

Hadoop S3Aの調整
 変更を提案
変更を提案
Angela Cheng著_
Hadoop S3Aコネクタは、HadoopベースのアプリケーションとS3オブジェクトストレージ間のシームレスなやり取りを容易にします。S3オブジェクトストレージを使用する際のパフォーマンスを最適化するには、Hadoop S3Aコネクタの調整が不可欠です。調整の詳細に進む前に、Hadoopとそのコンポーネントの基本を理解しておきましょう。
Hadoopとは
-
Hadoop * は、大規模なデータ処理とストレージを処理するために設計された強力なオープンソース・フレームワークです。これにより、コンピュータのクラスタ間で分散ストレージと並列処理が可能になります。
Hadoopの3つのコアコンポーネントは次のとおりです。
-
* Hadoop HDFS(Hadoop分散ファイルシステム)*:ストレージを処理し、データをブロックに分割してノード間で分散します。
-
* Hadoop MapReduce *:タスクを小さなチャンクに分割し、並行して実行することでデータを処理します。
-
* Hadoop YARN(Yet Another Resource Negotiator):* "リソースの管理とタスクのスケジュール設定を効率的に行う"
Hadoop HDFSおよびS3Aコネクタ
HDFSはHadoopエコシステムの重要なコンポーネントであり、効率的なビッグデータ処理において重要な役割を果たします。HDFSは信頼性の高いストレージと管理を実現します。並列処理と最適化されたデータストレージを実現し、データアクセスと分析を高速化します。
ビッグデータ処理では、HDFSは大規模データセットにフォールトトレラントなストレージを提供することに優れています。これは、データレプリケーションによって実現されます。IT部門は、データウェアハウス環境に大量の構造化データと非構造化データを格納して管理できます。さらに、Apache Spark、Hive、Pig、Flinkなどの主要なビッグデータ処理フレームワークとシームレスに統合し、スケーラブルで効率的なデータ処理を可能にします。UNIXベース(Linux)オペレーティングシステムと互換性があり、ビッグデータ処理にLinuxベースの環境を使用することを好む組織にとって理想的な選択肢です。
