機能検証 - ばかげた名前変更の修正
 変更を提案
変更を提案
機能検証では、ストレージに NFSv3 をマウントした Kafka クラスターはパーティションの再配分などの Kafka 操作を実行できないのに対し、修正を適用した NFSv4 にマウントされた別のクラスターは中断なく同じ操作を実行できることを示しました。
検証設定
セットアップは AWS 上で実行されます。次の表は、検証に使用されたさまざまなプラットフォーム コンポーネントと環境構成を示しています。
| プラットフォームコンポーネント | 環境設定 |
|---|---|
Confluent Platform バージョン 7.2.1 |
|
すべてのノード上のオペレーティング システム |
RHEL8.7以降 |
NetApp Cloud Volumes ONTAPインスタンス |
シングルノードインスタンス – M5.2xLarge |
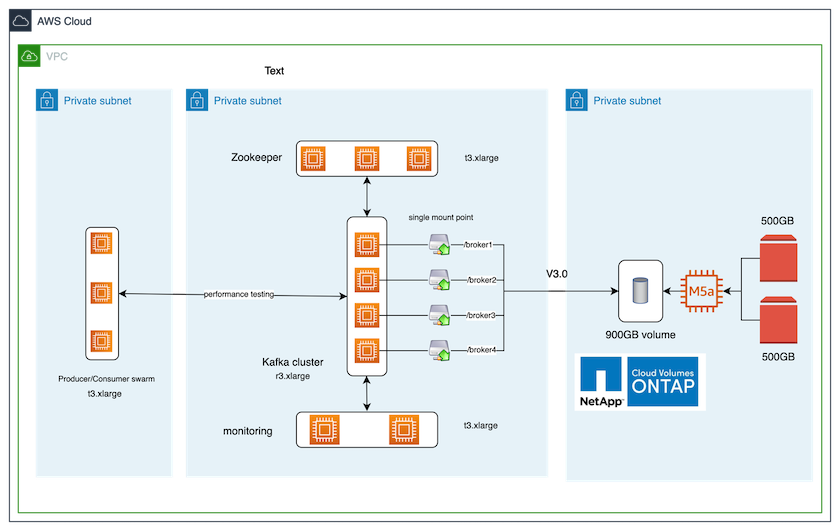
次の図は、このソリューションのアーキテクチャ構成を示しています。
建築の流れ
-
*計算します。*専用サーバーで実行される 3 ノードの Zookeeper アンサンブルを備えた 4 ノードの Kafka クラスターを使用しました。
-
監視。 Prometheus と Grafana の組み合わせには 2 つのノードを使用しました。
-
*作業量。*ワークロードを生成するために、この Kafka クラスターにデータを生成したり、この Kafka クラスターからデータを消費したりできる、別の 3 ノード クラスターを使用しました。
-
*ストレージ。*インスタンスに 2 つの 500 GB GP2 AWS-EBS ボリュームが接続された、単一ノードのNetApp Cloud Volumes ONTAPインスタンスを使用しました。これらのボリュームは、LIF を介して単一の NFSv4.1 ボリュームとして Kafka クラスターに公開されました。
すべてのサーバーに対して、Kafka のデフォルトのプロパティが選択されました。動物園の飼育員の群れにも同じことを行いました。
テストの方法論
-
アップデート `-is-preserve-unlink-enabled true`kafka ボリュームに次のように追加します。
aws-shantanclastrecall-aws::*> volume create -vserver kafka_svm -volume kafka_fg_vol01 -aggregate kafka_aggr -size 3500GB -state online -policy kafka_policy -security-style unix -unix-permissions 0777 -junction-path /kafka_fg_vol01 -type RW -is-preserve-unlink-enabled true [Job 32] Job succeeded: Successful
-
次の違いを持つ 2 つの類似した Kafka クラスターが作成されました。
-
*クラスター1*実稼働対応のONTAPバージョン 9.12.1 を実行するバックエンド NFS v4.1 サーバーは、 NetApp CVO インスタンスによってホストされていました。ブローカーに RHEL 8.7/RHEL 9.1 がインストールされました。
-
*クラスター2*バックエンド NFS サーバーは、手動で作成された汎用 Linux NFSv3 サーバーでした。
-
-
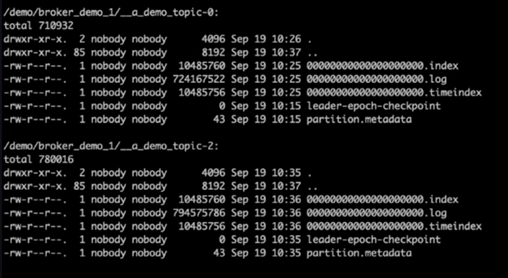
両方の Kafka クラスターにデモ トピックが作成されました。
クラスター 1:

クラスター 2:

-
両方のクラスターの新しく作成されたトピックにデータがロードされました。これは、デフォルトの Kafka パッケージに付属する produced-perf-test ツールキットを使用して実行されました。
