

NetApp Spark ソリューションの概要
 変更を提案
変更を提案
NetApp には、 FAS/ AFF、E シリーズ、 Cloud Volumes ONTAP の3 つのストレージ ポートフォリオがあります。当社では、Apache Spark を使用した Hadoop ソリューション向けに、 AFFおよび E シリーズをONTAPストレージ システムで検証しました。
NetAppが提供するデータ ファブリックは、次の図に示すように、データ アクセス、制御、保護、セキュリティのためのデータ管理サービスとアプリケーション (ビルディング ブロック) を統合します。
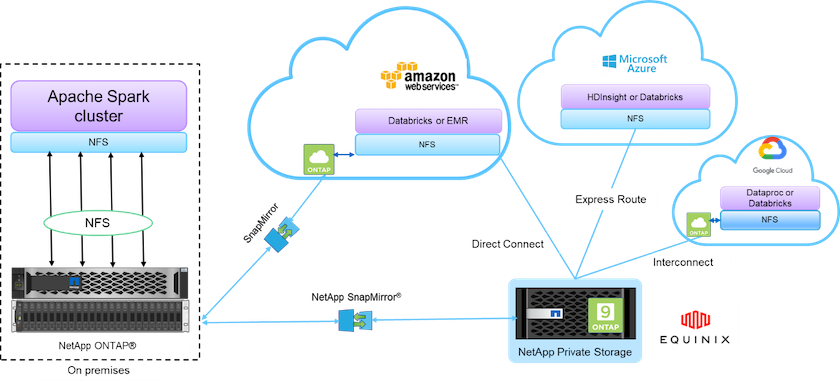
上の図の構成要素は次のとおりです。
-
* NetApp NFS ダイレクト アクセス。*追加のソフトウェアやドライバーを必要とせずに、最新の Hadoop および Spark クラスターにNetApp NFS ボリュームへの直接アクセスを提供します。
-
* NetApp Cloud Volumes ONTAPとGoogle Cloud NetApp Volumes 。* Amazon Web Services (AWS) または Microsoft Azure クラウド サービスのAzure NetApp Files (ANF) で実行されるONTAPに基づくソフトウェア定義の接続ストレージ。
-
* NetApp SnapMirrorテクノロジー。*オンプレミスとONTAP Cloud または NPS インスタンス間のデータ保護機能を提供します。
-
*クラウド サービス プロバイダー*これらのプロバイダーには、AWS、Microsoft Azure、Google Cloud、IBM Cloud が含まれます。
-
PaaS AWS の Amazon Elastic MapReduce (EMR) や Databricks、Microsoft Azure HDInsight や Azure Databricks などのクラウドベースの分析サービス。
次の図は、 NetAppストレージを使用した Spark ソリューションを示しています。
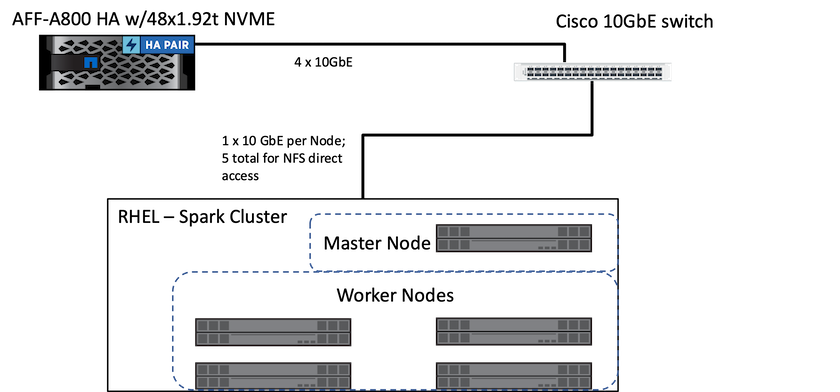
