

TR-4570: Apache Spark 向けNetAppストレージ ソリューション: アーキテクチャ、ユースケース、パフォーマンス結果
 変更を提案
変更を提案
Rick Huang、Karthikeyan Nagalingam、 NetApp
このドキュメントでは、Apache Spark アーキテクチャ、顧客のユースケース、およびビッグ データ分析と人工知能 (AI) に関連するNetAppストレージ ポートフォリオに焦点を当てています。また、一般的な Hadoop システムに対して業界標準の AI、機械学習 (ML)、ディープラーニング (DL) ツールを使用してさまざまなテスト結果を示し、適切な Spark ソリューションを選択できるようにします。まず、Spark アーキテクチャ、適切なコンポーネント、および 2 つのデプロイメント モード (クラスターとクライアント) が必要です。
このドキュメントでは、構成の問題に対処するための顧客の使用事例も提供し、ビッグ データ分析や Spark を使用した AI、ML、DL に関連するNetAppストレージ ポートフォリオの概要についても説明します。最後に、Spark 固有のユースケースとNetApp Spark ソリューション ポートフォリオから得られたテスト結果を紹介します。
顧客の課題
このセクションでは、小売、デジタル マーケティング、銀行、個別製造、プロセス製造、政府、専門サービスなどのデータ増加産業におけるビッグ データ分析と AI/ML/DL に関する顧客の課題に焦点を当てます。
予測不可能なパフォーマンス
従来の Hadoop の導入では、通常、市販のハードウェアが使用されます。パフォーマンスを向上させるには、ネットワーク、オペレーティング システム、Hadoop クラスター、Spark などのエコシステム コンポーネント、およびハードウェアを調整する必要があります。各レイヤーをチューニングしても、Hadoop は環境内での高パフォーマンス向けに設計されていない汎用ハードウェア上で実行されるため、望ましいパフォーマンス レベルを達成するのは難しい場合があります。
メディアとノードの障害
通常の状況でも、市販のハードウェアは故障しやすいものです。データ ノード上の 1 つのディスクに障害が発生した場合、Hadoop マスターはデフォルトでそのノードが正常でないと見なします。次に、そのノードの特定のデータをネットワーク経由でレプリカから正常なノードにコピーします。このプロセスにより、Hadoop ジョブのネットワーク パケットの速度が低下します。クラスターは、異常なノードが正常な状態に戻ったときに、データを再度コピーし、過剰に複製されたデータを削除する必要があります。
Hadoopベンダーロックイン
Hadoop ディストリビューターは独自のバージョン管理を備えた独自の Hadoop ディストリビューションを持っているため、顧客はそれらのディストリビューションに縛られてしまいます。ただし、多くの顧客は、特定の Hadoop ディストリビューションに縛られないインメモリ分析のサポートを必要としています。彼らには、配信を変更しながらも分析を持ち運べる自由が必要です。
複数の言語のサポートが不足している
多くの場合、顧客はジョブを実行するために MapReduce Java プログラムに加えて複数の言語のサポートを必要とします。 SQL やスクリプトなどのオプションにより、回答を得るための柔軟性が向上し、データを整理および取得するためのオプションが増え、データを分析フレームワークに移動する速度が速くなります。
使いにくさ
