

技術概要
 変更を提案
変更を提案
このセクションでは、このソリューションで使用されるテクノロジについて説明します。
NetAppStorageGRID
NetApp StorageGRIDは、高性能でコスト効率に優れたオブジェクト ストレージ プラットフォームです。階層型ストレージを使用すると、ローカル ストレージまたはブローカーの SAN ストレージに保存されている Confluent Kafka 上のデータの大部分が、リモート オブジェクト ストアにオフロードされます。この構成により、クラスターの再調整、拡張、縮小、または障害が発生したブローカーの交換にかかる時間とコストが削減され、運用が大幅に改善されます。オブジェクト ストレージは、オブジェクト ストア層に存在するデータの管理において重要な役割を果たすため、適切なオブジェクト ストレージを選択することが重要です。
StorageGRID は、分散型のノードベースのグリッド アーキテクチャを使用して、インテリジェントなポリシー主導のグローバル データ管理を提供します。ユビキタスなグローバル オブジェクト名前空間と洗練されたデータ管理機能を組み合わせることで、ペタバイト単位の非構造化データと数十億個のオブジェクトの管理を簡素化します。シングルコールのオブジェクト アクセスはサイト全体に拡張され、高可用性アーキテクチャを簡素化するとともに、サイトまたはインフラストラクチャの停止に関係なく継続的なオブジェクト アクセスを保証します。
マルチテナンシーにより、複数の非構造化クラウドおよびエンタープライズ データ アプリケーションを同じグリッド内で安全に処理できるようになり、 NetApp StorageGRIDの ROI と使用事例が増加します。メタデータ駆動型のオブジェクト ライフサイクル ポリシーを使用して複数のサービス レベルを作成し、複数の地域にわたって耐久性、保護、パフォーマンス、および局所性を最適化できます。ユーザーは、常に変化する IT 環境で要件が変わったときに、データ管理ポリシーを調整し、トラフィック制限を監視および適用して、中断なくデータ ランドスケープに再調整することができます。
グリッドマネージャーによるシンプルな管理
StorageGRID Grid Manager は、ブラウザベースのグラフィカル インターフェイスであり、世界中に分散された場所にあるStorageGRIDシステムを単一の画面で構成、管理、監視できます。
StorageGRID Grid Manager インターフェイスを使用して、次のタスクを実行できます。
-
画像、ビデオ、レコードなどのオブジェクトの、グローバルに分散されたペタバイト規模のリポジトリを管理します。
-
オブジェクトの可用性を確保するためにグリッド ノードとサービスを監視します。
-
情報ライフサイクル管理 (ILM) ルールを使用して、時間の経過に伴うオブジェクト データの配置を管理します。これらのルールは、オブジェクトのデータが取り込まれた後に何が起こるか、どのように損失から保護されるか、オブジェクト データがどこに保存されるか、どのくらいの期間保存されるかを制御します。
-
システム内のトランザクション、パフォーマンス、および操作を監視します。
情報ライフサイクル管理ポリシー
StorageGRIDには、特定のパフォーマンスとデータ保護の要件に応じて、オブジェクトのレプリカ コピーを保持したり、2+1 や 4+2 などの EC (消去コーディング) スキームを使用してオブジェクトを保存したりするなど、柔軟なデータ管理ポリシーがあります。ワークロードと要件は時間の経過とともに変化するため、ILM ポリシーも時間の経過とともに変更する必要があるのが一般的です。 ILM ポリシーの変更は中核機能であり、これによりStorageGRID のお客様は変化し続ける環境に迅速かつ簡単に適応できます。
パフォーマンス
StorageGRIDは、VM、ベアメタル、または専用アプライアンスなどのストレージノードを追加することでパフォーマンスを拡張します。"SG5712、SG5760、SG6060、またはSGF6024" 。当社のテストでは、SGF6024 アプライアンスを使用した最小サイズの 3 ノード グリッドで Apache Kafka の主要なパフォーマンス要件を超えました。顧客が追加のブローカーを使用して Kafka クラスターを拡張すると、ストレージ ノードを追加してパフォーマンスと容量を向上させることができます。
