggerisci modifiche
Suggerisci modifiche
Casi d'utilizzo di NetApp StorageGRID
La soluzione di storage a oggetti NetApp StorageGRID offre scalabilità, disponibilità dei dati, sicurezza e performance elevate. Le organizzazioni di ogni dimensione e settore utilizzano StorageGRID S3 per un'ampia gamma di casi d'utilizzo. Analizziamo alcuni scenari tipici:
Analisi dei big data: StorageGRID S3 viene spesso utilizzato come data Lake, dove le aziende memorizzano grandi quantità di dati strutturati e non strutturati per l'analisi utilizzando strumenti come Apache Spark, Splunk Smartstore e Dremio.
Tiering dati: i clienti NetApp utilizzano la funzionalità FabricPool di ONTAP per spostare automaticamente i dati tra un Tier locale ad alte prestazioni in StorageGRID. Il tiering libera il costoso storage flash per i dati hot, mantenendo i dati cold altamente disponibili su storage a oggetti a basso costo. Ciò massimizza performance e risparmi.
Backup dei dati e ripristino di emergenza: le aziende possono utilizzare StorageGRID S3 come soluzione affidabile e conveniente per il backup dei dati critici e il ripristino in caso di emergenza.
Archiviazione dei dati per le applicazioni: StorageGRID S3 può essere utilizzato come backend di archiviazione per le applicazioni, consentendo agli sviluppatori di archiviare e recuperare facilmente file, immagini, video e altri tipi di dati.
Distribuzione dei contenuti: StorageGRID S3 può essere utilizzato per archiviare e distribuire contenuti statici di siti web, file multimediali e download di software agli utenti di tutto il mondo, sfruttando la distribuzione geografica e lo spazio dei nomi globale di StorageGRID per una distribuzione dei contenuti rapida e affidabile.
Archivio dati: StorageGRID offre diversi tipi di storage e supporta il tiering in opzioni di storage pubblico a lungo termine a basso costo, rendendolo una soluzione ideale per l'archiviazione e la conservazione a lungo termine dei dati che devono essere conservati per scopi di conformità o cronologici.
Casi di utilizzo dello storage a oggetti
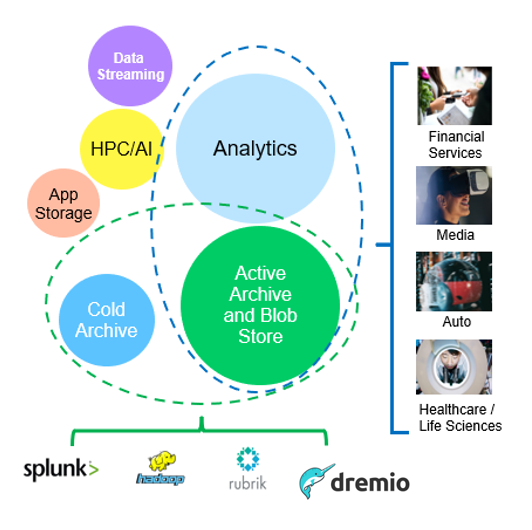
Tra questi, l'analisi dei big data è uno dei casi di utilizzo più importanti e l'andamento del suo utilizzo sta aumentando.
Perché scegliere StorageGRID per i data Lake?
-
Maggiore collaborazione - massiccia condivisione multi-sito, multi-tenancy con accesso API standard del settore
-
Costi operativi ridotti: Semplicità operativa di una singola architettura scale-out automatizzata con riparazione automatica
-
Scalabilità: Diversamente dalle tradizionali soluzioni Hadoop e data warehouse, lo storage a oggetti StorageGRID S3 separa lo storage dalle risorse di calcolo e dai dati, consentendo al business di scalare le proprie esigenze di storage man mano che crescono.
-
Durata e affidabilità: I StorageGRID offrono una durata del 99,999999999%, il che significa che i dati memorizzati sono altamente resistenti alla perdita di dati. Inoltre, offre un'elevata disponibilità per garantire che i dati siano sempre accessibili.