時間の経過とともにデータ量が増大するにつれて、独自のコンピューティングとストレージを使用してHadoopクラスタに新しいマシンを追加するアプローチは非効率的になります。リニアに拡張すると、リソースの効率的な使用やインフラの管理が難しくなります。
これらの課題に対処するために、Hadoop S3AコネクタはS3オブジェクトストレージに対するハイパフォーマンスI/Oを提供します。S3Aを使用してHadoopワークフローを実装することで、オブジェクトストレージをデータリポジトリとして活用でき、コンピューティングとストレージを分離することができます。これにより、コンピューティングとストレージを別々に拡張できます。コンピューティングとストレージを分離することで、コンピューティングジョブ専用のリソースを確保し、データセットのサイズに基づいて容量を提供することもできます。そのため、Hadoopワークフローの総所有コストを削減することができます。
Hadoop S3Aコネクタの調整
S3の動作はHDFSとは異なり、ファイルシステムの外観を維持しようとすると積極的に最適化されません。S3リソースを最も効率的に使用するには、慎重な調整、テスト、実験が必要です。
本ドキュメントのHadoopオプションはHadoop 3.3.5に基づいています。を参照してください。 "Hadoop 3.3.5 core-site.xml" 使用可能なすべてのオプションについて。
注–一部のHadoop fs.s3a設定のデフォルト値は、Hadoopのバージョンによって異なります。現在のHadoopバージョンに固有のデフォルト値を確認してください。これらの設定がHadoop core-site.xmlに指定されていない場合は、デフォルト値が使用されます。SparkまたはHive構成オプションを使用して、実行時に値を上書きできます。
これに行く必要があります。 "Apache Hadoopページ" 各fs.s3aオプションを理解するため。可能であれば、非本番環境のHadoopクラスタでテストして最適な値を特定します。
お読みください "S3Aコネクタでの作業時のパフォーマンスの最大化" その他のチューニングの推奨事項については、
主な考慮事項をいくつか見ていきましょう。
-
1 。データ圧縮*
