

EC2 および FSx Oracle データベース管理
 変更を提案
変更を提案
この Oracle 環境では、AWS EC2 および FSx 管理コンソールに加えて、Ansible 制御ノードとSnapCenter UI ツールがデータベース管理用に導入されています。
Ansible 制御ノードを使用すると、カーネルまたはパッチの更新時にプライマリ インスタンスとスタンバイ インスタンスの同期を維持する並列更新を使用して、Oracle 環境の構成を管理できます。 NetApp Automation Toolkit を使用すると、フェイルオーバー、再同期、フェイルバックを自動化し、Ansible による高速なアプリケーション リカバリと可用性を実現できます。一部の繰り返し可能なデータベース管理タスクは、プレイブックを使用して実行することで、人的エラーを削減できます。
SnapCenter UI ツールは、Oracle データベース用のSnapCenterプラグインを使用して、データベース スナップショットのバックアップ、ポイントインタイム リカバリ、データベースのクローン作成などを実行できます。 Oracleプラグインの機能の詳細については、"Oracle Database向けSnapCenterプラグインの概要" 。
次のセクションでは、Oracle データベース管理の主要機能がSnapCenter UI でどのように実現されるかについて詳しく説明します。
-
データベーススナップショットバックアップ
-
データベースのポイントインタイムリストア
-
データベースクローンの作成
データベースのクローン作成では、論理データエラーや破損が発生した場合にデータを回復できるように、別の EC2 ホスト上にプライマリデータベースのレプリカが作成されます。また、クローンはアプリケーションのテスト、デバッグ、パッチの検証などにも使用できます。
スナップショットを撮る
