

NetApp Cloud Tiering 에서 데이터 계층화에 사용되는 개체 스토리지 관리
 변경 제안
변경 제안
온프레미스 ONTAP 클러스터를 구성하여 특정 개체 스토리지에 데이터를 계층화한 후 NetApp Cloud Tiering 사용하여 추가 개체 스토리지 작업을 수행할 수 있습니다. 새로운 개체 스토리지를 추가하고, 계층화된 데이터를 보조 개체 스토리지로 미러링하고, 기본 개체 스토리지와 미러 개체 스토리지를 교체하고, 집계에서 미러링된 개체 저장소를 제거하는 등의 작업이 가능합니다.
클러스터에 대해 구성된 개체 저장소 보기
각 클러스터에 대해 구성된 모든 개체 저장소와 해당 저장소가 연결된 집계를 볼 수 있습니다.
-
클러스터 페이지에서 클러스터의 메뉴 아이콘을 선택하고 *개체 저장소 정보*를 선택합니다.
-
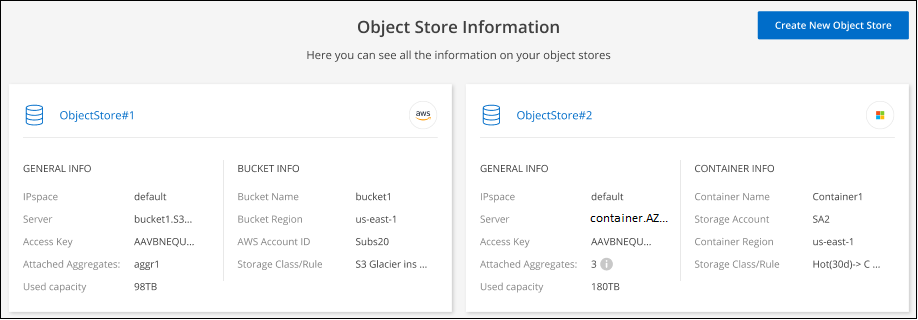
객체 저장소에 대한 세부 정보를 검토합니다.
이 예에서는 클러스터의 서로 다른 집계에 연결된 Amazon S3와 Azure Blob 개체 저장소를 모두 보여줍니다.
새로운 객체 저장소 추가
클러스터의 집계에 대한 새로운 객체 저장소를 추가할 수 있습니다. 생성한 후에는 집계에 첨부할 수 있습니다.
-
클러스터 페이지에서 클러스터의 메뉴 아이콘을 선택하고 *개체 저장소 정보*를 선택합니다.
-
개체 저장소 정보 페이지에서 *새 개체 저장소 만들기*를 선택합니다.
개체 저장소 마법사가 시작됩니다. 아래 예에서는 Amazon S3에 객체 저장소를 만드는 방법을 보여줍니다.
-
개체 저장소 이름 정의: 이 개체 저장소의 이름을 입력합니다. 이 클러스터에서 집계와 함께 사용할 수 있는 다른 개체 저장소와 고유해야 합니다.
-
공급자 선택: 공급자(예: Amazon Web Services)를 선택하고 *계속*을 선택합니다.
-
개체 저장소 만들기 페이지의 단계를 완료하세요.
-
S3 버킷: 새로운 S3 버킷을 추가하거나 fabric-pool 접두사로 시작하는 기존 S3 버킷을 선택합니다. 그런 다음 버킷에 대한 액세스를 제공하는 AWS 계정 ID를 입력하고 버킷 리전을 선택한 후 *계속*을 선택합니다.
fabric-pool 접두사가 필요한 이유는 콘솔 에이전트의 IAM 정책에 따라 인스턴스가 해당 접두사로 명명된 버킷에서 S3 작업을 수행할 수 있기 때문입니다. 예를 들어, S3 버킷의 이름을 _fabric-pool-AFF1_로 지정할 수 있습니다. 여기서 AFF1은 클러스터의 이름입니다.
-
스토리지 클래스 수명 주기: 클라우드 계층화는 계층화된 데이터의 수명 주기 전환을 관리합니다. 데이터는 Standard 클래스에서 시작하지만, 특정 일수가 지나면 데이터에 다른 저장 클래스를 적용하는 규칙을 만들 수 있습니다.
계층화된 데이터를 전환할 S3 스토리지 클래스를 선택하고, 데이터가 해당 클래스에 할당되기 전까지의 일수를 선택한 후 *계속*을 선택합니다. 예를 들어, 아래 스크린샷은 계층화된 데이터가 개체 저장소에서 45일이 지난 후 Standard 클래스에서 Standard-IA 클래스로 할당되는 것을 보여줍니다.
