

パート 2 - SageMaker でのモデルトレーニングのデータソースとして AWS Amazon FSx for NetApp ONTAP (FSx ONTAP) を活用する
 変更を提案
変更を提案
この記事は、Amazon FSx for NetApp ONTAP (FSx ONTAP) を使用して SageMaker で PyTorch モデルをトレーニングする方法について、具体的にはタイヤ品質分類プロジェクト向けのチュートリアルです。
はじめに
このチュートリアルでは、コンピューター ビジョン分類プロジェクトの実用的な例を示し、SageMaker 環境内で FSx ONTAP をデータ ソースとして利用する ML モデルの構築に関する実践的な体験を提供します。このプロジェクトは、ディープラーニング フレームワークである PyTorch を使用して、タイヤ画像に基づいてタイヤの品質を分類することに重点を置いています。 Amazon SageMaker のデータソースとして FSx ONTAPを使用した機械学習モデルの開発に重点を置いています。
FSx ONTAPとは
Amazon FSx ONTAP は、AWS が提供する完全に管理されたストレージソリューションです。 NetApp のONTAPファイル システムを活用して、信頼性が高く高性能なストレージを提供します。 NFS、SMB、iSCSI などのプロトコルをサポートしているため、さまざまなコンピューティング インスタンスやコンテナーからのシームレスなアクセスが可能になります。このサービスは、優れたパフォーマンスを提供し、高速かつ効率的なデータ操作を保証するように設計されています。また、高い可用性と耐久性も提供し、データのアクセスと保護が維持されます。さらに、 Amazon FSx ONTAPのストレージ容量はスケーラブルなので、ニーズに応じて簡単に調整できます。
前提条件
ネットワーク環境
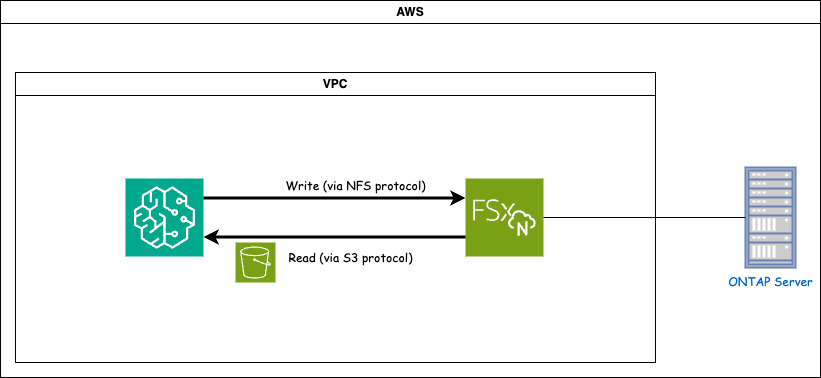
FSx ONTAP (Amazon FSx ONTAP) は AWS ストレージサービスです。これには、 NetApp ONTAPシステム上で実行されるファイルシステムと、それに接続する AWS 管理のシステム仮想マシン (SVM) が含まれます。提供された図では、AWS によって管理されるNetApp ONTAPサーバーは VPC の外部に配置されています。 SVM は SageMaker とNetApp ONTAPシステム間の仲介役として機能し、SageMaker から操作要求を受信して、基盤となるストレージに転送します。 FSx ONTAPにアクセスするには、SageMaker を FSx ONTAPデプロイメントと同じ VPC 内に配置する必要があります。この構成により、SageMaker と FSx ONTAP間の通信とデータ アクセスが保証されます。
データ アクセス
実際のシナリオでは、データ サイエンティストは通常、FSx ONTAPに保存されている既存のデータを活用して機械学習モデルを構築します。ただし、デモンストレーションの目的では、FSx ONTAPファイル システムは作成後最初は空であるため、トレーニング データを手動でアップロードする必要があります。これは、FSx ONTAP をボリュームとして SageMaker にマウントすることで実現できます。ファイルシステムが正常にマウントされると、マウントされた場所にデータセットをアップロードして、SageMaker 環境内でモデルをトレーニングするためにアクセスできるようになります。このアプローチにより、モデルの開発とトレーニングに SageMaker を使用しながら、FSx ONTAPのストレージ容量と機能を活用できます。
データ読み取りプロセスでは、FSx ONTAP をプライベート S3 バケットとして構成する必要があります。詳細な設定手順については、以下を参照してください。"パート 1 - Amazon FSx for NetApp ONTAP (FSx ONTAP) をプライベート S3 バケットとして AWS SageMaker に統合する"
統合の概要
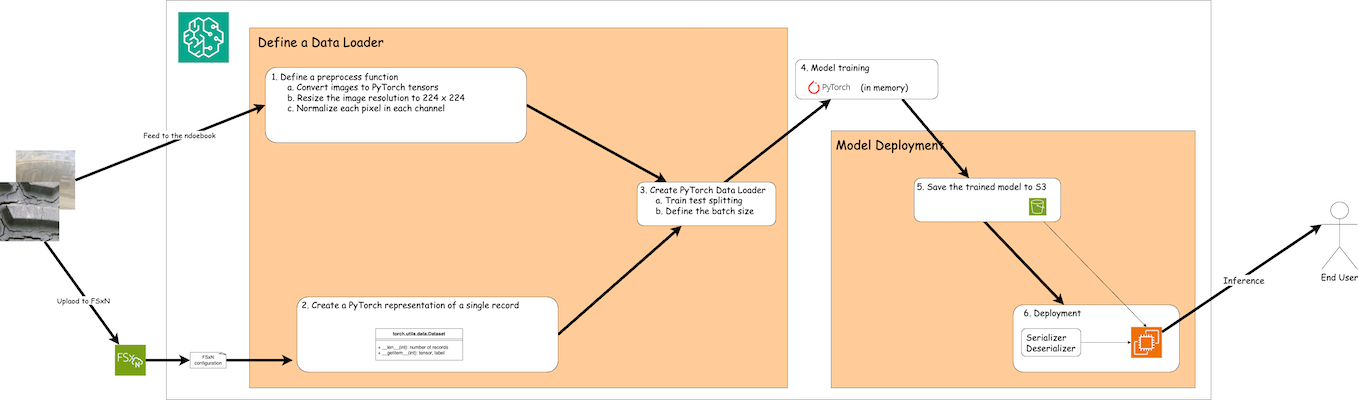
FSx ONTAPのトレーニング データを使用して SageMaker でディープ ラーニング モデルを構築するワークフローは、データ ローダーの定義、モデルのトレーニング、およびデプロイメントという 3 つの主なステップに要約できます。大まかに言えば、これらのステップは MLOps パイプラインの基盤を形成します。ただし、包括的な実装のために、各ステップにはいくつかの詳細なサブステップが含まれます。これらのサブステップには、データの前処理、データセットの分割、モデルの構成、ハイパーパラメータの調整、モデルの評価、モデルの展開などのさまざまなタスクが含まれます。これらの手順により、SageMaker 環境内で FSx ONTAPのトレーニング データを使用してディープ ラーニング モデルを構築および展開するための徹底的かつ効果的なプロセスが保証されます。
ステップバイステップの統合
データLoader
PyTorch ディープラーニング ネットワークをデータでトレーニングするために、データのフィードを容易にするデータ ローダーが作成されます。データ ローダーはバッチ サイズを定義するだけでなく、バッチ内の各レコードを読み取って前処理する手順も決定します。データ ローダーを構成することで、データの処理をバッチで処理し、ディープ ラーニング ネットワークのトレーニングが可能になります。
データ ローダーは 3 つの部分で構成されます。
前処理関数
from torchvision import transforms
preprocess = transforms.Compose([