EC2/FSx Oracle データベースは、ユーザーが設定した間隔で定期的にバックアップされます。ユーザーはいつでも 1 回限りのスナップショット バックアップを実行することもできます。これは、完全なデータベース スナップショット バックアップとアーカイブ ログのみのスナップショット バックアップの両方に適用されます。
完全なデータベーススナップショットを取得する
完全なデータベース スナップショットには、データ ファイル、制御ファイル、アーカイブ ログ ファイルなど、すべての Oracle ファイルが含まれます。
-
SnapCenter UI にログインし、左側のメニューで [リソース] をクリックします。 [表示] ドロップダウンから、リソース グループ ビューに変更します。
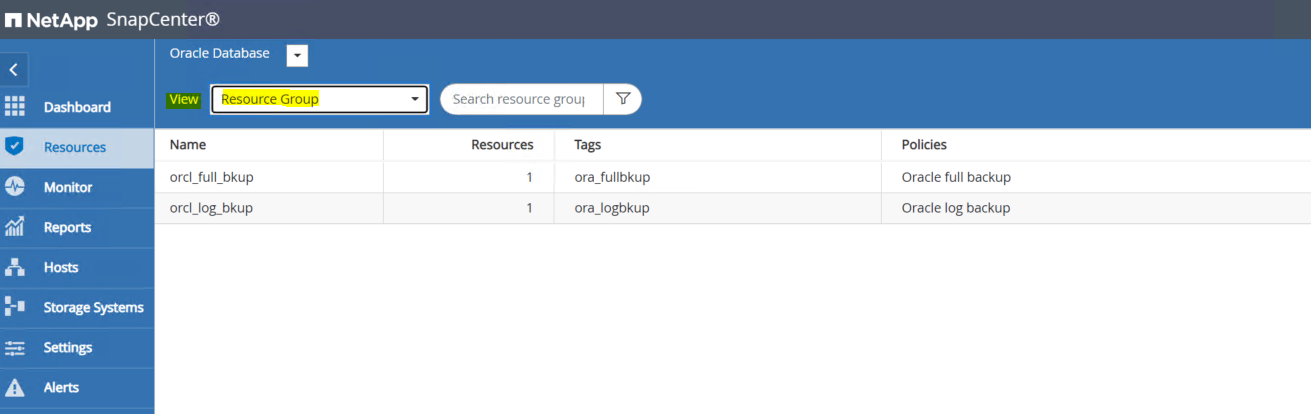
-
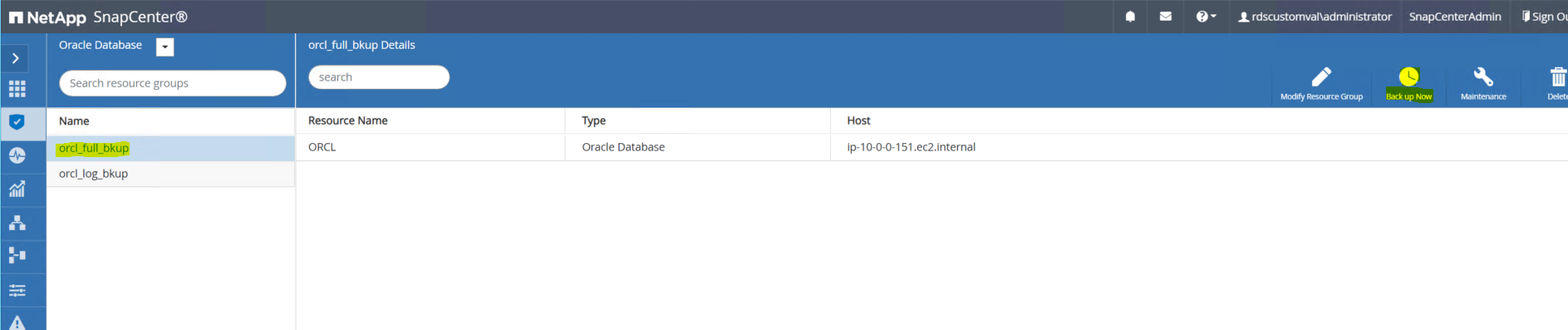
完全バックアップ リソース名をクリックし、[今すぐバックアップ] アイコンをクリックしてアドホック バックアップを開始します。
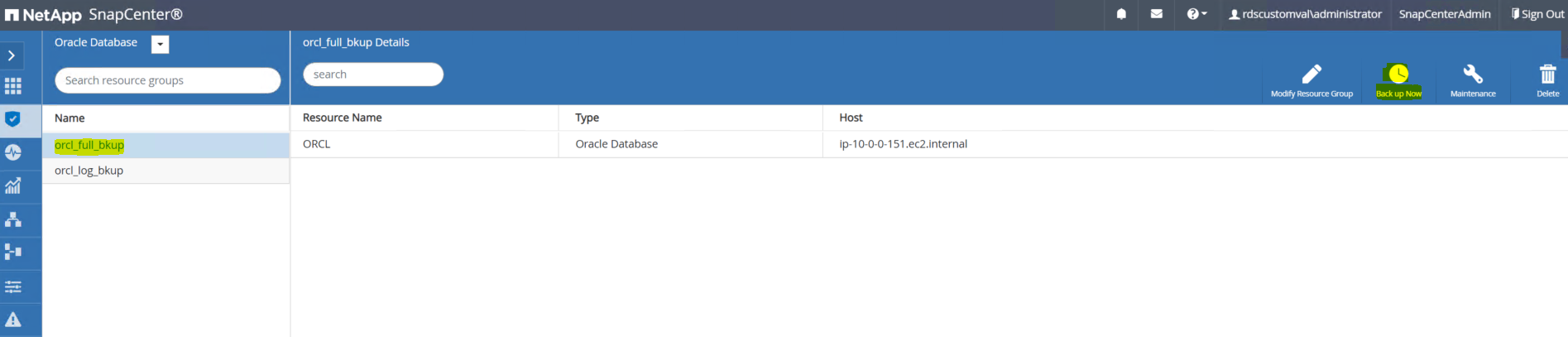
-
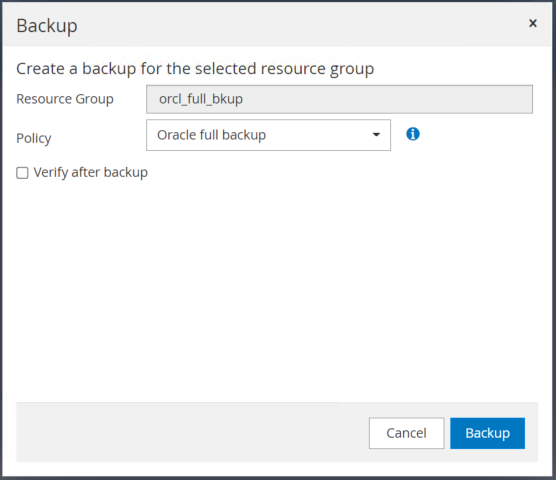
[バックアップ] をクリックし、バックアップを確認して完全なデータベース バックアップを開始します。
データベースのリソース ビューから、データベースの管理されたバックアップ コピー ページを開き、1 回限りのバックアップが正常に完了したことを確認します。完全なデータベース バックアップでは、データ ボリューム用とログ ボリューム用の 2 つのスナップショットが作成されます。
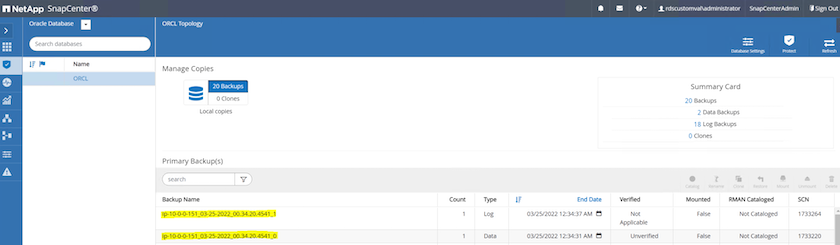
アーカイブログのスナップショットを取得する
