

TR-4956: AWS FSx/EC2 における PostgreSQL 高可用性の自動化と災害復旧
 変更を提案
変更を提案
アレン・カオ、ニヤズ・モハメド、NetApp
このソリューションは、FSx ONTAPストレージ オファリングに組み込まれたNetApp SnapMirrorテクノロジーと AWS のNetApp Ansible 自動化ツールキットに基づく、PostgreSQL データベースの導入と HA/DR セットアップ、フェイルオーバー、再同期の概要と詳細を提供します。
目的
PostgreSQLは広く使用されているオープンソースデータベースであり、最も人気のあるデータベースエンジンのトップ10の中で4位にランクされています。"DBエンジン" 。一方、PostgreSQL は、高度な機能を備えながらも、ライセンスフリーのオープンソース モデルであることから人気を博しています。一方、オープンソースであるため、特にパブリック クラウドにおける高可用性と災害復旧 (HA/DR) の領域における実稼働レベルのデータベース展開に関する詳細なガイダンスが不足しています。一般的に、ホットスタンバイ、ウォームスタンバイ、ストリーミングレプリケーションなどを備えた典型的な PostgreSQL HA/DR システムをセットアップするのは難しい場合があります。スタンバイ サイトを昇格させてからプライマリ サイトに戻すことで HA/DR 環境をテストすると、本番環境に混乱が生じる可能性があります。読み取りワークロードがストリーミング ホット スタンバイに展開されている場合、プライマリでパフォーマンスの問題が発生することが十分に文書化されています。
このドキュメントでは、アプリケーションレベルの PostgreSQL ストリーミング HA/DR ソリューションを廃止し、ストレージレベルのレプリケーションを使用して AWS FSx ONTAPストレージと EC2 コンピューティングインスタンスに基づく PostgreSQL HA/DR ソリューションを構築する方法を説明します。このソリューションは、よりシンプルで同等のシステムを作成し、従来の HA/DR 向け PostgreSQL アプリケーション レベルのストリーミング レプリケーションと比較して同等の結果をもたらします。
このソリューションは、PostgreSQL HA/DR 用の AWS ネイティブ FSX ONTAPクラウド ストレージで利用できる、実績のある成熟したNetApp SnapMirrorストレージ レベルのレプリケーション テクノロジーに基づいて構築されています。 NetAppソリューション チームが提供する自動化ツールキットを使用すると、簡単に実装できます。アプリケーション レベルのストリーミング ベースの HA/DR ソリューションにより、プライマリ サイトの複雑さとパフォーマンスの低下を排除しながら、同様の機能を提供します。このソリューションは、アクティブなプライマリ サイトに影響を与えることなく、簡単に展開およびテストできます。
このソリューションは、次のユースケースに対応します。
-
パブリック AWS クラウドにおける PostgreSQL の本番環境向け HA/DR 展開
-
パブリック AWS クラウドでの PostgreSQL ワークロードのテストと検証
-
NetApp SnapMirrorレプリケーション テクノロジーに基づく PostgreSQL HA/DR 戦略のテストと検証
観客
このソリューションは次の人々を対象としています。
-
パブリック AWS クラウドで HA/DR を備えた PostgreSQL を導入することに関心のある DBA。
-
パブリック AWS クラウドで PostgreSQL ワークロードをテストすることに関心のあるデータベース ソリューション アーキテクト。
-
AWS FSx ストレージにデプロイされた PostgreSQL インスタンスのデプロイと管理に関心のあるストレージ管理者。
-
AWS FSx/EC2 で PostgreSQL 環境を立ち上げることに関心のあるアプリケーション所有者。
ソリューションのテストおよび検証環境
このソリューションのテストと検証は、最終的な展開環境と一致しない可能性のある AWS FSx および EC2 環境で実行されました。詳細については、セクションをご覧ください。 [導入検討の重要な要素] 。
アーキテクチャ
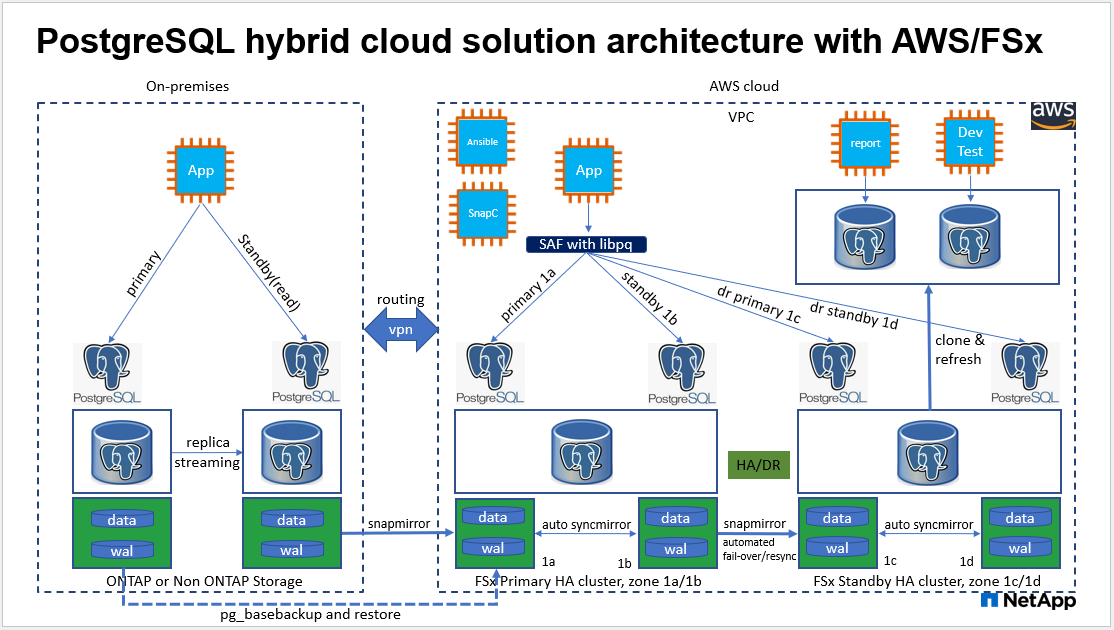
ハードウェアおよびソフトウェアコンポーネント
ハードウェア |
||
FSx ONTAPストレージ |
現在のバージョン |
プライマリおよびスタンバイ HA クラスターと同じ VPC およびアベイラビリティーゾーンにある 2 つの FSx HA ペア |