*이 저장소 클래스에 데이터 유지*를 선택하면 데이터는 표준 저장소 클래스에 유지되며 규칙은 적용되지 않습니다. "지원되는 스토리지 클래스 보기" .
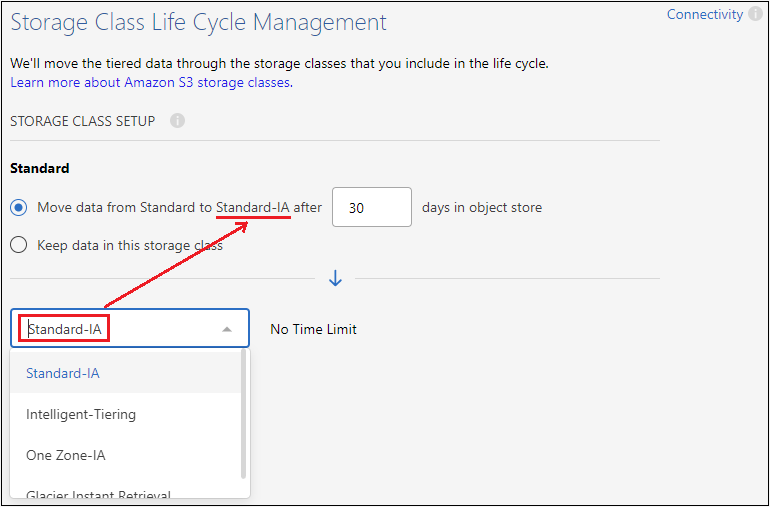
선택한 버킷의 모든 객체에 수명 주기 규칙이 적용됩니다.
-
자격 증명: 필요한 S3 권한이 있는 IAM 사용자의 액세스 키 ID와 비밀 키를 입력하고 *계속*을 선택합니다.
IAM 사용자는 S3 버킷 페이지에서 선택하거나 생성한 버킷과 동일한 AWS 계정에 있어야 합니다. 계층화 활성화 섹션에서 필요한 권한을 확인하세요.
-
클러스터 네트워크: ONTAP 개체 스토리지에 연결하는 데 사용할 IP 공간을 선택하고 *계속*을 선택합니다.
올바른 IP 공간을 선택하면 Cloud Tiering이 ONTAP 에서 클라우드 공급자의 개체 스토리지로의 연결을 설정할 수 있습니다.
-
객체 저장소가 생성됩니다.
이제 클러스터의 집계에 개체 저장소를 첨부할 수 있습니다.
미러링을 위해 집계에 두 번째 개체 저장소를 연결합니다.
두 번째 개체 저장소를 집계에 연결하여 FabricPool 미러를 생성하고 데이터를 두 개의 개체 저장소에 동기적으로 계층화할 수 있습니다. 집계에 이미 하나의 개체 저장소가 연결되어 있어야 합니다. "FabricPool 미러에 대해 자세히 알아보세요" .
MetroCluster 구성을 사용하는 경우 서로 다른 가용성 영역에 있는 퍼블릭 클라우드의 개체 저장소를 사용하는 것이 가장 좋습니다. "ONTAP 문서에서 MetroCluster 요구 사항에 대해 자세히 알아보세요." . MetroCluster 내에서 미러링되지 않은 집계를 사용하는 것은 권장되지 않습니다. 미러링되지 않은 집계를 사용하면 오류 메시지가 표시됩니다.
MetroCluster 구성에서 StorageGRID 개체 저장소로 사용하는 경우 두 ONTAP 시스템 모두 단일 StorageGRID 시스템에 FabricPool 계층화를 수행할 수 있습니다. 각 ONTAP 시스템은 데이터를 서로 다른 버킷으로 분류해야 합니다.
-
클러스터 페이지에서 선택한 클러스터에 대해 *고급 설정*을 선택합니다.

-
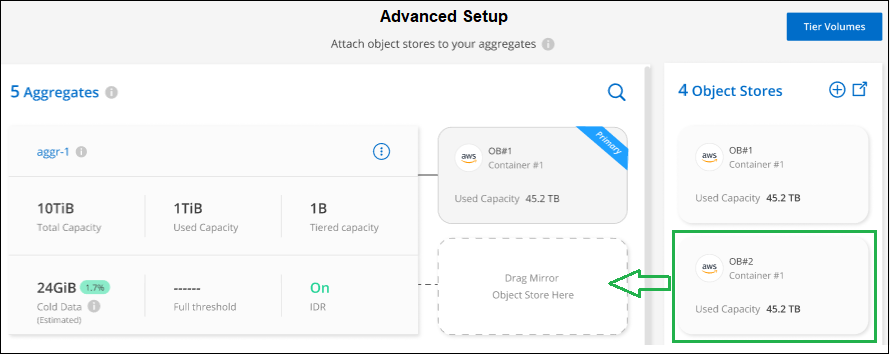
고급 설정 페이지에서 사용할 개체 저장소를 미러 개체 저장소 위치로 끌어다 놓습니다.