アーカイブ ログ スナップショットは、Oracle アーカイブ ログ ボリュームに対してのみ作成されます。
-
SnapCenter UI にログインし、左側のメニュー バーの [リソース] タブをクリックします。 [表示] ドロップダウンから、リソース グループ ビューに変更します。
-
ログ バックアップ リソース名をクリックし、[今すぐバックアップ] アイコンをクリックして、アーカイブ ログのアドホック バックアップを開始します。
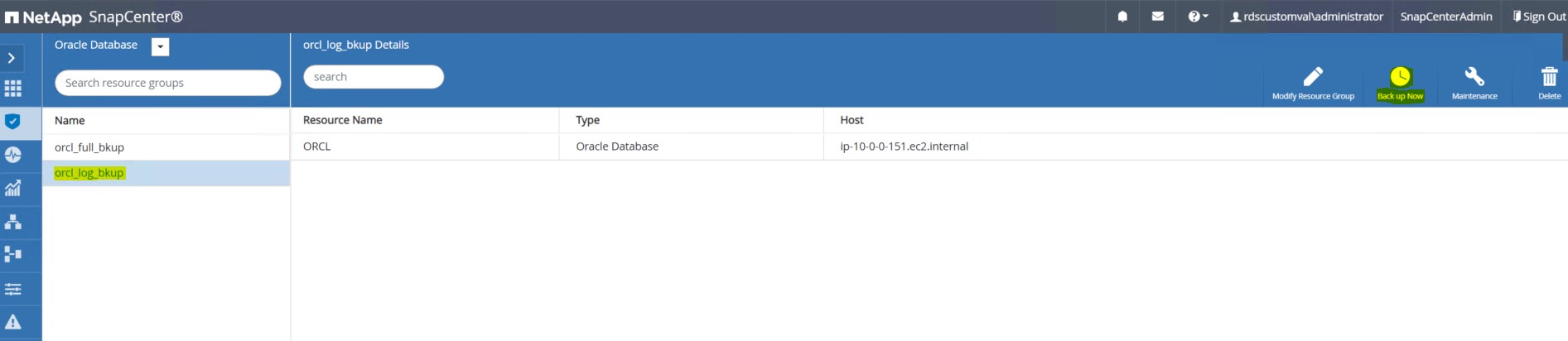
-
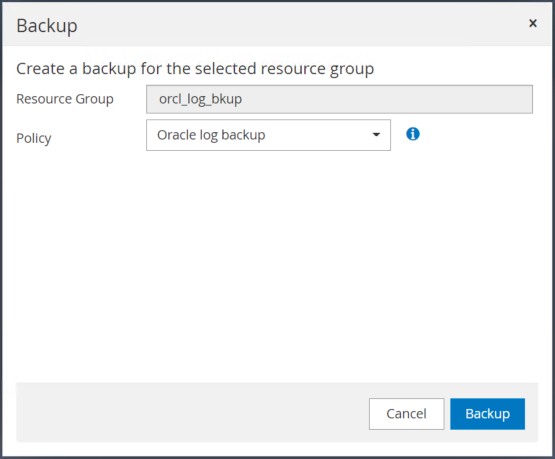
[バックアップ] をクリックし、バックアップを確認してアーカイブ ログのバックアップを開始します。
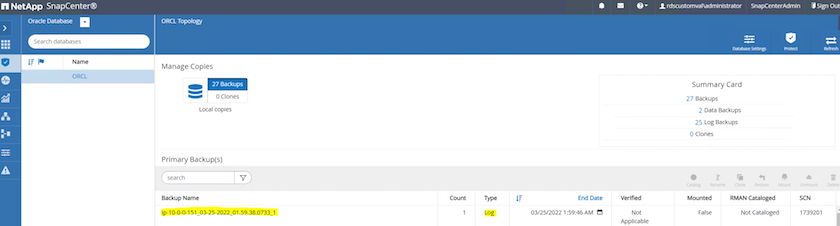
データベースのリソース ビューから、データベースの管理されたバックアップ コピー ページを開き、1 回限りのアーカイブ ログ バックアップが正常に完了したことを確認します。アーカイブ ログ バックアップでは、ログ ボリュームのスナップショットが 1 つ作成されます。
特定の時点への復元
特定の時点へのSnapCenterベースの復元は、同じ EC2 インスタンス ホスト上で実行されます。復元を実行するには、次の手順を実行します。
-
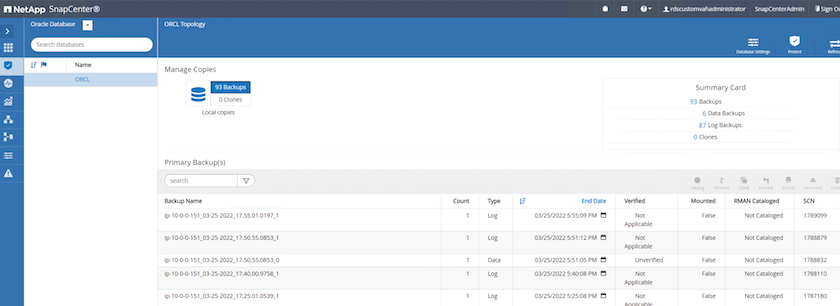
SnapCenterの [リソース] タブ > [データベース] ビューで、データベース名をクリックしてデータベース バックアップを開きます。
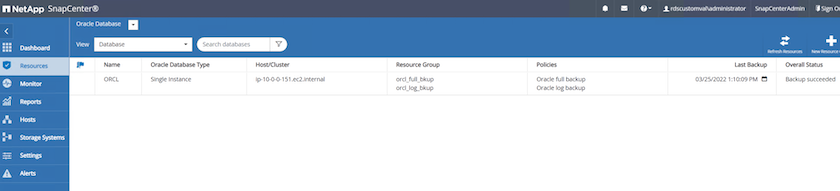
-
データベースのバックアップ コピーと復元する希望の時点を選択します。また、その時点の対応する SCN 番号も書き留めておきます。ポイントインタイム リストアは、時間または SCN のいずれかを使用して実行できます。