ロードバランサとエンドポイントの構成
StorageGRIDの管理ノードは、 StorageGRIDシステムを表示、構成、管理するための Grid Manager UI (ユーザー インターフェイス) と REST API エンドポイント、およびシステム アクティビティを追跡するための監査ログを提供します。 Confluent Kafka 階層型ストレージに高可用性の S3 エンドポイントを提供するために、管理ノードとゲートウェイ ノードでサービスとして実行されるStorageGRIDロード バランサーを実装しました。さらに、ロード バランサはローカル トラフィックも管理し、GSLB (グローバル サーバー負荷分散) と通信して災害復旧を支援します。
エンドポイント構成をさらに強化するために、 StorageGRID は管理ノードに組み込まれたトラフィック分類ポリシーを提供し、ワークロード トラフィックを監視し、ワークロードにさまざまなサービス品質 (QoS) 制限を適用できるようにします。トラフィック分類ポリシーは、ゲートウェイ ノードと管理ノードのStorageGRIDロード バランサ サービスのエンドポイントに適用されます。これらのポリシーは、トラフィックのシェーピングと監視に役立ちます。
StorageGRIDにおけるトラフィック分類
StorageGRIDには QoS 機能が組み込まれています。トラフィック分類ポリシーは、クライアント アプリケーションから送信されるさまざまな種類の S3 トラフィックを監視するのに役立ちます。次に、入力/出力帯域幅、読み取り/書き込み同時要求の数、または読み取り/書き込み要求レートに基づいてこのトラフィックに制限を設定するポリシーを作成して適用できます。
Apache Kafka
Apache Kafka は、Java と Scala で記述されたストリーム処理を使用したソフトウェア バスのフレームワーク実装です。リアルタイムのデータフィードを処理するための、統合された高スループット、低レイテンシのプラットフォームを提供することを目的としています。 Kafka は、Kafka Connect を介してデータのエクスポートとインポートのために外部システムに接続でき、Java ストリーム処理ライブラリである Kafka ストリームを提供します。 Kafka は、効率性を重視して最適化されたバイナリ TCP ベースのプロトコルを使用し、メッセージを自然にグループ化してネットワーク ラウンドトリップのオーバーヘッドを削減する「メッセージ セット」抽象化に依存しています。これにより、大規模な順次ディスク操作、大規模なネットワーク パケット、連続したメモリ ブロックが可能になり、Kafka はランダム メッセージ書き込みのバースト ストリームを線形書き込みに変換できるようになります。次の図は、Apache Kafka の基本的なデータ フローを示しています。
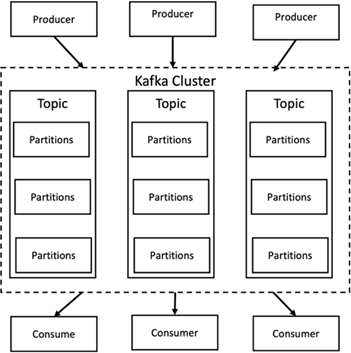
Kafka は、プロデューサーと呼ばれる任意の数のプロセスから送信されるキーと値のメッセージを保存します。データは、異なるトピック内の異なるパーティションに分割できます。パーティション内では、メッセージはオフセット (パーティション内のメッセージの位置) によって厳密に順序付けられ、タイムスタンプとともにインデックスが付けられて保存されます。コンシューマーと呼ばれる他のプロセスは、パーティションからメッセージを読み取ることができます。ストリーム処理の場合、Kafka は、Kafka からデータを消費し、結果を Kafka に書き戻す Java アプリケーションを作成できる Streams API を提供します。 Apache Kafka は、Apache Apex、Apache Flink、Apache Spark、Apache Storm、Apache NiFi などの外部ストリーム処理システムとも連携します。
