テスト結果
 変更を提案
変更を提案
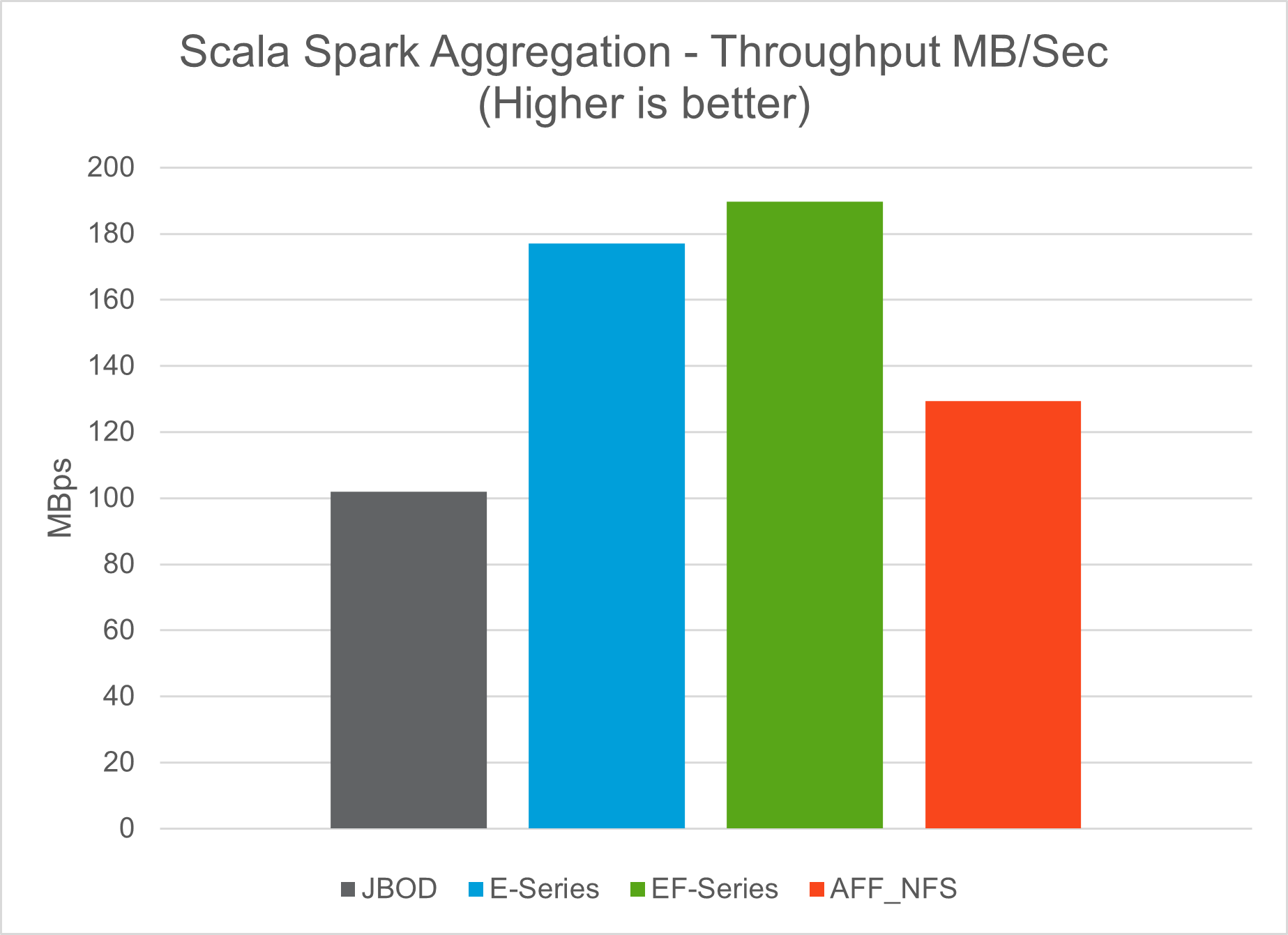
TeraGen ベンチマーク ツールの TeraSort および TeraValidate スクリプトを使用して、E5760、E5724、およびAFF-A800 構成での Spark パフォーマンス検証を測定しました。さらに、Spark NLP パイプラインと TensorFlow 分散トレーニング、Horovod 分散トレーニング、DeepFM による CTR 予測のための Keras を使用したマルチワーカー ディープラーニングという 3 つの主要なユース ケースがテストされました。
E シリーズとStorageGRID の両方の検証では、Hadoop レプリケーション ファクター 2 を使用しました。 AFF検証では、1 つのデータ ソースのみを使用しました。
次の表は、Spark パフォーマンス検証のハードウェア構成を示しています。
| タイプ | Hadoopワーカーノード | ドライブ タイプ | ノードあたりのドライブ数 | ストレージ コントローラ |
|---|---|---|---|---|
SG6060 |
4 |
SAS |
12 |
単一の高可用性(HA)ペア |
E5760 |
4 |
SAS |
60 |
単一のHAペア |
E5724 |
4 |
SAS |
24 |
単一のHAペア |
AFF800 |
4 |
SSD |
6 |
単一のHAペア |
次の表にソフトウェア要件を示します。
| ソフトウェア | version |
|---|---|
RHEL |
7.9 |
OpenJDK ランタイム環境 |
1.8.0 |
OpenJDK 64 ビット サーバー VM |
25.302 |
ギット |
2.24.1 |
GCC/G++ |
11.2.1 |
スパーク |
3.2.1 |
パイスパーク |
3.1.2 |
スパークNLP |
3.4.2 |
テンソルフロー |
2.9.0 |
ケラス |
2.9.0 |
ホロヴォド |
0.24.3 |
金融感情分析
我々は出版した"TR-4910: NetApp AIによる顧客コミュニケーションからの感情分析"エンドツーエンドの会話型AIパイプラインを構築した。 "NetApp DataOps ツールキット" 、 AFFストレージ、 NVIDIA DGX システム。パイプラインは、DataOpsツールキットを活用して、バッチオーディオ信号処理、自動音声認識(ASR)、転移学習、感情分析を実行します。 "NVIDIA Riva SDK" 、そして "タオフレームワーク"。感情分析のユースケースを金融サービス業界に拡大し、SparkNLP ワークフローを構築し、名前付きエンティティの認識などのさまざまな NLP タスク用に 3 つの BERT モデルをロードし、NASDAQ トップ 10 企業の四半期決算発表の文章レベルの感情を取得しました。
次のスクリプト `sentiment_analysis_spark. py`FinBERT モデルを使用して HDFS 内のトランスクリプトを処理し、次の表に示すように、肯定的、中立的、否定的な感情カウントを生成します。
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py hdfs:///data1/Transcripts/ > ./sentiment_analysis_hdfs.log 2>&1 real13m14.300s user557m11.319s sys4m47.676s