以前から、Hadoop は使いにくいという不満の声が上がっていました。 Hadoop は新しいバージョンが出るたびによりシンプルかつ強力になっているにもかかわらず、この批判は続いています。 Hadoop では、Java および MapReduce プログラミング パターンを理解する必要がありますが、これはデータベース管理者や従来のスクリプト スキルを持つ人にとっては難しい課題です。
複雑なフレームワークとツール
企業の AI チームはさまざまな課題に直面しています。専門的なデータ サイエンスの知識があっても、さまざまなデプロイメント エコシステムおよびアプリケーション用のツールとフレームワークを、単純に相互に変換できるとは限りません。データ サイエンス プラットフォームは、データの移動が容易で、モデルを再利用可能、すぐに使用できるコード、モデルのプロトタイピング、検証、バージョン管理、共有、再利用、本番環境への迅速な導入に関するベスト プラクティスをサポートするツールを備え、Spark 上に構築された対応するビッグ データ プラットフォームとシームレスに統合される必要があります。
NetAppを選ぶ理由
NetApp は、次の方法で Spark エクスペリエンスを向上できます。
-
NetApp NFS ダイレクト アクセス (下の図を参照) を使用すると、データを移動またはコピーすることなく、既存または新規の NFSv3 または NFSv4 データに対してビッグ データ分析ジョブを実行できます。データの複数のコピーを防ぎ、ソースとデータを同期する必要がなくなります。
-
より効率的なストレージとより少ないサーバーレプリケーション。たとえば、 NetApp E シリーズ Hadoop ソリューションでは、データのレプリカが 3 つではなく 2 つ必要であり、 FAS Hadoop ソリューションではデータ ソースは必要ですが、データのレプリケーションやコピーは必要ありません。 NetAppストレージ ソリューションでは、サーバー間のトラフィックも削減されます。
-
ドライブおよびノード障害時の Hadoop ジョブとクラスターの動作が改善されました。
-
データ取り込みパフォーマンスが向上します。
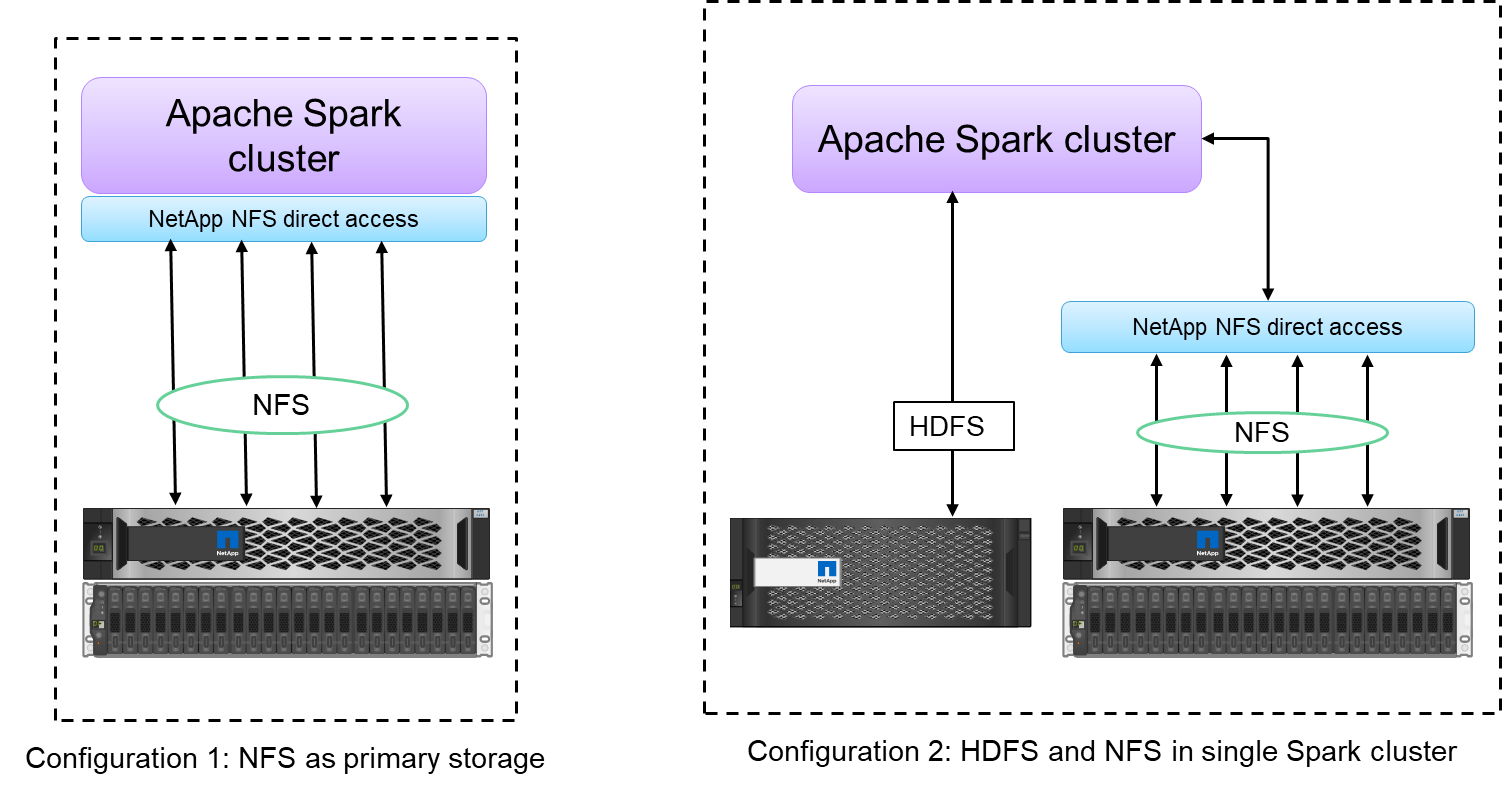
たとえば、金融や医療の分野では、ある場所から別の場所へのデータの移動は法的義務を満たす必要があり、これは簡単な作業ではありません。このシナリオでは、 NetApp NFS ダイレクト アクセスが、元の場所から財務データと医療データを分析します。もう 1 つの重要な利点は、 NetApp NFS ダイレクト アクセスを使用すると、ネイティブ Hadoop コマンドを使用して Hadoop データの保護が簡素化され、 NetAppの豊富なデータ管理ポートフォリオを使用してデータ保護ワークフローが実現されることです。
NetApp NFS ダイレクト アクセスは、Hadoop/Spark クラスターに 2 種類の導入オプションを提供します。
-
デフォルトでは、Hadoop または Spark クラスターは、データ ストレージとデフォルトのファイル システムとして Hadoop 分散ファイル システム (HDFS) を使用します。 NetApp NFS ダイレクト アクセスでは、デフォルトの HDFS を NFS ストレージに置き換えてデフォルトのファイル システムとして使用できるため、NFS データの直接分析が可能になります。
-