Kafka は 1 つ以上のサーバー (ブローカーと呼ばれる) のクラスター上で実行され、すべてのトピックのパーティションはクラスター ノード全体に分散されます。さらに、パーティションは複数のブローカーに複製されます。このアーキテクチャにより、Kafka はフォールト トレラントな方法で大量のメッセージ ストリームを配信できるようになり、Java Message Service (JMS)、Advanced Message Queuing Protocol (AMQP) などの従来のメッセージング システムの一部を置き換えることが可能になりました。 0.11.0.0 リリース以降、Kafka は、Streams API を使用して 1 回だけのストリーム処理を提供するトランザクション書き込みを提供します。
Kafka は、通常のトピックと圧縮されたトピックの 2 種類のトピックをサポートしています。通常のトピックは、保持時間またはスペースの制限付きで構成できます。指定された保持期間よりも古いレコードがある場合、またはパーティションのスペース制限を超えた場合、Kafka は古いデータを削除してストレージスペースを解放できます。デフォルトでは、トピックの保持期間は 7 日間に設定されていますが、データを無期限に保存することもできます。圧縮されたトピックの場合、レコードは時間または領域の境界に基づいて期限切れになることはありません。代わりに、Kafka は後続のメッセージを同じキーを持つ古いメッセージの更新として扱い、キーごとに最新のメッセージを削除しないことを保証します。ユーザーは、特定のキーに null 値を設定したいわゆるトゥームストーン メッセージを書き込むことで、メッセージを完全に削除できます。
Kafka には 5 つの主要な API があります。
-
*プロデューサー API。*アプリケーションがレコードのストリームを公開することを許可します。
-
*コンシューマー API*アプリケーションがトピックをサブスクライブし、レコードのストリームを処理することを許可します。
-
*コネクタ API。*トピックを既存のアプリケーションにリンクできる再利用可能なプロデューサー API とコンシューマー API を実行します。
-
*ストリーム API。*この API は入力ストリームを出力に変換し、結果を生成します。
-
管理 API。 Kafka トピック、ブローカー、およびその他の Kafka オブジェクトを管理するために使用されます。
コンシューマー API とプロデューサー API は、Kafka メッセージング プロトコルの上に構築され、Java での Kafka コンシューマー クライアントとプロデューサー クライアントのリファレンス実装を提供します。基礎となるメッセージング プロトコルはバイナリ プロトコルであり、開発者はこれを使用して任意のプログラミング言語で独自のコンシューマー クライアントまたはプロデューサー クライアントを作成できます。これにより、Kafka は Java 仮想マシン (JVM) エコシステムから解放されます。利用可能な非 Java クライアントのリストは、Apache Kafka wiki で管理されています。
Apache Kafka のユースケース
Apache Kafka は、メッセージング、Web サイトのアクティビティ追跡、メトリック、ログ集約、ストリーム処理、イベント ソーシング、コミット ログで最も人気があります。
-
Kafka はスループット、組み込みのパーティショニング、レプリケーション、フォールト トレランスが向上しており、大規模なメッセージ処理アプリケーションに適したソリューションとなっています。
-
Kafka は、追跡パイプライン内のユーザーのアクティビティ (ページ ビュー、検索) を、リアルタイムのパブリッシュ/サブスクライブ フィードのセットとして再構築できます。
-
Kafka は運用監視データによく使用されます。これには、分散アプリケーションからの統計を集約して、運用データの集中フィードを生成することが含まれます。
-
多くの人が、ログ集約ソリューションの代わりとして Kafka を使用しています。ログ集約では通常、サーバーから物理ログ ファイルが収集され、処理のために中央の場所 (ファイル サーバーや HDFS など) に配置されます。 Kafka はファイルの詳細を抽象化し、ログまたはイベント データをメッセージ ストリームとしてよりクリーンに抽象化します。これにより、処理のレイテンシが低減され、複数のデータ ソースと分散データ消費のサポートが容易になります。
