TR-4912: NetAppを使用した Confluent Kafka 階層型ストレージのベストプラクティスガイドライン
 変更を提案
変更を提案
Karthikeyan Nagalingam、JosephKantilparambil、 NetApp Rankesh Kumar、Confluent
Apache Kafka は、1 日に数兆件のイベントを処理できるコミュニティ分散型のイベント ストリーミング プラットフォームです。当初はメッセージング キューとして考案された Kafka は、分散コミット ログの抽象化に基づいています。 Kafka は 2011 年に LinkedIn によって作成され、オープンソース化されて以来、メッセージ キューから本格的なイベント ストリーミング プラットフォームへと進化してきました。 Confluent は、Confluent Platform を通じて Apache Kafka のディストリビューションを提供します。 Confluent Platform は、大規模な運用におけるオペレーターと開発者の両方のストリーミング エクスペリエンスを強化するように設計された追加のコミュニティ機能と商用機能を Kafka に補完します。
このドキュメントでは、次の内容を提供して、NetApp のオブジェクト ストレージ サービスで Confluent Tiered Storage を使用するためのベスト プラクティス ガイドラインについて説明します。
-
NetAppオブジェクトストレージによる合流性検証 – NetApp StorageGRID
-
階層型ストレージのパフォーマンステスト
-
NetAppストレージ システム上の Confluent に関するベスト プラクティス ガイドライン
Confluent 階層型ストレージを選ぶ理由
Confluent は、特にビッグ データ、分析、ストリーミング ワークロードなど、多くのアプリケーションのデフォルトのリアルタイム ストリーミング プラットフォームになっています。階層型ストレージを使用すると、ユーザーは Confluent プラットフォームでコンピューティングとストレージを分離できます。これにより、データの保存にかかるコスト効率が向上し、事実上無制限の量のデータを保存して、オンデマンドでワークロードをスケールアップ (またはスケールダウン) できるようになり、データやテナントの再調整などの管理タスクが容易になります。 S3 互換ストレージ システムは、これらすべての機能を活用して、すべてのイベントを 1 か所に集めてデータを民主化し、複雑なデータ エンジニアリングの必要性を排除できます。 Kafkaに階層型ストレージを使用する理由の詳細については、以下を参照してください。"Confluentによるこの記事" 。
NetApp instaclustr は、3.8.1 から階層型ストレージを備えた Kafka もサポートしています。詳細はこちらをご覧ください "Kafka 階層型ストレージを使用した Instaclust"
階層型ストレージにNetApp StorageGRID を選ぶ理由
StorageGRIDは、 NetAppによる業界をリードするオブジェクト ストレージ プラットフォームです。 StorageGRID は、Amazon Simple Storage Service (S3) API を含む業界標準のオブジェクト API をサポートする、ソフトウェア定義のオブジェクトベースのストレージ ソリューションです。 StorageGRID は、大規模に非構造化データを保存および管理し、安全で耐久性のあるオブジェクト ストレージを提供します。コンテンツは適切な場所、適切な時間、適切なストレージ層に配置され、ワークフローが最適化され、グローバルに分散されたリッチ メディアのコストが削減されます。
StorageGRIDの最大の差別化要因は、ポリシー主導のデータ ライフサイクル管理を可能にする情報ライフサイクル管理 (ILM) ポリシー エンジンです。ポリシー エンジンはメタデータを使用して、データの存続期間全体にわたってデータの保存方法を管理し、最初にパフォーマンスを最適化し、データが古くなるにつれてコストと耐久性を自動的に最適化します。
Confluent階層化ストレージの有効化
階層型ストレージの基本的な考え方は、データ保存のタスクとデータ処理のタスクを分離することです。この分離により、データ ストレージ層とデータ処理層を個別に拡張することがはるかに容易になります。
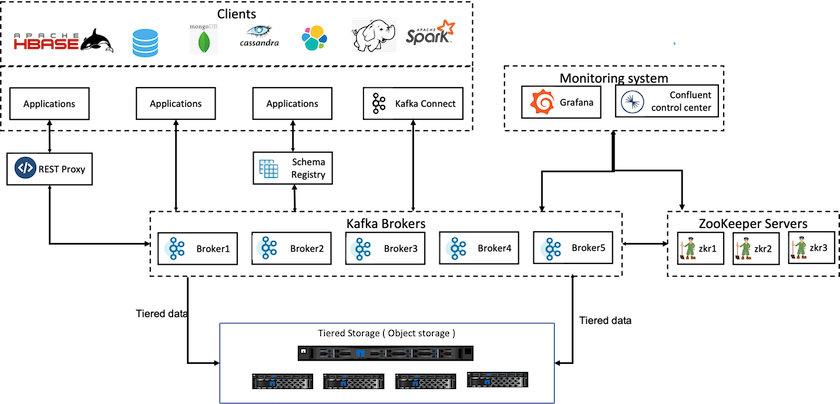
Confluent の階層型ストレージ ソリューションは、2 つの要素に対処する必要があります。まず、LIST 操作の不整合や、時々発生するオブジェクトの利用不可など、一般的なオブジェクト ストアの一貫性と可用性の特性を回避または回避する必要があります。次に、ゾンビ リーダーがオフセット範囲を階層化し続ける可能性を含め、階層化ストレージと Kafka のレプリケーションおよびフォールト トレランス モデル間のやり取りを正しく処理する必要があります。 NetAppオブジェクト ストレージは、一貫したオブジェクト可用性と HA モデルの両方を提供し、疲れたストレージを階層オフセット範囲で利用できるようにします。 NetAppオブジェクト ストレージは、一貫したオブジェクト可用性と HA モデルを提供し、疲れたストレージを階層オフセット範囲で利用できるようにします。
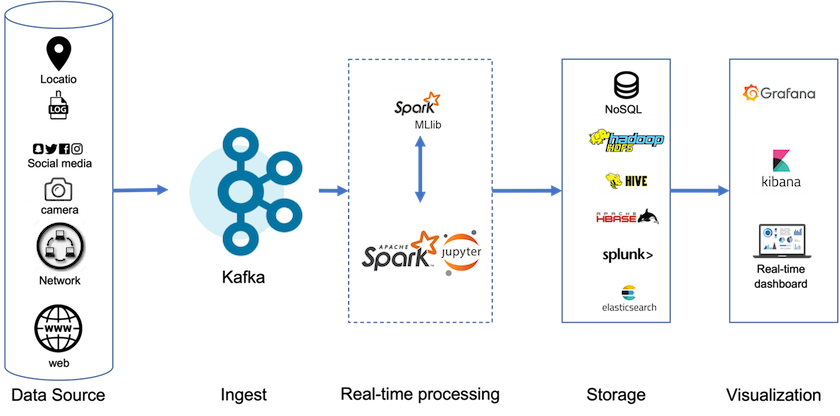
階層型ストレージを使用すると、ストリーミング データの末尾付近の低レイテンシの読み取りと書き込みに高性能プラットフォームを使用できるほか、高スループットの履歴読み取りにNetApp StorageGRIDなどの安価でスケーラブルなオブジェクト ストアを使用することもできます。また、NetApp ストレージ コントローラを使用した Spark 向けの技術ソリューションも用意しており、詳細はこちらをご覧ください。次の図は、Kafka がリアルタイム分析パイプラインにどのように適合するかを示しています。
次の図は、 NetApp StorageGRID がConfluent Kafka のオブジェクト ストレージ層としてどのように適合するかを示しています。