-
Sicurezza: StorageGRID offre varie funzionalità di sicurezza, tra cui crittografia, policy per il controllo degli accessi, gestione del ciclo di vita dei dati, blocco degli oggetti e versioni per proteggere i dati archiviati in bucket S3
StorageGRID S3 Data Lake
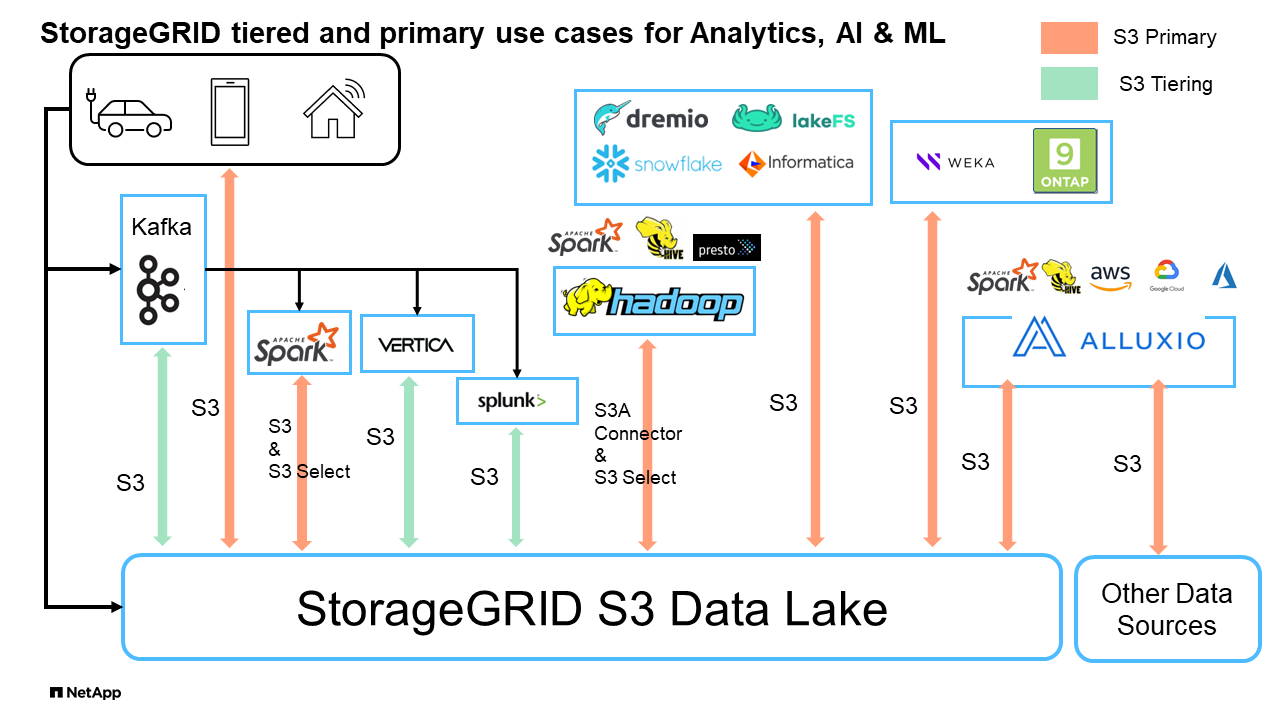
Benchmarking di Data warehouse e Lakehouses con storage a oggetti S3: Uno studio comparativo
Questo articolo presenta un benchmark completo di vari ecosistemi di data warehouse e lakehouse utilizzando NetApp StorageGRID. L'obiettivo è determinare quale sistema offre le migliori prestazioni con lo storage a oggetti S3. Consulta questo "Apache Iceberg: La guida definitiva" per saperne di più sulle architetture di data warehouse/lakehouse e sui formati delle tabelle (Parquet e Iceberg).
-
Strumento benchmark - TPC-DS - https://www.tpc.org/tpcds/
-
Ecosistemi di big data
-
Cluster di macchine virtuali, ciascuno con 128G GB di RAM e 24 vCPU, storage SSD per disco di sistema
-
Hadoop 3.3.5 con Hive 3.1.3 (1 nodi nome + 4 nodi dati)
-
Delta Lake con Spark 3.2.0 (1 master + 4 dipendenti) e Hadoop 3.3.5
-
Dremio v25,2 (1 coordinatore + 5 esecutori)
-
Trino v438 (1 coordinatore + 5 lavoratori)
-
Starburst v453 (1 coordinatore + 5 lavoratori)
-
-
Storage a oggetti
-
NetApp® StorageGRID^® 11,8 con bilanciamento del carico 3 x SG6060 + 1x SG1000
-
Protezione degli oggetti - 2 copie (il risultato è simile a EC 2+1)
-
-
Dimensioni del database 1000GB
-
La cache è stata disabilitata in tutti gli ecosistemi per ogni test di query utilizzando il formato Parquet. Per il formato Iceberg, abbiamo confrontato il numero di richieste GET S3 e il tempo totale di query tra scenari con cache disabilitata e scenari con cache abilitata.
TPC-DS include 99 query SQL complesse progettate per il benchmarking. Abbiamo misurato il tempo totale impiegato per eseguire tutte le 99 query e abbiamo condotto un'analisi dettagliata esaminando il tipo e il numero di richieste S3. I nostri test hanno confrontato l'efficienza di due formati di tabella popolari: Parquet e Iceberg.