次の表は、2016 年から 2020 年までの NASDAQ トップ 10 企業の収益報告の文章レベルの感情分析を示しています。
| 感情の数と割合 | 全10社 | AAPL | AMD | アマゾン | CSCO | グーグル | INTC | マイクロソフト | NVDA |
|---|---|---|---|---|---|---|---|---|---|
陽性数 |
7447 |
1567 |
743 |
290 |
682 |
826 |
824 |
904 |
417 |
中立カウント |
64067 |
6856 |
7596 |
5086 |
6650 |
5914 |
6099 |
5715 |
6189 |
マイナスカウント |
1787 |
253 |
213 |
84 |
189 |
97 |
282 |
202 |
89 |
分類されていない数 |
196 |
0 |
0 |
76 |
0 |
0 |
0 |
1 |
0 |
(合計数) |
73497 |
8676 |
8552 |
5536 |
7521 |
6837 |
7205 |
6822 |
6695 |
パーセンテージで見ると、CEO や CFO が話した文章のほとんどは事実に基づいており、したがって中立的な感情を伝えています。決算説明会では、アナリストは肯定的または否定的な感情を伝える可能性のある質問をします。ネガティブまたはポジティブな感情が、取引当日または翌日の株価にどのような影響を与えるかを定量的にさらに調査する価値があります。
次の表は、NASDAQ 上位 10 社の文章レベルの感情分析をパーセンテージで示したものです。
| 感情の割合 | 全10社 | AAPL | AMD | アマゾン | CSCO | グーグル | INTC | マイクロソフト | NVDA |
|---|---|---|---|---|---|---|---|---|---|
ポジティブ |
10.13% |
18.06% |
8.69% |
5.24% |
9.07% |
12.08% |
11.44% |
13.25% |
6.23% |
中性 |
87.17% |
79.02% |
88.82% |
91.87% |
88.42% |
86.50% |
84.65% |
83.77% |
92.44% |
ネガティブ |
2.43% |
2.92% |
2.49% |
1.52% |
2.51% |
1.42% |
3.91% |
2.96% |
1.33% |
未分類 |
0.27% |
0% |
0% |
1.37% |
0% |
0% |
0% |
0.01% |
0% |
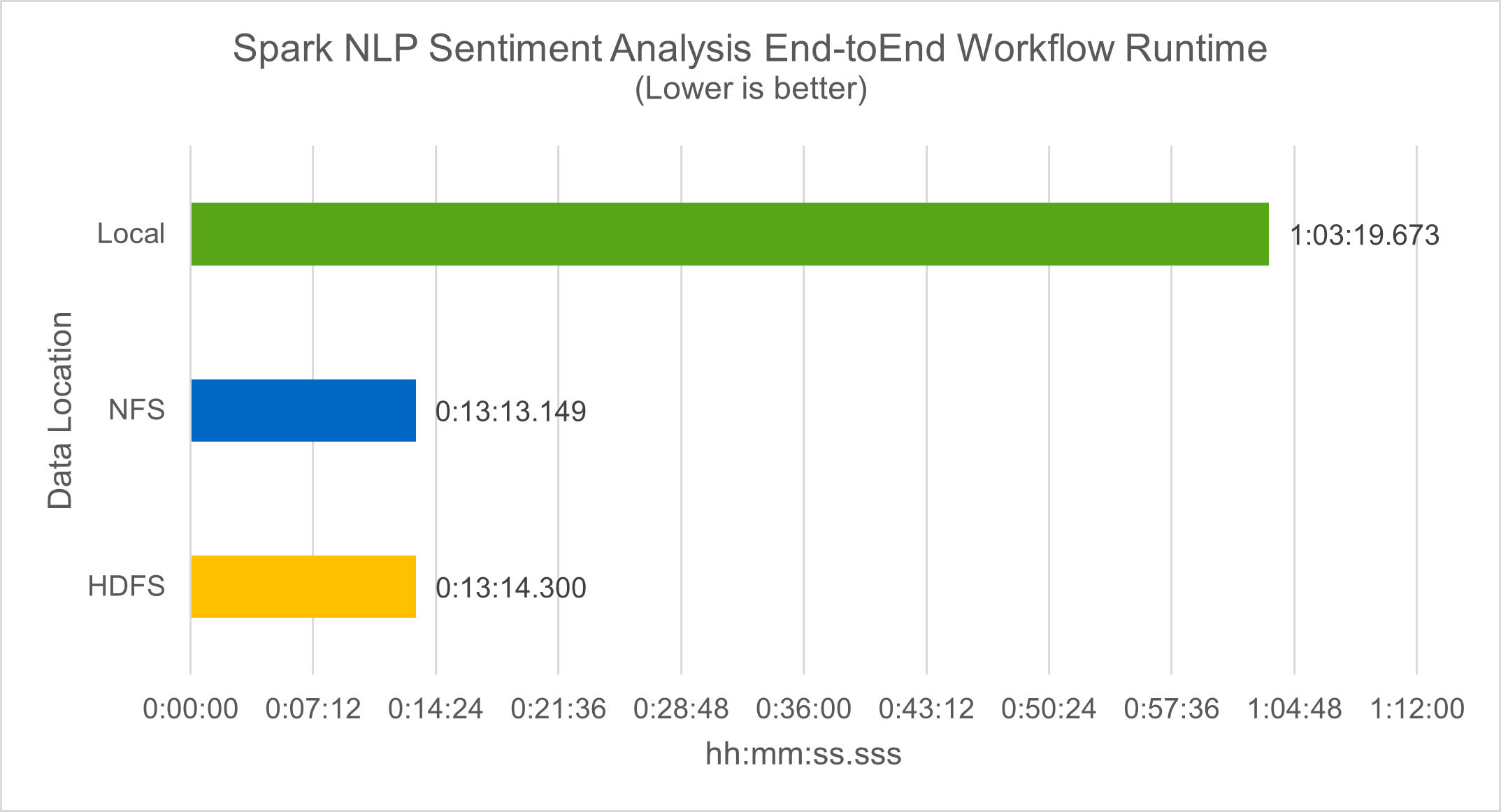
ワークフロー実行時間に関しては、4.78倍の大幅な改善が見られました。 `local`モードを HDFS の分散環境に移行し、NFS を活用することでさらに 0.14% の改善が実現しました。
