Kafka ワークロードにNetApp NFS を使用する理由
 変更を提案
変更を提案
Kafka を使用した NFS ストレージの無意味な名前変更の問題に対する解決策ができたので、Kafka ワークロードにNetApp ONTAPストレージを活用する堅牢なデプロイメントを作成できます。これにより、運用上のオーバーヘッドが大幅に削減されるだけでなく、Kafka クラスターに次のような利点がもたらされます。
-
*Kafka ブローカーの CPU 使用率が削減されました。*分散型NetApp ONTAPストレージを使用すると、ディスク I/O 操作がブローカーから分離され、CPU フットプリントが削減されます。
-
*ブローカーの回復時間が短縮されます。*分散されたNetApp ONTAPストレージは Kafka ブローカー ノード間で共有されるため、従来の Kafka デプロイメントと比較して、データを再構築することなく、いつでも短時間で新しいコンピューティング インスタンスが不良ブローカーを置き換えることができます。
-
*ストレージ効率。*アプリケーションのストレージ層がNetApp ONTAPを通じてプロビジョニングされるようになったため、顧客はインライン データ圧縮、重複排除、圧縮など、 ONTAPに備わっているストレージ効率の利点をすべて活用できます。
これらの利点は、このセクションで詳しく説明するテスト ケースでテストおよび検証されています。
Kafka ブローカーの CPU 使用率の削減
技術仕様は同一だが、ストレージ テクノロジが異なる 2 つの別々の Kafka クラスターで同様のワークロードを実行したところ、全体的な CPU 使用率が DAS よりも低いことがわかりました。 Kafka クラスターがONTAPストレージを使用している場合、全体的な CPU 使用率が低くなるだけでなく、CPU 使用率の増加は DAS ベースの Kafka クラスターよりも緩やかな勾配を示しました。
建築のセットアップ
次の表は、CPU 使用率の削減を示すために使用された環境構成を示しています。
| プラットフォームコンポーネント | 環境設定 |
|---|---|
Kafka 3.2.3 ベンチマークツール: OpenMessaging |
|
すべてのノード上のオペレーティング システム |
RHEL 8.7以降 |
NetApp Cloud Volumes ONTAPインスタンス |
シングルノードインスタンス – M5.2xLarge |
ベンチマークツール
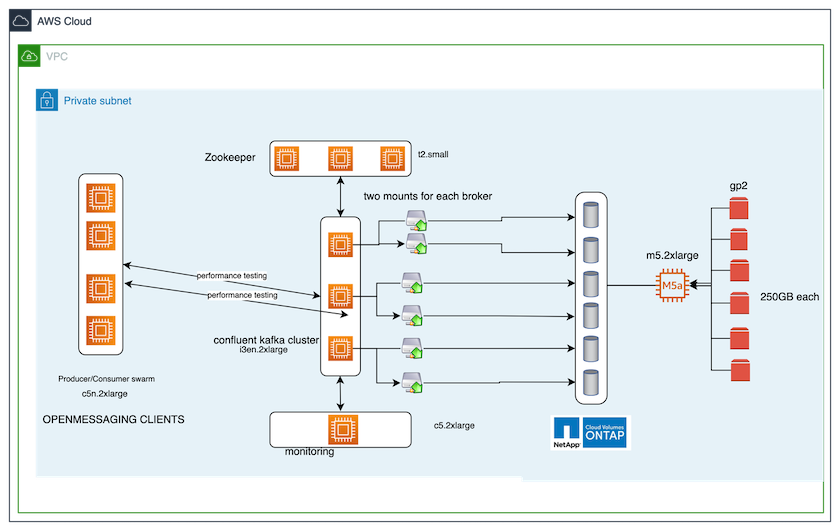
このテストケースで使用したベンチマークツールは "オープンメッセージング"フレームワーク。 OpenMessaging はベンダー中立かつ言語に依存しません。金融、電子商取引、IoT、ビッグデータに関する業界ガイドラインを提供し、異機種システムやプラットフォーム間でのメッセージングおよびストリーミング アプリケーションの開発に役立ちます。次の図は、OpenMessaging クライアントと Kafka クラスターの相互作用を示しています。
