

NetApp Data Classification을 통해 조직 데이터에 대한 거버넌스 세부 정보를 확인하세요
 변경 제안
변경 제안
조직의 스토리지 리소스에 있는 데이터와 관련된 비용을 제어하세요. NetApp Data Classification 시스템에서 오래된 데이터, 중복 파일, 매우 큰 파일의 양을 파악하여 일부 파일을 제거할지 아니면 비용이 덜 드는 개체 스토리지로 계층화할지 결정할 수 있도록 도와줍니다.
여기부터 연구를 시작해야 합니다. 거버넌스 대시보드에서 추가 조사할 영역을 선택할 수 있습니다.
또한 온프레미스 위치에서 클라우드로 데이터를 마이그레이션할 계획이라면 데이터를 이동하기 전에 데이터 크기를 확인하고 데이터에 중요한 정보가 포함되어 있는지 확인할 수 있습니다.
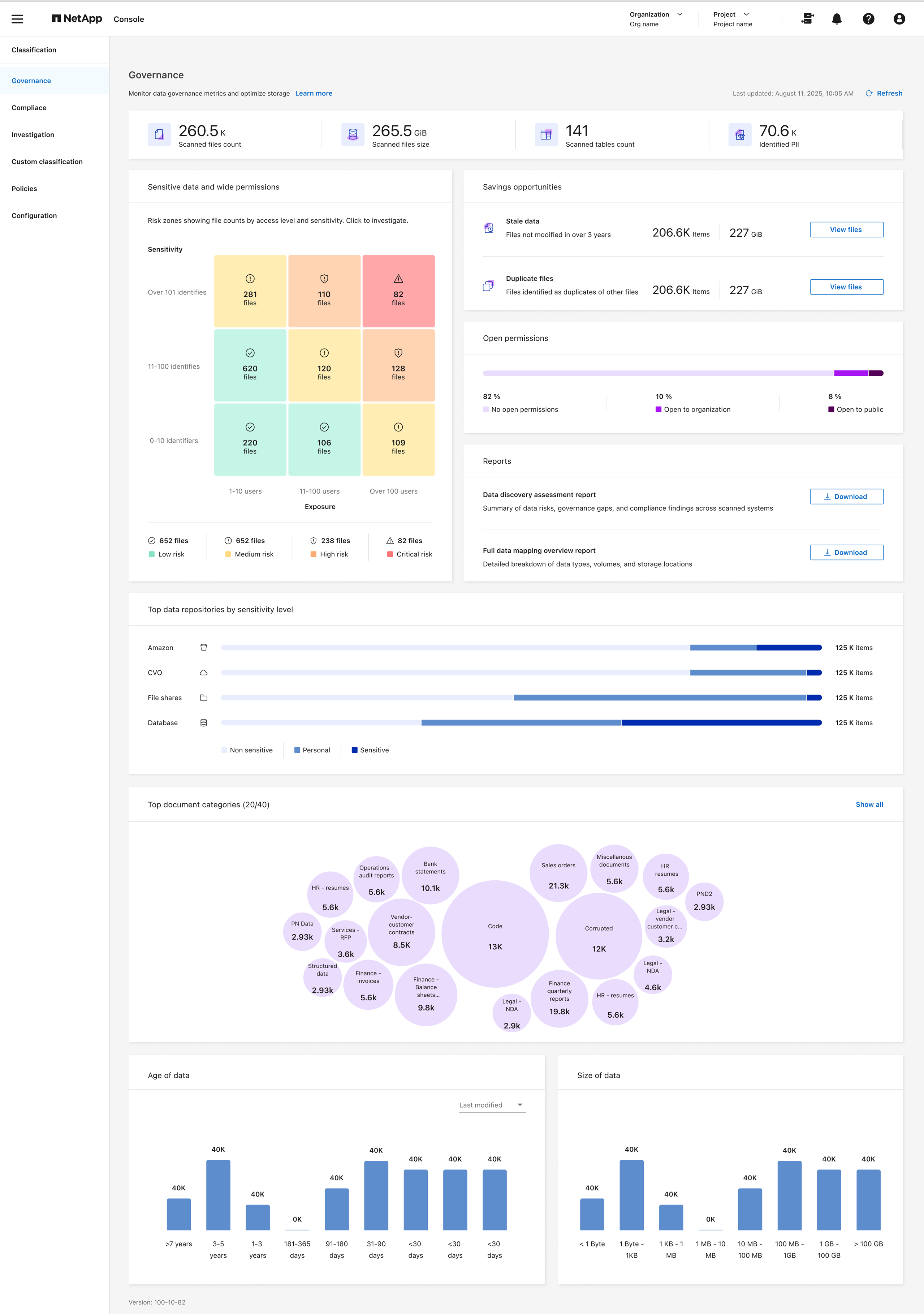
거버넌스 대시보드를 검토하세요
거버넌스 대시보드는 스토리지 리소스에 저장된 데이터와 관련된 비용을 제어하고 효율성을 높이는 데 도움이 되는 정보를 제공합니다.