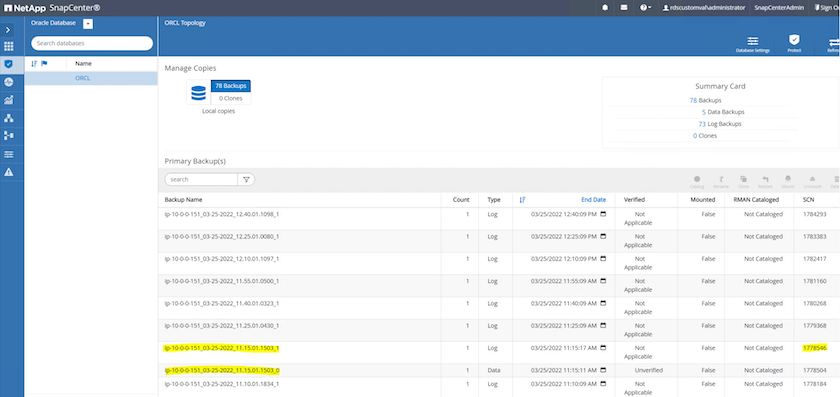
-
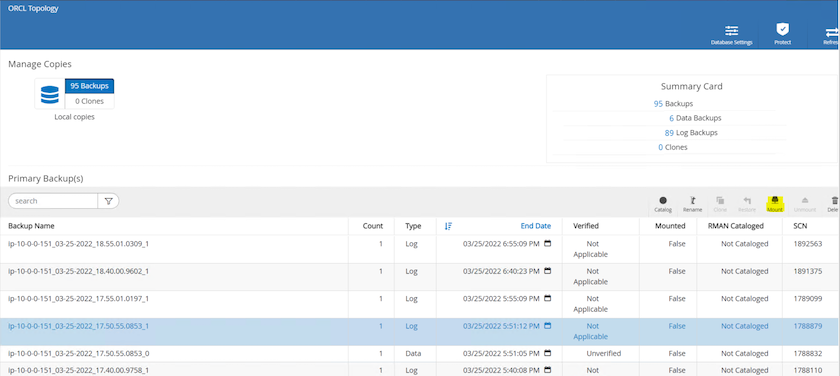
ログ ボリュームのスナップショットを強調表示し、[マウント] ボタンをクリックしてボリュームをマウントします。
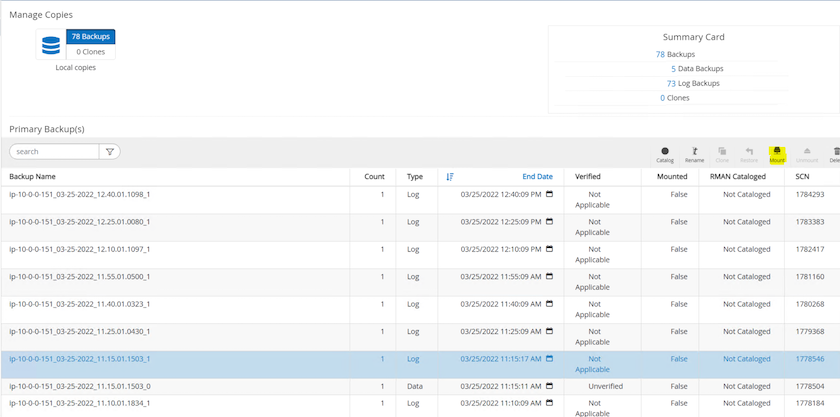
-
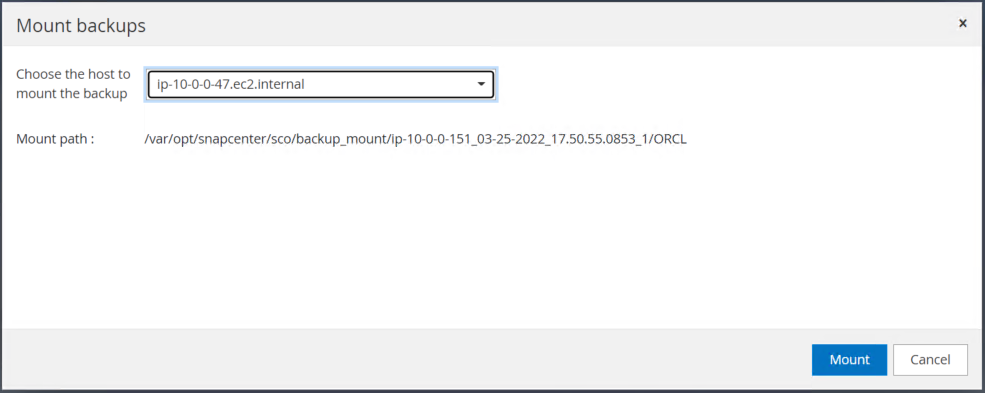
ログボリュームをマウントするプライマリ EC2 インスタンスを選択します。
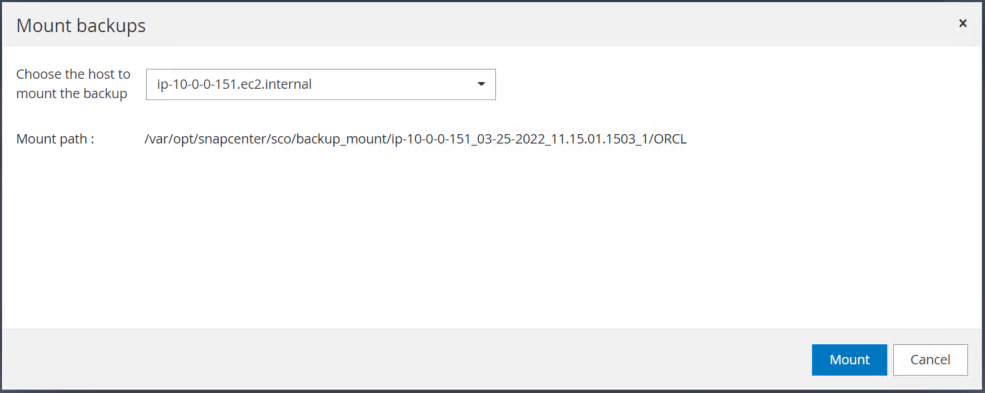
-
マウント ジョブが正常に完了したことを確認します。また、EC2 インスタンス ホストをチェックして、マウントされているログ ボリュームとマウント ポイント パスを確認します。


-
マウントされたログ ボリュームから現在のアーカイブ ログ ディレクトリにアーカイブ ログをコピーします。
[ec2-user@ip-10-0-0-151 ~]$ cp /var/opt/snapcenter/sco/backup_mount/ip-10-0-0-151_03-25-2022_11.15.01.1503_1/ORCL/1/db/ORCL_A/arch/*.arc /ora_nfs_log/db/ORCL_A/arch/
-
SnapCenter の[リソース] タブ > [データベース バックアップ] ページに戻り、データ スナップショット コピーを強調表示して、[復元] ボタンをクリックして、データベース復元ワークフローを開始します。
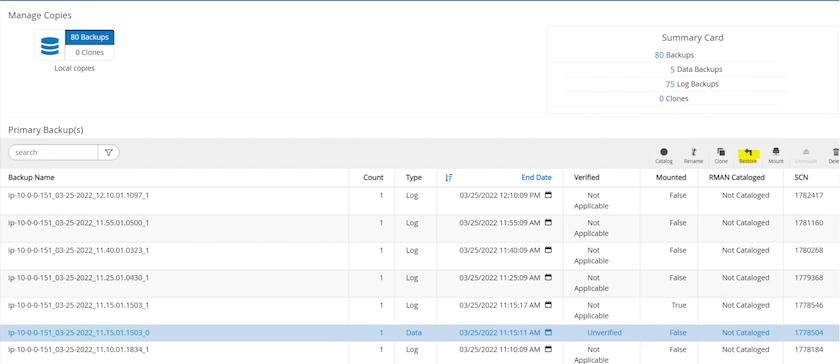
-
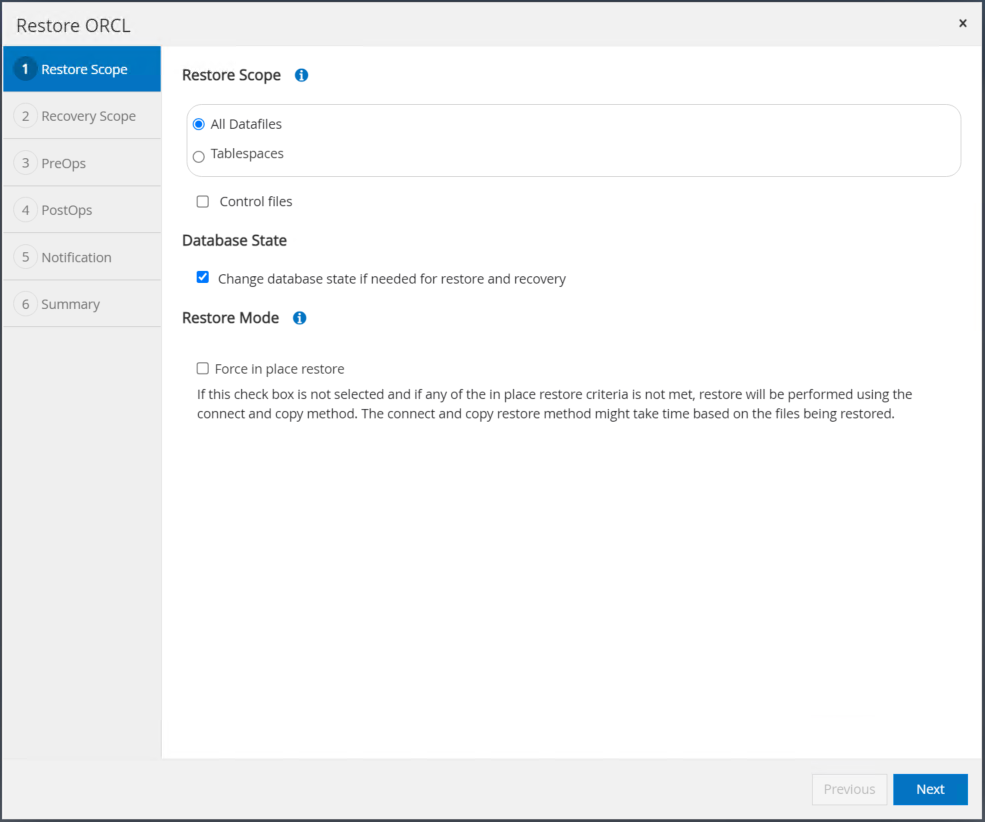