./kafka-producer-perf-test.sh --topic __a_demo_topic --throughput -1 --num-records 3000000 --record-size 1024 --producer-props acks=all bootstrap.servers=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092
-
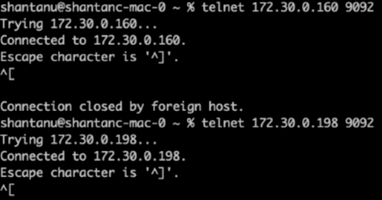
Telnet を使用して、各クラスターのブローカー 1 のヘルス チェックが実行されました。
-
テルネット
172.30.0.160 9092 -
テルネット
172.30.0.198 9092次のスクリーンショットは、両方のクラスター上のブローカーのヘルスチェックが成功したことを示しています。
-
-
NFSv3 ストレージ ボリュームを使用する Kafka クラスターがクラッシュする障害状態をトリガーするために、両方のクラスターでパーティションの再割り当てプロセスを開始しました。パーティションの再割り当ては、
kafka-reassign-partitions.sh。詳細なプロセスは次のとおりです。-
Kafka クラスター内のトピックのパーティションを再割り当てするために、提案された再割り当て構成 JSON を生成しました (これは両方のクラスターに対して実行されました)。
kafka-reassign-partitions --bootstrap-server=172.30.0.160:9092,172.30.0.172:9092,172.30.0.188:9092,172.30.0.123:9092 --broker-list "1,2,3,4" --topics-to-move-json-file /tmp/topics.json --generate
-
生成された再割り当てJSONは、
/tmp/reassignment- file.json。 -
実際のパーティションの再割り当てプロセスは、次のコマンドによって開始されました。
kafka-reassign-partitions --bootstrap-server=172.30.0.198:9092,172.30.0.163:9092,172.30.0.221:9092,172.30.0.204:9092 --reassignment-json-file /tmp/reassignment-file.json –execute
-
-
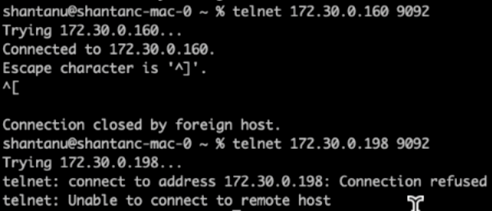
再割り当てが完了してから数分後、ブローカーの別のヘルス チェックで、NFSv3 ストレージ ボリュームを使用しているクラスターが不合理な名前変更の問題に遭遇してクラッシュした一方で、修正が適用されNetApp ONTAP NFSv4.1 ストレージ ボリュームを使用しているクラスター 1 は中断することなく操作を継続していることが示されました。
-
Cluster1-Broker-1 は稼働しています。
-
Cluster2-broker-1 は停止しています。
-
-
Kafka のログ ディレクトリを確認すると、修正が適用されたNetApp ONTAP NFSv4.1 ストレージ ボリュームを使用する Cluster 1 ではパーティション割り当てが適切に行われていたのに対し、汎用 NFSv3 ストレージを使用する Cluster 2 では、名前変更の問題によってパーティション割り当てが適切に行われず、クラッシュが発生していたことが明らかになりました。次の図は、クラスター 2 のパーティションの再バランスを示しています。これにより、NFSv3 ストレージで名前変更の問題が発生しました。
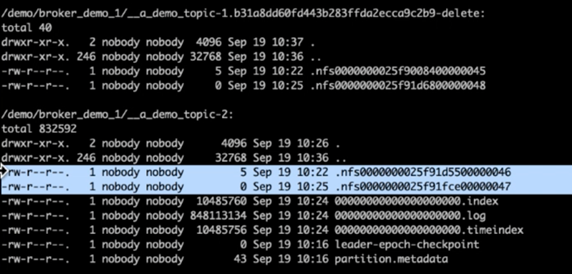
次の図は、 NetApp NFSv4.1 ストレージを使用したクラスター 1 のクリーン パーティションの再バランスを示しています。