-
NetApp Console 메뉴에서 *거버넌스 > 분류*를 선택합니다.
-
*거버넌스*를 선택하세요.
거버넌스 대시보드가 나타납니다.
저축 기회 검토
Saving Opportunities 구성 요소는 삭제하거나 비용이 덜 드는 개체 저장소로 계층화할 수 있는 데이터를 보여줍니다. _Saving Opportunities_의 데이터는 2시간마다 업데이트됩니다. 수동으로 데이터를 업데이트할 수도 있습니다.
-
데이터 분류 메뉴에서 *거버넌스*를 선택합니다.
-
Governance 대시보드의 각 Savings Opportunities 타일 내에서 *Optimize Storage*를 선택하여 Investigation 페이지에서 필터링된 결과를 확인합니다. 삭제하거나 비용이 저렴한 스토리지로 계층화해야 하는 데이터를 검색하려면 _Saving Opportunities_를 조사하십시오.
-
오래된 데이터 - 기본적으로 마지막 수정일로부터 3년 이상 지난 데이터는 오래된 데이터로 간주됩니다. [오래된 데이터의 정의를 사용자 지정할 수 있습니다](task-stale-data.html).
-
중복 파일 - 스캔하는 데이터 소스의 다른 위치에 중복된 파일입니다. "어떤 유형의 중복 파일이 표시되는지 확인하세요" .
-

|
데이터 소스 중 하나라도 데이터 계층화를 구현하는 경우 이미 개체 스토리지에 있는 오래된 데이터는 오래된 데이터 범주에서 식별할 수 있습니다. |
데이터 발견 평가 보고서 작성
데이터 발견 평가 보고서는 스캔된 환경에 대한 높은 수준의 분석을 제공하여 문제가 있는 영역과 잠재적인 수정 단계를 보여줍니다. 결과는 데이터 매핑과 분류를 기반으로 합니다. 이 보고서의 목적은 데이터 세트의 세 가지 중요한 측면에 대한 인식을 높이는 것입니다.
| 특징 | 설명 |
|---|---|
데이터 거버넌스 문제 |
귀하가 소유한 모든 데이터에 대한 자세한 그림과 비용을 절감하기 위해 데이터 양을 줄일 수 있는 영역에 대한 그림입니다. |
데이터 보안 노출 |
광범위한 액세스 권한으로 인해 내부 또는 외부 공격을 통해 데이터에 액세스할 수 있는 영역입니다. |
데이터 규정 준수 격차 |
보안과 DSAR(데이터 주체 접근 요청)을 위해 귀하의 개인 정보 또는 민감한 개인 정보가 어디에 있는지 알려드립니다. |
보고서를 사용하면 다음과 같은 작업을 수행할 수 있습니다.
