

ONTAP で MetroCluster FC ソフトウェアを設定する
 変更を提案
変更を提案
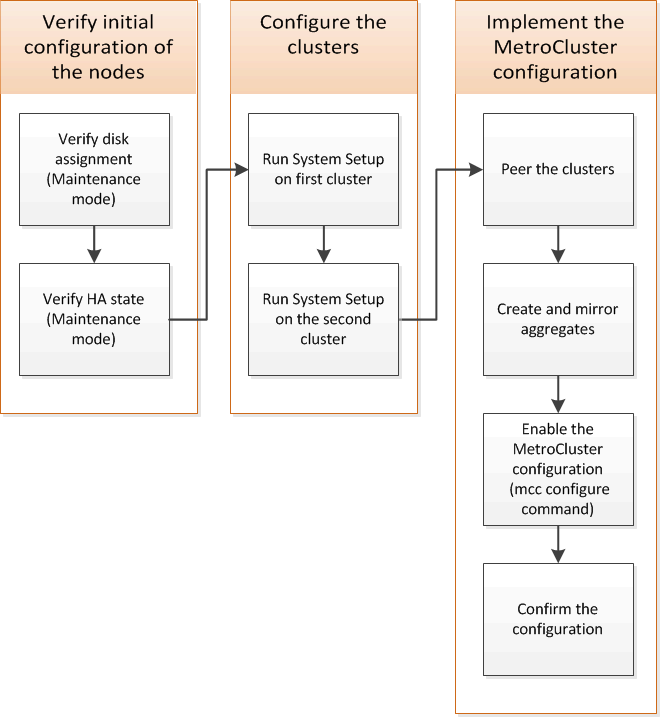
ONTAP の MetroCluster FC 構成で各ノードをセットアップする必要があります。これには、ノード レベルの構成と、2 つのサイトへのノードの構成が含まれます。また、2 つのサイト間の MetroCluster 関係を実装する必要があります。
必要な情報の収集
設定プロセスを開始する前に、コントローラモジュールに必要な IP アドレスを収集する必要があります。
サイト A の IP ネットワーク情報ワークシート
システムを設定する前に、最初の MetroCluster サイト(サイト A )の IP アドレスその他のネットワーク情報を、ネットワーク管理者から入手する必要があります。
スイッチ情報:サイト A (スイッチクラスタ)
システムをケーブル接続するときは、各クラスタスイッチのホスト名と管理 IP アドレスが必要です。この情報は、 2 ノードスイッチレスクラスタ構成または 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)を使用している場合は必要ありません。
クラスタスイッチ |
ホスト名 |
IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
インターコネクト 1. |
||||
インターコネクト 2 |
||||
管理 1 |
||||
管理 2. |
クラスタ作成情報:サイト A
クラスタを初めて作成するときは、次の情報が必要です。
情報のタイプ |
値を入力します |
クラスタ名 この手順で使用している例: site_A |
|
DNS ドメイン |
|
DNS ネームサーバ |
|
場所 |
|
管理者パスワード |
ノード情報:サイト A
クラスタ内のノードごとに、管理 IP アドレス、ネットワークマスク、およびデフォルトゲートウェイが必要です。
ノード |
ポート |
IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
ノード 1 この手順で使用している例: controller_A_1 |
||||
ノード 2 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)を使用している場合は不要 この手順で使用している例: controller_A_2 |
クラスタピアリング用の LIF およびポート:サイト A
クラスタ内のノードごとに、 2 つのクラスタ間 LIF の IP アドレス、ネットワークマスク、およびデフォルトゲートウェイが必要です。クラスタ間 LIF は、クラスタのピアリングに使用されます。
ノード |
ポート |
クラスタ間 LIF の IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
ノード 1 IC LIF 1 |
||||
ノード 1 IC LIF 2 |
||||
ノード 2 IC LIF 1 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)の場合は不要 |
||||
ノード 2 IC LIF 2 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)の場合は不要 |
タイムサーバ情報:サイト A
時間を同期する必要があります。これには 1 台以上の NTP タイムサーバが必要です。
ノード |
ホスト名 |
IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
NTP サーバ 1 |
||||
NTP サーバ 2 |
サイトA nbsp;AutoSupport 情報
各ノードで AutoSupport を設定する必要があります。これには次の情報が必要です。
情報のタイプ |
値を入力します |
|
送信元 E メールアドレス |
メールホスト |
|
IP アドレスまたは名前 |
転送プロトコル |
|
HTTP 、 HTTPS 、または SMTP |
プロキシサーバ |
|
受信者の E メールアドレスまたは配信リスト |
メッセージ全文 |
|
簡潔なメッセージ |
||
サイトA nbsp;SP情報
トラブルシューティングとメンテナンスのために、各ノードのサービスプロセッサ( SP )へのアクセスを有効にする必要があります。これには、ノードごとに次のネットワーク情報が必要です。
ノード |
IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
ノード 1 |
|||
ノード 2 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)の場合は不要 |
サイト B の IP ネットワーク情報ワークシート
システムを設定する前に、 2 つ目の MetroCluster サイト(サイト B )の IP アドレスその他のネットワーク情報を、ネットワーク管理者から入手する必要があります。
スイッチ情報:サイト B (スイッチクラスタ)
システムをケーブル接続するときは、各クラスタスイッチのホスト名と管理 IP アドレスが必要です。この情報は、 2 ノードスイッチレスクラスタ構成または 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)を使用している場合は必要ありません。
クラスタスイッチ |
ホスト名 |
IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
インターコネクト 1. |
||||
インターコネクト 2 |
||||
管理 1 |
||||
管理 2. |
クラスタ作成情報:サイト B
クラスタを初めて作成するときは、次の情報が必要です。
情報のタイプ |
値を入力します |
クラスタ名 この手順で使用される例:site_B |
|
DNS ドメイン |
|
DNS ネームサーバ |
|
場所 |
|
管理者パスワード |
ノード情報:サイト B
クラスタ内のノードごとに、管理 IP アドレス、ネットワークマスク、およびデフォルトゲートウェイが必要です。
ノード |
ポート |
IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
ノード 1 この手順で使用される例:controller_B_1 |
||||
ノード 2 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)の場合は不要 この手順で使用される例:controller_B_2 |
クラスタピアリング用の LIF およびポート:サイト B
クラスタ内のノードごとに、 2 つのクラスタ間 LIF の IP アドレス、ネットワークマスク、およびデフォルトゲートウェイが必要です。クラスタ間 LIF は、クラスタのピアリングに使用されます。
ノード |
ポート |
クラスタ間 LIF の IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
ノード 1 IC LIF 1 |
||||
ノード 1 IC LIF 2 |
||||
ノード 2 IC LIF 1 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)の場合は不要 |
||||
ノード 2 IC LIF 2 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)の場合は不要 |
タイムサーバ情報:サイト B
時間を同期する必要があります。これには 1 台以上の NTP タイムサーバが必要です。
ノード |
ホスト名 |
IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
NTP サーバ 1 |
||||
NTP サーバ 2 |
サイトB nbsp;AutoSupport情報
各ノードで AutoSupport を設定する必要があります。これには次の情報が必要です。
情報のタイプ |
値を入力します |
|
送信元 E メールアドレス |
||
メールホスト |
IP アドレスまたは名前 |
|
転送プロトコル |
HTTP 、 HTTPS 、または SMTP |
|
プロキシサーバ |
受信者の E メールアドレスまたは配信リスト |
|
メッセージ全文 |
簡潔なメッセージ |
|
パートナー |
||
サイトB nbsp;SP情報
トラブルシューティングとメンテナンスのために、各ノードのサービスプロセッサ( SP )へのアクセスを有効にする必要があります。これには、ノードごとに次のネットワーク情報が必要です。
ノード |
IP アドレス |
ネットワークマスク |
デフォルトゲートウェイ |
ノード 1 ( controller_B_1 ) |
|||
ノード 2 ( controller_B_2 ) 2 ノード MetroCluster 構成(サイトごとに 1 つのノード)の場合は不要 |
標準クラスタ構成と MetroCluster 構成の類似点 / 相違点
MetroCluster 構成の各クラスタのノードの構成は、標準クラスタのノードと似ています。
MetroCluster 構成は、 2 つの標準クラスタを基盤としています。構成は物理的に対称な構成である必要があり、各ノードのハードウェア構成が同じで、すべての MetroCluster コンポーネントがケーブル接続され、設定されている必要があります。ただし、 MetroCluster 構成のノードの基本的なソフトウェア設定は、標準クラスタのノードと同じです。
設定手順 |
標準クラスタ構成 |
MetroCluster の設定 |
各ノードで管理 LIF 、クラスタ LIF 、データ LIF を設定。 |
両方のクラスタタイプで同じです |
|
ルートアグリゲートを設定 |
両方のクラスタタイプで同じです |
|
クラスタ内のノードを HA ペアとして設定 |
両方のクラスタタイプで同じです |
|
クラスタ内の一方のノードでクラスタを設定。 |
両方のクラスタタイプで同じです |
|
もう一方のノードをクラスタに追加。 |
両方のクラスタタイプで同じです |
|
ミラーされたルートアグリゲートを作成 |
任意。 |
必須 |
クラスタをピアリング。 |
任意。 |
必須 |
MetroCluster 設定を有効にします。 |
該当しません |
必須 |
メンテナンスモードでコンポーネントの HA 状態を確認および設定する