-bash-4.2$ time ~/anaconda3/bin/spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.3 --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 --conf spark.driver.extraJavaOptions="-Xss10m -XX:MaxPermSize=1024M" --conf spark.executor.extraJavaOptions="-Xss10m -XX:MaxPermSize=512M" /sparkusecase/tr-4570-nlp/sentiment_analysis_spark.py file:///sparkdemo/sparknlp/Transcripts/ > ./sentiment_analysis_nfs.log 2>&1 real13m13.149s user537m50.148s sys4m46.173s
次の図に示すように、データとモデルの並列処理により、データ処理と分散 TensorFlow モデル推論速度が向上しました。ワークフローのボトルネックは事前トレーニング済みモデルのダウンロードであるため、NFS にデータを配置すると実行時間がわずかに改善されました。トランスクリプト データセットのサイズを増やすと、NFS の利点がより明らかになります。
Horovodパフォーマンスによる分散トレーニング
次のコマンドは、Sparkクラスタ内の実行時情報とログファイルを単一のコマンドで生成しました。 master`それぞれ 1 つのコアを持つ 160 個のエグゼキュータを持つノード。メモリ不足エラーを回避するために、実行メモリは 5 GB に制限されました。セクションを参照"主要なユースケースごとの Python スクリプト"データ処理、モデルトレーニング、モデル精度計算の詳細については、 `keras_spark_horovod_rossmann_estimator.py 。
(base) [root@n138 horovod]# time spark-submit --master local --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkusecase/horovod --local-submission-csv /tmp/submission_0.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_local. log 2>&1
10 回のトレーニング エポックで実行された結果は次のとおりです。
real43m34.608s user12m22.057s sys2m30.127s
入力データの処理、DNN モデルのトレーニング、精度の計算、TensorFlow チェックポイントと予測結果の CSV ファイルの生成には 43 分以上かかりました。トレーニング エポックの数を 10 に制限しましたが、実際には、十分なモデル精度を確保するために 100 に設定されることが多いです。トレーニング時間は通常、エポック数に比例して増加します。
次に、クラスタ内で利用可能な4つのワーカーノードを使用して、同じスクリプトを実行しました。 yarn HDFS 内のデータを使用するモード:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir hdfs:///user/hdfs/tr-4570/experiments/horovod --local-submission-csv /tmp/submission_1.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_yarn.log 2>&1