コンピューティング用のEC2インスタンス |
t2.xlarge/4vCPU/16G |
プライマリおよびスタンバイコンピューティングインスタンスとして 2 つの EC2 T2 xlarge |
Ansibleコントローラー |
オンプレミス Centos VM/4vCPU/8G |
オンプレミスまたはクラウドで Ansible 自動化コントローラをホストする VM |
ソフトウェア |
||
レッドハットリナックス |
RHEL-8.6.0_HVM-20220503-x86_64-2-Hourly2-GP2 |
テスト用にRedHatサブスクリプションを導入 |
Centos Linux |
CentOS Linux リリース 8.2.2004 (コア) |
オンプレミスのラボにデプロイされた Ansible コントローラのホスティング |
PostgreSQL |
バージョン14.5 |
自動化により、postgresql.ora yum リポジトリから PostgreSQL の最新バージョンが取得されます。 |
Ansible |
バージョン2.10.3 |
要件プレイブックでインストールされる必要なコレクションとライブラリの前提条件 |
導入検討の重要な要素
-
PostgreSQL データベースのバックアップ、リストア、リカバリ。 PostgreSQL データベースは、pg_dump を使用した論理バックアップ、pg_basebackup または低レベルの OS バックアップ コマンドを使用した物理的なオンライン バックアップ、ストレージ レベルの一貫性のあるスナップショットなど、さまざまなバックアップ方法をサポートしています。このソリューションでは、スタンバイ サイトでの PostgreSQL データベース データと WAL ボリュームのバックアップ、リストア、リカバリにNetApp の整合性グループ スナップショットを使用します。 NetApp の整合性グループ ボリューム スナップショットは、ストレージに書き込まれるときに I/O を順序付け、データベース データ ファイルの整合性を保護します。
-
*EC2 コンピューティングインスタンス。*これらのテストと検証では、PostgreSQL データベース コンピューティング インスタンスに AWS EC2 t2.xlarge インスタンス タイプを使用しました。 NetApp、データベース ワークロードに最適化されているため、導入時に PostgreSQL のコンピューティング インスタンスとして M5 タイプの EC2 インスタンスを使用することを推奨しています。スタンバイ コンピューティング インスタンスは、FSx HA クラスターにデプロイされたパッシブ (スタンバイ) ファイル システムと同じゾーンに常にデプロイする必要があります。
-
*FSx ストレージ HA クラスターの単一またはマルチゾーン展開。*これらのテストと検証では、単一の AWS アベイラビリティーゾーンに FSx HA クラスターをデプロイしました。本番環境での導入では、 NetApp は2 つの異なるアベイラビリティ ゾーンに FSx HA ペアを導入することを推奨しています。プライマリとスタンバイの間に特定の距離が必要な場合は、ビジネス継続性のための災害復旧スタンバイ HA ペアを別のリージョンに設定できます。 FSx HA クラスターは常に、アクティブ/パッシブ ファイル システムのペアで同期ミラーリングされた HA ペアでプロビジョニングされ、ストレージ レベルの冗長性を提供します。
-
*PostgreSQL データとログの配置。*一般的な PostgreSQL の展開では、データ ファイルとログ ファイルで同じルート ディレクトリまたはボリュームを共有します。私たちのテストと検証では、パフォーマンスを向上させるために、PostgreSQL データとログを 2 つの別々のボリュームに分離しました。データ ディレクトリでは、PostgreSQL WAL ログとアーカイブされた WAL ログをホストするログ ディレクトリまたはボリュームを指すためにソフト リンクが使用されます。
-
*PostgreSQL サービスの起動遅延タイマー。*このソリューションでは、NFS マウントされたボリュームを使用して、PostgreSQL データベース ファイルと WAL ログ ファイルを保存します。データベース ホストの再起動中に、ボリュームがマウントされていない状態で PostgreSQL サービスが起動を試みる場合があります。その結果、データベース サービスの起動が失敗します。 PostgreSQL データベースを正しく起動するには、10 ~ 15 秒のタイマー遅延が必要です。
-
