

NetApp StorageGRIDとビッグデータ分析
 変更を提案
変更を提案
NetApp StorageGRIDのユースケース
NetApp StorageGRIDオブジェクトストレージ解決策は、拡張性、データ可用性、セキュリティ、ハイパフォーマンスを提供します。StorageGRID S3は、あらゆる規模のさまざまな業界の組織で幅広いユースケースに使用されています。典型的なシナリオをいくつか見てみましょう。
ビッグデータ分析: StorageGRID S3はデータレイクとしてよく使用されています。企業は、Apache Spark、Splunk Smartstore、Dremioなどのツールを使用して、分析用に大量の構造化データと非構造化データを保存します。
データ階層化: NetAppのお客様は、ONTAPのFabricPool機能を使用して、ハイパフォーマンスなローカル階層間でStorageGRIDにデータを自動的に移動します。階層化することで、高価なフラッシュストレージをホットデータ用に解放し、コールドデータを低コストのオブジェクトストレージでいつでも利用できる状態に維持できます。これにより、パフォーマンスとコスト削減が最大化されます。
*データのバックアップとディザスタリカバリ:*企業は、StorageGRID S3を信頼性とコスト効率に優れた解決策として使用して、重要なデータのバックアップと災害時のリカバリを実行できます。
アプリケーション用のデータストレージ: StorageGRID S3はアプリケーションのストレージバックエンドとして使用できるため、開発者はファイル、画像、ビデオ、その他の種類のデータを簡単に保存および取得できます。
コンテンツ配信: StorageGRID S3を使用すると、静的なWebサイトコンテンツ、メディアファイル、ソフトウェアダウンロードを世界中のユーザに保存して配信できます。StorageGRIDの地理的な配信とグローバルネームスペースを活用して、高速で信頼性の高いコンテンツ配信を実現できます。
データアーカイブ: StorageGRIDは、さまざまな種類のストレージを提供し、パブリックな長期低コストストレージオプションへの階層化をサポートします。コンプライアンスや履歴目的で保持する必要があるデータのアーカイブや長期保存に最適な解決策です。
オブジェクトストレージのユースケース
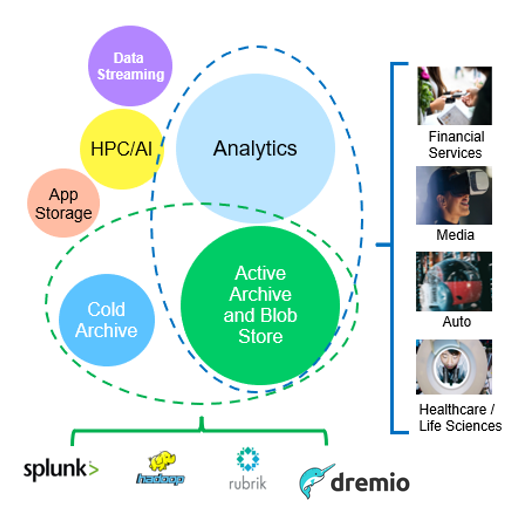
上記の中で、ビッグデータ分析は最も多くのユースケースの1つであり、その使用量は増加傾向にあります。
データレイクにStorageGRIDを選ぶ理由
-
コラボレーションの強化-業界標準のAPIアクセスによる大規模な共有マルチサイト、マルチテナンシー
-
運用コストの削減-単一の自己回復型自動スケールアウトアーキテクチャによる運用の簡易化
-
拡張性-従来のHadoopやデータウェアハウスソリューションとは異なり、StorageGRID S3オブジェクトストレージはコンピューティングやデータからストレージを切り離し、ビジネスの成長に合わせてストレージニーズを拡張できます。
-
耐久性と信頼性- StorageGRIDは99.999999999%の耐久性を提供し、保存されたデータはデータ損失に対して非常に耐性があります。また、高可用性を提供し、データへの常時アクセスを保証します。
-
セキュリティ- StorageGRIDは、暗号化、アクセス制御ポリシー、データライフサイクル管理、オブジェクトロック、S3バケットに格納されたデータを保護するバージョン管理など、さまざまなセキュリティ機能を提供します。
-
StorageGRID S3データレイク*
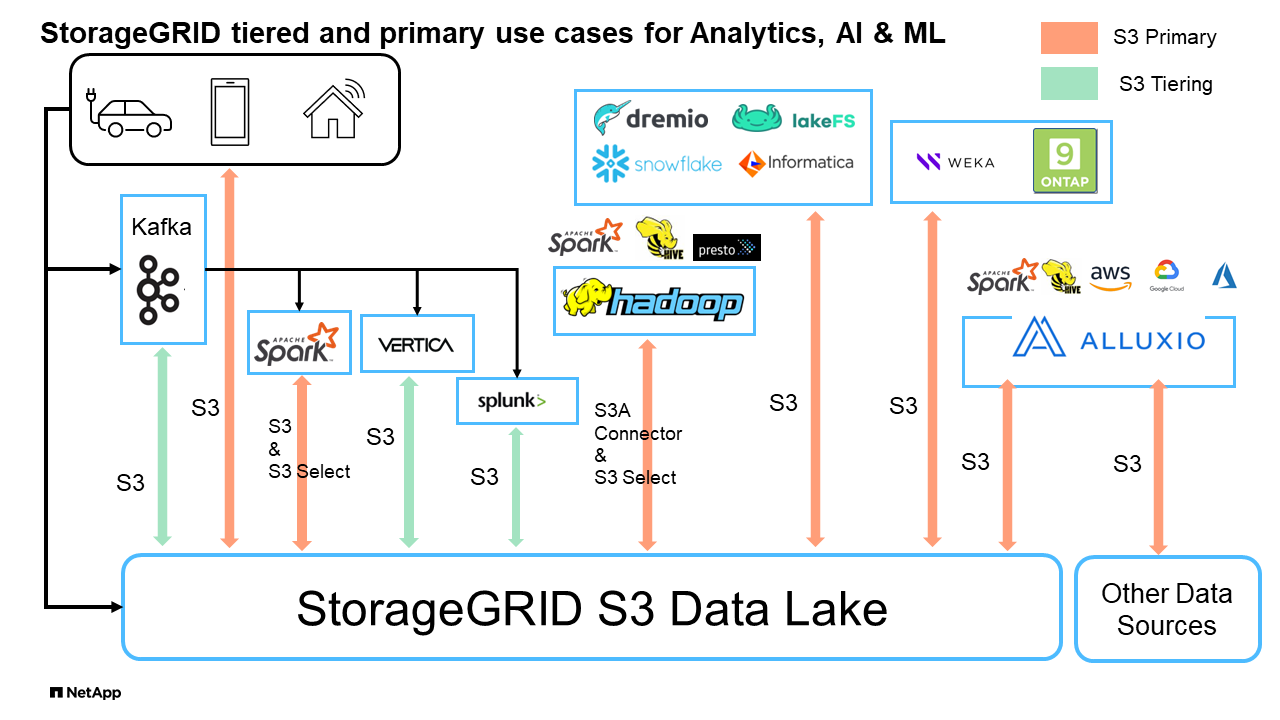
S3オブジェクトストレージを使用したデータウェアハウスとレイクハウスのベンチマーク比較調査