StorageGRID圧縮を有効にしないでください。ほとんどのビッグデータシステムでは、オブジェクト全体を読み出す代わりにバイト範囲GETを使用します。圧縮オブジェクトにbyte range getを使用すると、GETのパフォーマンスが大幅に低下します。
※ 2S3Aコミッタ*
一般的には、マジックs3aコミッターをお勧めします。これを参照してください "共通のS3Aコミッタオプションページ" マジックコミッタとそれに関連するs3a設定をよりよく理解するため。
マジックコミッター:
Magic Committerは、特にS3Guardを使用して、S3オブジェクトストアで一貫したディレクトリリストを提供します。
整合性のあるS3(現在はそうなっています)を使用すると、Magic Committerは任意のS3バケットで安全に使用できます。
選択と実験:
ユースケースに応じて、Staging Committer(クラスタHDFSファイルシステムに依存)とMagic Committerのどちらかを選択できます。
両方を試して、ワークロードと要件に最適なものを判断してください。
要約すると、S3Aコミッタは、S3への一貫した、高性能で信頼性の高い出力コミットメントという基本的な課題に対する解決策を提供します。内部設計により、データの整合性を維持しながら効率的なデータ転送を実現します。
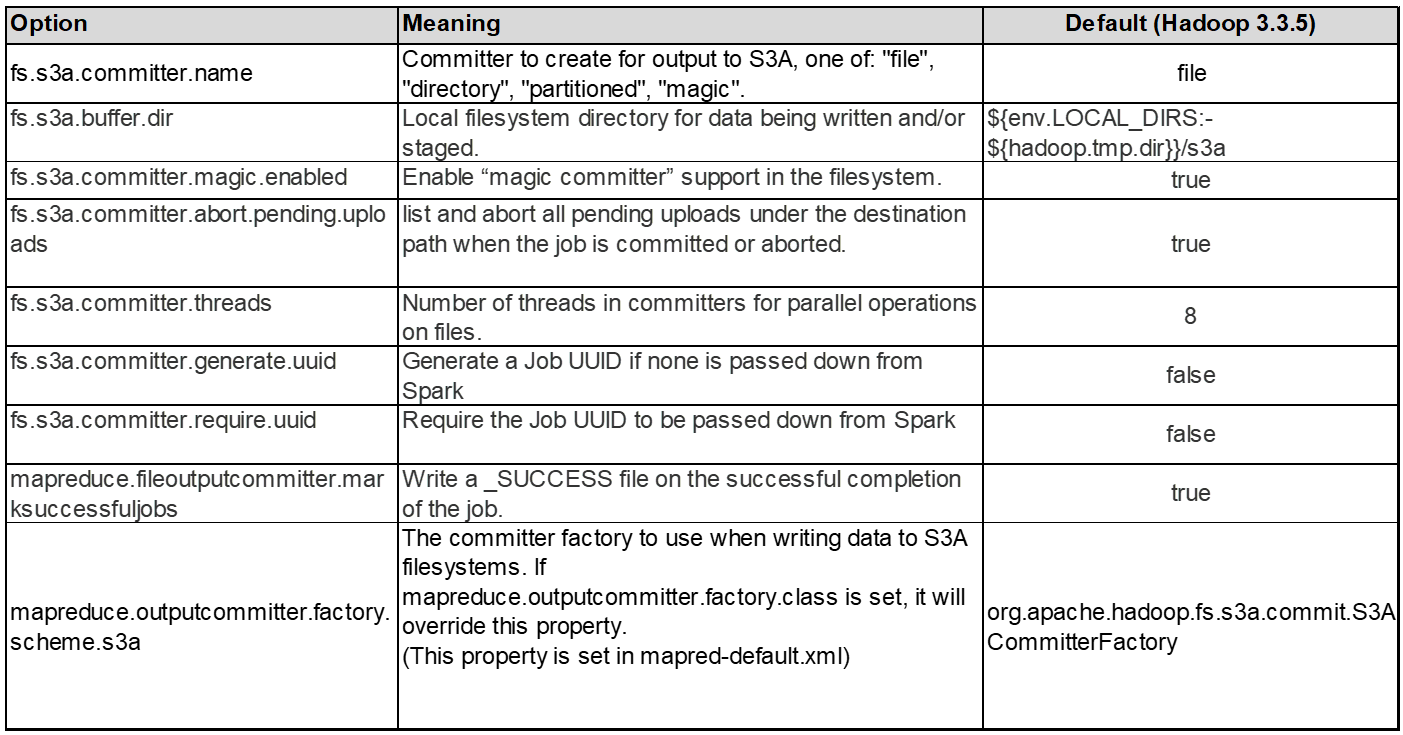
3.スレッド、接続プールサイズ、ブロックサイズ
-
1つのバケットとやり取りする各* S3A *クライアントには、アップロードおよびコピー処理用のオープンHTTP 1.1接続とスレッドの専用プールがあります。
-
S3にデータをアップロードする場合、データはブロックに分割されます。デフォルトのブロックサイズは32MBです。この値をカスタマイズするには、fs.s3a.block.sizeプロパティを設定します。
-
ブロックサイズを大きくすると、アップロード中にマルチパートパートパートを管理するオーバーヘッドが軽減されるため、大規模なデータアップロードのパフォーマンスが向上します。大規模なデータセットの場合、推奨値は256 MB以上です。
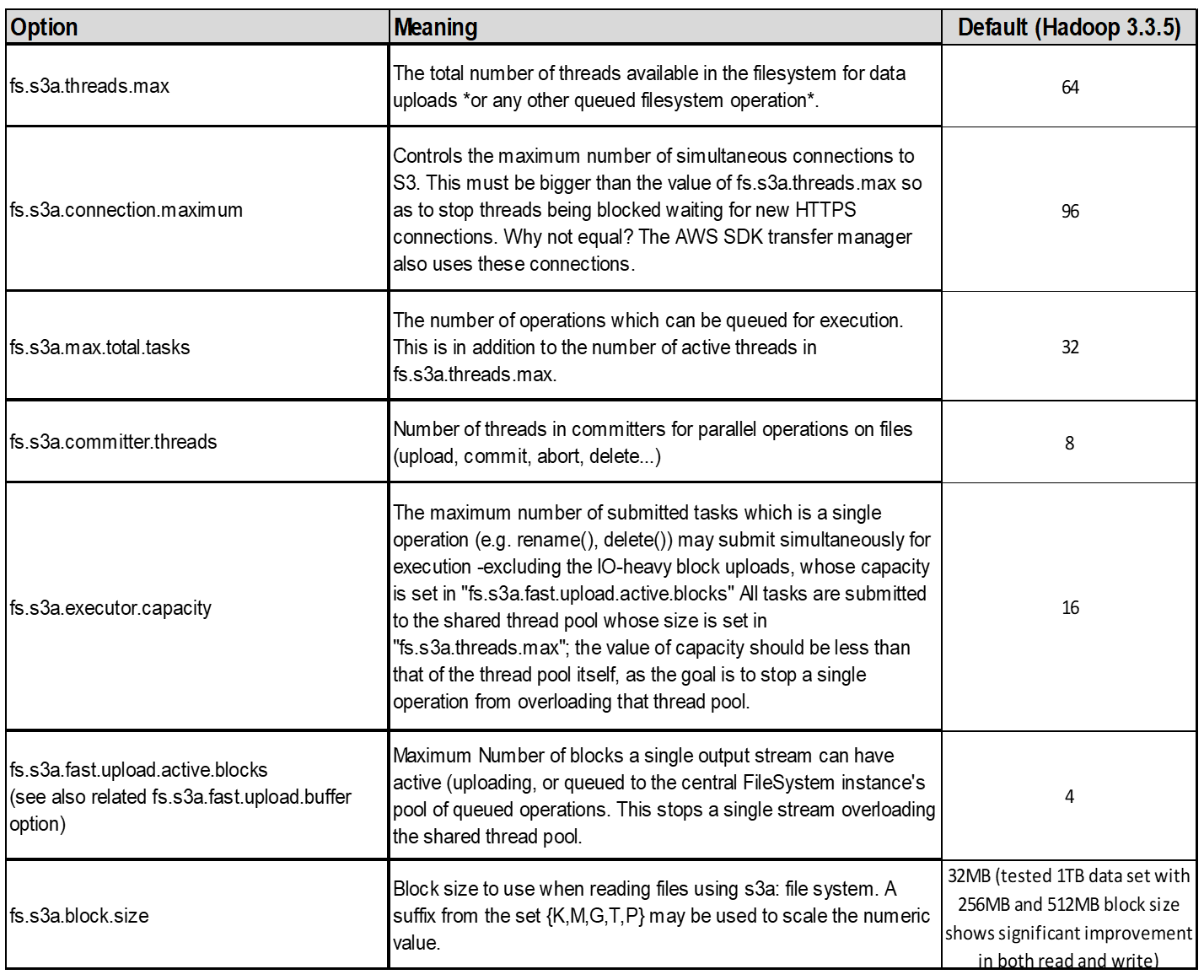
4.マルチパートアップロード