ストレージシステムをMetroCluster FC構成で構成する場合は、コントローラモジュールおよびシャーシのコンポーネントのハイアベイラビリティ(HA)状態がmccまたはmcc-2nであることを確認して、これらのコンポーネントが適切にブートするようにする必要があります。工場出荷状態のシステムではこの値を事前に設定しておく必要がありますが、作業を進める前に設定を確認しておく必要があります。

|
コントローラモジュールとシャーシのHA状態が正しくない場合は、ノードを再初期化しないとMetroClusterを設定できません。この手順を使用して設定を修正し、次のいずれかの手順を使用してシステムを初期化する必要があります。
|
システムがメンテナンスモードであることを確認します。
-
メンテナンスモードで、コントローラモジュールとシャーシの HA 状態を表示します。
「 ha-config show 」
HA の正しい状態は、 MetroCluster 構成によって異なります。
MetroCluster構成タイプ
すべてのコンポーネントのHA状態
8ノードまたは4ノードのMetroCluster FC構成
MCC
2 ノード MetroCluster FC 構成
mcc-2n
8ノードまたは4ノードのMetroCluster IP構成
mccip
-
表示されたコントローラのシステム状態が正しくない場合は、コントローラモジュールで構成に応じた正しいHA状態を設定します。
MetroCluster構成タイプ
コマンドを実行します
8ノードまたは4ノードのMetroCluster FC構成
「 ha-config modify controller mcc 」
2 ノード MetroCluster FC 構成
「 ha-config modify controller mcc-2n 」という形式で指定します
8ノードまたは4ノードのMetroCluster IP構成
「 ha-config modify controller mccip 」を参照してください
-
表示されたシャーシのシステム状態が正しくない場合は、シャーシの構成に応じた正しいHA状態を設定します。
MetroCluster構成タイプ
コマンドを実行します
8ノードまたは4ノードのMetroCluster FC構成
「 ha-config modify chassis mcc 」
2 ノード MetroCluster FC 構成
「 ha-config modify chassis mcc-2n 」というようになりました
8ノードまたは4ノードのMetroCluster IP構成
「 ha-config modify chassis mccip 」を参照してください
-
ノードを ONTAP でブートします。
「 boot_ontap 」
-
この手順をすべて繰り返して、MetroCluster構成の各ノードのHA状態を確認します。
システムのデフォルト設定をリストアし、コントローラモジュールで HBA タイプを設定しています
MetroCluster を正しくインストールするには、コントローラモジュールのデフォルトをリセットしてリストアします。
このタスクを実行する必要があるのは、 FC-to-SAS ブリッジを使用するストレッチ構成のみです。
-
LOADER プロンプトで環境変数をデフォルト設定に戻します。
「デフォルト設定」
-
ノードをメンテナンスモードでブートし、システム内の HBA の設定を行います。
-
メンテナンスモードでブートします。
「 boot_ontap maint 」を使用してください
-
ポートの現在の設定を確認します。
ucadmin show
-
必要に応じてポートの設定を更新します。
HBA のタイプと目的のモード
使用するコマンド
CNA FC
ucadmin modify -m fc -t initiator_adapter_name _ `
CNA イーサネット
ucadmin modify -mode cna_adapter_name _ `
FC ターゲット
fcadmin config -t target_adapter_name _`
FC イニシエータ
fcadmin config -t initiator_adapter_name_`
-
-
メンテナンスモードを終了します。
「 halt 」
コマンドの実行後、ノードが LOADER プロンプトで停止するまで待ちます。
-
ノードをブートしてメンテナンスモードに戻り、設定の変更が反映されるようにします。
「 boot_ontap maint 」を使用してください
-
変更内容を確認します。
HBA のタイプ
使用するコマンド
CNA
ucadmin show
FC
fcadmin show`
-
メンテナンスモードを終了します。
「 halt 」
コマンドの実行後、ノードが LOADER プロンプトで停止するまで待ちます。
-
ノードをブートメニューでブートします。
「 boot_ontap menu
コマンドの実行後、ブートメニューが表示されるまで待ちます。
-
ブートメニュープロンプトで「 wipeconfig 」と入力してノード設定をクリアし、 Enter キーを押します。
次の画面はブートメニューのプロンプトを示しています。
Please choose one of the following:
(1) Normal Boot.
(2) Boot without /etc/rc.
(3) Change password.
(4) Clean configuration and initialize all disks.
(5) Maintenance mode boot.
(6) Update flash from backup config.
(7) Install new software first.
(8) Reboot node.
(9) Configure Advanced Drive Partitioning.
Selection (1-9)? wipeconfig
This option deletes critical system configuration, including cluster membership.
Warning: do not run this option on a HA node that has been taken over.
Are you sure you want to continue?: yes
Rebooting to finish wipeconfig request.
FAS8020 システムでの X1132A-R6 クアッドポートカードの FC-VI ポートの設定
FAS8020 システムで X1132A-R6 クアッドポートカードを使用している場合は、メンテナンスモードに切り替えて、ポート 1a / 1b を FC-VI およびイニシエータ用に使用するように設定できます。工場出荷状態の MetroCluster システムでは、構成に応じて適切にポートが設定されているため、この設定は必要ありません。
このタスクはメンテナンスモードで実行する必要があります。

|
ucadmin コマンドを使用した FC ポートの FC-VI ポートへの変換は、 FAS8020 および AFF 8020 システムでのみサポートされます。他のプラットフォームでは、 FC ポートを FCVI ポートに変換することはできません。 |
-
ポートを無効にします。
「ストレージ無効化アダプタ 1a 」
「ストレージ無効化アダプタ 1b'
*> storage disable adapter 1a Jun 03 02:17:57 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1a. Host adapter 1a disable succeeded Jun 03 02:17:57 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1a is now offline. *> storage disable adapter 1b Jun 03 02:18:43 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1b. Host adapter 1b disable succeeded Jun 03 02:18:43 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1b is now offline. *>
-
ポートが無効になっていることを確認します。
ucadmin show
*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - - offline 1b fc initiator - - offline 1c fc initiator - - online 1d fc initiator - - online -
ポート a とポート b を FC-VI モードに設定します。
ucadmin modify -adapter 1a -type FCVI`
このコマンドでは、 1a だけを指定した場合でも、ポートペアの両方のポート 1a と 1b のモードが設定されます。
*> ucadmin modify -t fcvi 1a Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1a. Reboot the controller for the changes to take effect. Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1b. Reboot the controller for the changes to take effect.
-
変更が保留中であることを確認します。
ucadmin show
*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - fcvi offline 1b fc initiator - fcvi offline 1c fc initiator - - online 1d fc initiator - - online -
コントローラをシャットダウンし、メンテナンスモードでリブートします。
-
設定の変更を確認します。
ucadmin show local
Node Adapter Mode Type Mode Type Status ------------ ------- ------- --------- ------- --------- ----------- ... controller_B_1 1a fc fcvi - - online controller_B_1 1b fc fcvi - - online controller_B_1 1c fc initiator - - online controller_B_1 1d fc initiator - - online 6 entries were displayed.