「すべてのデータファイル」と「復元と回復のために必要な場合はデータベースの状態を変更する」をチェックし、「次へ」をクリックします。
-
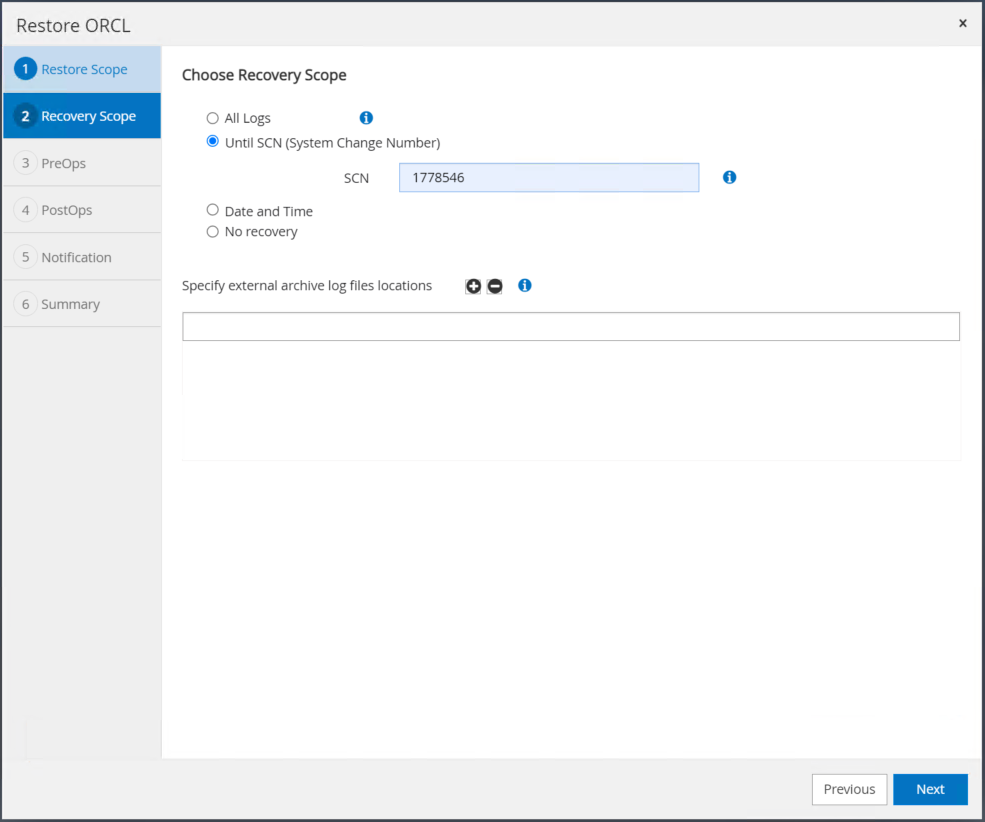
SCN または時間を使用して、必要な回復範囲を選択します。手順 6 で示したように、マウントされたアーカイブ ログを現在のログ ディレクトリにコピーするのではなく、マウントされたアーカイブ ログ パスを「外部アーカイブ ログ ファイルの場所の指定」にリストして回復することができます。
-
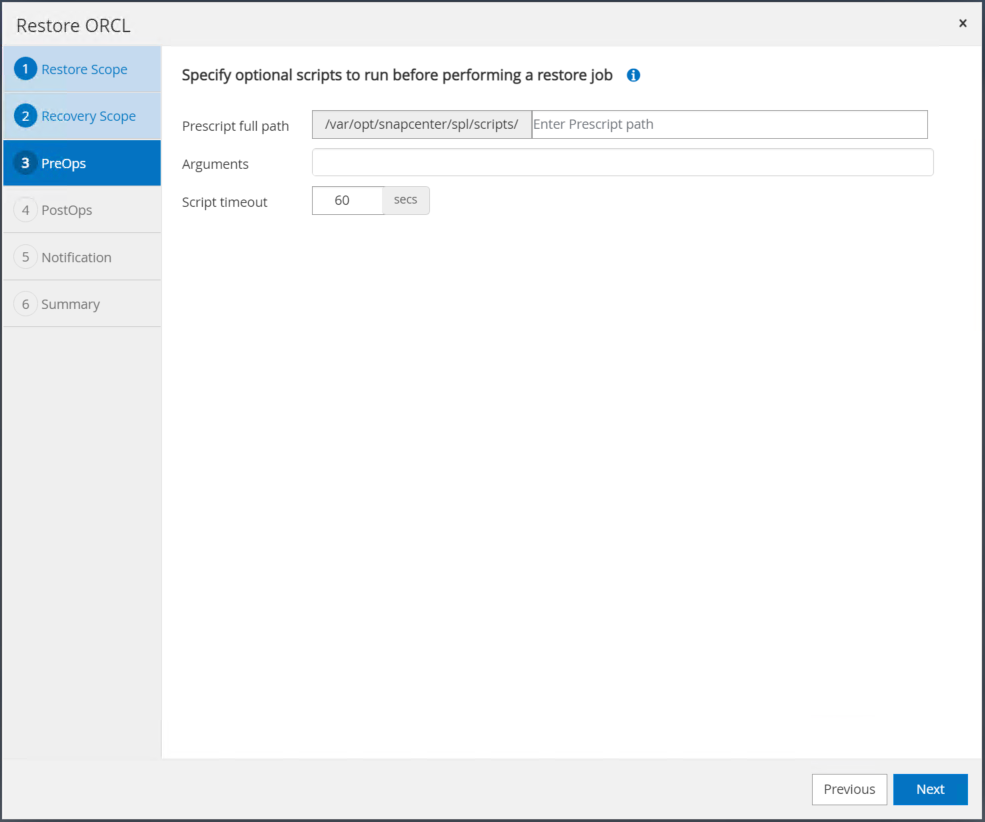
必要に応じて実行するオプションのプレスクリプトを指定します。
-
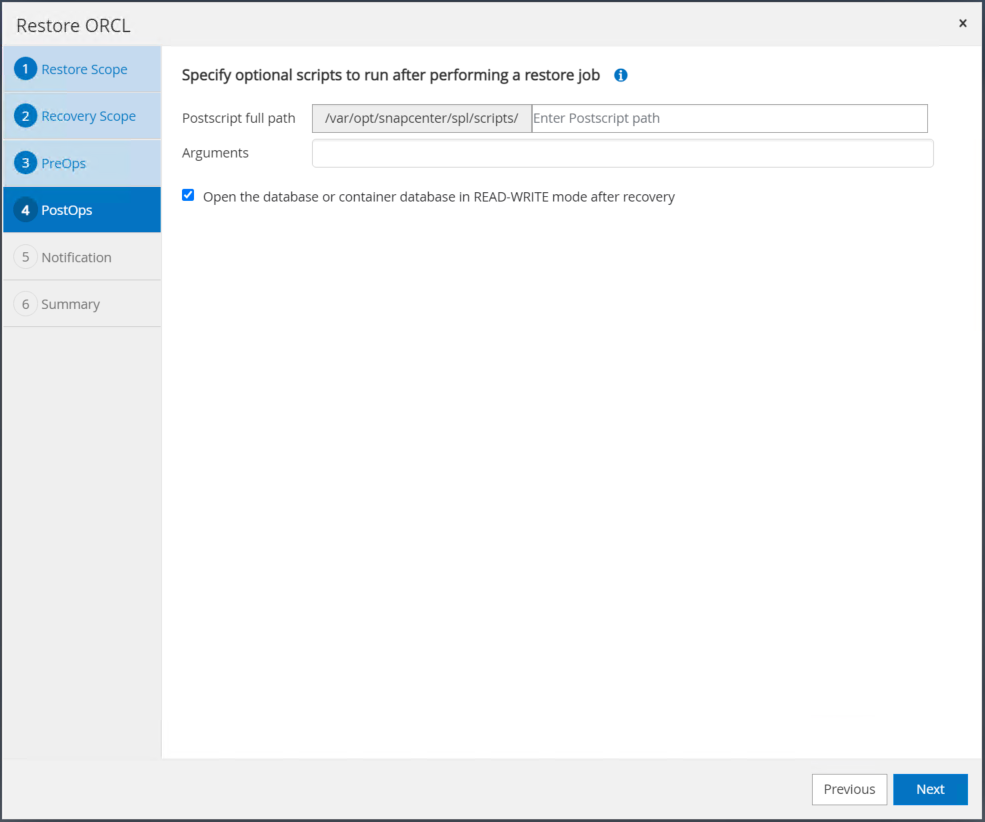
必要に応じて実行するオプションの afterscript を指定します。回復後に開いているデータベースを確認します。
-
ジョブ通知が必要な場合は、SMTP サーバーと電子メール アドレスを指定します。
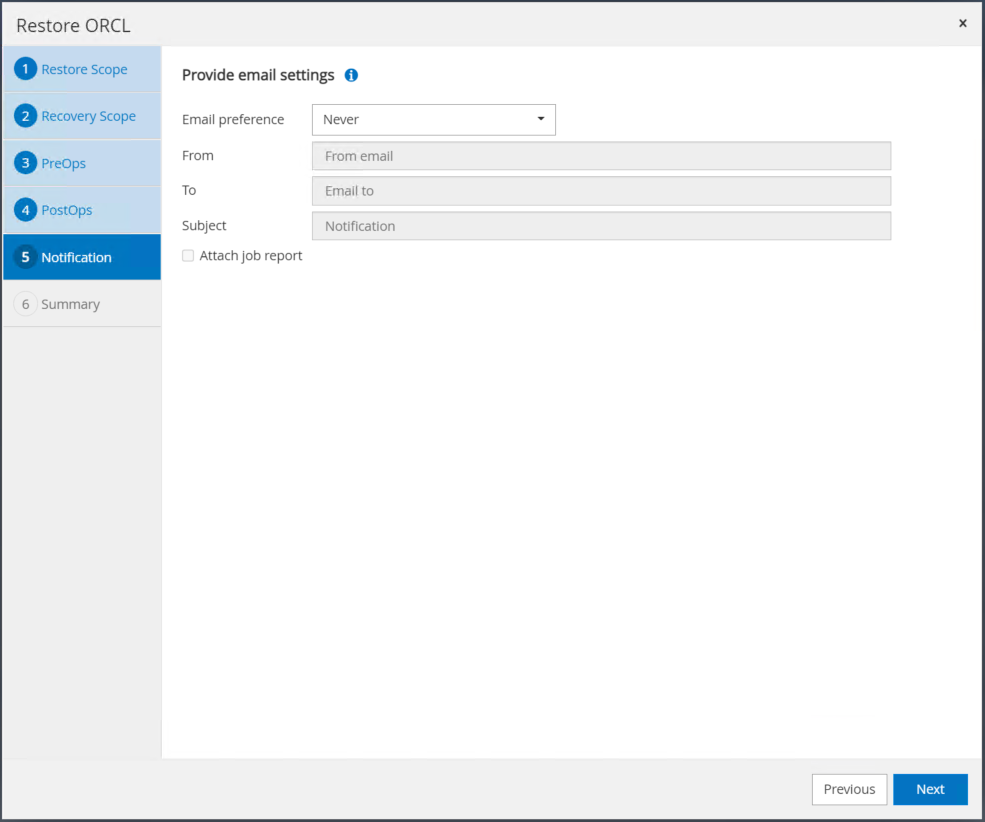
-
ジョブの概要を復元します。 [完了] をクリックして復元ジョブを開始します。
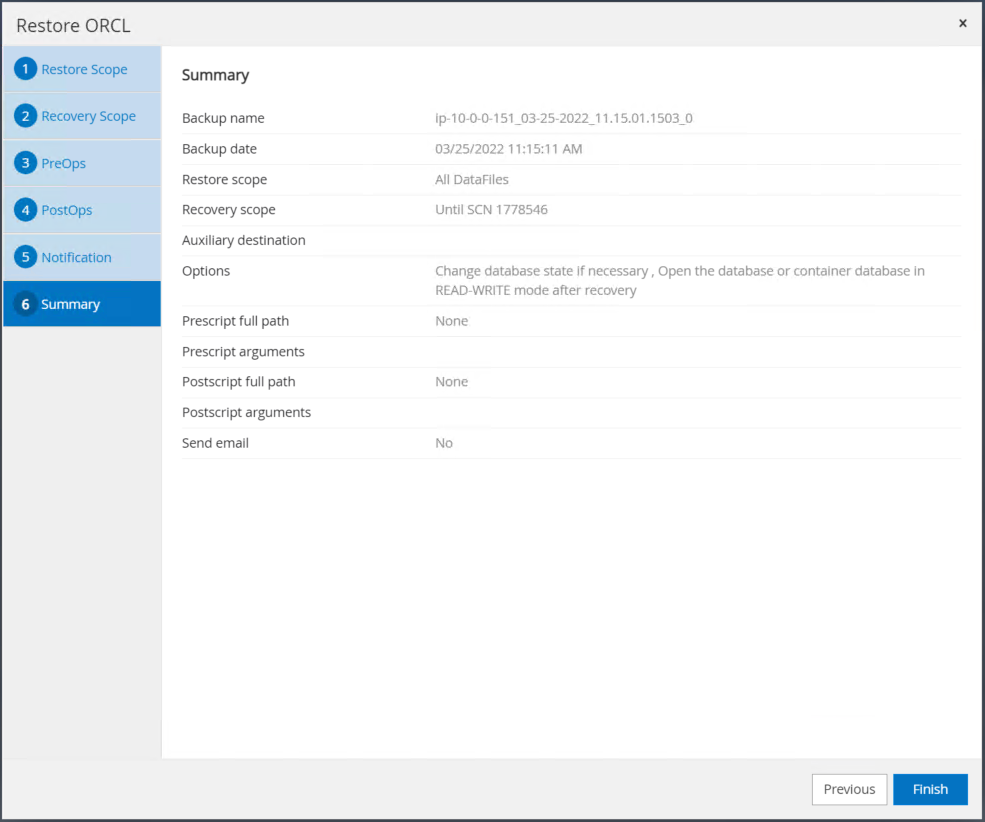
-
SnapCenterからの復元を検証します。
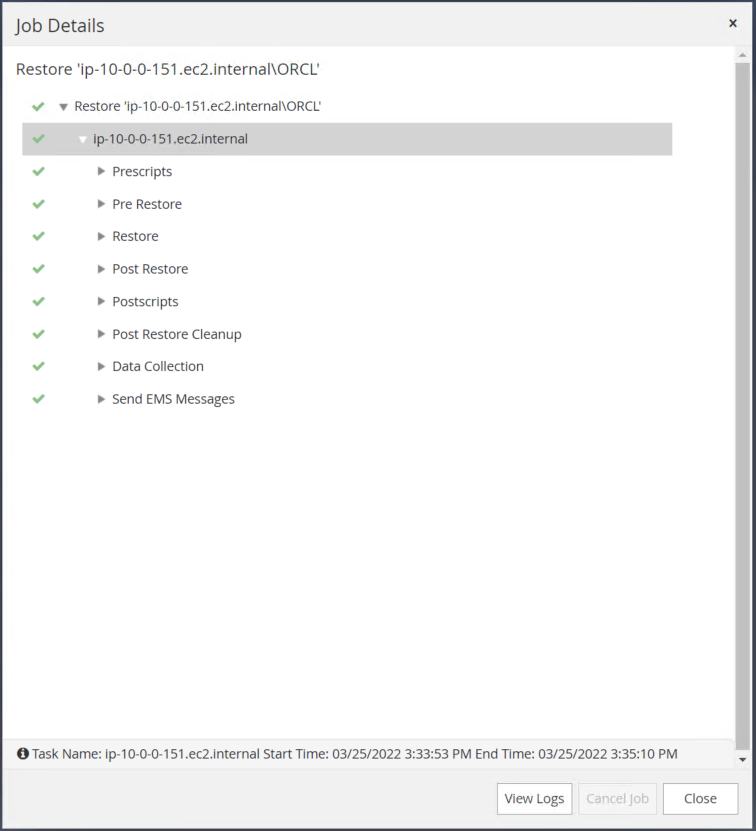
-
EC2 インスタンス ホストからの復元を検証します。
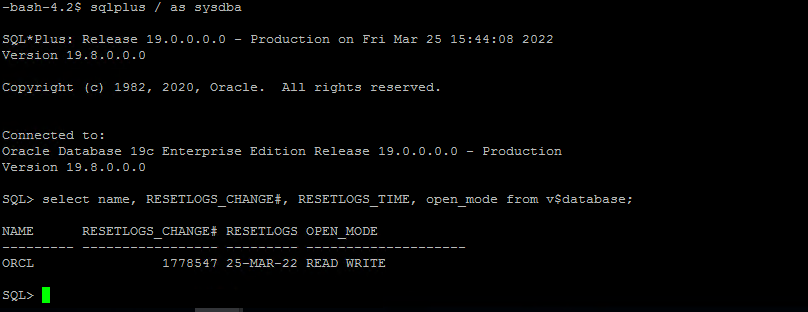
-
復元ログ ボリュームをアンマウントするには、手順 4 の手順を逆に実行します。
データベースクローンの作成
次のセクションでは、 SnapCenterクローン ワークフローを使用して、プライマリ データベースからスタンバイ EC2 インスタンスにデータベース クローンを作成する方法を説明します。