-
보존 정책을 변경하거나 특정 데이터(오래된 데이터 또는 중복 데이터)를 이동 또는 삭제하여 보관 비용을 줄이세요.
-
글로벌 그룹 관리 정책을 개정하여 광범위한 권한이 있는 데이터를 보호하세요.
-
PII를 보다 안전한 데이터 저장소로 옮겨 개인 정보나 민감한 개인 정보가 포함된 데이터를 보호하세요.
-
데이터 분류에서 *거버넌스*를 선택합니다.
-
보고서 타일에서 *데이터 검색 평가 보고서*를 선택합니다.
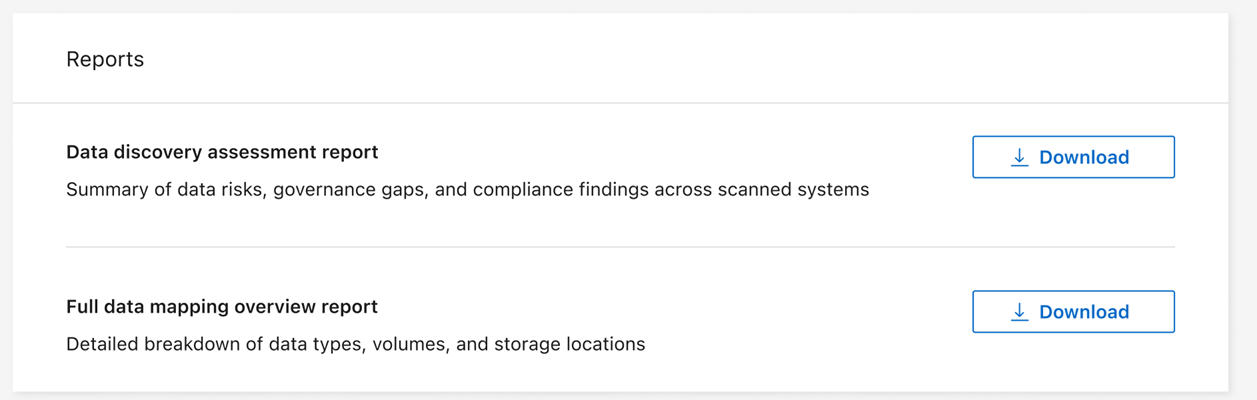
데이터 분류는 검토하고 공유할 수 있는 PDF 보고서를 생성합니다.
데이터 매핑 개요 보고서 만들기
데이터 매핑 개요 보고서는 마이그레이션, 백업, 보안 및 규정 준수 프로세스에 대한 결정을 내리는 데 도움이 되도록 회사 데이터 소스에 저장된 데이터에 대한 개요를 제공합니다. 이 보고서는 모든 시스템과 데이터 소스를 요약합니다. 또한 각 시스템에 대한 분석도 제공합니다.
보고서에는 다음과 같은 정보가 포함되어 있습니다.
| 범주 | 설명 |
|---|---|
사용 용량 |
모든 시스템에 대해: 각 시스템의 파일 수와 사용된 용량을 나열합니다. 단일 시스템의 경우: 가장 많은 용량을 사용하는 파일을 나열합니다. |
데이터의 시대 |
파일이 생성된 날짜, 마지막으로 수정된 날짜 또는 마지막으로 액세스된 날짜에 대한 세 가지 차트와 그래프를 제공합니다. 특정 날짜 범위를 기준으로 파일 수와 사용된 용량을 나열합니다. |
데이터 크기 |
시스템의 특정 크기 범위 내에 존재하는 파일의 수를 나열합니다. |
-
데이터 분류에서 *거버넌스*를 선택합니다.
-
보고서 타일에서 전체 데이터 매핑 개요 보고서 제목의 다운로드 버튼을 선택합니다.
데이터 분류는 필요에 따라 검토하고 다른 그룹으로 보낼 수 있는 PDF 보고서를 생성합니다.