メンテナンスモードでの 8 ノードまたは 4 ノード構成のディスク割り当ての検証
システムを ONTAP で完全にブートする前に、オプションで、メンテナンスモードでブートしてノードのディスク割り当てを確認することができます。ディスクは、各プールのディスク数が等しい、完全に対称なアクティブ / アクティブ構成を形成するように割り当てられている必要があります。
新しい MetroCluster システムの場合、出荷前にディスク割り当てが完了しています。
次の表に、 MetroCluster 構成のプール割り当ての例を示します。ディスクはシェルフ単位でプールに割り当てられます。
-
サイト A のディスクシェルフ *
ディスクシェルフ( sample_shelf_name ) |
所属ノード |
割り当てプール |
ディスクシェルフ 1 ( shelf_A_1_1 ) |
ノード A1 |
プール 0 |
ディスクシェルフ 2 ( shelf_A_1_3 ) |
||
ディスクシェルフ 3 ( shelf_B_1_1 ) |
ノード B1 |
プール 1. |
ディスクシェルフ 4 ( shelf_B_1_3 ) |
||
ディスクシェルフ 5 ( shelf_A_2_1 ) |
ノード A2 |
プール 0 |
ディスクシェルフ 6 ( shelf_A_2_3 ) |
||
ディスクシェルフ 7 ( shelf_B_2_1 ) |
ノード B2 |
プール 1. |
ディスクシェルフ 8 ( shelf_B_2_3 ) |
||
ディスクシェルフ 1 ( shelf_A_3_1 ) |
ノード a 3 |
プール 0 |
ディスクシェルフ 2 ( shelf_A_3_3 ) |
||
ディスクシェルフ 3 ( shelf_B_3_1 ) |
ノード B3 |
プール 1. |
ディスクシェルフ 4 ( shelf_B_3_3 ) |
||
ディスクシェルフ 5 ( shelf_A_4_1 ) |
ノード A4 |
プール 0 |
ディスクシェルフ 6 ( shelf_A_4_3 ) |
||
ディスクシェルフ 7 ( shelf_B_4_1 ) |
ノード B4 |
プール 1. |
ディスクシェルフ 8 ( shelf_B_4_3 ) |
-
サイト B のディスクシェルフ *
ディスクシェルフ( sample_shelf_name ) |
所属ノード |
割り当てプール |
ディスクシェルフ 9 ( shelf_B_1_2 ) |
ノード B1 |
プール 0 |
ディスクシェルフ 10 ( shelf_B_1_4 ) |
ディスクシェルフ 11 ( shelf_A_1_2 ) |
ノード A1 |
プール 1. |
ディスクシェルフ 12 ( shelf_A_1_4 ) |
ディスクシェルフ 13 ( shelf_B_2_2 ) |
ノード B2 |
プール 0 |
ディスクシェルフ 14 ( shelf_B_2_4 ) |
ディスクシェルフ 15 ( shelf_A_2_2 ) |
ノード A2 |
プール 1. |
ディスクシェルフ 16 ( shelf_A_2_4 ) |
ディスクシェルフ 1 ( shelf_B_3_2 ) |
ノード a 3 |
プール 0 |
ディスクシェルフ 2 ( shelf_B_3_4 ) |
ディスクシェルフ 3 ( shelf_A_3_2 ) |
ノード B3 |
プール 1. |
ディスクシェルフ 4 ( shelf_A_3_4 ) |
ディスクシェルフ 5 ( shelf_B_4_2 ) |
ノード A4 |
プール 0 |
ディスクシェルフ 6 ( shelf_B_4_4 ) |
ディスクシェルフ 7 ( shelf_A_4_2 ) |
ノード B4 |
-
シェルフの割り当てを確認します。
「 Disk show – v 」のように表示されます
-
必要に応じて、接続されているディスクシェルフ上のディスクを適切なプールに明示的に割り当てます。
「ディスク割り当て」
ワイルドカードを使用すると、 1 回のコマンドで 1 つのディスクシェルフのすべてのディスクを割り当てることができます。「 storage show disk --x 」コマンドを使用すると、各ディスクのディスクシェルフ ID とベイを識別できます。
AFF 以外のシステムでディスク所有権を割り当てています
MetroCluster ノードにディスクが正しく割り当てられていない場合、または構成で DS460C ディスクシェルフを使用している場合は、 MetroCluster 構成内の各ノードにシェルフ単位でディスクを割り当てる必要があります。構成内の各ノードのローカルディスクプールとリモートディスクプールでディスク数が同じになるように設定します。
ストレージコントローラがメンテナンスモードになっている必要があります。
構成に DS460C ディスクシェルフが含まれている場合を除き、工場出荷時の状態でディスクが正しく割り当てられていればこのタスクは必要ありません。
|
|
プール 0 には、ディスクを所有するストレージシステムと同じサイトにあるディスクを割り当てます。 プール 1 には、ディスクを所有するストレージシステムに対してリモートなディスクを割り当てます。 |
構成に DS460C ディスクシェルフが含まれている場合は、それぞれの 12 ディスクドロワーについて、次のガイドラインに従ってディスクを手動で割り当てる必要があります。
ドロワーのディスク |
ノードとプール |
0 ~ 2 |
ローカルノードのプール 0 |
3-5 |
HA パートナーノードのプール 0 |
6 ~ 8 |
ローカルノードのプール 1 の DR パートナー |
9 ~ 11 |
HA パートナーのプール 1 の DR パートナー |
このディスク割り当てパターンに従うことで、ドロワーがオフラインになった場合のアグリゲートへの影響を最小限に抑えることができます。
-
システムをブートしていない場合は、メンテナンスモードでブートします。
-
最初のサイト(サイト A )にあるノードにディスクシェルフを割り当てます。
ノードと同じサイトにあるディスクシェルフはプール 0 に割り当て、パートナーサイトにあるディスクシェルフはプール 1 に割り当てます。
各プールに同じ数のシェルフを割り当てる必要があります。
-
最初のノードで、ローカルディスクシェルフをプール 0 に、リモートディスクシェルフをプール 1 に割り当てます。
「 Disk assign-shelf_local-switch-name : shelf-name .port_-p_pool_`
ストレージコントローラ Controller_A_1 にシェルフが 4 台ある場合は、次のコマンドを問題に設定します。
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1
-
ローカルサイトの 2 番目のノードに対して処理を繰り返し、ローカルディスクシェルフをプール 0 に、リモートディスクシェルフをプール 1 に割り当てます。
「 Disk assign-shelf_local-switch-name : shelf-name .port_-p_pool_`
ストレージコントローラ Controller_A_2 にシェルフが 4 台ある場合は、次のコマンドを問題に設定します。
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1
-
-
2 番目のサイト(サイト B )にあるノードにディスクシェルフを割り当てます。
ノードと同じサイトにあるディスクシェルフはプール 0 に割り当て、パートナーサイトにあるディスクシェルフはプール 1 に割り当てます。
各プールに同じ数のシェルフを割り当てる必要があります。
-
リモートサイトの最初のノードで、ローカルディスクシェルフをプール 0 に、リモートディスクシェルフをプール 1 に割り当てます。
「ディスク assign -shelf_local-switch-namesshelf-name -p_pool` 」
ストレージコントローラ Controller_B_1 にシェルフが 4 台ある場合は、次のコマンドを問題します。
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1
-
リモートサイトの 2 番目のノードに対して処理を繰り返し、ローカルディスクシェルフをプール 0 に、リモートディスクシェルフをプール 1 に割り当てます。
「ディスク assign -shelf_shelf-name-p_pool_` 」
ストレージコントローラ Controller_B_2 にシェルフが 4 台ある場合は、次のコマンドを問題に実行します。
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1
-
-
シェルフの割り当てを確認します。
「 storage show shelf
-
メンテナンスモードを終了します。
「 halt 」
-
ブートメニューを表示します。
「 boot_ontap menu
-
各ノードで、オプション * 4 * を選択してすべてのディスクを初期化します。
AFF システムでディスク所有権を割り当てます
アグリゲートがミラーされた AFF システムを使用する構成で、ノードにディスク( SSD )が正しく割り当てられていない場合は、各シェルフの半分のディスクを 1 つのローカルノードに割り当て、残りの半分を対応する HA パートナーノードに割り当てる必要があります。構成内の各ノードのローカルディスクプールとリモートディスクプールでディスク数が同じになるように設定する必要があります。
ストレージコントローラがメンテナンスモードになっている必要があります。
これは、アグリゲートがミラーされていない構成、アクティブ / パッシブ構成、ローカルプールとリモートプールのディスク数が異なる構成には該当しません。
このタスクは、工場出荷時にディスクが正しく割り当てられている場合は必要ありません。
|
|
プール 0 には、ディスクを所有するストレージシステムと同じサイトにあるディスクを割り当てます。 プール 1 には、ディスクを所有するストレージシステムに対してリモートなディスクを割り当てます。 |
-
システムをブートしていない場合は、メンテナンスモードでブートします。
-
最初のサイト(サイト A )にあるノードにディスクを割り当てます。
各プールに同じ数のディスクを割り当てる必要があります。
-
最初のノードで、各シェルフの半分のディスクをプール 0 に、残りの半分を HA パートナーのプール 0 に割り当てます。
disk assign -shelf <shelf-name> -p <pool> -n <number-of-disks>ストレージコントローラ Controller_A_1 にシェルフが 4 台あり、各シェルフに SSD が 8 本ある場合は、次のコマンドを問題に設定します。
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1 -n 4
-
ローカルサイトの 2 番目のノードに対して処理を繰り返し、各シェルフの半分のディスクをプール 1 に、残りの半分を HA パートナーのプール 1 に割り当てます。
「 disk assign -disk disk-name -p pool 」という名前です
ストレージコントローラ Controller_A_1 にシェルフが 4 台あり、各シェルフに SSD が 8 本ある場合は、次のコマンドを問題に設定します。
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4
-
-
2 番目のサイト(サイト B )にあるノードにディスクを割り当てます。
各プールに同じ数のディスクを割り当てる必要があります。
-
リモートサイトの最初のノードで、各シェルフの半分のディスクをプール 0 に、残りの半分を HA パートナーのプール 0 に割り当てます。
「 disk assign -disk disk-name-p_pool_` 」
ストレージコントローラ Controller_B_1 にシェルフが 4 台あり、各シェルフに SSD が 8 本ある場合は、次のコマンドを問題で実行します。
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1 -n 4
-
リモートサイトの 2 番目のノードに対して処理を繰り返し、各シェルフの半分のディスクをプール 1 に、残りの半分を HA パートナーのプール 1 に割り当てます。