-
完全バックアップ リソース グループを使用して、 SnapCenterからプライマリ データベースの完全スナップショット バックアップを取得します。
-
SnapCenter の[リソース] タブ > [データベース] ビューから、レプリカの作成元となるプライマリ データベースの [データベース バックアップ管理] ページを開きます。
-
手順 4 で取得したログボリュームのスナップショットをスタンバイ EC2 インスタンス ホストにマウントします。
-
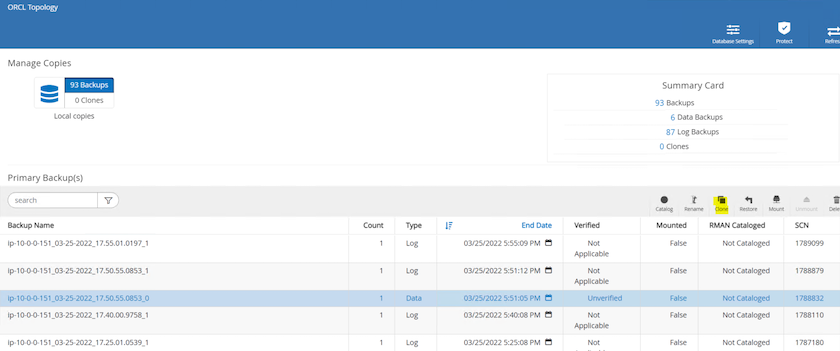
レプリカのクローンを作成するスナップショット コピーを強調表示し、[クローン] ボタンをクリックしてクローン手順を開始します。
-
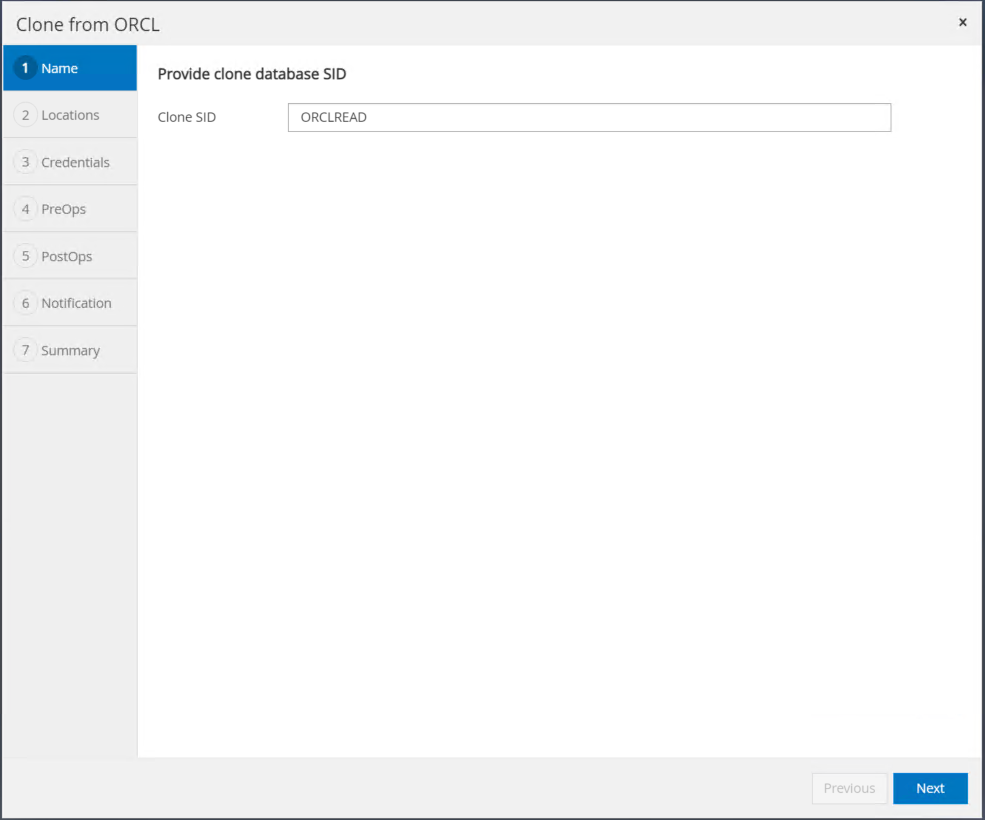
レプリカ コピー名をプライマリ データベース名と異なるように変更します。[Next]をクリックします。
-
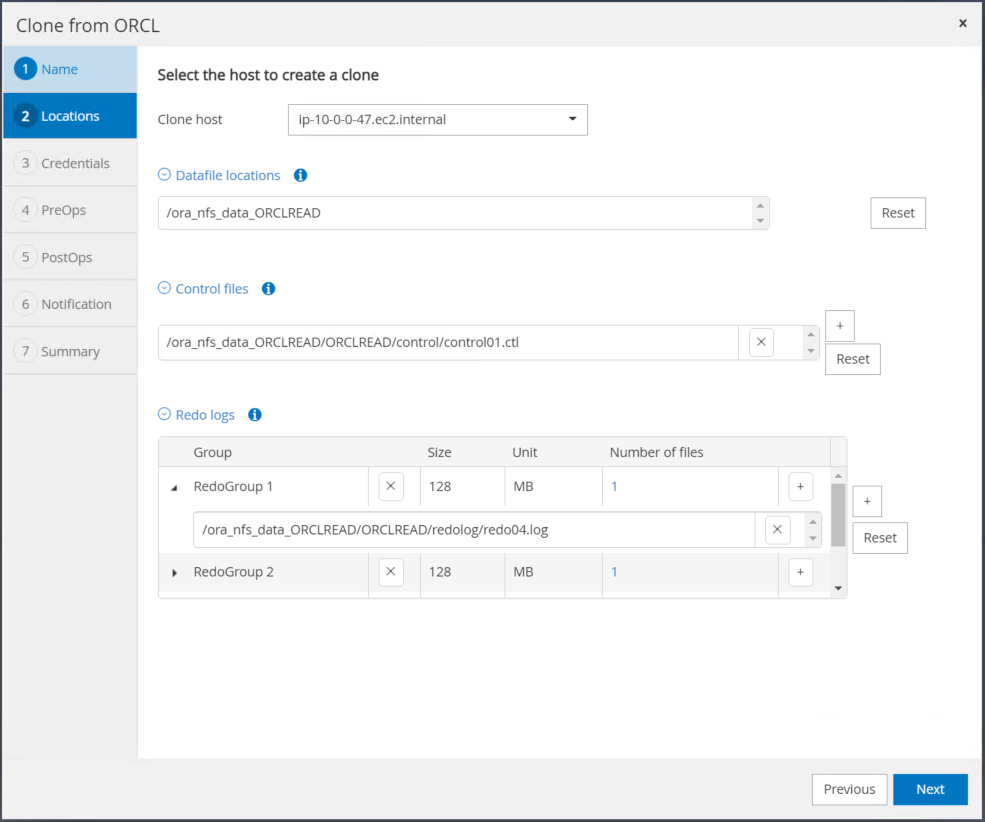
クローン ホストをスタンバイ EC2 ホストに変更し、デフォルトの名前を受け入れて、[次へ] をクリックします。
-
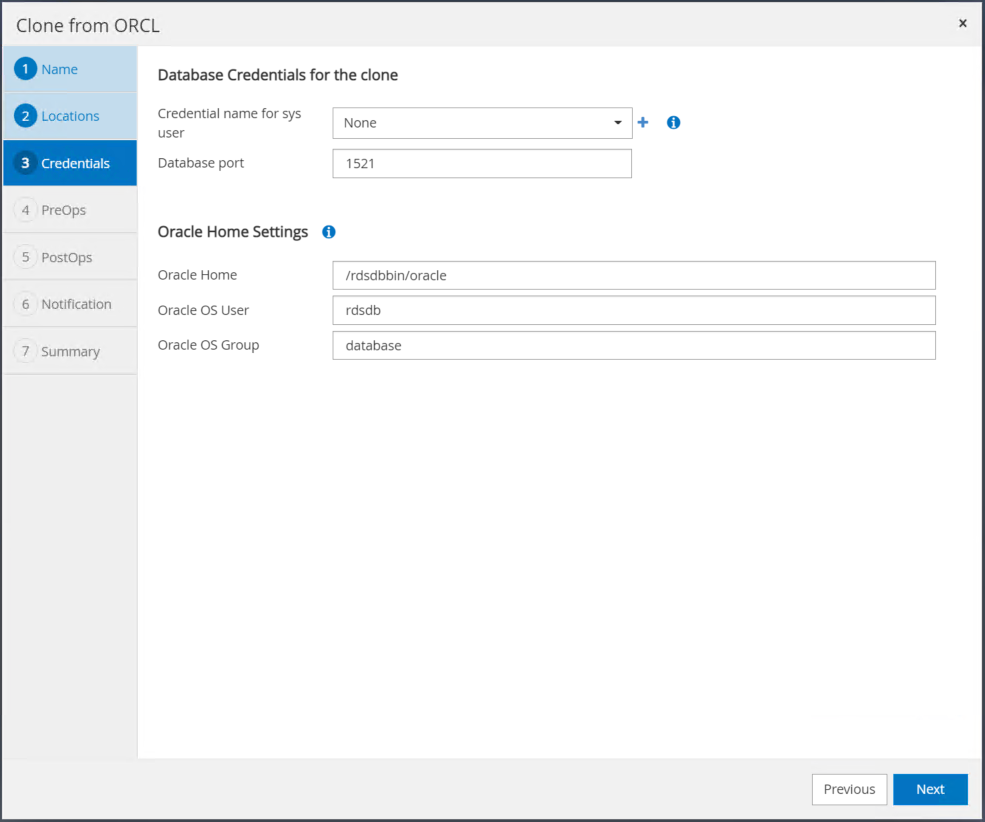
ターゲット Oracle サーバー ホスト用に構成された設定と一致するように Oracle ホーム設定を変更し、[次へ] をクリックします。
-
時間または SCN とマウントされたアーカイブ ログ パスを使用してリカバリ ポイントを指定します。
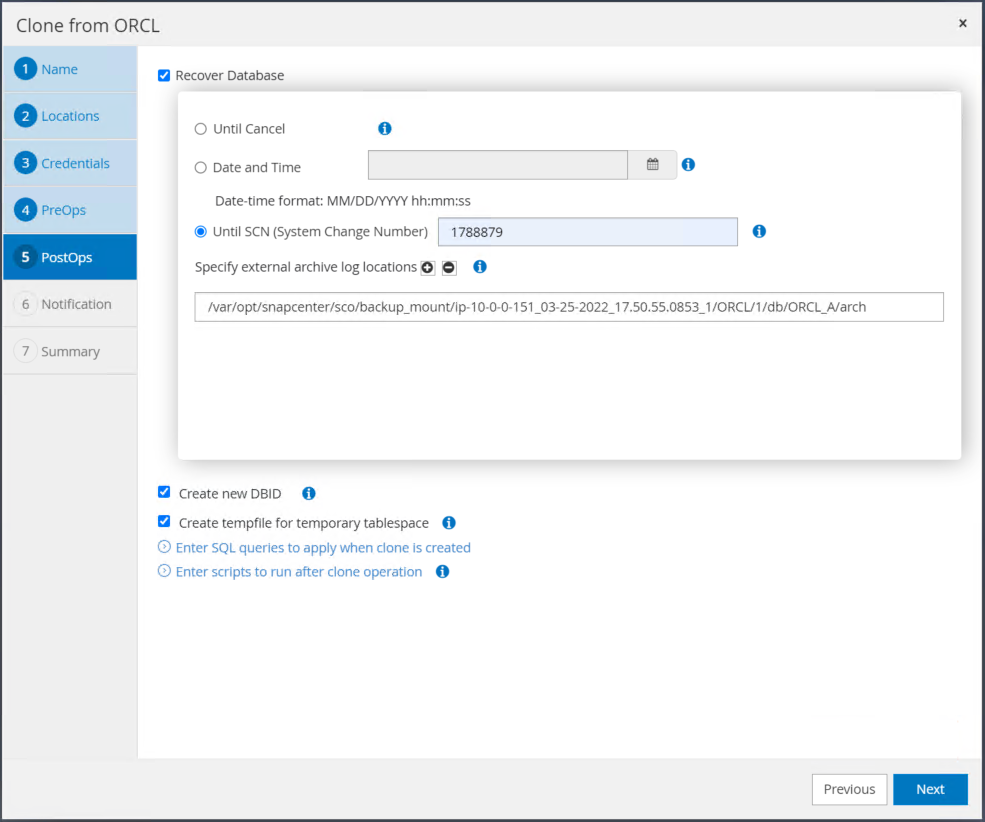
-
必要に応じて SMTP 電子メール設定を送信します。
-
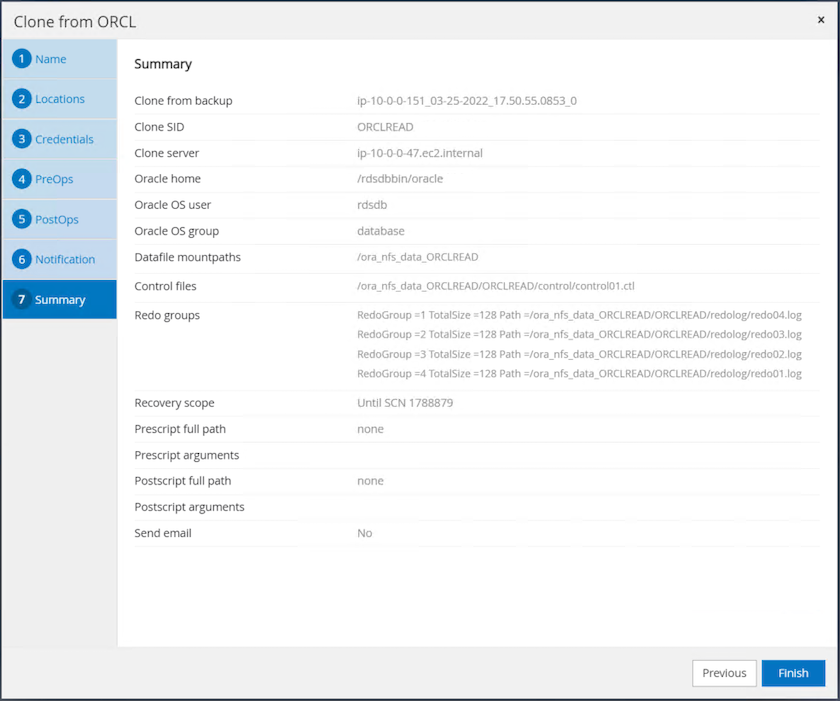
ジョブ サマリーを複製し、[完了] をクリックして複製ジョブを起動します。