ビジネス継続性のための RPO/RTO。 DR のためのプライマリからスタンバイへの FSx データ レプリケーションは ASYNC に基づいています。つまり、RPO はスナップショット バックアップとSnapMirrorレプリケーションの頻度に依存します。 Snapshot コピーとSnapMirrorレプリケーションの頻度を高くすると、RPO が短縮されます。したがって、災害発生時の潜在的なデータ損失と増分ストレージ コストの間でバランスが保たれます。 Snapshot コピーとSnapMirrorレプリケーションは RPO に対して最短 5 分間隔で実装でき、PostgreSQL は通常、RTO に対して 1 分以内に DR スタンバイ サイトで回復できることがわかりました。
-
データベースのバックアップ。 PostgreSQL データベースがオンプレミスデータセンターから AWS FSx ストレージに実装または移行されると、データは保護のために FSx HA ペアで自動同期されミラーリングされます。災害発生時には、複製されたスタンバイ サイトによってデータがさらに保護されます。長期的なバックアップ保持またはデータ保護のために、 NetApp、組み込みの PostgreSQL pg_basebackup ユーティリティを使用して、S3 BLOB ストレージに移植できる完全なデータベース バックアップを実行することを推奨しています。
ソリューションの展開
このソリューションの導入は、以下に示す詳細な手順に従って、 NetApp Ansible ベースの自動化ツールキットを使用して自動的に完了できます。
-
自動化ツールキットのREADme.mdの説明をお読みください。"na_postgresql_aws_deploy_hadr" 。
-
次のビデオウォークスルーをご覧ください。
-
必要なパラメータファイルを構成する(
hosts、host_vars/host_name.yml、fsx_vars.yml) は、テンプレートの関連セクションにユーザー固有のパラメータを入力することで作成できます。次に、コピー ボタンを使用して、ファイルを Ansible コントローラー ホストにコピーします。
自動展開の前提条件
展開には次の前提条件が必要です。
-
AWS アカウントが設定され、必要な VPC とネットワークセグメントが AWS アカウント内に作成されています。
-
AWS EC2 コンソールから、プライマリのプライマリ PostgreSQL DB サーバーとして 1 つ、スタンバイ DR サイトに 1 つの EC2 Linux インスタンスをデプロイする必要があります。プライマリ DR サイトとスタンバイ DR サイトでのコンピューティングの冗長性を確保するため、スタンバイ PostgreSQL DB サーバーとして 2 つの追加の EC2 Linux インスタンスをデプロイします。環境設定の詳細については、前のセクションのアーキテクチャ図を参照してください。また、"Linuxインスタンスのユーザーガイド"詳細についてはこちらをご覧ください。
-
AWS EC2 コンソールから、PostgreSQL データベースボリュームをホストするための 2 つの FSx ONTAPストレージ HA クラスターをデプロイします。 FSxストレージの導入に慣れていない場合は、ドキュメントを参照してください。"FSx ONTAPファイルシステムの作成"ステップバイステップの手順については、こちらをご覧ください。
-
Ansible コントローラーをホストするための Centos Linux VM を構築します。 Ansible コントローラーは、オンプレミスまたは AWS クラウドに配置できます。オンプレミスにある場合は、VPC、EC2 Linux インスタンス、および FSx ストレージ クラスターへの SSH 接続が必要です。
-
リソースの「RHEL/CentOS での CLI デプロイメント用の Ansible コントロールノードのセットアップ」セクションの説明に従って Ansible コントローラーをセットアップします。"NetAppソリューション自動化入門" 。
-
公開されているNetApp GitHub サイトから自動化ツールキットのコピーを複製します。
git clone https://github.com/NetApp-Automation/na_postgresql_aws_deploy_hadr.git-
ツールキットのルート ディレクトリから、前提条件となるプレイブックを実行して、Ansible コントローラーに必要なコレクションとライブラリをインストールします。