「 disk assign -disk disk-name-p_pool_` 」
ストレージコントローラ Controller_B_2 にシェルフが 4 台あり、各シェルフに SSD が 8 本ある場合は、次のコマンドを問題に設定します。
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1 -n 4
-
-
ディスクの割り当てを確認します。
「 storage show disk 」を参照してください
-
メンテナンスモードを終了します。
「 halt 」
-
ブートメニューを表示します。
「 boot_ontap menu
-
各ノードで、オプション * 4 * を選択してすべてのディスクを初期化します。
保守モードでの 2 ノード構成のディスク割り当ての検証
システムを ONTAP で完全にブートする前に、システムをメンテナンスモードでブートして、ノードのディスク割り当てを確認することもできます。ディスクは、両方のサイトが独自のディスクシェルフを所有してデータを提供し、各ノードおよび各プールのミラーディスク数が等しい、完全に対称な構成を形成するように割り当てられている必要があります。
システムをメンテナンスモードにする必要があります。
新しい MetroCluster システムの場合、出荷前にディスク割り当てが完了しています。
次の表に、 MetroCluster 構成のプール割り当ての例を示します。ディスクはシェルフ単位でプールに割り当てられます。
ディスクシェルフ(名前) |
サイト |
所属ノード |
割り当てプール |
ディスクシェルフ 1 ( shelf_A_1_1 ) |
サイト A |
ノード A1 |
プール 0 |
ディスクシェルフ 2 ( shelf_A_1_3 ) |
|||
ディスクシェルフ 3 ( shelf_B_1_1 ) |
ノード B1 |
プール 1. |
|
ディスクシェルフ 4 ( shelf_B_1_3 ) |
|||
ディスクシェルフ 9 ( shelf_B_1_2 ) |
サイト B |
ノード B1 |
プール 0 |
ディスクシェルフ 10 ( shelf_B_1_4 ) |
|||
ディスクシェルフ 11 ( shelf_A_1_2 ) |
ノード A1 |
プール 1. |
|
ディスクシェルフ 12 ( shelf_A_1_4 ) |
構成に DS460C ディスクシェルフが含まれている場合は、それぞれの 12 ディスクドロワーについて、次のガイドラインに従ってディスクを手動で割り当てる必要があります。
ドロワーのディスク |
ノードとプール |
1 ~ 6 |
ローカルノードのプール 0 |
7-12 |
DR パートナーのプール 1 |
このディスク割り当てパターンに従うことで、ドロワーがオフラインになった場合のアグリゲートへの影響を最小限に抑えることができます。
-
工場出荷状態のシステムの場合は、シェルフの割り当てを確認します。
「 Disk show – v 」のように表示されます
-
必要に応じて、 disk assign コマンドを使用すると、接続されているディスクシェルフ上のディスクを適切なプールに明示的に割り当てることができます。
ノードと同じサイトにあるディスクシェルフはプール 0 に割り当て、パートナーサイトにあるディスクシェルフはプール 1 に割り当てます。各プールに同じ数のシェルフを割り当てる必要があります。
-
システムをブートしていない場合は、メンテナンスモードでブートします。
-
サイト A のノードで、ローカルディスクシェルフをプール 0 に、リモートディスクシェルフをプール 1 に割り当てます。
「 disk assign -shelf_disk_shelf_name_-p_pool_` 」のようになります
ストレージコントローラ node_A_1 にシェルフが 4 台ある場合は、次のコマンドを問題できます。
*> disk assign -shelf shelf_A_1_1 -p 0 *> disk assign -shelf shelf_A_1_3 -p 0 *> disk assign -shelf shelf_A_1_2 -p 1 *> disk assign -shelf shelf_A_1_4 -p 1
-
リモートサイト(サイト B )のノードで、ローカルディスクシェルフをプール 0 に、リモートディスクシェルフをプール 1 に割り当てます。
「 disk assign -shelf_disk_shelf_name_-p_pool_` 」のようになります
ストレージコントローラ node_B_1 にシェルフが 4 台ある場合は、次のコマンドを問題に設定します。
*> disk assign -shelf shelf_B_1_2 -p 0 *> disk assign -shelf shelf_B_1_4 -p 0 *> disk assign -shelf shelf_B_1_1 -p 1 *> disk assign -shelf shelf_B_1_3 -p 1
-
各ディスクのディスクシェルフ ID とベイを表示します。
「 Disk show – v 」のように表示されます
-
ONTAP をセットアップしています
各コントローラモジュールに ONTAP をセットアップする必要があります。
新しいコントローラをネットブートする必要がある場合は、を参照してください "新しいコントローラモジュールのネットブート" MetroCluster アップグレード、移行、および拡張ガイドの各ガイドを参照してください。
2 ノード MetroCluster 構成での ONTAP のセットアップ
2 ノード MetroCluster 構成では、各クラスタでノードをブートし、クラスタセットアップウィザードを終了し、 cluster setup コマンドを使用してシングルノードクラスタとしてノードを構成する必要があります。
サービスプロセッサが設定されていないことを確認してください。
このタスクは、ネットアップの標準のストレージを使用した 2 ノード MetroCluster 構成が対象です。
このタスクは、 MetroCluster 構成の両方のクラスタで実行する必要があります。
ONTAP の設定の詳細については、を参照してください "ONTAP をセットアップする"。
-
最初のノードの電源をオンにします。
この手順はディザスタリカバリ( DR )サイトのノードでも実行する必要があります。 ノードがブートし、コンソールでクラスタセットアップウィザードが起動されて、 AutoSupport が自動的に有効になることを示すメッセージが表示されます。
::> Welcome to the cluster setup wizard. You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the cluster setup wizard. Any changes you made before quitting will be saved. You can return to cluster setup at any time by typing "cluster setup". To accept a default or omit a question, do not enter a value. This system will send event messages and periodic reports to NetApp Technical Support. To disable this feature, enter autosupport modify -support disable within 24 hours. Enabling AutoSupport can significantly speed problem determination and resolution, should a problem occur on your system. For further information on AutoSupport, see: http://support.netapp.com/autosupport/ Type yes to confirm and continue {yes}: yes Enter the node management interface port [e0M]: Enter the node management interface IP address [10.101.01.01]: Enter the node management interface netmask [101.010.101.0]: Enter the node management interface default gateway [10.101.01.0]: Do you want to create a new cluster or join an existing cluster? {create, join}: -
新しいクラスタを作成します。
「 create 」
-
ノードをシングルノードクラスタとして使用するかどうかを選択します。
Do you intend for this node to be used as a single node cluster? {yes, no} [yes]: -
Enter キーを押してシステムのデフォルト値をそのまま使用するか 'no' と入力してから Enter キーを押して ' 独自の値を入力します
-
プロンプトに従って * Cluster Setup * ウィザードを完了し、 Enter キーを押してデフォルト値をそのまま使用するか、独自の値を入力して Enter キーを押します。
デフォルト値は、プラットフォームとネットワークの構成に基づいて自動的に決定されます。
-
クラスタセットアップ * ウィザードが完了したら、次のコマンドを入力して、クラスタがアクティブで、最初のノードが正常に機能していることを確認します
「 cluster show 」を参照してください
次の例は、第 1 ノードが含まれるクラスタ( cluster1-01 )が正常に機能しており、クラスタへの参加条件を満たしていることを示しています。
cluster1::> cluster show Node Health Eligibility --------------------- ------- ------------ cluster1-01 true true
管理 SVM やノード SVM に対する設定に変更が必要になった場合は、 cluster setup コマンドを使用してクラスタセットアップウィザードにアクセスできます。
8 ノード / 4 ノード MetroCluster 構成での ONTAP のセットアップ
各ノードをブートすると、 System Setup ツールを使用してノードおよびクラスタの基本的な設定を実行するよう求めるメッセージが表示されます。クラスタを設定したら、 ONTAP CLI に戻ってアグリゲートを作成し、 MetroCluster 構成を作成します。
MetroCluster 構成のケーブル接続を完了しておく必要があります。
このタスクは、ネットアップの標準のストレージを使用した 8 ノード / 4 ノード MetroCluster 構成が対象です。
新規で購入した MetroCluster システムは事前に設定されており、ここで説明する手順を実行する必要はありません。ただし、 AutoSupport ツールを設定する必要があります。
このタスクは、 MetroCluster 構成の両方のクラスタで実行する必要があります。
この手順では、 System Setup ツールを使用します。必要に応じて、 CLI クラスタセットアップウィザードを使用することもできます。
-
各ノードに電源が入っていない場合は、電源を投入してブートします。
システムが保守モードになっている場合は問題、 halt コマンドを使用して保守モードを終了し、次に LOADER プロンプトで次のコマンドを問題します。
「 boot_ontap 」
次のような出力が表示されます。
Welcome to node setup You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the setup wizard. Any changes you made before quitting will be saved. To accept a default or omit a question, do not enter a value. . . .