-
クローン ジョブのログを確認してレプリカ クローンを検証します。
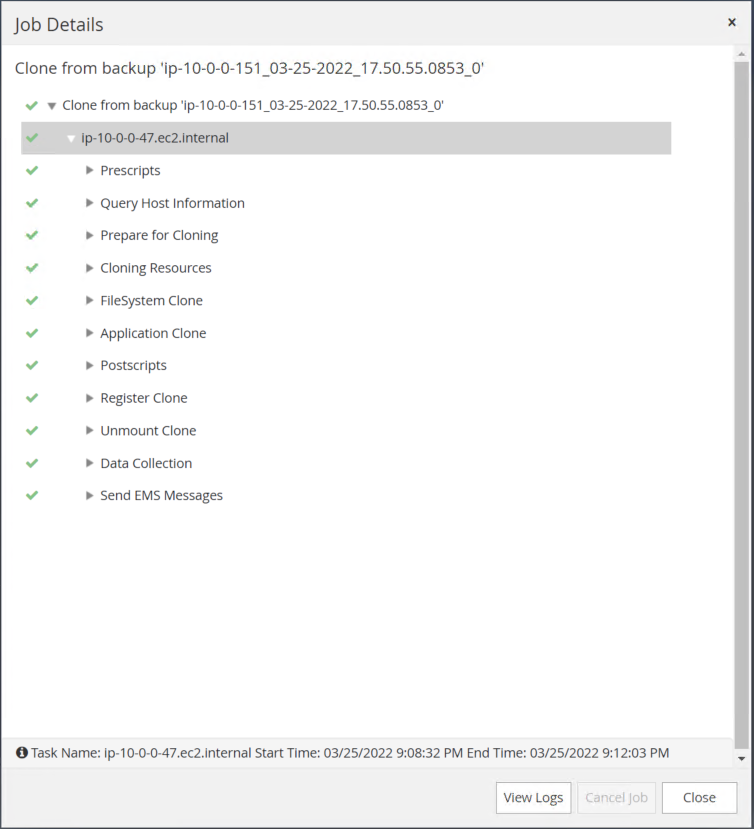
クローンされたデータベースはすぐにSnapCenterに登録されます。
-
Oracle アーカイブ ログ モードをオフにします。 EC2 インスタンスに oracle ユーザーとしてログインし、次のコマンドを実行します。
sqlplus / as sysdbashutdown immediate;startup mount;alter database noarchivelog;alter database open;

|
プライマリ Oracle バックアップ コピーの代わりに、同じ手順でターゲット FSx クラスター上の複製されたセカンダリ バックアップ コピーからクローンを作成することもできます。 |
スタンバイへのHAフェイルオーバーと再同期
スタンバイ Oracle HA クラスタは、コンピューティング レイヤーまたはストレージ レイヤーのいずれかのプライマリ サイトで障害が発生した場合に高可用性を提供します。このソリューションの大きな利点の 1 つは、ユーザーがいつでも、任意の頻度でインフラストラクチャをテストおよび検証できることです。フェイルオーバーは、ユーザーがシミュレートすることも、実際の障害によってトリガーすることもできます。フェイルオーバー プロセスは同一であり、自動化してアプリケーションの迅速な回復を実現できます。
フェイルオーバー手順については次のリストを参照してください。
-
フェイルオーバーをシミュレートするには、セクションに示されているように、ログスナップショットバックアップを実行して最新のトランザクションをスタンバイサイトにフラッシュします。[アーカイブログのスナップショットを取得する] 。実際の障害によってトリガーされたフェイルオーバーの場合、最後に成功したスケジュールされたログ ボリューム バックアップを使用して、最後に回復可能なデータがスタンバイ サイトに複製されます。