-
*計算します。*専用サーバーで実行される 3 ノードの Zookeeper アンサンブルを備えた 3 ノードの Kafka クラスターを使用しました。各ブローカーには、専用の LIF を介してNetApp CVO インスタンス上の単一ボリュームへの 2 つの NFSv4.1 マウント ポイントがありました。
-
監視。 Prometheus と Grafana の組み合わせには 2 つのノードを使用しました。ワークロードを生成するために、この Kafka クラスターにワークロードを生成したり、この Kafka クラスターからワークロードを消費したりできる、独立した 3 ノード クラスターがあります。
-
*ストレージ。*インスタンスにマウントされた 6 つの 250 GB GP2 AWS-EBS ボリュームを備えた単一ノードのNetApp Cloud Volumes ONTAPインスタンスを使用しました。これらのボリュームは、専用の LIF を介して 6 つの NFSv4.1 ボリュームとして Kafka クラスターに公開されました。
-
*構成。*このテスト ケースで構成可能な 2 つの要素は、Kafka ブローカーと OpenMessaging ワークロードでした。
-
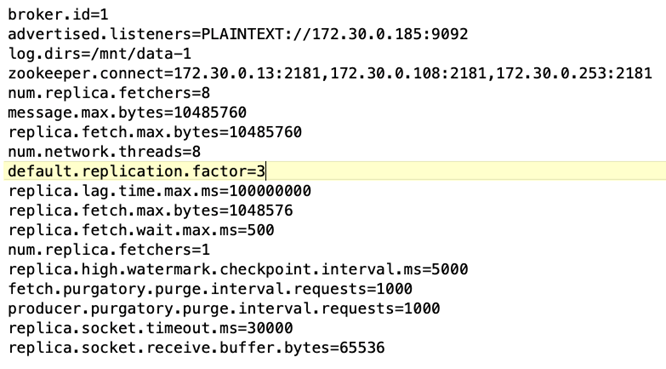
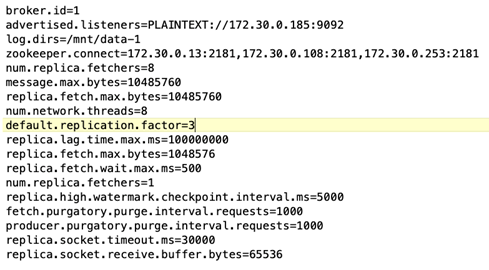
ブローカー設定 Kafka ブローカーには次の仕様が選択されました。以下で強調されているように、すべての測定に複製係数 3 を使用しました。
-
-
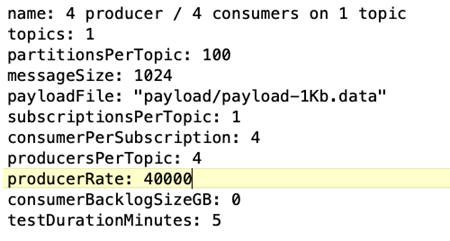
*OpenMessaging ベンチマーク (OMB) ワークロード構成。*以下の仕様が提供されました。以下に強調表示されている目標生産者率を指定しました。
テストの方法論
-
2 つの類似したクラスターが作成され、それぞれ独自のベンチマーク クラスター スウォームのセットを持ちました。
-
クラスター1 NFS ベースの Kafka クラスター。
-
クラスター2 DAS ベースの Kafka クラスター。
-
-
OpenMessaging コマンドを使用して、各クラスターで同様のワークロードがトリガーされました。
sudo bin/benchmark --drivers driver-kafka/kafka-group-all.yaml workloads/1-topic-100-partitions-1kb.yaml
-
生成率の設定は 4 回の反復で増加され、CPU 使用率は Grafana で記録されました。生産率は次のレベルに設定されました。
-
10,000
-
40,000
-
80,000
-