ansible-playbook -i hosts requirements.ymlansible-galaxy collection install -r collections/requirements.yml --force --force-with-deps-
DBホスト変数ファイルに必要なEC2 FSxインスタンスパラメータを取得します。 `host_vars/*`グローバル変数ファイル `fsx_vars.yml`構成。
ホストファイルを設定する
プライマリ FSx ONTAPクラスタ管理 IP と EC2 インスタンスのホスト名を hosts ファイルに入力します。
# Primary FSx cluster management IP address [fsx_ontap] 172.30.15.33
# Primary PostgreSQL DB server at primary site where database is initialized at deployment time [postgresql] psql_01p ansible_ssh_private_key_file=psql_01p.pem
# Primary PostgreSQL DB server at standby site where postgresql service is installed but disabled at deployment # Standby DB server at primary site, to setup this server comment out other servers in [dr_postgresql] # Standby DB server at standby site, to setup this server comment out other servers in [dr_postgresql] [dr_postgresql] -- psql_01s ansible_ssh_private_key_file=psql_01s.pem #psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
host_varsフォルダ内のhost_name.ymlファイルを設定します。
# Add your AWS EC2 instance IP address for the respective PostgreSQL server host
ansible_host: "10.61.180.15"
# "{{groups.postgresql[0]}}" represents first PostgreSQL DB server as defined in PostgreSQL hosts group [postgresql]. For concurrent multiple PostgreSQL DB servers deployment, [0] will be incremented for each additional DB server. For example, "{{groups.posgresql[1]}}" represents DB server 2, "{{groups.posgresql[2]}}" represents DB server 3 ... As a good practice and the default, two volumes are allocated to a PostgreSQL DB server with corresponding /pgdata, /pglogs mount points, which store PostgreSQL data, and PostgreSQL log files respectively. The number and naming of DB volumes allocated to a DB server must match with what is defined in global fsx_vars.yml file by src_db_vols, src_archivelog_vols parameters, which dictates how many volumes are to be created for each DB server. aggr_name is aggr1 by default. Do not change. lif address is the NFS IP address for the SVM where PostgreSQL server is expected to mount its database volumes. Primary site servers from primary SVM and standby servers from standby SVM.