transforms.ToTensor(),
transforms.Resize((224,224)),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])上記のコード スニペットは、torchvision.transforms モジュールを使用した画像前処理変換の定義を示しています。このチュートリアルでは、一連の変換を適用するための前処理オブジェクトが作成されます。まず、ToTensor() 変換により、画像をテンソル表現に変換します。その後、Resize224,224 変換により、画像のサイズが 224x224 ピクセルの固定サイズに変更されます。最後に、Normalize() 変換は、各チャネルに沿って平均を減算し、標準偏差で割ることでテンソル値を正規化します。正規化に使用される平均値と標準偏差値は、事前トレーニング済みのニューラル ネットワーク モデルでよく使用されます。全体として、このコードは、画像データをテンソルに変換し、サイズを変更し、ピクセル値を正規化することで、画像データをさらに処理したり、事前トレーニング済みモデルに入力したりできるように準備します。
PyTorch データセットクラス
import torch
from io import BytesIO
from PIL import Image
class FSxNImageDataset(torch.utils.data.Dataset):
def __init__(self, bucket, prefix='', preprocess=None):
self.image_keys = [
s3_obj.key
for s3_obj in list(bucket.objects.filter(Prefix=prefix).all())
]
self.preprocess = preprocess
def __len__(self):
return len(self.image_keys)
def __getitem__(self, index):
key = self.image_keys[index]
response = bucket.Object(key)
label = 1 if key[13:].startswith('defective') else 0
image_bytes = response.get()['Body'].read()
image = Image.open(BytesIO(image_bytes))
if image.mode == 'L':
image = image.convert('RGB')
if self.preprocess is not None:
image = self.preprocess(image)
return image, labelこのクラスは、データセット内のレコードの合計数を取得する機能を提供し、各レコードのデータを読み取るメソッドを定義します。 getitem 関数内で、コードは boto3 S3 バケット オブジェクトを使用して、FSx ONTAPからバイナリ データを取得します。 FSx ONTAPからデータにアクセスするためのコード スタイルは、Amazon S3 からデータを読み取る場合と似ています。以降の説明では、プライベート S3 オブジェクト bucket の作成プロセスについて詳しく説明します。
プライベートS3リポジトリとしてのFSx ONTAP
seed = 77 # Random seed
bucket_name = '<Your ONTAP bucket name>' # The bucket name in ONTAP
aws_access_key_id = '<Your ONTAP bucket key id>' # Please get this credential from ONTAP
aws_secret_access_key = '<Your ONTAP bucket access key>' # Please get this credential from ONTAP
fsx_endpoint_ip = '<Your FSx ONTAP IP address>' # Please get this IP address from FSXNimport boto3
# Get session info
region_name = boto3.session.Session().region_name
# Initialize Fsxn S3 bucket object
# --- Start integrating SageMaker with FSXN ---
# This is the only code change we need to incorporate SageMaker with FSXN
s3_client: boto3.client = boto3.resource(
's3',
region_name=region_name,
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key,
use_ssl=False,
endpoint_url=f'http://{fsx_endpoint_ip}',
config=boto3.session.Config(
signature_version='s3v4',
s3={'addressing_style': 'path'}
)
)
# s3_client = boto3.resource('s3')
bucket = s3_client.Bucket(bucket_name)