보고서가 1MB보다 크면 PDF 파일이 데이터 분류 인스턴스에 보관되고 정확한 위치에 대한 팝업 메시지가 표시됩니다. 사내 Linux 머신이나 클라우드에 배포한 Linux 머신에 Data Classification을 설치한 경우 PDF 파일로 바로 이동할 수 있습니다. 데이터 분류가 클라우드에 배포되면 PDF 파일을 다운로드하려면 SSH를 통해 데이터 분류 인스턴스에 대한 권한을 부여해야 합니다.
데이터 민감도별로 나열된 상위 데이터 저장소를 검토하세요.
데이터 매핑 개요 보고서의 민감도 수준별 상위 데이터 저장소 영역에는 가장 민감한 항목이 포함된 상위 4개 데이터 저장소(시스템 및 데이터 소스)가 나열됩니다. 각 시스템의 막대형 차트는 다음과 같이 구분됩니다.
-
민감하지 않은 데이터
-
개인정보
-
민감한 개인 데이터
이 데이터는 2시간마다 새로 고쳐지며, 수동으로 새로 고칠 수 있습니다.
-
각 카테고리에 속한 총 항목 수를 보려면 막대의 각 섹션 위에 커서를 올려놓으세요.
-
조사 페이지에 나타날 결과를 필터링하려면 막대에서 각 영역을 선택하고 자세히 조사하세요.
민감한 데이터와 광범위한 권한 검토
거버넌스 대시보드의 민감한 데이터 및 광범위한 권한 영역에서는 민감한 데이터가 포함되어 있고 광범위한 권한이 있는 파일의 수가 표시됩니다. 표에는 다음과 같은 유형의 권한이 나와 있습니다.
-
수평축에는 가장 제한적인 허가부터 가장 관대한 제한까지 있습니다.
-
수직축에는 가장 민감하지 않은 데이터부터 가장 민감한 데이터까지 나열되어 있습니다.
-
각 카테고리에 있는 총 파일 수를 보려면 각 상자 위에 커서를 올려놓으세요.
-
조사 페이지에 나타날 결과를 필터링하려면 상자를 선택하고 자세히 조사하세요.
공개 허가 유형별로 나열된 데이터 검토
데이터 매핑 개요 보고서의 열린 권한 영역에는 스캔 중인 모든 파일에 대해 각 유형의 권한에 대한 백분율이 표시됩니다. 차트에서는 다음과 같은 유형의 권한을 보여줍니다.
-
공개 허가 없음
-
조직에 개방적
-
대중에게 공개
-
알 수 없는 액세스
-
각 카테고리에 있는 총 파일 수를 보려면 각 상자 위에 커서를 올려놓으세요.
-
조사 페이지에 나타날 결과를 필터링하려면 상자를 선택하고 자세히 조사하세요.
데이터의 연령과 크기를 검토하세요
데이터 매핑 개요 보고서의 연령 및 크기 그래프에 있는 항목을 조사하여 삭제하거나 비용이 덜 드는 개체 저장소로 계층화해야 할 데이터가 있는지 확인할 수 있습니다.
-
데이터 연령 차트에서 데이터 연령에 대한 자세한 내용을 보려면 차트의 한 지점 위에 커서를 놓습니다.
-
연령이나 사이즈 범위로 필터링하려면 해당 연령이나 사이즈를 선택하세요.
-
데이터 연령 그래프 - 데이터가 생성된 시간, 마지막으로 액세스된 시간 또는 마지막으로 수정된 시간을 기준으로 데이터를 분류합니다.
-
데이터 그래프의 크기 - 크기에 따라 데이터를 분류합니다.
-
|
|
데이터 소스 중 하나라도 데이터 계층화를 구현하는 경우 개체 스토리지에 이미 있는 오래된 데이터는 데이터 연령 그래프에서 식별될 수 있습니다. |