host_datastores_nfs:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
# Add swap space to EC2 instance, that is equal to size of RAM up to 16G max. Determine the number of blocks by dividing swap size in MB by 128.
swap_blocks: "128"
# Postgresql user configurable parameters
psql_port: "5432"
buffer_cache: "8192MB"
archive_mode: "on"
max_wal_size: "5GB"
client_address: "172.30.15.0/24"varsフォルダ内のグローバルfsx_vars.ymlファイルを設定します。
########################################################################
###### PostgreSQL HADR global user configuration variables ######
###### Consolidate all variables from FSx, Linux, and postgresql ######
########################################################################
###########################################
### Ontap env specific config variables ###
###########################################
####################################################################################################
# Variables for SnapMirror Peering
####################################################################################################
#Passphrase for cluster peering authentication
passphrase: "xxxxxxx"
#Please enter destination or standby FSx cluster name
dst_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter destination or standby FSx cluster management IP
dst_cluster_ip: "172.30.15.90"
#Please enter destination or standby FSx cluster inter-cluster IP
dst_inter_ip: "172.30.15.13"
#Please enter destination or standby SVM name to create mirror relationship
dst_vserver: "dr"
#Please enter destination or standby SVM management IP
dst_vserver_mgmt_lif: "172.30.15.88"
#Please enter destination or standby SVM NFS lif
dst_nfs_lif: "172.30.15.88"
#Please enter source or primary FSx cluster name
src_cluster_name: "FsxId0cf8e0bccb14805e8"
#Please enter source or primary FSx cluster management IP
src_cluster_ip: "172.30.15.20"
#Please enter source or primary FSx cluster inter-cluster IP
src_inter_ip: "172.30.15.5"
#Please enter source or primary SVM name to create mirror relationship
src_vserver: "prod"
#Please enter source or primary SVM management IP
src_vserver_mgmt_lif: "172.30.15.115"
#####################################################################################################
# Variable for PostgreSQL Volumes, lif - source or primary FSx NFS lif address
#####################################################################################################
src_db_vols:
- {vol_name: "{{groups.postgresql[0]}}_pgdata", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
src_archivelog_vols:
- {vol_name: "{{groups.postgresql[0]}}_pglogs", aggr_name: "aggr1", lif: "172.21.94.200", size: "100"}
#Names of the Nodes in the ONTAP Cluster
nfs_export_policy: "default"
#####################################################################################################
### Linux env specific config variables ###
#####################################################################################################
#NFS Mount points for PostgreSQL DB volumes