s3aコミッタ*常に* MPU(マルチパートアップロード)を使用してデータをs3バケットにアップロードします。これは、タスクの失敗、タスクの投機的な実行、およびコミット前のジョブの中止を可能にするために必要です。マルチパートアップロードに関連する主な仕様を次に示します。
-
最大オブジェクトサイズ:5TiB(テラバイト)。
-
アップロードあたりの最大パーツ数:10、000
-
パーツ番号:1~10,000(含む)。
-
パーツサイズ:5MiB~5GiB。特に、マルチパートアップロードの最後のパートには最小サイズの制限はありません。
S3マルチパートアップロードに小さいパートサイズを使用すると、メリットとデメリットの両方があります。
利点:
-
ネットワークの問題からのクイックリカバリ:小さなパーツをアップロードすると、ネットワークエラーによるアップロードの再開による影響が最小限に抑えられます。パーツに障害が発生した場合は、オブジェクト全体ではなく、その特定のパーツのみを再アップロードする必要があります。
-
並列化の向上:マルチスレッディングまたは同時接続を利用して、より多くのパーツを並行してアップロードできます。この並列化により、特に大きなファイルを処理する場合のパフォーマンスが向上します。
欠点:
-
ネットワークオーバーヘッド:部品サイズが小さいほど、アップロードする部品が増えます。各部品には独自のHTTPリクエストが必要です。HTTP要求が増えると、個 々 の要求の開始と完了のオーバーヘッドが増加します。多数の小さなパーツを管理すると、パフォーマンスに影響を与える可能性があります。
-
複雑さ:注文の管理、パーツの追跡、アップロードの成功の確認は面倒です。アップロードを中止する必要がある場合は、すでにアップロードされているすべてのパーツを追跡してパージする必要があります。
Hadoopの場合、fs.s3a.multipart.sizeには256MB以上のパーツサイズを推奨します。fs.s3a.mutlipart.threshold値は常に2 x fs.s3a.multipart.size値に設定します。たとえば、fs.s3a.multipart.size=256Mの場合、fs.s3a.mutlipart.thresholdは512Mにする必要があります。
