

USA il connettore S3A di Cloudera Hadoop con StorageGRID
 Suggerisci modifiche
Suggerisci modifiche
Di Angela Cheng
Hadoop è da tempo la preferita dai data scientist. Hadoop consente l'elaborazione distribuita di grandi set di dati tra cluster di computer utilizzando semplici framework di programmazione. Hadoop è stato progettato per scalare da singoli server a migliaia di macchine, con ogni macchina in possesso di calcolo e storage locali.
Perché utilizzare S3A per i flussi di lavoro Hadoop?
Con la crescita del volume di dati nel tempo, l'approccio all'aggiunta di nuove macchine con il proprio calcolo e storage è diventato inefficiente. La scalabilità lineare crea delle sfide per l'utilizzo efficiente delle risorse e la gestione dell'infrastruttura.
Per affrontare queste sfide, il client Hadoop S3A offre i/o dalle performance elevate rispetto allo storage a oggetti S3. L'implementazione di un workflow Hadoop con S3A consente di sfruttare lo storage a oggetti come repository di dati e consente di separare calcolo e storage, il che consente di scalare calcolo e storage in modo indipendente. Il disaccoppiamento di calcolo e storage consente inoltre di dedicare la giusta quantità di risorse per i processi di calcolo e di fornire capacità in base alle dimensioni del set di dati. Pertanto, è possibile ridurre il TCO complessivo per i flussi di lavoro Hadoop.
Configurare S3A Connector per l'utilizzo di StorageGRID
Prerequisiti
-
Un URL endpoint StorageGRID S3, una chiave di accesso s3 tenant e una chiave segreta per il test di connessione Hadoop S3A.
-
Un cluster Cloudera e un'autorizzazione root o sudo a ciascun host del cluster per installare il pacchetto Java.
Ad aprile 2022, Java 11.0.14 con Cloudera 7.1.7 è stato testato rispetto a StorageGRID 11.5 e 11.6. Tuttavia, il numero di versione di Java potrebbe essere diverso al momento di una nuova installazione.
Installare il pacchetto Java
-
Controlla la "Matrice di supporto di Cloudera" per la versione di JDK supportata.
-
Scaricare il "Pacchetto Java 11.x." Che corrisponde al sistema operativo del cluster Cloudera. Copiare questo pacchetto su ciascun host del cluster. In questo esempio, il pacchetto rpm viene utilizzato per CentOS.
-
Accedere a ciascun host come root o utilizzando un account con autorizzazione sudo. Eseguire le seguenti operazioni su ciascun host:
-
Installare il pacchetto:
$ sudo rpm -Uvh jdk-11.0.14_linux-x64_bin.rpm
-
Controllare dove è installato Java. Se sono installate più versioni, impostare la nuova versione installata come predefinita:
alternatives --config java There are 2 programs which provide 'java'. Selection Command ----------------------------------------------- +1 /usr/java/jre1.8.0_291-amd64/bin/java 2 /usr/java/jdk-11.0.14/bin/java Enter to keep the current selection[+], or type selection number: 2
-
Aggiungere questa riga alla fine di
/etc/profile. Il percorso deve corrispondere al percorso della selezione precedente:export JAVA_HOME=/usr/java/jdk-11.0.14
-
Eseguire il seguente comando per rendere effettivo il profilo:
source /etc/profile
-
Configurazione di Cloudera HDFS S3A
Fasi
-
Dalla GUI di Cloudera Manager, selezionare Clusters > HDFS e selezionare Configuration (Configurazione).
-
In CATEGORY (CATEGORIA), selezionare Advanced (Avanzate) e scorrere verso il basso per individuare
Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml. -
Fare clic sul segno (+) e aggiungere le seguenti coppie di valori.