-
システムの指示に従って AutoSupport ツールを有効にします。
-
プロンプトに従ってノード管理インターフェイスを設定します。
次のようなプロンプトが表示されます。
Enter the node management interface port: [e0M]: Enter the node management interface IP address: 10.228.160.229 Enter the node management interface netmask: 225.225.252.0 Enter the node management interface default gateway: 10.228.160.1
-
ノードがハイアベイラビリティモードで設定されていることを確認します。
「 storage failover show -fields mode 」を選択します
そうでない場合は、各ノードで次のコマンドを問題処理してノードをリブートする必要があります。
「 storage failover modify -mode ha -node localhost 」を参照してください
このコマンドを実行するとハイアベイラビリティモードが設定されますが、ストレージフェイルオーバーは有効になりません。ストレージフェイルオーバーは、あとで実行する MetroCluster の設定プロセスで自動的に有効になります。
-
クラスタインターコネクトとして 4 つのポートが構成されていることを確認します。
「 network port show 」のように表示されます
次の例は、 cluster_A の出力を示しています。
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ node_A_1 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 node_A_2 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
2 ノードスイッチレスクラスタ(クラスタインターコネクトスイッチのないクラスタ)を作成する場合は、 switchless-cluster ネットワークモードを有効にします。
-
advanced 権限レベルに切り替えます。
「 advanced 」の権限が必要です
advanced モードで続行するかどうかを確認するプロンプトが表示されたら、「 y 」と入力します。advanced モードのプロンプトが表示されます( * > )。
-
switchless-cluster モードを有効にします。
network options switchless-cluster modify -enabled true
-
admin 権限レベルに戻ります。
「特権管理者」
-
-
最初のブート後にシステムコンソールに表示される情報に従って、 System Setup ツールを起動します。
-
System Setup ツールを使用して各ノードを設定し、クラスタを作成します。ただし、アグリゲートは作成しないでください。
後続のタスクでミラーされたアグリゲートを作成します。
ONTAP のコマンドラインインターフェイスに戻り、後続のタスクを実行して MetroCluster の設定を完了します。
クラスタを MetroCluster 構成に設定
クラスタをピアリングし、ルートアグリゲートをミラーリングし、ミラーリングされたデータアグリゲートを作成し、コマンドを問題して MetroCluster の処理を実装する必要があります。
を実行する前に metrocluster configure、HAモードおよびDRミラーリングが有効になっていないため、この想定動作に関連するエラーメッセージが表示される場合があります。HAモードとDRミラーリングは、あとでコマンドを実行するときに有効にします metrocluster configure をクリックして構成を実装してください。
クラスタをピアリング
MetroCluster 構成内のクラスタが相互に通信し、 MetroCluster ディザスタリカバリに不可欠なデータミラーリングを実行できるようにするために、クラスタ間にはピア関係が必要です。
クラスタ間 LIF を設定しています
MetroCluster パートナークラスタ間の通信に使用するポートにクラスタ間 LIF を作成する必要があります。専用のポートを使用することも、データトラフィック用を兼ねたポートを使用することもできます。
専用ポートでのクラスタ間 LIF の設定
専用ポートにクラスタ間 LIF を設定できます。通常は、レプリケーショントラフィックに使用できる帯域幅が増加します。
-
クラスタ内のポートの一覧を表示します。
「 network port show 」のように表示されます
コマンド構文全体については、マニュアルページを参照してください。
次の例は、「 cluster01 」内のネットワークポートを示しています。
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
クラスタ間通信専用に使用可能なポートを特定します。
network interface show -fields home-port 、 curr -port
コマンド構文全体については、マニュアルページを参照してください。
次の例は、ポート e0e とポート e0f に LIF が割り当てられていないことを示しています。
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
専用ポートのフェイルオーバーグループを作成します。
「 network interface failover-groups create -vserver_system_svm 」 -failover-group_failover_group_ -targets_physical_or_logical_ports_`
次の例は、ポート「 e0e 」と「 e0f 」を、システム「 SVMcluster01 」上のフェイルオーバーグループ intercluster01 に割り当てます。
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
フェイルオーバーグループが作成されたことを確認します。
「 network interface failover-groups show 」と表示されます
コマンド構文全体については、マニュアルページを参照してください。
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
システム SVM にクラスタ間 LIF を作成して、フェイルオーバーグループに割り当てます。
ONTAP 9.6 以降「 network interface create -vserver system_svm _ -lif_lif_name_service-policy default -intercluster -home-node _-home-port _ -port_IP_address _port_ip-netmask netmask _ -failover-group _` 」のようになります
ONTAP 9.5 以前「 network interface create -vserver_system_SVM_lif_lif_name — ロール intercluster -home-node node_name のクラスタ間ホームポートポート _port-address port_ip-netmask netmask_—failover-group_failover_group_name 」
コマンド構文全体については、マニュアルページを参照してください。
次の例は、フェイルオーバーグループ「 intercluster01 」にクラスタ間 LIF 「 cluster01_icl01 」と「 cluster01_icl02 」を作成します。
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
クラスタ間 LIF が作成されたことを確認します。
ONTAP 9.6 以降次のコマンドを実行します。
network interface show -service-policy default-interclusterONTAP 9.5 以前次のコマンドを実行します。
network interface show -role interclusterコマンド構文全体については、マニュアルページを参照してください。
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0f true -
クラスタ間 LIF が冗長構成になっていることを確認します。
ONTAP 9.6 以降次のコマンドを実行します。
network interface show -service-policy default-intercluster -failoverONTAP 9.5 以前次のコマンドを実行します。
network interface show -role intercluster -failoverコマンド構文全体については、マニュアルページを参照してください。
次の例は、 SVM 「 e0e 」ポート上のクラスタ間 LIF 「 cluster01_icl01 」と「 cluster01_icl02 」が「 e0f 」ポートにフェイルオーバーされることを示しています。
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
専用のポートを使用することが適切なクラスタ間ネットワーク解決策であるかどうかを判断するには、 LAN のタイプ、利用可能な WAN 帯域幅、レプリケーション間隔、変更率、ポート数などの設定や要件を考慮する必要があります。
共有データポートでのクラスタ間 LIF の設定
データネットワークと共有するポートにクラスタ間 LIF を設定できます。これにより、クラスタ間ネットワークに必要なポート数を減らすことができます。
-
クラスタ内のポートの一覧を表示します。
「 network port show 」のように表示されます
コマンド構文全体については、マニュアルページを参照してください。
次の例は、 cluster01 内のネットワークポートを示しています。
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
システム SVM にクラスタ間 LIF を作成します。
ONTAP 9.6 以降次のコマンドを実行します。
network interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmaskONTAP 9.5 以前次のコマンドを実行します。
network interface create -vserver system_SVM -lif LIF_name -role intercluster -home-node node -home-port port -address port_IP -netmask netmaskコマンド構文全体については、マニュアルページを参照してください。次の例は、クラスタ間 LIF cluster01_icl01 と cluster01_icl02 を作成します。
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
クラスタ間 LIF が作成されたことを確認します。
ONTAP 9.6 以降次のコマンドを実行します。
network interface show -service-policy default-interclusterONTAP 9.5 以前次のコマンドを実行します。
network interface show -role interclusterコマンド構文全体については、マニュアルページを参照してください。
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
クラスタ間 LIF が冗長構成になっていることを確認します。
ONTAP 9.6 以降次のコマンドを実行します。
network interface show –service-policy default-intercluster -failoverONTAP 9.5 以前次のコマンドを実行します。
network interface show -role intercluster -failoverコマンド構文全体については、マニュアルページを参照してください。
次の例は、「 e0c 」ポート上のクラスタ間 LIF 「 cluster01_icl01 」と「 cluster01_icl02 」が「 e0d 」ポートにフェイルオーバーされることを示しています。
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-02:e0c, cluster01-02:e0d
クラスタピア関係を作成
MetroCluster クラスタ間にクラスタピア関係を作成する必要があります。
cluster peer create コマンドを使用すると、ローカルクラスタとリモートクラスタ間にピア関係を作成できます。ピア関係が作成されたら ' リモート・クラスタ上で cluster peer create を実行して ' ローカル・クラスタに対してピア関係を認証できます
-
ピア関係にあるクラスタ内の各ノードでクラスタ間 LIF を作成しておく必要があります。
-
クラスタで ONTAP 9.3 以降が実行されている必要があります。
-
デスティネーションクラスタで、ソースクラスタとのピア関係を作成します。
cluster peer create -generate-passphrase -offer-expiration_mm/dd/YYYY HH : MM : SS|1…7days | 1…168hours_-peer-addrs_peer_lif_ips_-ipspace_ips_`
「 -generate-passphrase 」と「 -peer-addrs 」の両方を指定した場合、生成されたパスワードを使用できるのは、「 -peer-addrs 」にクラスタ間 LIF が指定されているクラスタだけです。
カスタム IPspace を使用しない場合は、 -ipspace オプションを無視してかまいません。コマンド構文全体については、マニュアルページを参照してください。
次の例は、リモートクラスタを指定せずにクラスタピア関係を作成します。
cluster02::> cluster peer create -generate-passphrase -offer-expiration 2days Passphrase: UCa+6lRVICXeL/gq1WrK7ShR Expiration Time: 6/7/2017 08:16:10 EST Initial Allowed Vserver Peers: - Intercluster LIF IP: 192.140.112.101 Peer Cluster Name: Clus_7ShR (temporary generated) Warning: make a note of the passphrase - it cannot be displayed again. -
ソースクラスタで、ソースクラスタをデスティネーションクラスタに対して認証します。
'cluster peer create -peer-addrs peer_lif_ips-ipspace ips'
コマンド構文全体については、マニュアルページを参照してください。
次の例は、クラスタ間 LIF の IP アドレス「 192.140.112.101 」および「 192.140.112.102 」でローカルクラスタをリモートクラスタに対して認証します。
cluster01::> cluster peer create -peer-addrs 192.140.112.101,192.140.112.102 Notice: Use a generated passphrase or choose a passphrase of 8 or more characters. To ensure the authenticity of the peering relationship, use a phrase or sequence of characters that would be hard to guess. Enter the passphrase: Confirm the passphrase: Clusters cluster02 and cluster01 are peered.プロンプトが表示されたら、ピア関係のパスフレーズを入力します。
-
クラスタピア関係が作成されたことを確認します。
「 cluster peer show -instance 」のように表示されます