mount_points:
- "/pgdata"
- "/pglogs"
#RedHat subscription username and password
redhat_sub_username: "xxxxx"
redhat_sub_password: "xxxxx"
####################################################
### DB env specific install and config variables ###
####################################################
#The latest version of PostgreSQL RPM is pulled/installed and config file is deployed from a preconfigured template
#Recovery type and point: default as all logs and promote and leave all PITR parameters blankPostgreSQLの導入とHA/DRのセットアップ
次のタスクでは、PostgreSQL DB サーバー サービスをデプロイし、プライマリ EC2 DB サーバー ホスト上のプライマリ サイトでデータベースを初期化します。次に、スタンバイ サイトにスタンバイ プライマリ EC2 DB サーバー ホストがセットアップされます。最後に、災害復旧のために、プライマリ サイトの FSx クラスターからスタンバイ サイトの FSx クラスターへの DB ボリュームのレプリケーションが設定されます。
-
プライマリ FSx クラスターに DB ボリュームを作成し、プライマリ EC2 インスタンス ホストに postgresql をセットアップします。
ansible-playbook -i hosts postgresql_deploy.yml -u ec2-user --private-key psql_01p.pem -e @vars/fsx_vars.yml -
スタンバイ DR EC2 インスタンス ホストをセットアップします。
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.yml -
FSx ONTAPクラスタ ピアリングとデータベース ボリューム レプリケーションを設定します。
ansible-playbook -i hosts fsx_replication_setup.yml -e @vars/fsx_vars.yml -
前の手順を 1 ステップの PostgreSQL デプロイメントと HA/DR セットアップに統合します。
ansible-playbook -i hosts postgresql_hadr_setup.yml -u ec2-user -e @vars/fsx_vars.yml -
プライマリ サイトまたはスタンバイ サイトのいずれかでスタンバイ PostgreSQL DB ホストを設定するには、ホスト ファイルの [dr_postgresql] セクションにある他のすべてのサーバーをコメント アウトし、それぞれのターゲット ホスト (psql_01ps やプライマリ サイトのスタンバイ EC2 コンピューティング インスタンスなど) で postgresql_standby_setup.yml プレイブックを実行します。次のようなホストパラメータファイルがあることを確認してください。 `psql_01ps.yml`は、 `host_vars`ディレクトリ。
[dr_postgresql] -- #psql_01s ansible_ssh_private_key_file=psql_01s.pem psql_01ps ansible_ssh_private_key_file=psql_01ps.pem #psql_01ss ansible_ssh_private_key_file=psql_01ss.pem
ansible-playbook -i hosts postgresql_standby_setup.yml -u ec2-user --private-key psql_01ps.pem -e @vars/fsx_vars.ymlPostgreSQLデータベースのスナップショットバックアップとスタンバイサイトへのレプリケーション
PostgreSQL データベース スナップショットのバックアップとスタンバイ サイトへのレプリケーションは、ユーザーが定義した間隔で Ansible コントローラー上で制御および実行できます。間隔は 5 分程度まで短くなることが確認されています。したがって、プライマリ サイトで障害が発生した場合、次のスケジュールされたスナップショット バックアップの直前に障害が発生すると、5 分間のデータ損失が発生する可能性があります。
*/15 * * * * /home/admin/na_postgresql_aws_deploy_hadr/data_log_snap.shDRのためのスタンバイサイトへのフェイルオーバー
DR 演習として PostgreSQL HA/DR システムをテストするには、次のプレイブックを実行して、スタンバイ サイトのプライマリ スタンバイ EC2 DB インスタンスでフェイルオーバーと PostgreSQL データベースのリカバリを実行します。実際の DR シナリオでは、実際に DR サイトへのフェイルオーバーに対して同じことを実行します。
ansible-playbook -i hosts postgresql_failover.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.ymlフェイルオーバーテスト後に複製されたDBボリュームを再同期する
フェイルオーバー テスト後に再同期を実行して、データベース ボリュームのSnapMirrorレプリケーションを再確立します。
ansible-playbook -i hosts postgresql_standby_resync.yml -u ec2-user --private-key psql_01s.pem -e @vars/fsx_vars.ymlEC2 コンピューティングインスタンスの障害によるプライマリ EC2 DB サーバーからスタンバイ EC2 DB サーバーへのフェイルオーバー
NetApp、手動フェイルオーバーを実行するか、ライセンスが必要になる可能性のある確立された OS クラスタウェアを使用することをお勧めします。
詳細情報の入手方法
このドキュメントに記載されている情報の詳細については、次のドキュメントや Web サイトを参照してください。
-
Amazon FSx ONTAP
-
Amazon EC2
-
NetAppソリューション自動化