# --- End integrating SageMaker with FSXN ---SageMaker で FSx ONTAPからデータを読み取るために、S3 プロトコルを使用して FSx ONTAPストレージを指すハンドラーが作成されます。これにより、FSx ONTAP をプライベート S3 バケットとして扱うことができます。ハンドラーの設定には、FSx ONTAP SVM の IP アドレス、バケット名、および必要な資格情報の指定が含まれます。これらの構成項目の取得に関する詳細な説明については、次の文書を参照してください。"パート 1 - Amazon FSx for NetApp ONTAP (FSx ONTAP) をプライベート S3 バケットとして AWS SageMaker に統合する" 。
上記の例では、バケット オブジェクトを使用して PyTorch データセット オブジェクトをインスタンス化しています。データセット オブジェクトについては、後続のセクションでさらに詳しく説明します。
PyTorchデータLoader
from torch.utils.data import DataLoader
torch.manual_seed(seed)
# 1. Hyperparameters
batch_size = 64
# 2. Preparing for the dataset
dataset = FSxNImageDataset(bucket, 'dataset/tyre', preprocess=preprocess)
train, test = torch.utils.data.random_split(dataset, [1500, 356])
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)提供されている例では、バッチ サイズ 64 が指定されており、各バッチに 64 個のレコードが含まれることを示しています。 PyTorch Dataset クラス、前処理関数、およびトレーニング バッチ サイズを組み合わせることで、トレーニング用のデータ ローダーを取得します。このデータ ローダーは、トレーニング フェーズ中にデータセットをバッチで反復処理するプロセスを容易にします。
モデルトレーニング
from torch import nn
class TyreQualityClassifier(nn.Module):
def __init__(self):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,32,(3,3)),
nn.ReLU(),
nn.Conv2d(32,64,(3,3)),
nn.ReLU(),
nn.Flatten(),
nn.Linear(64*(224-6)*(224-6),2)
)
def forward(self, x):
return self.model(x)import datetime
num_epochs = 2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TyreQualityClassifier()
fn_loss = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
model.to(device)
for epoch in range(num_epochs):
for idx, (X, y) in enumerate(data_loader):
X = X.to(device)
y = y.to(device)
y_hat = model(X)
loss = fn_loss(y_hat, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
current_time = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"Current Time: {current_time} - Epoch [{epoch+1}/{num_epochs}]- Batch [{idx + 1}] - Loss: {loss}", end='\r')このコードは標準の PyTorch トレーニング プロセスを実装します。これは、畳み込み層と線形層を使用してタイヤの品質を分類する TyreQualityClassifier と呼ばれるニューラル ネットワーク モデルを定義します。トレーニング ループはデータ バッチを反復処理し、損失を計算し、バックプロパゲーションと最適化を使用してモデルのパラメータを更新します。さらに、監視の目的で現在の時刻、エポック、バッチ、損失を出力します。
モデルの展開
導入
import io
import os
import tarfile
import sagemaker
# 1. Save the PyTorch model to memory
buffer_model = io.BytesIO()
traced_model = torch.jit.script(model)
torch.jit.save(traced_model, buffer_model)
# 2. Upload to AWS S3
sagemaker_session = sagemaker.Session()
bucket_name_default = sagemaker_session.default_bucket()
model_name = f'tyre_quality_classifier.pth'
# 2.1. Zip PyTorch model into tar.gz file
buffer_zip = io.BytesIO()
with tarfile.open(fileobj=buffer_zip, mode="w:gz") as tar:
# Add PyTorch pt file
file_name = os.path.basename(model_name)
file_name_with_extension = os.path.split(file_name)[-1]