大きなデータセットには大きなパーツサイズを使用してください。特定のユースケースとネットワーク条件に基づいて、これらの要因のバランスを取る部品サイズを選択することが重要です。
マルチパートアップロードは "3段階のプロセス":
-
アップロードが開始され、StorageGRIDはupload-idを返します。
-
オブジェクトパーツはupload-idを使用してアップロードされます。
-
すべてのオブジェクトパートがアップロードされると、は、upload-idを指定して完全なマルチパートアップロード要求を送信します。StorageGRIDは、アップロードされたパーツからオブジェクトを構築し、クライアントがオブジェクトにアクセスできるようにします。
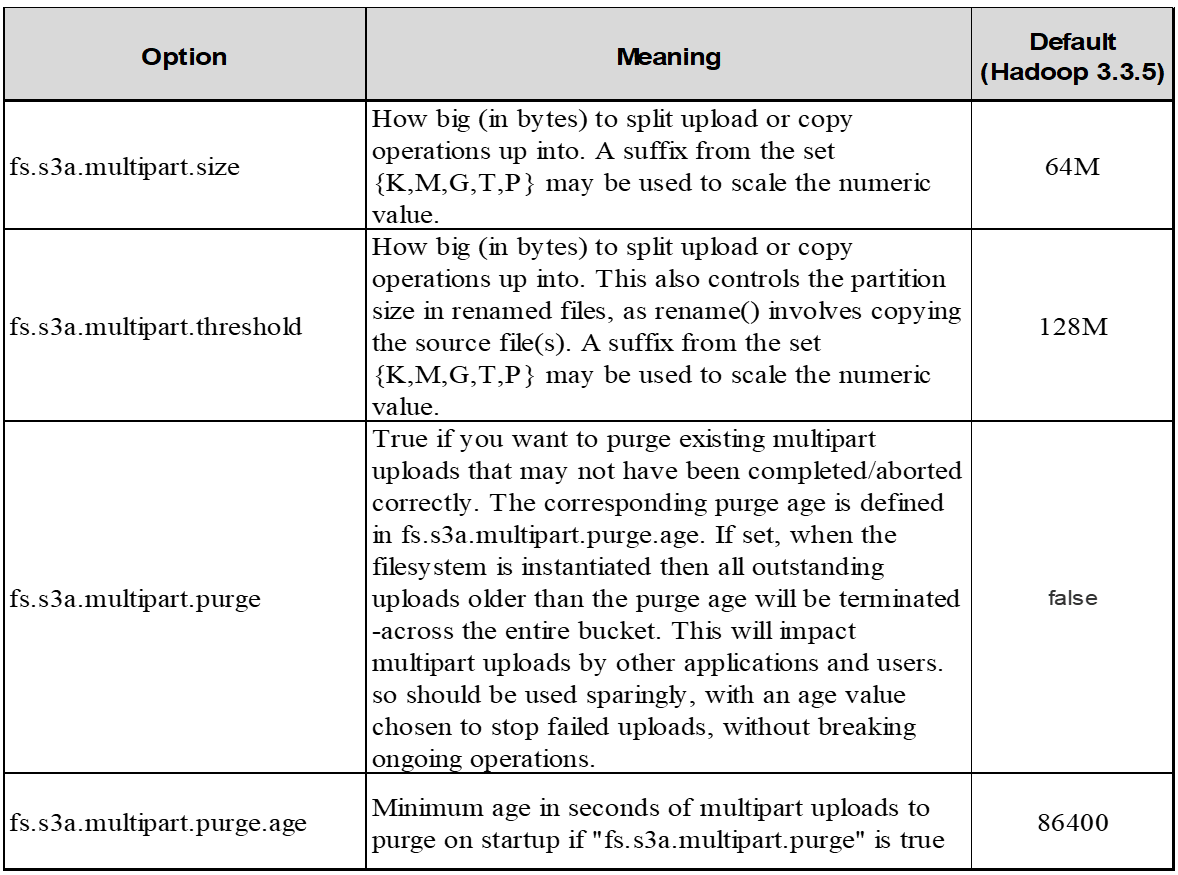
Complete multipart upload要求が正常に送信されなかった場合、パーツはStorageGRIDに残り、オブジェクトは作成されません。これは、ジョブが中断、失敗、または中止された場合に発生します。マルチパートアップロードが完了するか中止されるか、アップロードが開始されてから15日が経過するとStorageGRIDがそれらのパートをパージするまで、パートはグリッドに残ります。バケット内で実行中のマルチパートアップロードが多数(数十万から数百万)ある場合、Hadoopが「list-multipart-uploads」を送信すると(この要求はアップロードIDでフィルタリングされません)、要求の完了に時間がかかるか、最終的にタイムアウトになることがあります。fs.s3a.mutlipart.purgeをtrueに設定し、適切なfs.s3a.multipart.purge.ageの値を設定することを検討してください(例:5~7日、デフォルト値の86400、つまり1日は使用しないでください)。または、NetAppサポートに状況を調査してください。
5.メモリ内のバッファ書き込みデータ
パフォーマンスを向上させるには、書き込みデータをS3にアップロードする前にメモリにバッファします。これにより、少量の書き込み数が削減され、効率が向上します。

S3とHDFSは別 々 の方法で機能することに注意してください。S3リソースを最も効率的に使用するには、慎重な調整/テスト/実験が必要です。