Nome Valore fs.s3a.access.key
<chiave di accesso s3 tenant da StorageGRID>
fs.s3a.secret.key
<chiave segreta s3 tenant da StorageGRID>
fs.s3a.connection.ssl.enabled
[true o false] (l'impostazione predefinita è https se questa voce non è presente)
fs.s3a.endpoint
<StorageGRID S3 endpoint:porta>
fs.s3a.impl
Org.apache.hadoop.fs.s3a.S3AFileSystem
fs.s3a.path.style.access
[true o false] (l'impostazione predefinita è lo stile dell'host virtuale se questa voce non è presente)
Esempio di screenshot
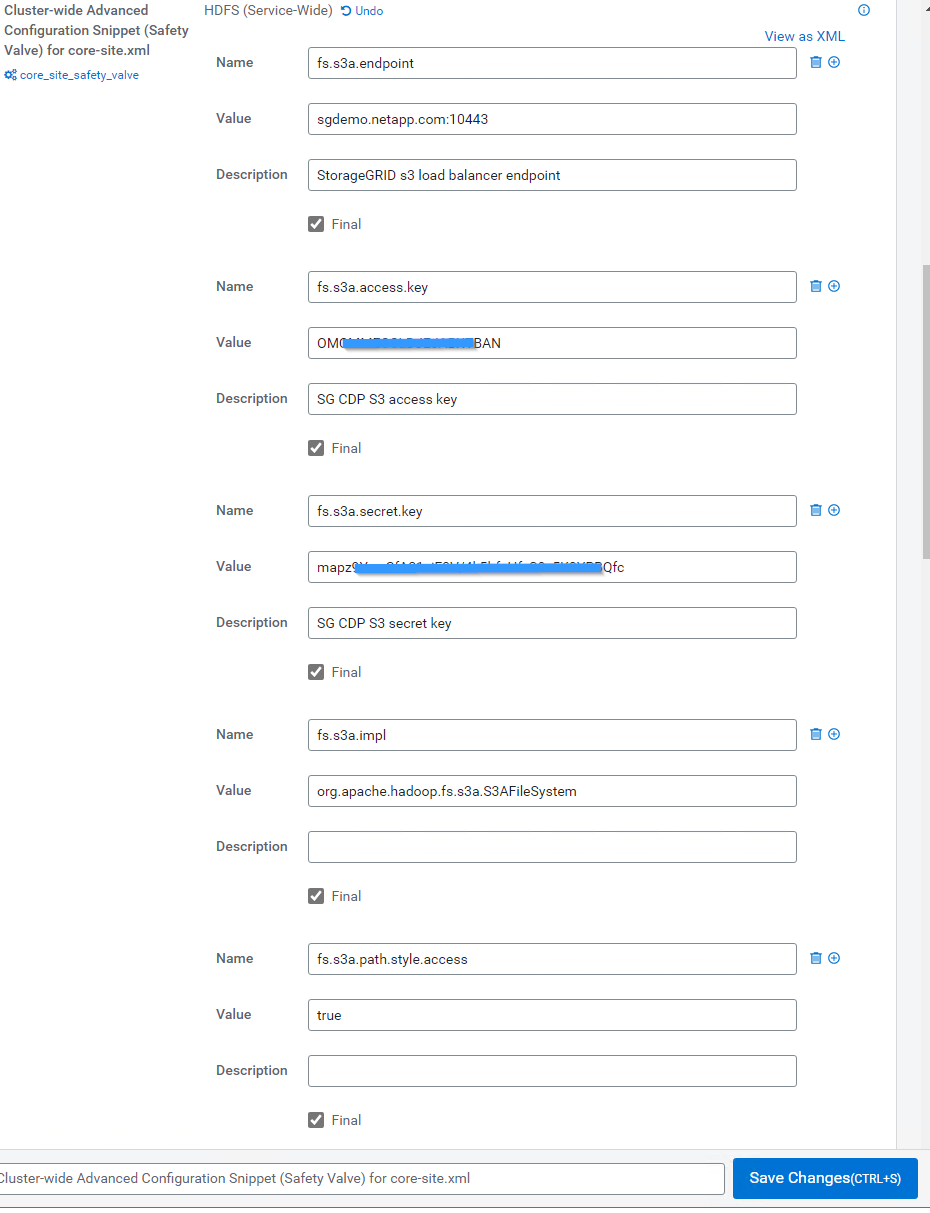
-
Fare clic sul pulsante Save Changes (Salva modifiche). Selezionare l'icona di configurazione obsoleta dalla barra dei menu di HDFS, selezionare Restart stale Services (Riavvia servizi obsoleti) nella pagina successiva e selezionare Restart Now (Riavvia ora).
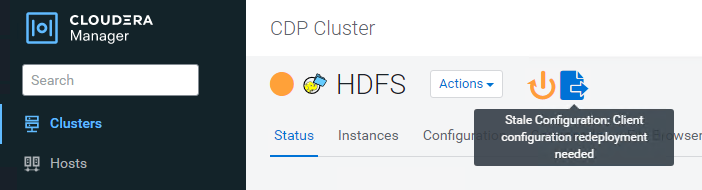
Verificare la connessione S3A a StorageGRID
Eseguire un test di connessione di base
Accedere a uno degli host nel cluster Cloudera e immettere hadoop fs -ls s3a://<bucket-name>/.
Nell'esempio seguente viene utilizzato il path syle con un bucket hdfs-test preesistente e un oggetto test.
[root@ce-n1 ~]# hadoop fs -ls s3a://hdfs-test/ 22/02/15 18:24:37 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties 22/02/15 18:24:37 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 22/02/15 18:24:37 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started 22/02/15 18:24:37 INFO Configuration.deprecation: No unit for fs.s3a.connection.request.timeout(0) assuming SECONDS Found 1 items -rw-rw-rw- 1 root root 1679 2022-02-14 16:03 s3a://hdfs-test/test 22/02/15 18:24:38 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system... 22/02/15 18:24:38 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped. 22/02/15 18:24:38 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete.