結果として、実行時間は次のように改善されました。
real8m13.728s user7m48.421s sys1m26.063s
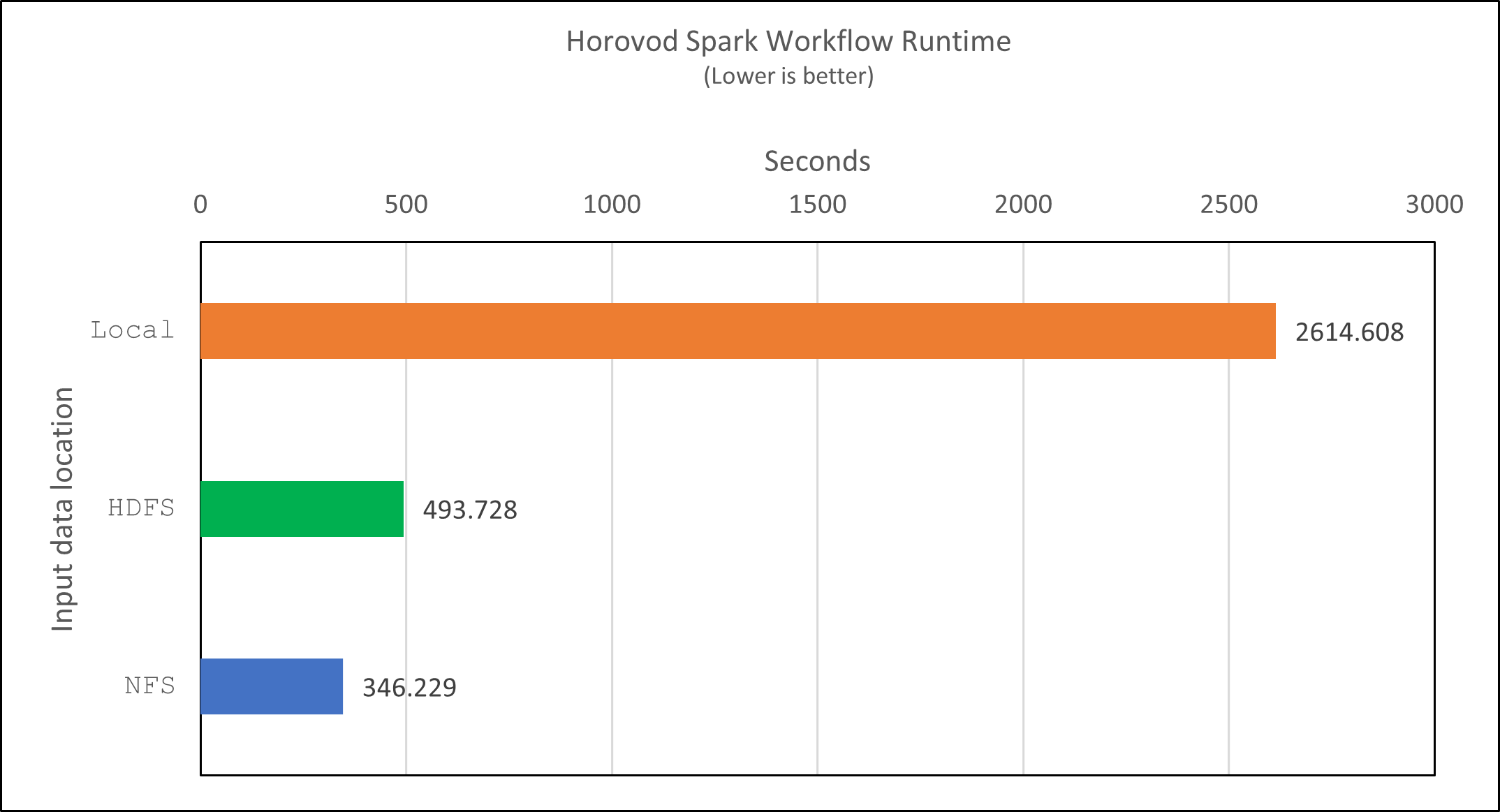
HorovodのモデルとSparkのデータ並列処理により、実行速度が5.29倍向上しました。 yarn`対 `local`10 回のトレーニング エポックを含むモード。これは次の図に凡例とともに示されています。 `HDFS`そして `Local。基盤となる TensorFlow DNN モデルのトレーニングは、利用可能な場合は GPU を使用してさらに高速化できます。私たちはこのテストを実施し、その結果を今後の技術レポートで公開する予定です。
次のテストでは、NFS と HDFS にある入力データの実行時間を比較しました。 AFF A800のNFSボリュームは、 /sparkdemo/horovod Spark クラスター内の 5 つのノード (マスター 1 つ、ワーカー 4 つ) にわたって。前回のテストと同様のコマンドを実行したが、 `--data- dir`パラメータはNFSマウントを指すようになりました:
(base) [root@n138 horovod]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/horovod/keras_spark_horovod_rossmann_estimator.py --epochs 10 --data-dir file:///sparkdemo/horovod --local-submission-csv /tmp/submission_2.csv --local-checkpoint-file /tmp/checkpoint/ > /tmp/keras_spark_horovod_rossmann_estimator_nfs.log 2>&1
NFS を使用した場合の実行時間は次のようになりました。
real 5m46.229s user 5m35.693s sys 1m5.615s
次の図に示すように、さらに 1.43 倍の高速化が実現しました。したがって、 NetAppオールフラッシュ ストレージをクラスターに接続することで、顧客は Horovod Spark ワークフローの高速データ転送と配信のメリットを享受でき、単一ノードで実行する場合と比較して 7.55 倍の高速化を実現できます。
CTR予測パフォーマンスのためのディープラーニングモデル
CTR を最大化するように設計されたレコメンデーション システムでは、低次から高次まで数学的に計算できるユーザー ビヘイビアの背後にある高度な機能の相互作用を学習する必要があります。低次の機能と高次の機能の相互作用は、どちらか一方に偏ることなく、優れたディープラーニング モデルにとって同等に重要です。因数分解マシン ベースのニューラル ネットワークである Deep Factorization Machine (DeepFM) は、推奨用の因数分解マシンと特徴学習用のディープラーニングを新しいニューラル ネットワーク アーキテクチャに組み合わせています。