-
Kafka の多くのユーザーは、複数のステージで構成される処理パイプラインでデータを処理します。このパイプラインでは、生の入力データが Kafka トピックから消費され、その後、さらなる消費や後続処理のために、集約、拡充、またはその他の方法で新しいトピックに変換されます。たとえば、ニュース記事を推奨するための処理パイプラインでは、RSS フィードから記事のコンテンツをクロールし、「記事」トピックに公開する場合があります。さらに処理を進めると、このコンテンツが正規化または重複排除され、クリーンアップされた記事コンテンツが新しいトピックに公開され、最終処理段階でこのコンテンツをユーザーに推奨しようとする可能性があります。このような処理パイプラインは、個々のトピックに基づいてリアルタイムのデータフローのグラフを作成します。
-
イベント サウシングは、状態の変化が時間順のレコードのシーケンスとして記録されるアプリケーション設計のスタイルです。 Kafka は非常に大きなログ データの保存をサポートしているため、このスタイルで構築されたアプリケーションにとって優れたバックエンドになります。
-
Kafka は、分散システムの一種の外部コミット ログとして機能します。ログはノード間でデータを複製するのに役立ち、障害が発生したノードがデータを復元するための再同期メカニズムとして機能します。 Kafka のログ圧縮機能は、このユースケースのサポートに役立ちます。
合流
Confluent Platform は、アプリケーション開発と接続の高速化、ストリーム処理による変換の実現、大規模なエンタープライズ運用の簡素化、厳格なアーキテクチャ要件への対応を支援するように設計された高度な機能で Kafka を補完する、エンタープライズ対応のプラットフォームです。 Apache Kafka のオリジナル作成者によって構築された Confluent は、エンタープライズ グレードの機能によって Kafka の利点を拡大するとともに、Kafka の管理や監視の負担を軽減します。現在、Fortune 100 企業の 80% 以上がデータ ストリーミング テクノロジーを活用しており、そのほとんどが Confluent を使用しています。
Confluentを選ぶ理由
Confluent は、履歴データとリアルタイム データを単一の信頼できる中央ソースに統合することで、まったく新しいカテゴリの最新のイベント駆動型アプリケーションを簡単に構築し、ユニバーサル データ パイプラインを実現し、完全なスケーラビリティ、パフォーマンス、信頼性を備えた強力な新しいユースケースを実現します。
Confluent は何に使用されますか?
Confluent Platform を使用すると、異なるシステム間でデータがどのように転送されるか、または統合されるかといった基礎となる仕組みを心配するのではなく、データからビジネス価値を引き出す方法に集中できます。具体的には、Confluent Platform は、データ ソースを Kafka に接続し、ストリーミング アプリケーションを構築するだけでなく、Kafka インフラストラクチャのセキュリティ保護、監視、管理も簡素化します。現在、Confluent Platform は、金融サービス、オムニチャネル小売、自律走行車から不正検出、マイクロサービス、IoT まで、さまざまな業界の幅広いユースケースに使用されています。
次の図は、Confluent Kafka プラットフォームのコンポーネントを示しています。
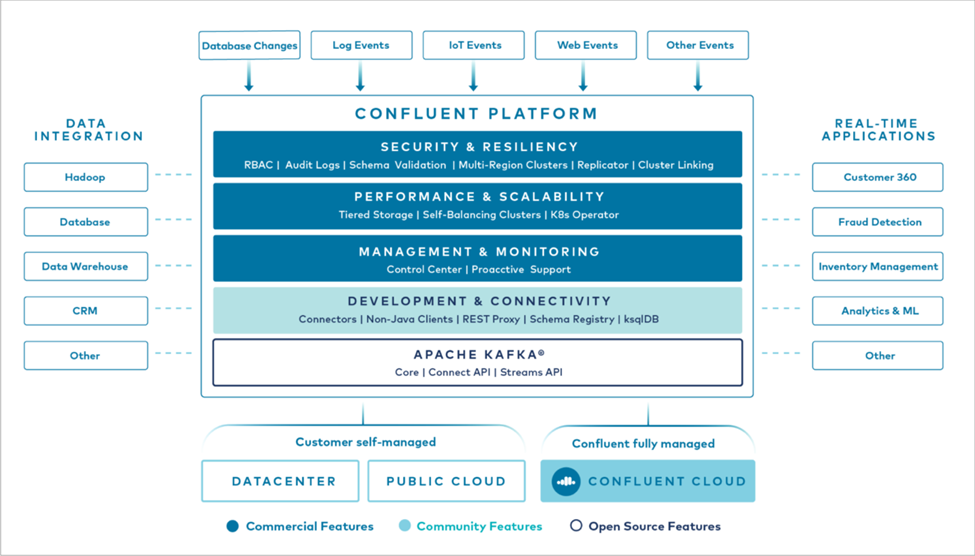
Confluentのイベントストリーミングテクノロジーの概要
Confluent Platformの中核は "Apache Kafka"最も人気のあるオープンソースの分散ストリーミング プラットフォームです。 Kafka の主な機能は次のとおりです。
-
レコードのストリームを公開およびサブスクライブします。
-
フォールト トレラントな方法でレコードのストリームを保存します。
-
レコードのストリームを処理します。
Confluent Platform には、すぐに使用できる Schema Registry、REST Proxy、合計 100 個以上の構築済み Kafka コネクタ、ksqlDB も含まれています。