別の導入オプションとして、 NetApp NFS ダイレクト アクセスでは、単一の Hadoop または Spark クラスター内の HDFS とともに NFS を追加ストレージとして構成することがサポートされています。この場合、顧客は NFS エクスポートを通じてデータを共有し、HDFS データと同じクラスターからデータにアクセスできます。
NetApp NFS ダイレクト アクセスを使用する主な利点は次のとおりです。
-
現在の場所からデータを分析することで、分析データを HDFS などの Hadoop インフラストラクチャに移動する、時間とパフォーマンスを消費するタスクを回避します。
-
レプリカの数を 3 個から 1 個に減らします。
-
ユーザーがコンピューティングとストレージを切り離して、個別に拡張できるようにします。
-
ONTAPの豊富なデータ管理機能を活用して、エンタープライズ データ保護を提供します。
-
Hortonworks データ プラットフォームの認定。
-
ハイブリッド データ分析の展開を可能にします。
-
動的マルチスレッド機能を活用してバックアップ時間を短縮します。
見る"TR-4657: NetAppハイブリッド クラウド データ ソリューション - 顧客のユースケースに基づく Spark と Hadoop"Hadoop データのバックアップ、クラウドからオンプレミスへのバックアップと災害復旧、既存の Hadoop データでの DevTest の有効化、データ保護とマルチクラウド接続、分析ワークロードの高速化を実現します。
次のセクションでは、Spark のお客様にとって重要なストレージ機能について説明します。
ストレージ階層化
Hadoop ストレージ階層化を使用すると、ストレージ ポリシーに従って、異なるストレージ タイプでファイルを保存できます。ストレージの種類には以下が含まれます hot、 cold 、 warm 、 all_ssd 、 one_ssd 、 そして lazy_persist。
異なるストレージ ポリシーを持つ SSD および SAS ドライブを搭載したNetApp AFFストレージ コントローラと E シリーズ ストレージ コントローラで Hadoop ストレージ階層化の検証を実行しました。 AFF-A800 の Spark クラスターには 4 つのコンピューティング ワーカー ノードがありますが、E シリーズのクラスターには 8 つのコンピューティング ワーカー ノードがあります。これは主に、ソリッド ステート ドライブ (SSD) とハード ドライブ ディスク (HDD) のパフォーマンスを比較するためのものです。
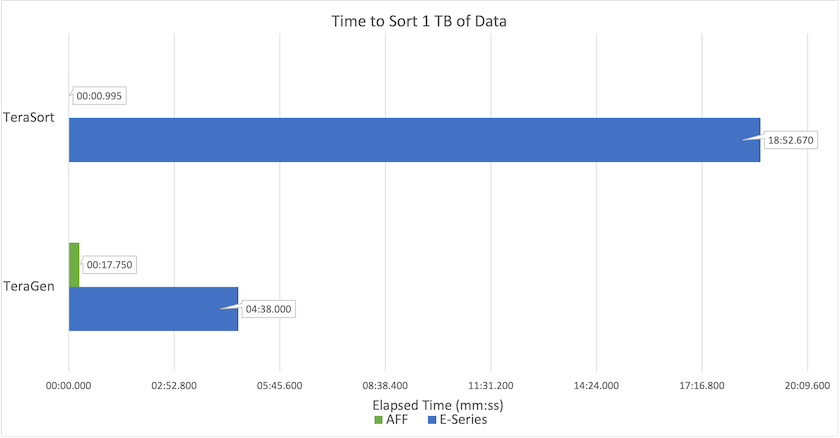
次の図は、Hadoop SSD に対するNetAppソリューションのパフォーマンスを示しています。
-
ベースライン NL-SAS 構成では、8 つのコンピューティング ノードと 96 個の NL-SAS ドライブが使用されました。この構成では、4 分 38 秒で 1 TB のデータが生成されました。見る "TR-3969 NetApp Eシリーズ Hadoop ソリューション"クラスターとストレージ構成の詳細については、こちらをご覧ください。
-
TeraGen を使用すると、SSD 構成では NL-SAS 構成よりも 15.66 倍高速に 1 TB のデータを生成しました。さらに、SSD 構成では、コンピューティング ノードの数とディスク ドライブの数も半分になりました (合計 24 台の SSD ドライブ)。ジョブの完了時間に基づくと、NL-SAS 構成のほぼ 2 倍の速度でした。
-