100,000
-
観察
Kafka でNetApp NFS ストレージを使用すると、主に 2 つの利点があります。
-
*CPU 使用率を約 3 分の 1 削減できます。*同様のワークロードでの全体的な CPU 使用率は、DAS SSD と比較して NFS の方が低く、節約幅は生成率が低い場合は 5%、生成率が高い場合は 32% です。
-
*生産率が高い場合の CPU 使用率のドリフトが 3 分の 1 に減少します。*予想どおり、生産率が上がるにつれて、CPU 使用率の増加は上向きに推移しました。ただし、DAS を使用する Kafka ブローカーの CPU 使用率は、低い生成率の場合の 31% から高い生成率の場合の 70% に上昇し、39% 増加しました。ただし、NFS ストレージ バックエンドでは、CPU 使用率は 26% から 38% に上昇し、12% 増加しました。
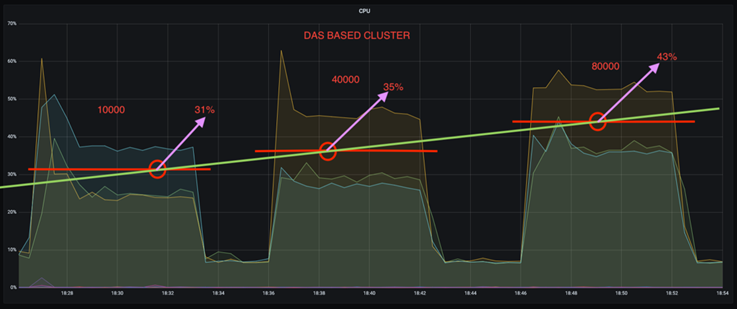
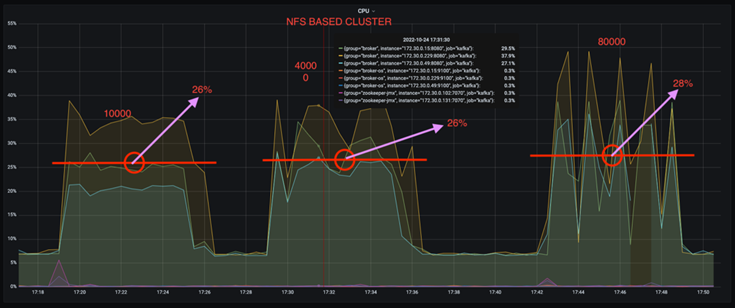
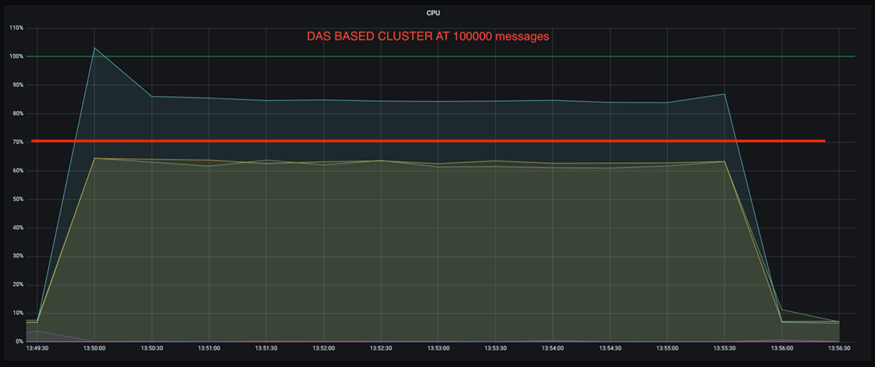
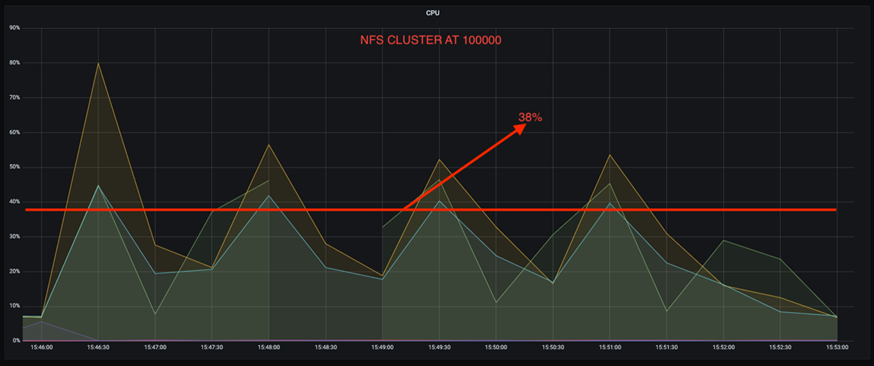
また、100,000 件のメッセージでは、DAS は NFS クラスターよりも CPU 使用率が高くなります。
ブローカーの回復が速い
共有NetApp NFS ストレージを使用すると、Kafka ブローカーの回復が速くなることがわかりました。 Kafka クラスターでブローカーがクラッシュした場合、このブローカーは同じブローカー ID を持つ正常なブローカーに置き換えられます。このテストケースを実行すると、DAS ベースの Kafka クラスターの場合、クラスターは新しく追加された正常なブローカー上でデータを再構築するため、時間がかかることがわかりました。 NetApp NFS ベースの Kafka クラスターの場合、置き換えたブローカーは以前のログ ディレクトリからデータを読み取り続けるため、回復がはるかに速くなります。
建築のセットアップ
次の表は、NAS を使用した Kafka クラスターの環境構成を示しています。
| プラットフォームコンポーネント | 環境設定 |
|---|---|
カフカ 3.2.3 |
|
すべてのノード上のオペレーティング システム |
RHEL8.7以降 |
NetApp Cloud Volumes ONTAPインスタンス |
シングルノードインスタンス – M5.2xLarge |
次の図は、NAS ベースの Kafka クラスターのアーキテクチャを示しています。
-
*計算します。*専用サーバー上で実行される 3 ノードの Zookeeper アンサンブルを備えた 3 ノードの Kafka クラスター。各ブローカーには、専用 LIF を介してNetApp CVO インスタンス上の単一ボリュームへの 2 つの NFS マウント ポイントがあります。