従来の因数分解マシンは、特徴間の潜在ベクトルの内積としてペアワイズ特徴相互作用をモデル化し、理論的には高次の情報を取得できますが、実際には、機械学習の専門家は、計算とストレージの複雑さが高いため、通常、2 次特徴相互作用のみを使用します。 Googleのようなディープニューラルネットワークの変種 "ワイド&ディープモデル"一方、線形ワイドモデルとディープモデルを組み合わせることで、ハイブリッドネットワーク構造における洗練された機能の相互作用を学習します。
このワイド&ディープ モデルには 2 つの入力があります。1 つは基礎となるワイド モデル用、もう 1 つはディープ モデル用です。後者の部分では依然として専門家による特徴エンジニアリングが必要であり、そのためこの手法を他のドメインに一般化することは困難です。ワイド&ディープ モデルとは異なり、DeepFM は、ワイド部分とディープ部分が同じ入力と埋め込みベクトルを共有するため、特徴エンジニアリングなしで生の特徴を使用して効率的にトレーニングできます。
まずCriteo train.txt (11GB)ファイルをCSVファイルに `ctr_train.csv`NFSマウントに保存 `/sparkdemo/tr-4570-data`使用して `run_classification_criteo_spark.py`セクションから"それぞれの主要なユースケース向けの Python スクリプト。"このスクリプト内では、関数 `process_input_file`タブを削除して挿入するためのいくつかの文字列メソッドを実行します ','`区切り文字として '\n'`改行として。元のファイルのみを処理する必要があることに注意してください `train.txt`一度実行すると、コード ブロックがコメントとして表示されます。
さまざまなDLモデルの以下のテストでは、 ctr_train.csv`入力ファイルとして。その後のテスト実行では、入力CSVファイルは、次のフィールドを含むスキーマを持つSpark DataFrameに読み込まれました。 'label'`整数密な特徴 `['I1', 'I2', 'I3', …, 'I13']、およびスパースな特徴 ['C1', 'C2', 'C3', …, 'C26']。次の `spark-submit`コマンドは入力 CSV を受け取り、クロス検証のために 20% 分割して DeepFM モデルをトレーニングし、10 回のトレーニング エポック後に最適なモデルを選択して、テスト セットでの予測精度を計算します。
(base) [root@n138 ~]# time spark-submit --master yarn --executor-memory 5g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > /tmp/run_classification_criteo_spark_local.log 2>&1
データファイルは `ctr_train.csv`11GBを超える場合は、十分な容量を設定する必要があります `spark.driver.maxResultSize`エラーを回避するには、データセットのサイズよりも大きくする必要があります。
spark = SparkSession.builder \
.master("yarn") \
.appName("deep_ctr_classification") \