-
개체 저장소 연결 대화 상자에서 *연결*을 선택하면 두 번째 개체 저장소가 집계에 연결됩니다.
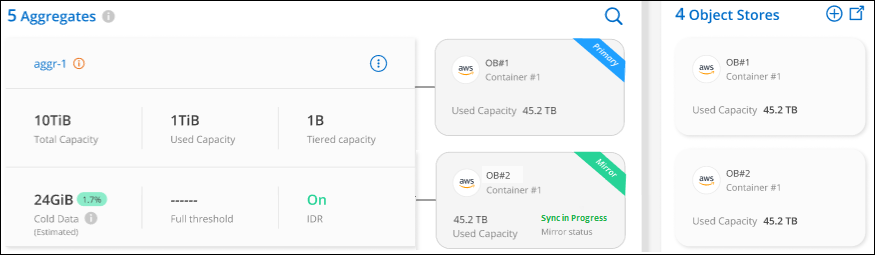
2개의 개체 저장소가 동기화되는 동안 미러 상태는 "동기화 진행 중"으로 표시됩니다. 동기화가 완료되면 상태가 "동기화됨"으로 변경됩니다.
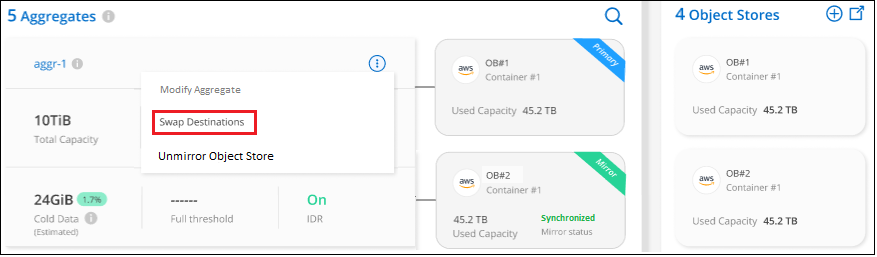
기본 및 미러 개체 저장소를 교체합니다.
기본 및 미러 개체 저장소를 집계로 바꿀 수 있습니다. 개체 저장소 미러가 기본이 되고, 원래 기본이 미러가 됩니다.
-
클러스터 페이지에서 선택한 클러스터에 대해 *고급 설정*을 선택합니다.
-
고급 설정 페이지에서 집계에 대한 메뉴 아이콘을 선택하고 *대상 바꾸기*를 선택합니다.
-
대화 상자에서 작업을 승인하면 기본 및 미러 개체 저장소가 바뀝니다.
집계에서 미러 객체 저장소 제거
더 이상 추가 개체 저장소에 복제할 필요가 없으면 FabricPool 미러를 제거할 수 있습니다.
-
클러스터 페이지에서 선택한 클러스터에 대해 *고급 설정*을 선택합니다.
-
고급 설정 페이지에서 집계에 대한 메뉴 아이콘을 선택하고 *개체 저장소 미러링 해제*를 선택합니다.

미러 개체 저장소가 집계에서 제거되고 계층화된 데이터는 더 이상 복제되지 않습니다.

|
MetroCluster 구성에서 미러 개체 저장소를 제거할 때 기본 개체 저장소도 제거할지 여부를 묻는 메시지가 표시됩니다. 기본 개체 저장소를 집계에 연결된 상태로 유지하거나 제거할 수 있습니다. |
계층화된 데이터를 다른 클라우드 공급자로 마이그레이션
클라우드 티어링을 사용하면 계층화된 데이터를 다른 클라우드 공급자로 쉽게 마이그레이션할 수 있습니다. 예를 들어 Amazon S3에서 Azure Blob으로 이동하려면 위에 나열된 단계를 순서대로 따르면 됩니다.
-
Azure Blob 개체 저장소를 추가합니다.
-
이 새로운 객체 저장소를 기존 집계에 대한 미러로 연결합니다.
-
기본 및 미러 개체 저장소를 바꿉니다.
-
Amazon S3 객체 저장소의 미러링을 해제합니다.