-
監視。 Prometheus と Grafana の組み合わせの 2 つのノード。ワークロードを生成するために、この Kafka クラスターに対して生成および消費できる別の 3 ノード クラスターを使用します。
-
*ストレージ。*インスタンスにマウントされた 6 つの 250 GB GP2 AWS-EBS ボリュームを持つ単一ノードのNetApp Cloud Volumes ONTAPインスタンス。これらのボリュームは、専用の LIF を介して 6 つの NFS ボリュームとして Kafka クラスターに公開されます。
-
*ブローカーの構成*このテスト ケースで構成可能な唯一の要素は Kafka ブローカーです。 Kafka ブローカーには次の仕様が選択されました。その `replica.lag.time.mx.ms`特定のノードが ISR リストから削除される速度を決定するため、高い値に設定されます。不良ノードと正常なノードを切り替える場合、そのブローカー ID が ISR リストから除外されないようにする必要があります。
テストの方法論
-
2 つの類似したクラスターが作成されました。
-
EC2 ベースの合流クラスター。
-
NetApp NFS ベースの合流クラスター。
-
-
元の Kafka クラスターのノードと同一の構成で、スタンバイ Kafka ノードが 1 つ作成されました。
-
各クラスターでサンプルトピックが作成され、ブローカーごとに約 110 GB のデータが入力されました。
-
EC2 ベースのクラスター。 Kafkaブローカーデータディレクトリは、
/mnt/data-2(次の図では、cluster1 の Broker-1 [左端末])。 -
* NetApp NFS ベースのクラスター。* KafkaブローカーデータディレクトリはNFSポイントにマウントされます
/mnt/data(次の図では、cluster2 の Broker-1 [右端末])。
-
-
各クラスターで、Broker-1 が終了され、失敗したブローカーの回復プロセスがトリガーされました。
-
ブローカーが終了した後、ブローカーの IP アドレスがスタンバイ ブローカーのセカンダリ IP として割り当てられました。これは、Kafka クラスター内のブローカーが次のように識別されるため必要でした。
-
*IPアドレス*障害が発生したブローカー IP をスタンバイ ブローカーに再割り当てすることによって割り当てられます。
-
*ブローカーID*これはスタンバイブローカーで設定されました
server.properties。
-
-
IP が割り当てられると、スタンバイ ブローカーで Kafka サービスが開始されました。
-
しばらくして、サーバー ログを取得して、クラスター内の置換ノードでデータを構築するのにかかった時間をチェックしました。
観察