cluster01::> cluster peer show -instance Peer Cluster Name: cluster02 Remote Intercluster Addresses: 192.140.112.101, 192.140.112.102 Availability of the Remote Cluster: Available Remote Cluster Name: cluster2 Active IP Addresses: 192.140.112.101, 192.140.112.102 Cluster Serial Number: 1-80-123456 Address Family of Relationship: ipv4 Authentication Status Administrative: no-authentication Authentication Status Operational: absent Last Update Time: 02/05 21:05:41 IPspace for the Relationship: Default -
ピア関係にあるノードの接続状態とステータスを確認します。
cluster peer health show
cluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
クラスタピア関係の作成( ONTAP 9.2 以前)
「 cluster peer create 」コマンドを使用して、ローカルクラスタとリモートクラスタ間のピア関係の要求を開始できます。ピア関係がローカルクラスタによって要求された後 ' リモートクラスタ上で cluster peer create を実行して ' 関係を受け入れることができます
-
ピア関係にあるクラスタ内の各ノードでクラスタ間 LIF を作成しておく必要があります。
-
クラスタ管理者は、各クラスタが他のクラスタに対して自身を認証する際に使用するパスフレーズに同意しておく必要があります。
-
データ保護のデスティネーションクラスタで、データ保護のソースクラスタとのピア関係を作成します。
'cluster peer create -peer-addrs_peer_lif_ips_-ipspace_`
カスタム IPspace を使用しない場合は、 -ipspace オプションを無視してかまいません。コマンド構文全体については、マニュアルページを参照してください。
次の例は、クラスタ間 LIF の IP アドレス「 192.168.2.201 」および「 192.168.2.202 」で、リモートクラスタとのクラスタピア関係を作成します。
cluster02::> cluster peer create -peer-addrs 192.168.2.201,192.168.2.202 Enter the passphrase: Please enter the passphrase again:
プロンプトが表示されたら、ピア関係のパスフレーズを入力します。
-
データ保護のソースクラスタで、ソースクラスタをデスティネーションクラスタに対して認証します。
'cluster peer create -peer-addrs_peer_lif_ips_-ipspace_`
コマンド構文全体については、マニュアルページを参照してください。
次の例は、クラスタ間 LIF の IP アドレス「 192.140.112.203 」および「 192.140.112.204 」でローカルクラスタをリモートクラスタに対して認証します。
cluster01::> cluster peer create -peer-addrs 192.168.2.203,192.168.2.204 Please confirm the passphrase: Please confirm the passphrase again:
プロンプトが表示されたら、ピア関係のパスフレーズを入力します。
-
クラスタピア関係が作成されたことを確認します。
cluster peer show – instance
コマンド構文全体については、マニュアルページを参照してください。
cluster01::> cluster peer show –instance Peer Cluster Name: cluster01 Remote Intercluster Addresses: 192.168.2.201,192.168.2.202 Availability: Available Remote Cluster Name: cluster02 Active IP Addresses: 192.168.2.201,192.168.2.202 Cluster Serial Number: 1-80-000013
-
ピア関係にあるノードの接続状態とステータスを確認します。
cluster peer health show
コマンド構文全体については、マニュアルページを参照してください。
cluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
ルートアグリゲートをミラーリング
データ保護を提供するには、ルートアグリゲートをミラーする必要があります。
デフォルトでは、ルートアグリゲートは RAID-DP タイプのアグリゲートとして作成されます。ルートアグリゲートのタイプは RAID-DP から RAID4 に変更することができます。次のコマンドは、ルートアグリゲートを RAID4 タイプのアグリゲートに変更します。
storage aggregate modify –aggregate aggr_name -raidtype raid4
|
|
ADP 以外のシステムでは、ミラーリングの実行前後に、アグリゲートの RAID タイプをデフォルトの RAID-DP から RAID4 に変更できます。 |
-
ルートアグリゲートをミラーします。
「 storage aggregate mirror aggr_name 」のようになります
次のコマンドでは、 controller_A_1 のルートアグリゲートがミラーされます。
controller_A_1::> storage aggregate mirror aggr0_controller_A_1
これによりアグリゲートがミラーされるため、ローカルのプレックスとリモートのプレックスがリモートの MetroCluster サイトに配置されたアグリゲートが作成されます。
-
MetroCluster 構成の各ノードについて、同じ手順を繰り返します。
各ノードでミラーされたデータアグリゲートを作成します
DR グループの各ノードに、ミラーされたデータアグリゲートを 1 つ作成する必要があります。
-
新しいアグリゲートで使用するドライブを把握しておく必要があります。
-
複数のドライブタイプを含むシステム(異機種混在ストレージ)の場合は、正しいドライブタイプが選択されるようにする方法を確認しておく必要があります。
-
ドライブは特定のノードによって所有されます。アグリゲートを作成する場合、アグリゲート内のすべてのドライブは同じノードによって所有される必要があります。そのノードが、作成するアグリゲートのホームノードになります。
-
アグリゲート名は、 MetroCluster 構成を計画する際に決定した命名規則に従う必要があります。を参照してください "ディスクおよびアグリゲートの管理"。
-
アグリゲート名は、MetroClusterサイト全体で一意である必要があります。つまり、サイト A とサイト B に同じ名前を持つ 2 つの異なるデータ アグリゲートを持つことはできません。
-
使用可能なスペアのリストを表示します。
「 storage disk show -spare -owner node_name 」という名前になります
-
storage aggregate create -mirror true コマンドを使用して、アグリゲートを作成します。
クラスタ管理インターフェイスでクラスタにログインした場合、クラスタ内の任意のノードにアグリゲートを作成できます。アグリゲートを特定のノード上に作成するには、「 -node 」パラメータを使用するか、そのノードが所有するドライブを指定します。
次のオプションを指定できます。
-
アグリゲートのホームノード(通常運用時にアグリゲートを所有するノード)
-
アグリゲートに追加するドライブのリスト
-
追加するドライブ数
最小サポート構成では、使用可能なドライブ数が制限されていますが、 3 つのディスク RAID-DP アグリゲートを作成できるようにするには、「 force-small-aggregate 」オプションを使用する必要があります。 -
アグリゲートに使用するチェックサム形式
-
使用するドライブのタイプ
-
使用するドライブのサイズ
-
使用するドライブの速度
-
アグリゲート上の RAID グループの RAID タイプ
-
RAID グループに含めることができるドライブの最大数
-
RPM の異なるドライブが許可されるかどうか
これらのオプションの詳細については 'storage aggregate create のマニュアルページを参照してください
次のコマンドでは、 10 本のディスクを含むミラーアグリゲートが作成されます。
cluster_A::> storage aggregate create aggr1_node_A_1 -diskcount 10 -node node_A_1 -mirror true [Job 15] Job is queued: Create aggr1_node_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
新しいアグリゲートの RAID グループとドライブを確認します。
「 storage aggregate show-status -aggregate _aggregate-name _ 」を参照してください
ミラーされていないデータアグリゲートの作成
MetroCluster 構成が提供する冗長なミラーリングを必要としないデータについては、必要に応じてミラーされていないデータアグリゲートを作成できます。
-
新しいアグリゲートで使用されるドライブを把握していることを確認します。
-
複数のドライブタイプを含むシステム(異機種混在ストレージ)の場合は、正しいドライブタイプが選択されていることを確認する方法を理解しておく必要があります。

|
MetroCluster FC 構成では、ミラーされていないアグリゲートがスイッチオーバー後にオンラインになるのは、アグリゲート内のリモートディスクにアクセスできる場合のみです。ISL で障害が発生すると、ミラーされていないリモートディスク内のデータにローカルノードがアクセスできなくなる可能性があります。アグリゲートに障害が発生すると、ローカルノードがリブートされる場合があります。 |
-
ドライブは特定のノードによって所有されます。アグリゲートを作成する場合、アグリゲート内のすべてのドライブは同じノードによって所有される必要があります。そのノードが、作成するアグリゲートのホームノードになります。
|
|
ミラーされていないアグリゲートは、そのアグリゲートを所有するノードに対してローカルでなければなりません。 |
-
アグリゲート名は、 MetroCluster 構成を計画する際に決定した命名規則に従う必要があります。
-
_Disks and aggregates management _ アグリゲートのミラーリングの詳細については、を参照してください。
-
使用可能なスペアのリストを表示します。
「 storage disk show -spare -owner_node_name _ 」というように入力します
-
アグリゲートを作成します。
「 storage aggregate create 」
クラスタ管理インターフェイスでクラスタにログインした場合、クラスタ内の任意のノードにアグリゲートを作成できます。アグリゲートが特定のノード上に作成されていることを確認するには、「 -node 」パラメータを使用するか、そのノードが所有するドライブを指定します。
次のオプションを指定できます。
-
アグリゲートのホームノード(通常運用時にアグリゲートを所有するノード)
-
アグリゲートに追加するドライブのリスト
-
追加するドライブ数
-
アグリゲートに使用するチェックサム形式
-
使用するドライブのタイプ
-
使用するドライブのサイズ
-
使用するドライブの速度
-
アグリゲート上の RAID グループの RAID タイプ
-
RAID グループに含めることができるドライブの最大数
-
RPM の異なるドライブが許可されるかどうか
これらのオプションの詳細については、 storage aggregate create のマニュアルページを参照してください。
次のコマンドでは、 10 本のディスクを含むミラーされていないアグリゲートが作成さ
controller_A_1::> storage aggregate create aggr1_controller_A_1 -diskcount 10 -node controller_A_1 [Job 15] Job is queued: Create aggr1_controller_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
新しいアグリゲートの RAID グループとドライブを確認します。
「 storage aggregate show-status -aggregate _aggregate-name _ 」を参照してください
MetroCluster 構成の実装
MetroCluster 構成でデータ保護を開始するに MetroCluster は 'data configure コマンドを実行する必要があります
-
ルート以外のミラーされたデータアグリゲートが各クラスタに少なくとも 2 つ必要です。
その他のデータアグリゲートはミラーされていてもいなくてもかまいません。
これは「 storage aggregate show 」コマンドで確認できます。
ミラーされた単一のデータアグリゲートを使用する場合は、を参照してください 手順 1. 手順については、を参照し -
コントローラおよびシャーシの ha-config の状態が「 mcc 」である必要があります。
MetroCluster 構成を有効にするには ' 任意のノードで MetroCluster configure コマンドを 1 回実行します問題サイトごとまたはノードごとにコマンドを問題で実行する必要はありません。また、問題するノードまたはサイトはどれでもかまいません。
MetroCluster configure コマンドを実行すると '2 つのクラスタそれぞれのシステム ID が最も小さい 2 つのノードが 'DR (災害復旧)パートナーとして自動的にペア設定されます4 ノード MetroCluster 構成の場合は、 DR パートナーのペアは 2 組になります。2 つ目の DR ペアは、システム ID が大きい 2 つのノードで作成されます。
|
|
コマンドMetroCluster configure'を実行する前に'Onboard Key Manager(OKM;オンボードキーマネージャ)または外部キー管理を構成しないでください |
-
MetroCluster 構成の内容
操作
複数のデータアグリゲート
いずれかのノードのプロンプトで、 MetroCluster を設定します。
MetroCluster configure node-name
ミラーされた 1 つのデータアグリゲート
-
いずれかのノードのプロンプトで、 advanced 権限レベルに切り替えます。
「 advanced 」の権限が必要です
advanced モードで続行するかどうかを尋ねられたら、「 y 」と入力して応答する必要があります。 advanced モードのプロンプト( * > )が表示されます。
-
MetroCluster に -allow-with-one-aggregate true パラメータを設定します。
「 MetroCluster configure -allow-with-one-aggregate true_node-name_` 」
-
admin 権限レベルに戻ります。
「特権管理者」
複数のデータアグリゲートを使用することを推奨します。最初の DR グループにアグリゲートが 1 つしかなく、 1 つのアグリゲートを含む DR グループを追加する場合は、メタデータボリュームを単一のデータアグリゲートから移動する必要があります。この手順の詳細については、を参照してください "MetroCluster 構成でのメタデータボリュームの移動"。 次のコマンドは、 controller_A_1 を含む DR グループ内のすべてのノードの MetroCluster 構成を有効にします。
cluster_A::*> metrocluster configure -node-name controller_A_1 [Job 121] Job succeeded: Configure is successful.
