

障害ストレージボリュームを特定してアンマウントします
 変更を提案
変更を提案
ストレージボリュームに障害が発生したストレージノードをリカバリする場合は、障害ボリュームを特定し、アンマウントする必要があります。障害ストレージボリュームのみがリカバリ手順 で再フォーマットされることを確認する必要があります。
を使用して Grid Manager にサインインします "サポートされている Web ブラウザ"。
障害が発生したストレージボリュームはできるだけ早くリカバリする必要があります。
まず最初に、接続解除されたボリューム、アンマウントが必要なボリューム、または I/O エラーが発生しているボリュームを検出します。障害ボリュームがランダムに破損したファイルシステムを含んでいる状態で接続されている場合は、ディスクの未使用部分または未割り当て部分の破損をシステムが検出できないことがあります。

|
ディスクの追加や再接続、ノードの停止、ノードの開始、リブートなど、ボリュームをリカバリするための手動手順を実行する前に、この手順 を完了しておく必要があります。それ以外の場合は、を実行したときに reformat_storage_block_devices.rb スクリプトでファイルシステムエラーが発生し、スクリプトがハングしたり失敗したりする場合があります。
|
|
|
を実行する前に、ハードウェアを修理し、ディスクを適切に接続します reboot コマンドを実行します
|

|
障害ストレージボリュームは慎重に特定してください。この情報を使用して、再フォーマットが必要なボリュームを確認します。ボリュームが再フォーマットされると、そのボリューム上のデータは復元できません。 |
障害ストレージボリュームを正しくリカバリするには、障害ストレージボリュームのデバイス名とそのボリューム ID の両方を把握しておく必要があります。
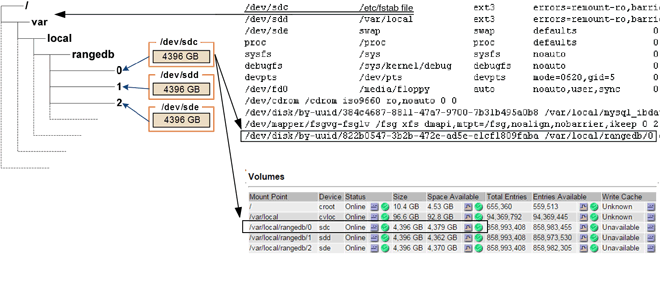
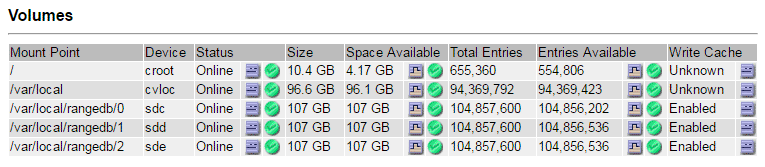
インストール時に、各ストレージデバイスにはファイルシステムの Universal Unique Identifier ( UUID )が割り当てられ、その UUID を使用してストレージノードの rangedb ディレクトリにマウントされます。ファイルシステムのUUIDとrangedbディレクトリは、に記載されています /etc/fstab ファイル。デバイス名、 rangedb ディレクトリ、およびマウントされたボリュームのサイズは、 Grid Manager に表示されます。
次の例では、deviceです /dev/sdc には4TBのボリュームがマウントされています /var/local/rangedb/0`デバイス名を使用します `/dev/disk/by-uuid/822b0547-3b2b-472e-ad5e-e1cf1809faba を参照してください /etc/fstab ファイル:
-
次の手順を実行して、障害ストレージボリュームとそのデバイス名を記録します。
-
サポート * > * ツール * > * グリッドトポロジ * を選択します。
-
サイト * > * 障害ストレージノード * > * LDR * > * Storage * > * Overview * > * Main * を選択し、アラームのあるオブジェクトストアを検索します。

-
サイト * > * failed Storage Node * > * SSM * > * Resources * > * Overview * > * Main * を選択します。前の手順で特定した各障害ストレージボリュームのマウントポイントとボリュームサイズを確認します。
オブジェクトストアには、 16 進表記の番号が付けられています。たとえば、 0000 は最初のボリューム、 000F は 16 番目のボリュームです。この例では、IDが0000のオブジェクトストアはに対応しています
/var/local/rangedb/0デバイス名がsdcで、サイズが107GBの場合。
-
-
障害が発生したストレージノードにログインします。
-
次のコマンドを入力します。
ssh admin@grid_node_IP -
に記載されているパスワードを入力します
Passwords.txtファイル。 -
次のコマンドを入力してrootに切り替えます。
su - -
に記載されているパスワードを入力します
Passwords.txtファイル。
rootとしてログインすると、プロンプトがから変わります
$終了:#。 -
-
次のスクリプトを実行して、障害ストレージボリュームをアンマウントします。
sn-unmount-volume object_store_ID。
object_store_IDは、障害ストレージボリュームのIDです。たとえば、と指定します0IDが0000のオブジェクトストアのコマンド。 -
プロンプトが表示されたら、* y *を押して、ストレージボリューム0に応じてCassandraサービスを停止します。
Cassandraサービスがすでに停止している場合は、プロンプトは表示されません。Cassandra サービスは、ボリューム 0 に対してのみ停止します。 root@Storage-180:~/var/local/tmp/storage~ # sn-unmount-volume 0 Services depending on storage volume 0 (cassandra) aren't down. Services depending on storage volume 0 must be stopped before running this script. Stop services that require storage volume 0 [y/N]? y Shutting down services that require storage volume 0. Services requiring storage volume 0 stopped. Unmounting /var/local/rangedb/0 /var/local/rangedb/0 is unmounted.
数秒後にボリュームがアンマウントされます。プロセスの各ステップを示すメッセージが表示されます。最後のメッセージは、ボリュームがアンマウントされたことを示しています。
-
ボリュームがビジー状態であるためにアンマウントに失敗した場合は、を使用して強制的にアンマウントできます
--use-umountofオプション:
を使用して強制的にアンマウントします --use-umountofオプションを指定すると、ボリュームを使用する原因 のプロセスやサービスが予期せずに動作したり、クラッシュしたりすることがあります。root@Storage-180:~ # sn-unmount-volume --use-umountof /var/local/rangedb/2 Unmounting /var/local/rangedb/2 using umountof /var/local/rangedb/2 is unmounted. Informing LDR service of changes to storage volumes