Risultato query TPC-DS con formato tabella parquet
| Ecosistema | Alveare | Lago Delta | Dremio | Trino | Starburst |
|---|---|---|---|---|---|
TPCDS 99 query |
1084 1 |
55 |
36 |
32 |
28 |
S3 richieste di ripartizione |
OTTIENI |
1.117.184 |
2.074.610 |
3.939.690 |
1.504.212 |
1.495.039 |
osservazione: |
80% range get di 2KB a 2MB da 32MB oggetti, 50 - 100 richieste/sec |
Il range del 73% è inferiore a 100KB da 32MB oggetti, 1000 - 1400 richieste/sec |
90% 1M byte range get from 256MB objects, 2500 - 3000 requests/sec |
Dimensioni del range: 50% inferiore a 100KB, 16% circa 1MB, 27% 2MB-9MB, 3500 - 4000 richieste/sec |
Dimensioni del range: 50% inferiore a 100KB, 16% circa 1MB, 27% 2MB-9MB, 4000 - 5000 richiesta/sec |
Elenca oggetti |
312.053 |
24.158 |
120 |
509 |
512 |
TESTA |
156.027 |
12.103 |
96 |
0 |
0 |
TESTA |
982.126 |
922.732 |
0 |
0 |
0 |
Richieste totali |
2.567.390 |
3.033.603 |
3.939,906 |
1.504.721 |
1 Impossibile completare la query numero 72
Risultato query TPC-DS con formato tabella Iceberg
| Ecosistema | Dremio | Trino | Starburst |
|---|---|---|---|
TPCDS 99 query + minuti totali (cache disattivata) |
22 |
28 |
22 |
TPCDS 99 query + minuti totali 2 (cache abilitata) |
16 |
28 |
21,5 |
S3 richieste di ripartizione |
GET (OTTIENI) (cache disattivata) |
1.985.922 |
938.639 |
931.582 |
GET (OTTIENI) (cache abilitata) |
611.347 |
30.158 |
3.281 |
osservazione: |
Dimensioni di RICEZIONE intervallo: 67% 1MB, 15% 100KB, 10% 500KB, 3500 - 4500 richieste/sec |
Dimensioni del range: 42% inferiore a 100KB, 17% circa 1MB, 33% 2MB-9MB, 3500 - 4000 richieste/sec |
Dimensioni del range: 43% inferiore a 100KB, 17% circa 1MB, 33% 2MB-9MB, 4000 - 5000 richieste/sec |
Elenca oggetti |
1465 |
0 |
0 |
TESTA |
1464 |
0 |
0 |
TESTA |
3.702 |
509 |
509 |
Richieste totali (cache disattivata) |
1.992.553 |
939.148 |
2 le prestazioni Trino/Starburst sono causate da colli di bottiglia causati dalle risorse di elaborazione; l'aggiunta di più RAM al cluster riduce il tempo totale di query.
Come mostrato nella prima tabella, Hive è significativamente più lento di altri moderni dati ecosistemi lakehouse. Abbiamo osservato che Hive ha inviato un gran numero di richieste list-objects S3, che in genere sono lente su tutte le piattaforme di storage a oggetti, soprattutto quando si gestiscono bucket contenenti molti oggetti. Ciò aumenta notevolmente la durata complessiva della query. Inoltre, i moderni ecosistemi lakehouse possono inviare in parallelo un elevato numero di richieste GET, che vanno da 2.000 a 5.000 richieste al secondo, rispetto alle richieste da 50 a 100 di Hive al secondo. Il file system standard mimicry di Hive e Hadoop S3A contribuisce alla lentezza di Hive nell'interazione con lo storage a oggetti S3.
L'utilizzo di Hadoop (su storage a oggetti HDFS o S3) con Hive o Spark richiede un'estesa conoscenza di Hadoop e Hive/Spark, oltre a una comprensione dell'interazione delle impostazioni di ogni servizio. Insieme, hanno più di 1.000 impostazioni, molte delle quali sono correlate e non possono essere modificate indipendentemente. Trovare la combinazione ottimale di impostazioni e valori richiede un'enorme quantità di tempo e di lavoro.
Confrontando i risultati di Parquet e Iceberg, notiamo che il formato della tabella è un fattore di prestazioni importante. Il formato della tavola Iceberg è più efficiente del Parquet in termini di numero di S3 richieste, con un numero di richieste inferiore dal 35% al 50% rispetto al formato Parquet.
Le prestazioni di Dremio, Trino o Starburst sono principalmente determinate dalla potenza di calcolo del cluster. Sebbene tutte e tre utilizzino il connettore S3A per la connessione allo storage a oggetti S3, non richiedono Hadoop e la maggior parte delle impostazioni fs.S3A di Hadoop non sono utilizzate da questi sistemi. Questo semplifica il tuning delle performance, eliminando la necessità di imparare e testare le varie impostazioni di Hadoop S3A.
Da questo risultato del benchmark, possiamo concludere che il sistema di analisi dei big data ottimizzato per carichi di lavoro basati su S3 è un importante fattore di performance. I moderni Lakehouse ottimizzano l'esecuzione delle query, utilizzano in modo efficiente i metadati e forniscono un accesso perfetto ai dati S3, producendo performance migliori rispetto a Hive quando si utilizza lo storage S3.
Fare riferimento a questa "pagina" sezione per configurare l'origine dati Dremio S3 con StorageGRID.
Visita i collegamenti riportati di seguito per scoprire come StorageGRID e Dremio collaborano per fornire un'infrastruttura di data Lake moderna ed efficiente e come NetApp è passata da Hive + HDFS a Dremio + StorageGRID per migliorare in modo significativo l'efficienza dell'analisi dei big data.