.config("spark.jars.packages", "io.github.ravwojdyla:spark-schema-utils_2.12:0.1.0") \
.config("spark.executor.cores", "1") \
.config('spark.executor.memory', '5gb') \
.config('spark.executor.memoryOverhead', '1500') \
.config('spark.driver.memoryOverhead', '1500') \
.config("spark.sql.shuffle.partitions", "480") \
.config("spark.sql.execution.arrow.enabled", "true") \
.config("spark.driver.maxResultSize", "50gb") \
.getOrCreate()
上記において `SparkSession.builder`有効にした設定 "アパッチアロー"はSpark DataFrameをPandas DataFrameに変換します。 `df.toPandas()`方法。
22/06/17 15:56:21 INFO scheduler.DAGScheduler: Job 2 finished: toPandas at /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py:96, took 627.126487 s Obtained Spark DF and transformed to Pandas DF using Arrow.
ランダムに分割した後、トレーニング データセットには 3600 万行以上、テスト セットには 900 万のサンプルが含まれます。
Training dataset size = 36672493 Testing dataset size = 9168124
この技術レポートは GPU を使用せずに CPU テストに焦点を当てているため、適切なコンパイラ フラグを使用して TensorFlow をビルドすることが不可欠です。このステップでは、GPU アクセラレーション ライブラリの呼び出しを回避し、TensorFlow の Advanced Vector Extensions (AVX) と AVX2 命令を最大限に活用します。これらの機能は、ベクトル化された加算、フィードフォワード内の行列乗算、バックプロパゲーション DNN トレーニングなどの線形代数計算用に設計されています。 256 ビット浮動小数点 (FP) レジスタを使用する AVX2 で利用可能な Fused Multiply Add (FMA) 命令は、整数コードとデータ型に最適であり、最大 2 倍の速度向上をもたらします。 FP コードとデータ型の場合、AVX2 は AVX よりも 8% 高速化します。
2022-06-18 07:19:20.101478: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
ソースからTensorFlowを構築するには、 NetAppは以下を使用することを推奨しています。 "バゼル" 。私たちの環境では、シェルプロンプトで次のコマンドを実行してインストールしました。 dnf 、 dnf-plugins 、そしてバゼル。