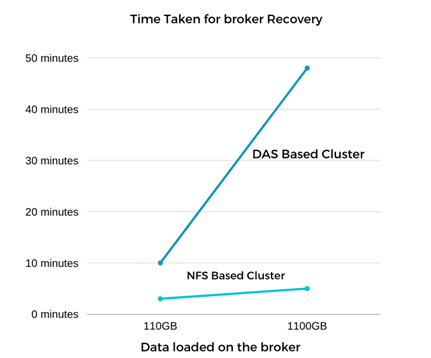
Kafka ブローカーの回復はほぼ 9 倍高速になりました。障害が発生したブローカー ノードの回復にかかる時間は、Kafka クラスターで DAS SSD を使用する場合と比較して、 NetApp NFS 共有ストレージを使用する場合の方が大幅に短縮されることがわかりました。 1 TB のトピック データの場合、DAS ベースのクラスターのリカバリ時間は 48 分でしたが、 NetApp-NFS ベースの Kafka クラスターの場合は 5 分未満でした。
EC2 ベースのクラスターでは新しいブローカー ノードで 110 GB のデータを再構築するのに 10 分かかりましたが、NFS ベースのクラスターでは 3 分でリカバリを完了しました。また、ログでは、EC2 のパーティションのコンシューマー オフセットが 0 である一方、NFS クラスターではコンシューマー オフセットが以前のブローカーから取得されていることも確認しました。
[2022-10-31 09:39:17,747] INFO [LogLoader partition=test-topic-51R3EWs-0000-55, dir=/mnt/kafka-data/broker2] Reloading from producer snapshot and rebuilding producer state from offset 583999 (kafka.log.UnifiedLog$) [2022-10-31 08:55:55,170] INFO [LogLoader partition=test-topic-qbVsEZg-0000-8, dir=/mnt/data-1] Loading producer state till offset 0 with message format version 2 (kafka.log.UnifiedLog$)
DASベースのクラスター
-
バックアップ ノードは 08:55:53,730 に開始されました。

-
データ再構築プロセスは 09:05:24,860 に終了しました。 110GB のデータの処理には約 10 分かかりました。

NFSベースのクラスタ
-
バックアップ ノードは 09:39:17,213 に開始されました。開始ログエントリは以下に強調表示されています。

-
データ再構築プロセスは 09:42:29,115 に終了しました。 110GB のデータの処理には約 3 分かかりました。

約 1 TB のデータを含むブローカーに対してテストを繰り返しましたが、DAS の場合は約 48 分、NFS の場合は約 3 分かかりました。結果は次のグラフに示されています。
ストレージ効率