この記事では、NetApp StorageGRID を使用したさまざまなデータ ウェアハウスおよびレイクハウス エコシステムの包括的なベンチマークを紹介します。目標は、S3 オブジェクト ストレージで最も優れたパフォーマンスを発揮するシステムを特定することです。データ ウェアハウス/レイクハウスのアーキテクチャとテーブル形式(Parquet および Iceberg)の詳細については、こちらのhttps://hello.dremio.com/wp-apache-iceberg-the-definitive-guide-reg.html["『Apache Iceberg: The Definitive Guide』"]を参照してください。
-
ベンチマークツール- TPC-DS- https://www.tpc.org/tpcds/
-
ビッグデータエコシステム
-
VMのクラスタ(それぞれ128G RAM、24 vCPU、システムディスク用SSDストレージ)
-
Hadoop 3.3.5とHive 3.1.3(1つのネームノード+ 4つのデータノード)
-
Delta LakeとSpark 3.2.0(1マスター+ 4ワーカー)およびHadoop 3.3.5
-
Dremio v25.2(コーディネータ1名+執行者5名)
-
Trino v438(コーディネータ1名+作業者5名)
-
Starburst v453(コーディネータ1名+ワーカー5名)
-
-
オブジェクトストレージ
-
SG6060を3台+ SG1000ロードバランサを1台搭載した場合、SG®SG®11.8 NetApp StorageGRID
-
オブジェクト保護-コピー×2(EC 2+1と同様の結果)
-
-
データベースサイズ1000GB
-
Parquet形式を使用したクエリテストごとに、すべてのエコシステムでキャッシュが無効になりました。Iceberg形式では、S3 GET要求の数と、キャッシュが無効なシナリオとキャッシュが有効なシナリオの間の合計クエリ時間を比較しました。
TPC-DSには、ベンチマーク用に設計された99の複雑なSQLクエリが含まれています。99個すべてのクエリの実行にかかった合計時間を測定し、S3要求のタイプと数を調べて詳細な分析を行いました。私たちのテストでは、寄木細工とアイスバーグという2つの一般的なテーブル形式の効率を比較しました。
寄木細工テーブル形式のTPC-DSクエリ結果
| エコシステム | ハイブ | デルタレイク" | デレミオ | トリノ | スターバースト |
|---|---|---|---|---|---|
TPCDS 99クエリ+ |
1084 ^ 1 ^ |
55 |
36 |
32 |
28 |
S3要求の内訳 |
取得 |
一、一一七、一八四 |
2、074、610 |
3,939,690 |
1,504,212 |
1,495,039 |
観察:+ |
80%のGET:32MBオブジェクトから2KB~2MB、50~100要求/秒 |
73%の範囲は、32MBオブジェクトから100KB未満、1、000~1400要求/秒 |
90% 1Mバイト範囲は256MBのオブジェクトから取得、2500~3000の要求/秒 |
範囲GETサイズ:100KB未満50%、1MB前後16%、2MB~9MB 27%、3500~4000要求/秒 |
範囲GETサイズ:100KB未満50%、1MB前後16%、2MB~9MB 27%、4000-5000要求/秒 |
オブジェクトをリスト表示 |
三一二、〇 五三 |
二四、一五八 |
120 |
509 |
512 |
頭部+ |
156、027 |
一二、一 〇 三 |
96 |
0 |
0 |
頭部+ |
982、126 |
922、732 |
0 |
0 |
0 |
リクエスト総数 |
二、五六七、三九 〇 |
3、033、603 |
3,939.906 |
1,504,721 |
1Hiveクエリー番号72を完了できません
氷山表形式のTPC-DSクエリ結果
| エコシステム | デレミオ | トリノ | スターバースト |
|---|---|---|---|
TPCDS 99クエリ+合計分(キャッシュ無効) |