ONTAP Spark ソリューションは、既存の本番データへのアクセスを使用して、インプレース分析と AI、ML、DL ワークフローにNetApp NFS 直接アクセス プロトコルを使用します。 Hadoop ノードで利用可能な本番データは、インプレース分析および AI、ML、DL ジョブを実行するためにエクスポートされます。 Hadoop ノードで処理するデータには、 NetApp NFS 直接アクセスを使用しても使用しなくてもアクセスできます。 Sparkではスタンドアロンまたは yarn`クラスタマネージャでは、NFSボリュームを次のように設定できます。 `\file://<target_volume> 。異なるデータセットを使用して 3 つのユースケースを検証しました。これらの検証の詳細は、「テスト結果」のセクションに記載されています。 (外部参照)
次の図は、 NetApp Apache Spark/Hadoop ストレージの位置付けを示しています。
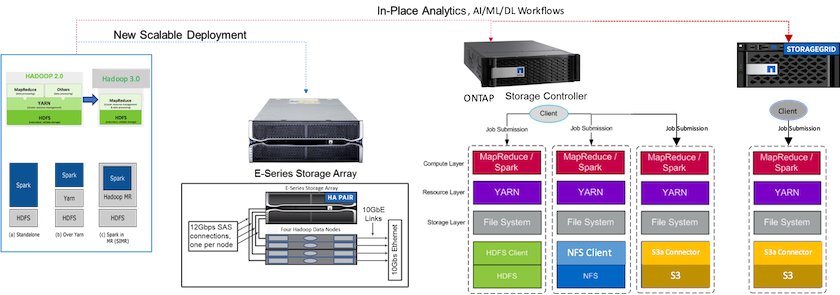
E シリーズ Spark ソリューション、 AFF/ FAS ONTAP Spark ソリューション、 StorageGRID Spark ソリューションの独自の機能を特定し、詳細な検証とテストを実施しました。当社の観察に基づき、 NetApp は、グリーンフィールド インストールと新しいスケーラブルな導入には E シリーズ ソリューションを推奨し、既存の NFS データを使用したインプレース分析、AI、ML、DL ワークロードにはAFF/ FASソリューションを推奨し、オブジェクト ストレージが必要な場合の AI、ML、DL および最新のデータ分析にはStorageGRID を推奨しています。
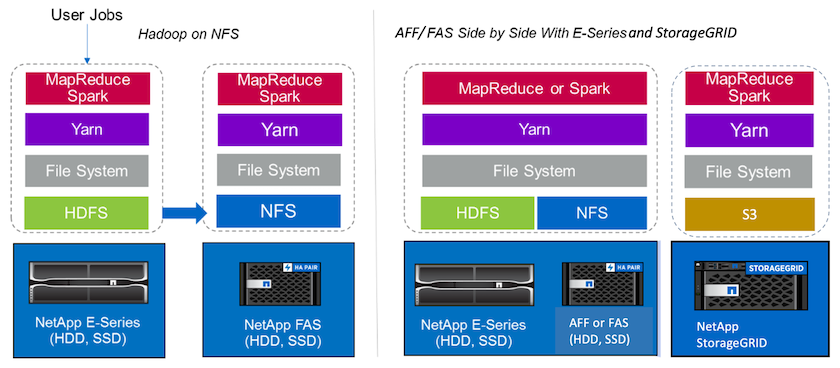
データ レイクは、分析、AI、ML、DL ジョブに使用できるネイティブ形式の大規模なデータセットのストレージ リポジトリです。 E シリーズ、 AFF/ FAS、 StorageGRID SG6060 Spark ソリューション用のデータ レイク リポジトリを構築しました。 E シリーズ システムは Hadoop Spark クラスターへの HDFS アクセスを提供しますが、既存の運用データは Hadoop クラスターへの NFS 直接アクセス プロトコルを通じてアクセスされます。オブジェクト ストレージに存在するデータセットに対して、 NetApp StorageGRID はS3 および S3a の安全なアクセスを提供します。