Kafka クラスターのストレージ層はNetApp ONTAPを通じてプロビジョニングされたため、 ONTAPのすべてのストレージ効率機能を利用できました。これは、Cloud Volumes ONTAPでプロビジョニングされた NFS ストレージを使用して Kafka クラスターで大量のデータを生成することによってテストされました。 ONTAP の機能により、スペースが大幅に削減されたことがわかりました。
建築のセットアップ
次の表は、NAS を使用した Kafka クラスターの環境構成を示しています。
| プラットフォームコンポーネント | 環境設定 |
|---|---|
カフカ 3.2.3 |
|
すべてのノード上のオペレーティング システム |
RHEL8.7以降 |
NetApp Cloud Volumes ONTAPインスタンス |
単一ノードインスタンス – M5.2xLarge |
次の図は、NAS ベースの Kafka クラスターのアーキテクチャを示しています。
-
*計算します。*専用サーバーで実行される 3 ノードの Zookeeper アンサンブルを備えた 3 ノードの Kafka クラスターを使用しました。各ブローカーには、専用 LIF を介してNetApp CVO インスタンス上の単一ボリュームへの 2 つの NFS マウント ポイントがありました。
-
監視。 Prometheus と Grafana の組み合わせには 2 つのノードを使用しました。ワークロードを生成するために、この Kafka クラスターに対して生成と消費が可能な別の 3 ノード クラスターを使用しました。
-
*ストレージ。*インスタンスにマウントされた 6 つの 250 GB GP2 AWS-EBS ボリュームを備えた単一ノードのNetApp Cloud Volumes ONTAPインスタンスを使用しました。これらのボリュームは、専用の LIF を介して 6 つの NFS ボリュームとして Kafka クラスターに公開されました。
-
*構成。*このテスト ケースで構成可能な要素は、Kafka ブローカーでした。
圧縮はプロデューサー側でオフにされたため、プロデューサーは高いスループットを生成できるようになりました。代わりに、ストレージ効率はコンピューティング層によって処理されました。
テストの方法論
-
上記の仕様で Kafka クラスターがプロビジョニングされました。
-
クラスターでは、OpenMessaging ベンチマーク ツールを使用して約 350 GB のデータが生成されました。
-
ワークロードが完了した後、 ONTAP System Manager と CLI を使用してストレージ効率統計が収集されました。
観察
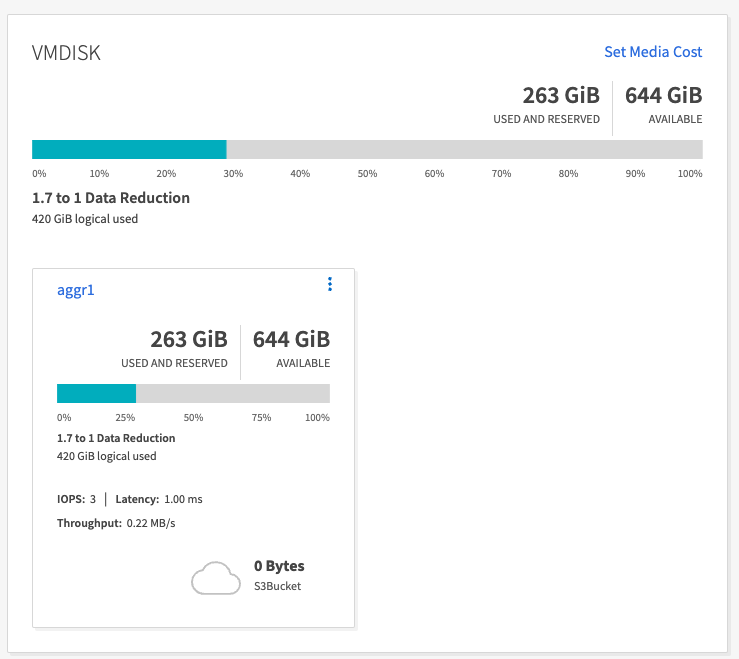
OMB ツールを使用して生成されたデータでは、ストレージ効率比が 1.70:1 で、スペースが約 33% 節約されました。次の図に示すように、生成されたデータによって使用された論理スペースは 420.3 GB で、データを保持するために使用された物理スペースは 281.7 GB でした。