-
-
サイト A のネットワークステータスを確認します。
「 network port show 」のように表示されます
次の例は、 4 ノード MetroCluster 構成でのネットワークポートの用途を示しています。
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- --------- ---------------- ----- ------- ------------ controller_A_1 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 controller_A_2 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
MetroCluster 構成の両方のサイトから MetroCluster 構成を確認します。
-
サイト A から構成を確認します。
「 MetroCluster show 」
cluster_A::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
サイト B から構成を確認します。
「 MetroCluster show 」
cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
ONTAP ソフトウェアでのフレームのインオーダー配信またはアウトオブオーダー配信の設定
Fibre Channel ( FC )スイッチの設定に応じて、フレームの In-Order Delivery ( IOD ;インオーダー配信)または Out-of-Order Delivery ( OOD ;アウトオブオーダー配信)のいずれかを設定する必要があります。
FC スイッチが IOD に設定されている場合は、 ONTAP ソフトウェアを IOD に設定する必要があります。同様に、 FC スイッチが OOD に設定されている場合は、 ONTAP を OOD に設定する必要があります。
|
|
設定を変更するには、コントローラをリブートする必要があります。 |
-
ONTAP でのフレームの処理方法として IOD または OOD のいずれかを設定します。
-
ONTAP では、デフォルトではフレームの IOD が有効になっています。設定の詳細を確認するには、次の手順を
-
advanced モードに切り替えます。
「高度」
-
設定を確認します。
MetroCluster インターコネクト・アダプタ・ショー
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
-
フレームの OOD を設定するには、各ノードで次の手順を実行する必要があります。
-
advanced モードに切り替えます。
「高度」
-
MetroCluster 構成の設定を確認します。
MetroCluster インターコネクト・アダプタ・ショー
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
ノード「
m cc4-b1' 」およびノード「 `m cc4-b0」で OOD を有効にします。MetroCluster 相互接続アダプタ modify -Node_node_name --is-ood-enabled true
mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b1 -is-ood-enabled true mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b2 -is-ood-enabled true
-
両方向でハイアベイラビリティ(HA)テイクオーバーを実行してコントローラをリブートします。
-
設定を確認します。
MetroCluster インターコネクト・アダプタ・ショー
-
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up true 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up true 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up true 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up true 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
MetroCluster FC構成でのSNMPv3の設定
認証プロトコルとプライバシープロトコルは、スイッチと ONTAP システムで同じである必要があります。
ONTAPは現在、プライバシー保護(暗号化)にはAES-128、認証にはSHA-256をサポートしています。
|
|
|
-
コントローラのプロンプトで各スイッチの SNMP ユーザを作成します。
'securitylogin create (セキュリティログインの作成
Controller_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10.10.10.10
-
サイトで必要に応じて、次のプロンプトに応答します。
EngineID の場合は、ENTER を押してデフォルト値を割り当てます。 Enter the authoritative entity's EngineID [remote EngineID]: Which authentication protocol do you want to choose (none, md5, sha, sha2-256) [none]: sha Enter the authentication protocol password (minimum 8 characters long): Enter the authentication protocol password again: Which privacy protocol do you want to choose (none, des, aes128) [none]: aes128 Enter privacy protocol password (minimum 8 characters long): Enter privacy protocol password again:
同じユーザ名を IP アドレスが異なる別のスイッチに追加できます。 -
残りのスイッチの SNMP ユーザを作成します。
次の例は、 IP アドレス 10.10.10.11 のスイッチのユーザ名を作成する方法を示しています。
Controller_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10. 10.10.11
-
ログインエントリがスイッチごとに 1 つずつあることを確認します。
「 securitylogin show 」を参照してください
Controller_A_1::> security login show -user-or-group-name snmpv3user -fields remote-switch-ipaddress vserver user-or-group-name application authentication-method remote-switch-ipaddress ------------ ------------------ ----------- --------------------- ----------------------- node_A_1 SVM 1 snmpv3user snmp usm 10.10.10.10 node_A_1 SVM 2 snmpv3user snmp usm 10.10.10.11 node_A_1 SVM 3 snmpv3user snmp usm 10.10.10.12 node_A_1 SVM 4 snmpv3user snmp usm 10.10.10.13 4 entries were displayed.
-
スイッチのプロンプトで SNMPv3 を設定します。
Brocadeスイッチ(FOS 9.x)snmpconfig --add snmpv3 -index <index> -user <user_name> -groupname <rw/ro> -auth_proto <auth_protocol> -auth_passwd <auth_password> -priv_proto <priv_protocol> -priv_passwd <priv_password>Brocadeスイッチ (FOS 8.x 以前)「 mpconfig — set snmpv3 」
この例では、読み取り専用ユーザーを構成する方法を示します。必要に応じて RW ユーザーを調整できます。 RO アクセスが必要な場合は、「User (ro):」の後に「snmpv3user」を指定します。
Switch-A1:admin> snmpconfig --set snmpv3 SNMP Informs Enabled (true, t, false, f): [false] true SNMPv3 user configuration(snmp user not configured in FOS user database will have physical AD and admin role as the default): User (rw): [snmpadmin1] Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [3] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [2] Engine ID: [00:00:00:00:00:00:00:00:00] User (ro): [snmpuser2] snmpv3user Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [2] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [3]
Cisco スイッチsnmp-server user <user_name> auth [md5/sha/sha-256] <auth_password> priv (aes-128) <priv_password>
また、未使用のアカウントにパスワードを設定して保護し、 ONTAP リリースで最適な暗号化機能を使用する必要があります。 -
必要に応じて、残りのスイッチユーザに暗号化とパスワードを設定します。
健常性監視用の MetroCluster コンポーネントの設定
MetroCluster 構成のコンポーネントを監視するには、いくつかの特別な設定手順を実行する必要があります。
|
|
セキュリティを強化するために、NetAppでは、スイッチのヘルスを監視するようにSNMPv2またはSNMPv3を設定することを推奨します。 |
これらのタスクは、 FC-to-SAS ブリッジを使用するシステムにのみ適用されます。
Fabric OS 9.0.1以降、SNMPv2はBrocadeスイッチのヘルスモニタリングではサポートされていません。代わりにSNMPv3を使用する必要があります。SNMPv3を使用している場合は、次のセクションに進む前にONTAPでSNMPv3を設定する必要があります。詳細については、MetroCluster FC構成でのSNMPv3の設定を参照してください。
|
|
|
NetAppでは、MetroCluster FC構成のコンポーネントを監視するための次のツールのみがサポートされます。
-
Brocade Network Advisor ( BNA )
-
Brocade SANnav
-
Active IQ Config Advisor
-
NetAppヘルスモニタリング(ONTAP)
-
MetroClusterデータコレクタ(MC_DC)
健常性監視用の MetroCluster FC スイッチの設定
ファブリック接続 MetroCluster 構成の FC スイッチを監視するには、いくつかの設定手順を追加で実行する必要があります。
|
|
ONTAP 9.8以降では storage switch、コマンドがに置き換えられ `system switch fibre-channel`ました。以降の手順ではコマンドを使用し `storage switch`ますが、ONTAP 9.8以降を実行している場合はコマンドを使用 `system switch fibre-channel`することを推奨します。
|
-
各 MetroCluster ノードに IP アドレスを指定してスイッチを追加します。
実行するコマンドは、SNMPv2とSNMPv3のどちらを使用しているかによって異なります。
SNMPv3を使用してスイッチを追加します。storage switch add -address <ip_adddress> -snmp-version SNMPv3 -snmp-community-or-username <SNMP_user_configured_on_the_switch>SNMPv2を使用してスイッチを追加します。「 storage switch add -address ipaddress 」と入力します
このコマンドは、 MetroCluster 構成の 4 つのスイッチすべてに対して繰り返す必要があります。
健常性監視では、 Brocade 7840 FC スイッチと NoISLPresent_Alert を除くすべてのアラートがサポートされます 次の例は、 IP アドレスが 10.10.10.10 のスイッチを追加するコマンドを示しています。
controller_A_1::> storage switch add -address 10.10.10.10
-
すべてのスイッチが適切に設定されたことを確認します。
「 storage switch show 」と表示されます
ポーリング間隔が 15 分であるため、すべてのデータが反映されるまで最大で 15 分かかる場合があります。