TeraSort を使用すると、SSD 構成では 1 TB のデータを NL-SAS 構成よりも 1138.36 倍速くソートできました。さらに、SSD 構成では、コンピューティング ノードの数とディスク ドライブの数も半分になりました (合計 24 台の SSD ドライブ)。したがって、ドライブあたりでは、NL-SAS 構成よりも約 3 倍高速になりました。
-
重要なのは、回転ディスクからオールフラッシュへの移行によりパフォーマンスが向上することです。コンピューティングノードの数はボトルネックではありませんでした。 NetApp のオールフラッシュ ストレージを使用すると、ランタイム パフォーマンスが適切に拡張されます。
-
NFS では、データはすべて一緒にプールされることと機能的に同等であり、ワークロードに応じてコンピューティング ノードの数を削減できます。 Apache Spark クラスター ユーザーは、コンピューティング ノードの数を変更するときにデータを手動で再バランスする必要がありません。
パフォーマンスのスケーリング - スケールアウト
AFFソリューションの Hadoop クラスターからさらに計算能力が必要な場合は、適切な数のストレージ コントローラーを備えたデータ ノードを追加できます。 NetApp、ストレージ コントローラ アレイごとに 4 つのデータ ノードから開始し、ワークロードの特性に応じて、ストレージ コントローラごとに 8 つのデータ ノードまで増やすことを推奨しています。
AFFとFAS はインプレース分析に最適です。コンピューティング要件に基づいてノード マネージャーを追加でき、中断のない操作により、ダウンタイムなしでオンデマンドでストレージ コントローラーを追加できます。当社は、NVME メディア サポート、効率保証、データ削減、QOS、予測分析、クラウド階層化、レプリケーション、クラウド展開、セキュリティなど、 AFFおよびFASの豊富な機能を提供します。お客様が要件を満たせるよう、 NetApp は追加のライセンス費用なしで、ファイルシステム分析、クォータ、オンボックス負荷分散などの機能を提供します。 NetApp は、同時ジョブ数、低レイテンシ、シンプルな操作、および 1 秒あたりのギガバイト単位のスループットにおいて競合他社よりも優れたパフォーマンスを発揮します。さらに、 NetApp Cloud Volumes ONTAP は3 つの主要クラウド プロバイダーすべてで実行されます。
パフォーマンスのスケーリング - スケールアップ
スケールアップ機能を使用すると、追加のストレージ容量が必要な場合に、 AFF、 FAS、および E シリーズ システムにディスク ドライブを追加できます。 Cloud Volumes ONTAPでは、ストレージを PB レベルに拡張するために、使用頻度の低いデータをブロック ストレージからオブジェクト ストレージに階層化し、追加のコンピューティングなしでCloud Volumes ONTAPライセンスをスタックするという 2 つの要素を組み合わせています。
複数のプロトコル
NetAppシステムは、SAS、iSCSI、FCP、InfiniBand、NFS など、Hadoop 展開のほとんどのプロトコルをサポートしています。
運用およびサポートソリューション
このドキュメントで説明されている Hadoop ソリューションは、 NetAppによってサポートされています。これらのソリューションは、主要な Hadoop ディストリビューターによって認定されています。詳細については、 "ホートンワークス"サイトとCloudera "認証"そして "partner"サイト。