

AFF A900オンプレミスのパフォーマンス概要と検証
 変更を提案
変更を提案
オンプレミスでは、 ONTAP 9.12.1RC1 を搭載したNetApp AFF A900ストレージ コントローラを使用して、Kafka クラスターのパフォーマンスとスケーリングを検証しました。以前のONTAPおよびAFFを使用した階層型ストレージのベスト プラクティスと同じテストベッドを使用しました。
AFF A900 を評価するために、Confluent Kafka 6.2.0 を使用しました。クラスターには 8 つのブローカー ノードと 3 つの Zookeeper ノードが含まれます。パフォーマンス テストには、5 つの OMB ワーカー ノードを使用しました。
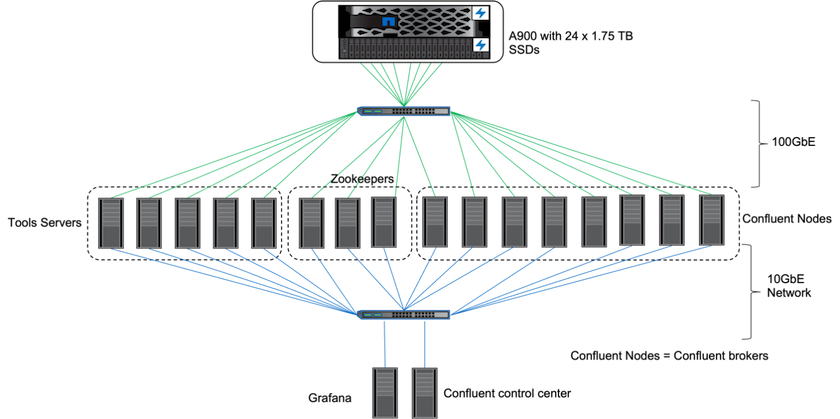
ストレージ構成
NetApp FlexGroups インスタンスを使用して、ログ ディレクトリに単一の名前空間を提供し、リカバリと構成を簡素化しました。ログ セグメント データへの直接パス アクセスを提供するために、NFSv4.1 と pNFS を使用しました。
クライアントのチューニング
各クライアントは、次のコマンドを使用してFlexGroupインスタンスをマウントしました。
mount -t nfs -o vers=4.1,nconnect=16 172.30.0.121:/kafka_vol01 /data/kafka_vol01
さらに、 max_session_slots``デフォルトから `64`に `180。これは、 ONTAPのデフォルトのセッション スロット制限と一致します。
Kafkaブローカーのチューニング
テスト対象システムのスループットを最大化するために、特定の主要なスレッド プールのデフォルト パラメータを大幅に増加しました。ほとんどの構成では、Confluent Kafka のベスト プラクティスに従うことをお勧めします。このチューニングは、ストレージへの未処理の I/O の同時実行性を最大化するために使用されました。これらのパラメータは、ブローカーのコンピューティング リソースとストレージ属性に合わせて調整できます。
num.io.threads=96 num.network.threads=96 background.threads=20 num.replica.alter.log.dirs.threads=40 num.replica.fetchers=20 queued.max.requests=2000
ワークロードジェネレータのテスト方法論
スループット ドライバーとトピック構成には、クラウド テストと同じ OMB 構成を使用しました。
-
FlexGroupインスタンスは、 AFFクラスター上で Ansible を使用してプロビジョニングされました。
--- - name: Set up kafka broker processes hosts: localhost vars: ntap_hostname: 'hostname' ntap_username: 'user' ntap_password: 'password' size: 10 size_unit: tb vserver: vs1 state: present https: true export_policy: default volumes: - name: kafka_fg_vol01 aggr: ["aggr1_a", "aggr2_a", "aggr1_b", "aggr2_b"] path: /kafka_fg_vol01 tasks: - name: Edit volumes netapp.ontap.na_ontap_volume: state: "{{ state }}" name: "{{ item.name }}" aggr_list: "{{ item.aggr }}" aggr_list_multiplier: 8 size: "{{ size }}" size_unit: "{{ size_unit }}" vserver: "{{ vserver }}" snapshot_policy: none export_policy: default junction_path: "{{ item.path }}" qos_policy_group: none wait_for_completion: True hostname: "{{ ntap_hostname }}" username: "{{ ntap_username }}" password: "{{ ntap_password }}" https: "{{ https }}" validate_certs: false connection: local with_items: "{{ volumes }}" -
ONTAP SVM で pNFS が有効になりました。
vserver modify -vserver vs1 -v4.1-pnfs enabled -tcp-max-xfer-size 262144
-
ワークロードは、Cloud Volumes ONTAPと同じワークロード構成を使用して、スループット ドライバーによってトリガーされました。 「定常状態のパフォーマンス " 下に。ワークロードではレプリケーション係数 3 が使用され、ログ セグメントの 3 つのコピーが NFS に保持されました。
sudo bin/benchmark --drivers driver-kafka/kafka-throughput.yaml workloads/1-topic-100-partitions-1kb.yaml
-
最後に、バックログを使用して、消費者が最新のメッセージに追いつく能力を測定するための測定を完了しました。 OMB は、測定の開始時にコンシューマーを一時停止することでバックログを構築します。これにより、バックログの作成 (プロデューサーのみのトラフィック)、バックログの排出 (トピック内の見逃されたイベントをコンシューマーが追いつくコンシューマー中心のフェーズ)、および定常状態の 3 つの異なるフェーズが生成されます。「究極のパフォーマンスとストレージの限界の探求詳細については、「」を参照してください。
定常状態のパフォーマンス
AWS のCloud Volumes ONTAPと AWS の DAS と同様の比較を行うために、OpenMessaging ベンチマークを使用してAFF A900 を評価しました。すべてのパフォーマンス値は、プロデューサー レベルとコンシューマー レベルでの Kafka クラスターのスループットを表します。
Confluent Kafka とAFF A900 を使用した定常状態のパフォーマンスでは、プロデューサーとコンシューマーの両方で 3.4 GBps を超える平均スループットが達成されました。これは、Kafka クラスター全体で 340 万件を超えるメッセージです。 BrokerTopicMetrics の持続スループットをバイト/秒単位で視覚化することで、 AFF A900がサポートする優れた安定したパフォーマンスとトラフィックを確認できます。
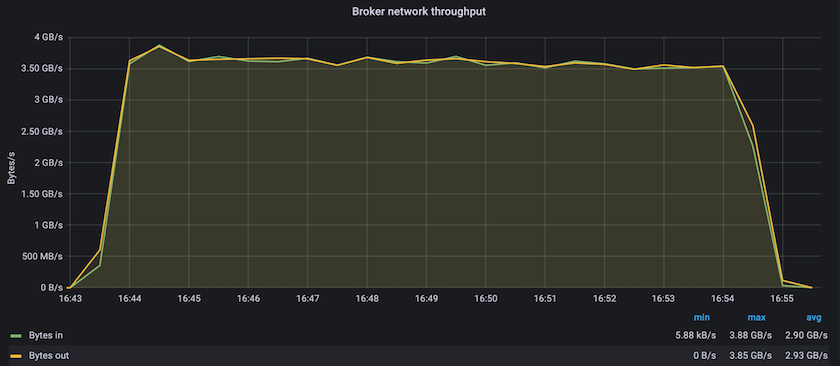
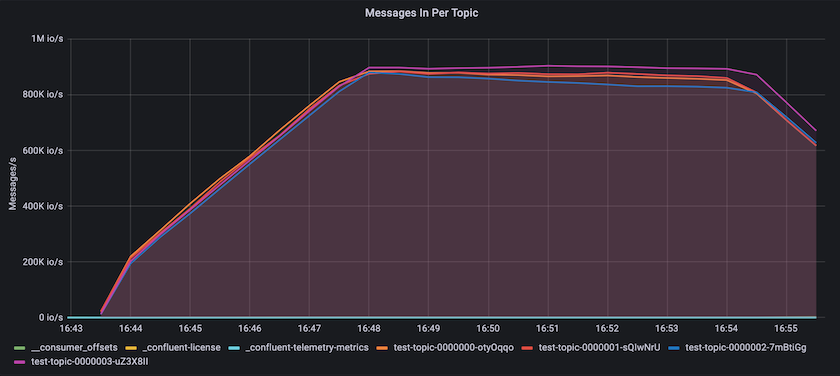
これは、トピックごとに配信されるメッセージのビューと一致します。次のグラフはトピックごとの内訳を示しています。テストした構成では、4 つのトピックにわたってトピックごとに約 90 万件のメッセージが確認されました。
