

障害が発生したストレージボリュームを識別してマウント解除する
 変更を提案
変更を提案
障害が発生したストレージ ボリュームを持つストレージ ノードをリカバリする場合は、障害が発生したボリュームを識別してマウント解除する必要があります。リカバリ手順の一環として、障害の発生したストレージ ボリュームのみが再フォーマットされていることを確認する必要があります。
グリッドマネージャにサインインするには、"サポートされているウェブブラウザ" 。
障害が発生したストレージ ボリュームをできるだけ早く回復する必要があります。
回復プロセスの最初のステップは、切断されたボリューム、アンマウントする必要があるボリューム、または I/O エラーが発生しているボリュームを検出することです。障害が発生したボリュームがまだ接続されているが、ファイル システムがランダムに破損している場合、システムはディスクの未使用部分または未割り当て部分の破損を検出しない可能性があります。

|
ディスクの追加または再接続、ノードの停止、ノードの起動、再起動など、ボリュームを回復するための手動の手順を実行する前に、この手順を完了する必要があります。それ以外の場合は、 `reformat_storage_block_devices.rb`スクリプトを実行すると、ファイル システム エラーが発生し、スクリプトがハングしたり失敗したりする可能性があります。 |
|
|
実行する前にハードウェアを修復し、ディスクを適切に接続してください。 `reboot`指示。 |

|
障害が発生したストレージ ボリュームを慎重に識別します。この情報を使用して、どのボリュームを再フォーマットする必要があるかを確認します。ボリュームを再フォーマットすると、ボリューム上のデータは回復できなくなります。 |
障害が発生したストレージ ボリュームを正しく回復するには、障害が発生したストレージ ボリュームのデバイス名とボリューム ID の両方を知っておく必要があります。
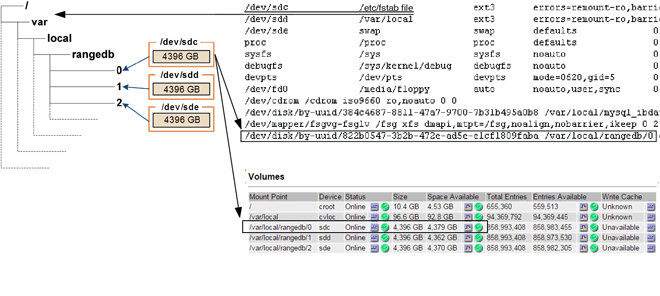
インストール時に、各ストレージ デバイスにファイル システムのユニバーサル ユニーク ID (UUID) が割り当てられ、割り当てられたファイル システム UUID を使用してストレージ ノード上の rangedb ディレクトリにマウントされます。ファイルシステムUUIDとrangedbディレクトリは、 `/etc/fstab`ファイル。デバイス名、rangedb ディレクトリ、マウントされたボリュームのサイズがグリッド マネージャーに表示されます。
次の例では、デバイス `/dev/sdc`ボリュームサイズは4TBで、マウントされている `/var/local/rangedb/0`デバイス名を使用して `/dev/disk/by-uuid/822b0547-3b2b-472e-ad5e-e1cf1809faba`の中で/`etc/fstab`ファイル:
-
障害が発生したストレージ ボリュームとそのデバイス名を記録するには、次の手順を実行します。
-
サポート > ツール > グリッド トポロジ を選択します。
-
サイト > 障害が発生したストレージ ノード > LDR > ストレージ > 概要 > メイン を選択し、アラームのあるオブジェクト ストアを探します。

-
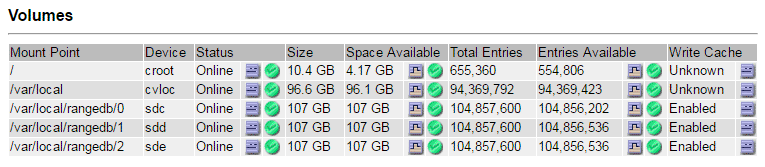
サイト > 障害が発生したストレージ ノード > SSM > リソース > 概要 > メイン を選択します。前の手順で特定された障害が発生した各ストレージ ボリュームのマウント ポイントとボリューム サイズを確認します。
オブジェクト ストアは 16 進表記で番号が付けられます。たとえば、0000 は最初のボリューム、000F は 16 番目のボリュームです。この例では、IDが0000のオブジェクトストアは、 `/var/local/rangedb/0`デバイス名は sdc、サイズは 107 GB です。
-
-
障害が発生したストレージノードにログインします。
-
次のコマンドを入力します。
ssh admin@grid_node_IP -
記載されているパスワードを入力してください `Passwords.txt`ファイル。
-
ルートに切り替えるには、次のコマンドを入力します。
su - -
記載されているパスワードを入力してください `Passwords.txt`ファイル。
ルートとしてログインすると、プロンプトは
$`に `#。 -
-
障害が発生したストレージ ボリュームをアンマウントするには、次のスクリプトを実行します。
sn-unmount-volume object_store_IDその `object_store_ID`障害が発生したストレージ ボリュームの ID です。たとえば、次のように指定します `0`ID 0000 のオブジェクト ストアのコマンドで。
-
プロンプトが表示されたら、y を押して、ストレージ ボリューム 0 に応じて Cassandra サービスを停止します。
Cassandra サービスがすでに停止されている場合は、プロンプトは表示されません。 Cassandra サービスはボリューム 0 に対してのみ停止されます。 root@Storage-180:~/var/local/tmp/storage~ # sn-unmount-volume 0 Services depending on storage volume 0 (cassandra) aren't down. Services depending on storage volume 0 must be stopped before running this script. Stop services that require storage volume 0 [y/N]? y Shutting down services that require storage volume 0. Services requiring storage volume 0 stopped. Unmounting /var/local/rangedb/0 /var/local/rangedb/0 is unmounted.
数秒後、ボリュームはアンマウントされます。プロセスの各ステップを示すメッセージが表示されます。最後のメッセージは、ボリュームがマウント解除されたことを示します。
-
ボリュームがビジー状態のためアンマウントに失敗した場合は、 `--use-umountof`オプション:
強制的にアンマウントするには `--use-umountof`このオプションを選択すると、ボリュームを使用するプロセスまたはサービスが予期しない動作をしたりクラッシュしたりする可能性があります。 root@Storage-180:~ # sn-unmount-volume --use-umountof /var/local/rangedb/2 Unmounting /var/local/rangedb/2 using umountof /var/local/rangedb/2 is unmounted. Informing LDR service of changes to storage volumes