-
プライマリ FSx クラスタとスタンバイ FSx クラスタ間のSnapMirror を解除します。
-
複製されたスタンバイ データベース ボリュームをスタンバイ EC2 インスタンス ホストにマウントします。
-
複製された Oracle バイナリが Oracle リカバリに使用される場合は、Oracle バイナリを再リンクします。
-
スタンバイ Oracle データベースを、使用可能な最後のアーカイブ ログにリカバリします。
-
アプリケーションおよびユーザー アクセス用にスタンバイ Oracle データベースを開きます。
-
実際のプライマリ サイトに障害が発生した場合、スタンバイ Oracle データベースが新しいプライマリ サイトの役割を引き継ぎ、データベース ボリュームを使用して、リバースSnapMirror方式で障害が発生したプライマリ サイトを新しいスタンバイ サイトとして再構築できるようになります。
-
テストまたは検証のためにプライマリ サイトの障害をシミュレートする場合は、テスト演習の完了後にスタンバイ Oracle データベースをシャットダウンします。次に、スタンバイ EC2 インスタンス ホストからスタンバイ データベース ボリュームをマウント解除し、プライマリ サイトからスタンバイ サイトへのレプリケーションを再同期します。
これらの手順は、パブリックNetApp GitHub サイトからダウンロードできるNetApp Automation Toolkit を使用して実行できます。
git clone https://github.com/NetApp-Automation/na_ora_hadr_failover_resync.gitセットアップとフェイルオーバーのテストを行う前に、README の指示をよくお読みください。