yum install dnf dnf install 'dnf-command(copr)' dnf copr enable vbatts/bazel dnf install bazel5
ビルド プロセス中に C++17 機能を使用するには、GCC 5 以降を有効にする必要があります。これは、RHEL によって Software Collections Library (SCL) とともに提供されます。次のコマンドはインストールします `devtoolset`RHEL 7.9 クラスター上の GCC 11.2.1:
subscription-manager repos --enable rhel-server-rhscl-7-rpms yum install devtoolset-11-toolchain yum install devtoolset-11-gcc-c++ yum update scl enable devtoolset-11 bash . /opt/rh/devtoolset-11/enable
最後の2つのコマンドは devtoolset-11、使用する /opt/rh/devtoolset-11/root/usr/bin/gcc(GCC 11.2.1)。また、 `git`バージョンは 1.8.3 より大きいです (RHEL 7.9 に付属)。こちらを参照してください "記事"更新用 `git`2.24.1 まで。
最新の TensorFlow マスター リポジトリのクローンがすでに作成されているものと想定します。次に、 `workspace`ディレクトリ `WORKSPACE`AVX、AVX2、FMA を使用してソースから TensorFlow をビルドするためのファイル。実行 `configure`ファイルを開き、正しい Python バイナリの場所を指定します。 "CUDA" GPU を使用していないため、テストでは無効になっています。あ `.bazelrc`ファイルは設定に従って生成されます。さらに、ファイルを編集して設定しました `build --define=no_hdfs_support=false`HDFS サポートを有効にします。参照 `.bazelrc`セクション内"主要なユースケースごとのPythonスクリプト"設定とフラグの完全なリストについては、こちらをご覧ください。
./configure bazel build -c opt --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-mfpmath=both -k //tensorflow/tools/pip_package:build_pip_package
正しいフラグを使用して TensorFlow をビルドした後、次のスクリプトを実行して Criteo ディスプレイ広告データセットを処理し、DeepFM モデルをトレーニングし、予測スコアから受信者操作特性曲線の下の領域 (ROC AUC) を計算します。
(base) [root@n138 examples]# ~/anaconda3/bin/spark-submit --master yarn --executor-memory 15g --executor-cores 1 --num-executors 160 /sparkusecase/DeepCTR/examples/run_classification_criteo_spark.py --data-dir file:///sparkdemo/tr-4570-data > . /run_classification_criteo_spark_nfs.log 2>&1