22 |
28 |
22 |
TPCDS 99クエリ+合計分2(キャッシュ有効) |
16 |
28 |
21.5 |
S3要求の内訳 |
GET(キャッシュ無効) |
1,985,922 |
938,639 |
931,582 |
GET(キャッシュ有効) |
611,347 |
30,158 |
3,281 |
観察:+ |
範囲GETサイズ:67%1MB、15% 100KB、10% 500KB、3500~4500リクエスト/秒 |
範囲GETサイズ:100KB未満42%、1MB前後17%、2MB~9MB 33%、3500~4000要求/秒 |
範囲GETサイズ:100KB未満43%、1MB前後17%、2MB~9MB 33%、4000-5000要求/秒 |
オブジェクトをリスト表示 |
1465 |
0 |
0 |
頭部+ |
1464 |
0 |
0 |
頭部+ |
3,702 |
509 |
509 |
合計要求数(キャッシュ無効) |
1,992,553 |
939,148 |
2トリノ/スターバーストのパフォーマンスは、コンピューティングリソースによってボトルネックになっています。クラスタにRAMを追加すると、合計クエリ時間が短縮されます。
最初の表に示すように、Hiveは他の最新のデータLakehouseエコシステムよりも大幅に低速です。Hiveが大量のS3リストオブジェクト要求を送信したことがわかりましたが、すべてのオブジェクトストレージプラットフォーム(特に多数のオブジェクトを含むバケットを扱う場合)では通常処理が遅くなります。これにより、全体的なクエリ時間が大幅に長くなります。さらに、現代のLakehouseエコシステムは、Hiveの毎秒50~100の要求に対して、毎秒2,000から5,000の要求までの多数のGET要求を並行して送信することができます。HiveとHadoop S3Aによる標準的なファイルシステムの模倣により、S3オブジェクトストレージとのやり取りが遅くなっています。
HiveまたはSparkでHadoop(HDFSまたはS3オブジェクトストレージ)を使用するには、HadoopとHive/Sparkの両方に関する広範な知識と、各サービスの設定がどのように連動するかを理解している必要があります。合計で1,000を超える設定があり、その多くは相互に関連しており、独立して変更することはできません。設定と値の最適な組み合わせを見つけるには、膨大な時間と労力が必要です。
寄木細工とアイスバーグの結果を比較すると、表形式が主要なパフォーマンス要因であることがわかります。Icebergテーブル形式は、S3要求の数に関して寄木細工よりも効率的であり、寄木細工形式と比較して35%~50%少ない要求です。
Dremio、Trino、Starburstのパフォーマンスは、主にクラスタのコンピューティング能力によって駆動されます。3つともS3オブジェクトストレージ接続にS3Aコネクタを使用しますが、Hadoopは必要なく、Hadoopのfs.s3a設定のほとんどはこれらのシステムでは使用されません。これにより、パフォーマンスの調整が簡易化され、Hadoop S3Aのさまざまな設定を学習してテストする必要がなくなります。
このベンチマーク結果から、S3ベースのワークロード向けに最適化されたビッグデータ分析システムが大きなパフォーマンス要因であることがわかります。最新のレイクハウスでは、クエリの実行が最適化され、メタデータが効率的に利用され、S3データへのシームレスなアクセスが提供されるため、S3ストレージを使用する場合にHiveよりもパフォーマンスが向上します。
StorageGRIDでDremio S3データソースを設定するには、こちらを参照し "ページ"てください。
StorageGRIDとDremioが連携して最新の効率的なデータレイクインフラを提供する方法や、NetAppがHive + HDFSからDremio + StorageGRIDに移行してビッグデータ分析の効率を劇的に向上させる方法については、以下のリンクをご覧ください。