次の例は、 MetroCluster FC スイッチが設定されたことを検証するコマンドを示しています。
controller_A_1::> storage switch show Fabric Switch Name Vendor Model Switch WWN Status ---------------- --------------- ------- ------------ ---------------- ------ 1000000533a9e7a6 brcd6505-fcs40 Brocade Brocade6505 1000000533a9e7a6 OK 1000000533a9e7a6 brcd6505-fcs42 Brocade Brocade6505 1000000533d3660a OK 1000000533ed94d1 brcd6510-fcs44 Brocade Brocade6510 1000000533eda031 OK 1000000533ed94d1 brcd6510-fcs45 Brocade Brocade6510 1000000533ed94d1 OK 4 entries were displayed. controller_A_1::>
スイッチの World Wide Name ( WWN ;ワールドワイド名)が表示される場合は、 ONTAP ヘルスモニタを使用して FC スイッチに接続し、監視できます。
健常性監視用の FC-to-SAS ブリッジの設定
9.8 より前のバージョンの ONTAP を実行しているシステムでは、 MetroCluster 構成の FC-to-SAS ブリッジを監視するには、いくつかの特別な設定手順を実行する必要があります。
-
FibreBridge ブリッジでは、サードパーティ製の SNMP 監視ツールはサポートされません。
-
ONTAP 9.8 以降では、デフォルトで FC-to-SAS ブリッジがインバンド接続で監視されるため、追加の設定は必要ありません。
|
|
ONTAP 9.8 以降では 'storage bridge コマンドは 'system bridge コマンドに置き換えられました次の手順は「 storage bridge 」コマンドを示していますが、 ONTAP 9.8 以降を実行している場合は「 system bridge 」コマンドが優先されます。 |
-
ONTAP クラスタのプロンプトで、ブリッジをヘルスモニタの対象に追加します。
-
使用している ONTAP のバージョンに対応したコマンドを使用して、ブリッジを追加します。
ONTAP バージョン
コマンドを実行します
9.5 以降
「 storage bridge add -address 0.0.0.0 -managed-by in-band-name_bridge-name_`
9.4 以前
「 storage bridge add -address_bridge-ip-address_-name_bridge-name_` 」
-
ブリッジが追加され、正しく設定されていることを確認します。
「 storage bridge show 」
ポーリング間隔に応じて、すべてのデータが反映されるまで 15 分程度かかる場合があります。「 Status 」列の値が「 ok 」で、 World Wide Name ( WWN ;ワールドワイド名)などのその他の情報が表示されていれば、 ONTAP ヘルスモニタでブリッジに接続して監視できます。
次の例は、 FC-to-SAS ブリッジが設定されていることを示しています。
controller_A_1::> storage bridge show Bridge Symbolic Name Is Monitored Monitor Status Vendor Model Bridge WWN ------------------ ------------- ------------ -------------- ------ ----------------- ---------- ATTO_10.10.20.10 atto01 true ok Atto FibreBridge 7500N 20000010867038c0 ATTO_10.10.20.11 atto02 true ok Atto FibreBridge 7500N 20000010867033c0 ATTO_10.10.20.12 atto03 true ok Atto FibreBridge 7500N 20000010867030c0 ATTO_10.10.20.13 atto04 true ok Atto FibreBridge 7500N 2000001086703b80 4 entries were displayed controller_A_1::>
-
MetroCluster の設定を確認しています
MetroCluster 構成内のコンポーネントおよび関係が正しく機能していることを確認できます。
チェックは、初期設定後と、 MetroCluster 設定に変更を加えたあとに実施する必要があります。また、ネゴシエート(計画的)スイッチオーバーやスイッチバックの処理の前にも実施します。
いずれかまたは両方のクラスタに対して短時間に MetroCluster check run コマンドを 2 回発行すると ' 競合が発生し ' コマンドがすべてのデータを収集しない場合がありますそれ以降の MetroCluster check show コマンドでは ' 期待される出力は表示されません
-
構成を確認します。
「 MetroCluster check run 」のようになります
このコマンドはバックグラウンドジョブとして実行され、すぐに完了しない場合があります。
cluster_A::> metrocluster check run The operation has been started and is running in the background. Wait for it to complete and run "metrocluster check show" to view the results. To check the status of the running metrocluster check operation, use the command, "metrocluster operation history show -job-id 2245"
cluster_A::> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
最新の MetroCluster check run コマンドから ' より詳細な結果を表示します
MetroCluster check aggregate show
MetroCluster check cluster show
MetroCluster check config-replication show
MetroCluster check lif show
MetroCluster check node show
「 MetroCluster check show 」コマンドは、最新の「 MetroCluster check run 」コマンドの結果を表示します。MetroCluster check show コマンドを使用する前に ' 必ず MetroCluster check run コマンドを実行して ' 表示されている情報が最新であることを確認してください 次に、正常な 4 ノード MetroCluster 構成の MetroCluster check aggregate show コマンドの出力例を示します。
cluster_A::> metrocluster check aggregate show Last Checked On: 8/5/2014 00:42:58 Node Aggregate Check Result --------------- -------------------- --------------------- --------- controller_A_1 controller_A_1_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2 controller_A_2_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok 18 entries were displayed.次に、正常な 4 ノード MetroCluster 構成の MetroCluster check cluster show コマンドの出力例を示します。この出力は、必要に応じてネゴシエートスイッチオーバーを実行できる状態であることを示しています。
Last Checked On: 9/13/2017 20:47:04 Cluster Check Result --------------------- ------------------------------- --------- mccint-fas9000-0102 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok mccint-fas9000-0304 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok 10 entries were displayed.
Config Advisor での MetroCluster 構成エラーの確認
一般的な構成エラーの有無を確認する Config Advisor ツールをネットアップサポートサイトからダウンロードできます。
Config Advisor は、構成の検証や健常性のチェックに使用できるツールです。データ収集とシステム分析のために、セキュアなサイトにもセキュアでないサイトにも導入できます。
|
|
Config Advisor のサポートには制限があり、オンラインでしか使用できません。 |
-
Config Advisor のダウンロードページにアクセスし、ツールをダウンロードします。
-
Config Advisor を実行し、ツールの出力を確認して、問題が検出された場合は出力に表示される推奨事項に従って対処します。
ローカル HA の処理を検証しています
4 ノード MetroCluster 構成の場合、 MetroCluster 構成のローカル HA ペアの処理を検証する必要があります。2 ノード構成の場合は不要です。
2 ノード MetroCluster 構成ではローカル HA ペアは構成されないため、このタスクは適用されません。
このタスクの例では、次の標準的な命名規則を使用します。
-
cluster_A
-
controller_A_1
-
controller_A_2
-
-
cluster_B
-
controller_B_1
-
controller_B_2
-
-
cluster_A で、フェイルオーバーとギブバックを両方向で実行します。
-
ストレージフェイルオーバーが有効になっていることを確認します。
「 storage failover show 」をクリックします
両方のノードでテイクオーバーが可能であることが出力に示されます。
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed. -
controller_A_1 から controller_A_2 をテイクオーバーします。
'storage failover takeover controller_A_2
テイクオーバー処理の進捗は storage failover show-takeover コマンドを使用して監視できます。
-
テイクオーバーが完了したことを確認します。
「 storage failover show 」をクリックします
出力には、 controller_A_1 がテイクオーバー状態であること、 HA パートナーをテイクオーバーしたことが示されます。
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ----------------- controller_A_1 controller_A_2 false In takeover controller_A_2 controller_A_1 - Unknown 2 entries were displayed. -
controller_A_2 をギブバックします。
'storage failover giveback controller_A_2
「 storage failover show-giveback 」コマンドを使用すると、ギブバック処理の進捗を監視できます。
-
ストレージフェイルオーバーが通常の状態に戻ったことを確認します。
「 storage failover show 」をクリックします
両方のノードでテイクオーバーが可能であることが出力に示されます。
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed.-
ここまでの手順を繰り返して、今度は controller_A_2 から controller_A_1 をテイクオーバーします。
-
-
cluster_B に関して、上記の手順を繰り返します
スイッチオーバー、修復、スイッチバックを検証しています
MetroCluster 構成のスイッチオーバー、修復、スイッチバックの処理を検証する必要があります。
-
に記載されているネゴシエートスイッチオーバー、修復、スイッチバックの手順を使用します "災害からリカバリします"。
構成バックアップファイルを保護しています
ローカルクラスタ内のデフォルトの場所に加えて、クラスタ構成バックアップファイルをアップロードするリモート URL ( HTTP または FTP )を指定することで、クラスタ構成バックアップファイルの保護を強化できます。
-
構成バックアップファイルのリモートデスティネーションの URL を設定します。
「システム構成のバックアップ設定 MODIT_URL-of-destination_ 」
。 "CLI を使用したクラスタ管理" 追加情報が含まれています。