Confluent プラットフォームのエンタープライズ機能の概要
-
Confluent コントロール センター Kafka を管理および監視するための GUI ベースのシステム。 Kafka Connect を簡単に管理し、他のシステムへの接続を作成、編集、管理できるようになります。
-
Kubernetes 用の Confluent。 Confluent for Kubernetes は Kubernetes オペレーターです。 Kubernetes オペレーターは、特定のプラットフォーム アプリケーションに固有の機能と要件を提供することで、Kubernetes のオーケストレーション機能を拡張します。 Confluent Platform の場合、これには Kubernetes 上の Kafka のデプロイメント プロセスを大幅に簡素化し、一般的なインフラストラクチャ ライフサイクル タスクを自動化することが含まれます。
-
*Kafka への Confluent コネクタ。*コネクタは Kafka Connect API を使用して、Kafka をデータベース、キー値ストア、検索インデックス、ファイルシステムなどの他のシステムに接続します。 Confluent Hub には、最も人気のあるデータ ソースとシンク用のダウンロード可能なコネクタがあり、Confluent Platform で完全にテストされサポートされているバージョンのコネクタも含まれています。詳細は以下をご覧ください "ここをクリックしてください。"。
-
*自己バランス型クラスター。*自動化された負荷分散、障害検出、自己修復を提供します。手動で調整することなく、必要に応じてブローカーを追加または廃止するためのサポートを提供します。
-
*合流クラスターのリンク。*クラスターを直接接続し、リンク ブリッジを介して 1 つのクラスターから別のクラスターにトピックをミラーリングします。クラスター リンクにより、マルチデータセンター、マルチクラスター、ハイブリッド クラウドの展開のセットアップが簡素化されます。
-
*Confluent 自動データバランサー*クラスター内のブローカーの数、パーティションのサイズ、パーティションの数、およびリーダーの数を監視します。これにより、データをシフトしてクラスター全体で均一なワークロードを作成しながら、再バランスのトラフィックを調整して、再バランス中の本番ワークロードへの影響を最小限に抑えることができます。
-
*合流型複製子。*複数のデータ センターで複数の Kafka クラスターを管理することがこれまで以上に簡単になります。
-
*階層型ストレージ*お気に入りのクラウド プロバイダーを使用して大量の Kafka データを保存するオプションを提供し、運用上の負担とコストを削減します。階層型ストレージを使用すると、コスト効率の高いオブジェクト ストレージにデータを保存し、コンピューティング リソースが必要な場合にのみブローカーを拡張できます。
-
Confluent JMS クライアント。 Confluent Platform には、Kafka 用の JMS 互換クライアントが含まれています。この Kafka クライアントは、バックエンドとして Kafka ブローカーを使用して、JMS 1.1 標準 API を実装します。これは、JMS を使用するレガシー アプリケーションがあり、既存の JMS メッセージ ブローカーを Kafka に置き換えたい場合に役立ちます。
-
*Confluent MQTT プロキシ。*中間に MQTT ブローカーを必要とせずに、MQTT デバイスおよびゲートウェイから Kafka に直接データを公開する方法を提供します。
-
Confluent セキュリティ プラグイン Confluent セキュリティ プラグインは、さまざまな Confluent Platform ツールおよび製品にセキュリティ機能を追加するために使用されます。現在、Confluent REST プロキシには、受信リクエストを認証し、認証されたプリンシパルを Kafka へのリクエストに伝播するのに役立つプラグインが用意されています。これにより、Confluent REST プロキシ クライアントは Kafka ブローカーのマルチテナント セキュリティ機能を利用できるようになります。