究極のパフォーマンスとストレージの限界の探求
AFFについては、バックログ機能を使用して OMB でもテストしました。バックログ機能は、Kafka クラスターにイベントのバックログが蓄積されている間、コンシューマーのサブスクリプションを一時停止します。このフェーズでは、プロデューサー トラフィックのみが発生し、ログにコミットされるイベントが生成されます。これはバッチ処理またはオフライン分析ワークフローを最もよくエミュレートします。これらのワークフローでは、コンシューマー サブスクリプションが開始され、ブローカー キャッシュからすでに削除されている履歴データを読み取る必要があります。
この構成におけるコンシューマー スループットのストレージ制限を理解するために、プロデューサーのみのフェーズを測定し、A900 が吸収できる書き込みトラフィックの量を把握しました。次のセクションを参照してください。サイズガイドこのデータをどのように活用するかを理解してください。
この測定のプロデューサーのみの部分では、A900 パフォーマンスの限界を押し上げる高いピーク スループットが確認されました (プロデューサーとコンシューマーのトラフィックを処理する他のブローカー リソースが飽和していない場合)。

|
この測定では、メッセージごとのオーバーヘッドを制限し、NFS マウント ポイントへのストレージ スループットを最大化するために、メッセージ サイズを 16k に増やしました。 |
messageSize: 16384 consumerBacklogSizeGB: 4096
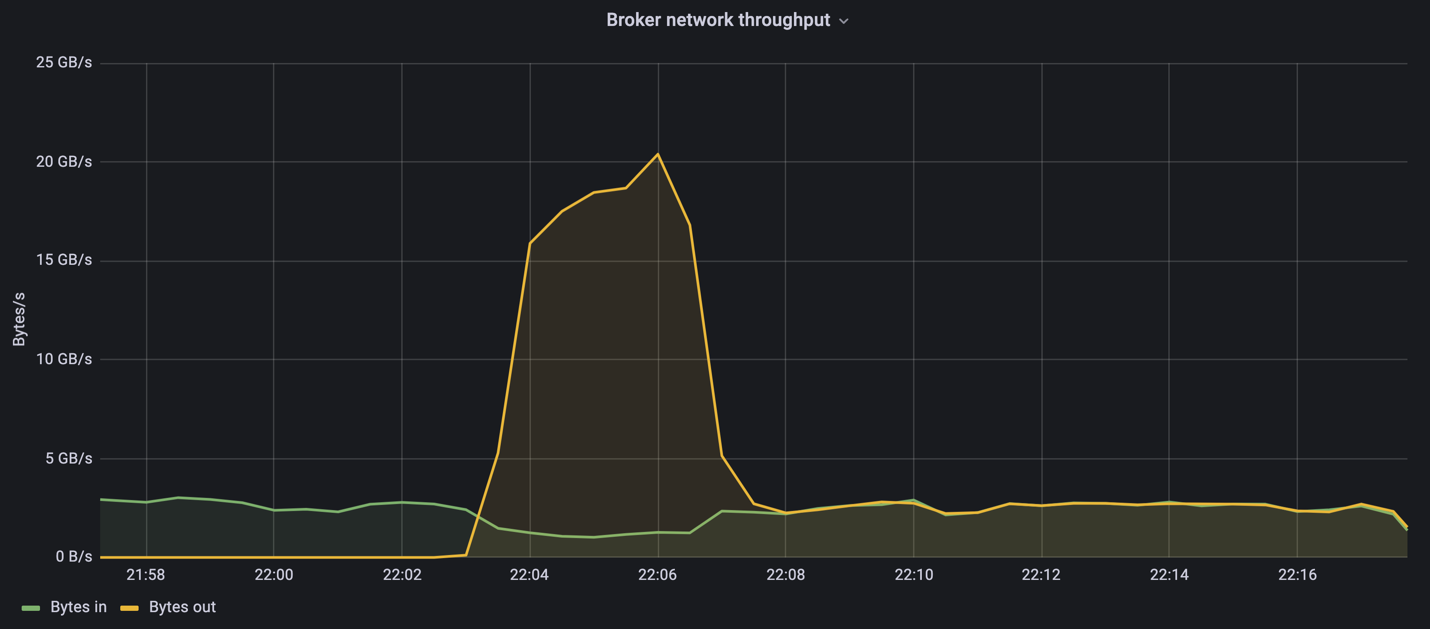
Confluent Kafka クラスターは、ピーク時のプロデューサー スループット 4.03GBps を達成しました。
18:12:23.833 [main] INFO WorkloadGenerator - Pub rate 257759.2 msg/s / 4027.5 MB/s | Pub err 0.0 err/s …
OMB がイベントバックログの入力を完了すると、コンシューマー トラフィックが再開されました。バックログの排出による測定中に、すべてのトピックにわたって 20 GBps を超えるピーク消費者スループットが観測されました。 OMB ログ データを保存する NFS ボリュームへの合計スループットは、約 30 GBps に近づきました。
サイズガイド
Amazon Web Servicesは "サイズガイド"Kafka クラスターのサイズ設定とスケーリング用。
このサイズ設定は、Kafka クラスターのストレージ スループット要件を決定するための便利な式を提供します。
レプリケーション係数 r を持つ tcluster のクラスターに生成される集約スループットの場合、ブローカー ストレージが受信するスループットは次のようになります。
t[storage] = t[cluster]/#brokers + t[cluster]/#brokers * (r-1)
= t[cluster]/#brokers * r
これをさらに簡略化することができます。
max(t[cluster]) <= max(t[storage]) * #brokers/r
この式を使用すると、Kafka ホット層のニーズに適したONTAPプラットフォームを選択できます。
次の表は、さまざまなレプリケーション係数を持つ A900 の予測プロデューサー スループットを示しています。
| 複製係数 | プロデューサースループット(GPps) |
|---|---|
3(測定値) |
3.4 |
2 |
5.1 |
1 |
10.2 |