tarinfo = tarfile.TarInfo(file_name_with_extension)
tarinfo.size = len(buffer_model.getbuffer())
buffer_model.seek(0)
tar.addfile(tarinfo, buffer_model)
# 2.2. Upload the tar.gz file to S3 bucket
buffer_zip.seek(0)
boto3.resource('s3') \
.Bucket(bucket_name_default) \
.Object(f'pytorch/{model_name}.tar.gz') \
.put(Body=buffer_zip.getvalue())SageMaker ではモデルをデプロイするために S3 に保存する必要があるため、コードは PyTorch モデルを Amazon S3 に保存します。モデルを Amazon S3 にアップロードすると、SageMaker からアクセスできるようになり、デプロイされたモデルのデプロイと推論が可能になります。
import time
from sagemaker.pytorch import PyTorchModel
from sagemaker.predictor import Predictor
from sagemaker.serializers import IdentitySerializer
from sagemaker.deserializers import JSONDeserializer
class TyreQualitySerializer(IdentitySerializer):
CONTENT_TYPE = 'application/x-torch'
def serialize(self, data):
transformed_image = preprocess(data)
tensor_image = torch.Tensor(transformed_image)
serialized_data = io.BytesIO()
torch.save(tensor_image, serialized_data)
serialized_data.seek(0)
serialized_data = serialized_data.read()
return serialized_data
class TyreQualityPredictor(Predictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(
endpoint_name,
sagemaker_session=sagemaker_session,
serializer=TyreQualitySerializer(),
deserializer=JSONDeserializer(),
)
sagemaker_model = PyTorchModel(
model_data=f's3://{bucket_name_default}/pytorch/{model_name}.tar.gz',
role=sagemaker.get_execution_role(),
framework_version='2.0.1',
py_version='py310',
predictor_cls=TyreQualityPredictor,
entry_point='inference.py',
source_dir='code',
)
timestamp = int(time.time())
pytorch_endpoint_name = '{}-{}-{}'.format('tyre-quality-classifier', 'pt', timestamp)
sagemaker_predictor = sagemaker_model.deploy(
initial_instance_count=1,
instance_type='ml.p3.2xlarge',
endpoint_name=pytorch_endpoint_name
)このコードは、SageMaker への PyTorch モデルのデプロイを容易にします。これは、入力データを PyTorch テンソルとして前処理してシリアル化するカスタム シリアライザー TyreQualitySerializer を定義します。 TyreQualityPredictor クラスは、定義されたシリアライザーと JSONDeserializer を利用するカスタム予測子です。このコードは、モデルの S3 の場所、IAM ロール、フレームワークのバージョン、推論のエントリ ポイントを指定するための PyTorchModel オブジェクトも作成します。コードはタイムスタンプを生成し、モデルとタイムスタンプに基づいてエンドポイント名を構築します。最後に、インスタンス数、インスタンスタイプ、生成されたエンドポイント名を指定して、deploy メソッドを使用してモデルがデプロイされます。これにより、PyTorch モデルをデプロイし、SageMaker で推論にアクセスできるようになります。
推論
image_object = list(bucket.objects.filter('dataset/tyre'))[0].get()
image_bytes = image_object['Body'].read()
with Image.open(with Image.open(BytesIO(image_bytes)) as image:
predicted_classes = sagemaker_predictor.predict(image)
print(predicted_classes)これは、デプロイされたエンドポイントを使用して推論を行う例です。