Risoluzione dei problemi
Scenario 1
Utilizzare una connessione HTTPS a StorageGRID e ottenere un handshake_failure errore dopo un timeout di 15 minuti.
Motivo: versione precedente di JRE/JDK che utilizza una suite di crittografia TLS obsoleta o non supportata per la connessione a StorageGRID.
Esempio di messaggio di errore
[root@ce-n1 ~]# hadoop fs -ls s3a://hdfs-test/ 22/02/15 18:52:34 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties 22/02/15 18:52:34 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 22/02/15 18:52:34 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started 22/02/15 18:52:35 INFO Configuration.deprecation: No unit for fs.s3a.connection.request.timeout(0) assuming SECONDS 22/02/15 19:04:51 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system... 22/02/15 19:04:51 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped. 22/02/15 19:04:51 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete. 22/02/15 19:04:51 WARN fs.FileSystem: Failed to initialize fileystem s3a://hdfs-test/: org.apache.hadoop.fs.s3a.AWSClientIOException: doesBucketExistV2 on hdfs: com.amazonaws.SdkClientException: Unable to execute HTTP request: Received fatal alert: handshake_failure: Unable to execute HTTP request: Received fatal alert: handshake_failure ls: doesBucketExistV2 on hdfs: com.amazonaws.SdkClientException: Unable to execute HTTP request: Received fatal alert: handshake_failure: Unable to execute HTTP request: Received fatal alert: handshake_failure
Risoluzione: assicurarsi che JDK 11.x o versione successiva sia installato e impostare la libreria Java predefinita. Fare riferimento a. Installare il pacchetto Java per ulteriori informazioni.
Scenario 2:
Impossibile connettersi a StorageGRID con messaggio di errore Unable to find valid certification path to requested target.
Motivo: il certificato del server endpoint StorageGRID S3 non è attendibile dal programma Java.
Esempio di messaggio di errore:
[root@hdp6 ~]# hadoop fs -ls s3a://hdfs-test/ 22/03/11 20:58:12 WARN impl.MetricsConfig: Cannot locate configuration: tried hadoop-metrics2-s3a-file-system.properties,hadoop-metrics2.properties 22/03/11 20:58:13 INFO impl.MetricsSystemImpl: Scheduled Metric snapshot period at 10 second(s). 22/03/11 20:58:13 INFO impl.MetricsSystemImpl: s3a-file-system metrics system started 22/03/11 20:58:13 INFO Configuration.deprecation: No unit for fs.s3a.connection.request.timeout(0) assuming SECONDS 22/03/11 21:12:25 INFO impl.MetricsSystemImpl: Stopping s3a-file-system metrics system... 22/03/11 21:12:25 INFO impl.MetricsSystemImpl: s3a-file-system metrics system stopped. 22/03/11 21:12:25 INFO impl.MetricsSystemImpl: s3a-file-system metrics system shutdown complete. 22/03/11 21:12:25 WARN fs.FileSystem: Failed to initialize fileystem s3a://hdfs-test/: org.apache.hadoop.fs.s3a.AWSClientIOException: doesBucketExistV2 on hdfs: com.amazonaws.SdkClientException: Unable to execute HTTP request: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target: Unable to execute HTTP request: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
Risoluzione: NetApp consiglia di utilizzare un certificato server emesso da un'autorità pubblica nota per la firma del certificato per garantire che l'autenticazione sia sicura. In alternativa, aggiungere un certificato CA o server personalizzato all'archivio di trust Java.
Completare i seguenti passaggi per aggiungere un certificato CA o server personalizzato StorageGRID all'archivio di trust Java.
-
Eseguire il backup del file caacerts Java predefinito esistente.
cp -ap $JAVA_HOME/lib/security/cacerts $JAVA_HOME/lib/security/cacerts.orig
-
Importare il certificato dell'endpoint StorageGRID S3 nell'archivio di trust Java.
keytool -import -trustcacerts -keystore $JAVA_HOME/lib/security/cacerts -storepass changeit -noprompt -alias sg-lb -file <StorageGRID CA or server cert in pem format>
Suggerimenti per la risoluzione dei problemi
-
Aumentare il livello di log di hadoop per ESEGUIRE IL DEBUG.
export HADOOP_ROOT_LOGGER=hadoop.root.logger=DEBUG,console -
Eseguire il comando e indirizzare i messaggi di log a error.log.
hadoop fs -ls s3a://<bucket-name>/ &>error.log
Di Angela Cheng