10 回のトレーニング エポック後、テスト データセットの AUC スコアを取得しました。
Epoch 1/10 125/125 - 7s - loss: 0.4976 - binary_crossentropy: 0.4974 - val_loss: 0.4629 - val_binary_crossentropy: 0.4624 Epoch 2/10 125/125 - 1s - loss: 0.3281 - binary_crossentropy: 0.3271 - val_loss: 0.5146 - val_binary_crossentropy: 0.5130 Epoch 3/10 125/125 - 1s - loss: 0.1948 - binary_crossentropy: 0.1928 - val_loss: 0.6166 - val_binary_crossentropy: 0.6144 Epoch 4/10 125/125 - 1s - loss: 0.1408 - binary_crossentropy: 0.1383 - val_loss: 0.7261 - val_binary_crossentropy: 0.7235 Epoch 5/10 125/125 - 1s - loss: 0.1129 - binary_crossentropy: 0.1102 - val_loss: 0.7961 - val_binary_crossentropy: 0.7934 Epoch 6/10 125/125 - 1s - loss: 0.0949 - binary_crossentropy: 0.0921 - val_loss: 0.9502 - val_binary_crossentropy: 0.9474 Epoch 7/10 125/125 - 1s - loss: 0.0778 - binary_crossentropy: 0.0750 - val_loss: 1.1329 - val_binary_crossentropy: 1.1301 Epoch 8/10 125/125 - 1s - loss: 0.0651 - binary_crossentropy: 0.0622 - val_loss: 1.3794 - val_binary_crossentropy: 1.3766 Epoch 9/10 125/125 - 1s - loss: 0.0555 - binary_crossentropy: 0.0527 - val_loss: 1.6115 - val_binary_crossentropy: 1.6087 Epoch 10/10 125/125 - 1s - loss: 0.0470 - binary_crossentropy: 0.0442 - val_loss: 1.6768 - val_binary_crossentropy: 1.6740 test AUC 0.6337
以前のユースケースと同様に、Spark ワークフロー ランタイムをさまざまな場所に存在するデータと比較しました。次の図は、Spark ワークフロー ランタイムのディープラーニング CTR 予測の比較を示しています。