

NetApp Data Classification 에서 사용자 정의 분류 만들기
 변경 제안
변경 제안
NetApp Data Classification 하면 조직의 규제 및 준수 요구 사항에 맞는 데이터를 식별하기 위해 사용자 지정 범주 또는 개별 식별자를 생성할 수 있습니다.
데이터 분류는 범주형과 개인 식별자형, 두 가지 유형의 사용자 지정 분류기를 지원합니다. 사용자 지정 카테고리는 사용자가 업로드한 파일 세트를 기반으로 생성되며, 데이터 분류 기능은 이를 통해 조직 내 유사한 데이터를 식별하는 AI 모델을 구축합니다(예: 의료 연구 기관은 임상 분석 카테고리를 생성할 수 있습니다). 사용자 지정 개인 식별자는 키워드 목록 또는 정규 표현식(regex)을 사용하여 생성되며, 규정 준수 위험을 초래할 수 있는 조직별 특정 정보를 식별하는 데 사용됩니다.
모든 사용자 지정 분류는 사용자 지정 분류 대시보드에서 확인할 수 있습니다.
사용자 지정 개인 식별자를 생성하세요
데이터 분류 기능을 사용하면 문맥 키워드 또는 정규 표현식을 사용하여 조직 고유의 데이터를 식별하는 맞춤형 개인 식별자를 생성할 수 있습니다.
키워드 목록을 사용하여 개인 식별자를 생성하는 경우, 해당 목록은 다음 요구 사항을 충족해야 합니다.
-
키워드 입력은 대소문자를 구분하지 않습니다.
-
키워드는 최소 세 글자 이상이어야 합니다. 세 글자 미만의 단어는 모두 무시됩니다.
-
중복되는 단어는 한 번만 추가됩니다.
-
키워드 목록의 총 길이는 50만 자를 초과할 수 없습니다. 목록에는 최소 하나 이상의 키워드가 포함되어야 합니다.
-
사용자 정의 분류 탭을 선택합니다.
-
사용자 지정 분류기를 만들려면 + 새 분류기를 선택하세요.
-
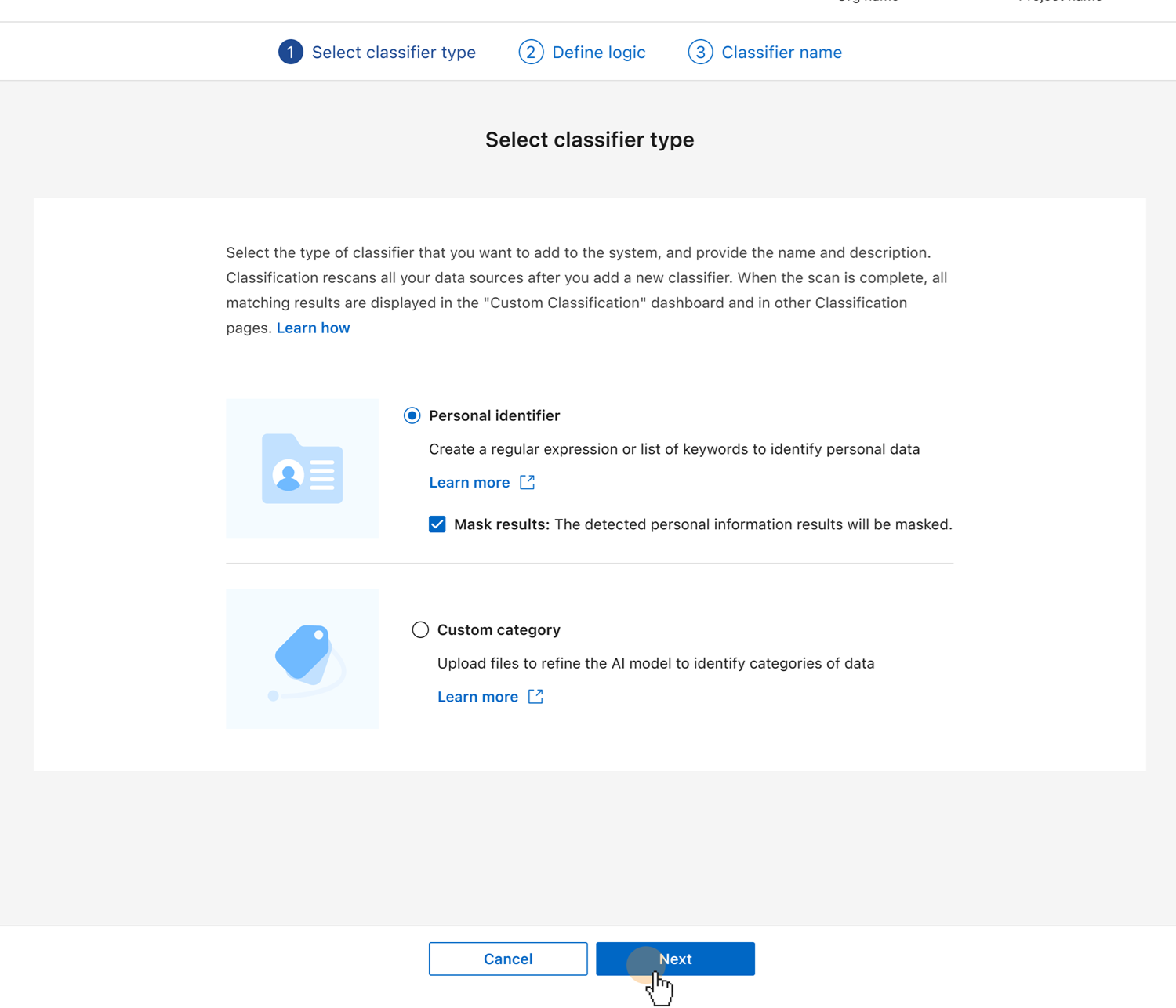
*개인 식별자*를 선택하세요. 선택적으로 결과 마스킹을 선택하여 감지된 개인 정보를 가릴 수 있습니다.
-
다음을 선택하세요.
-
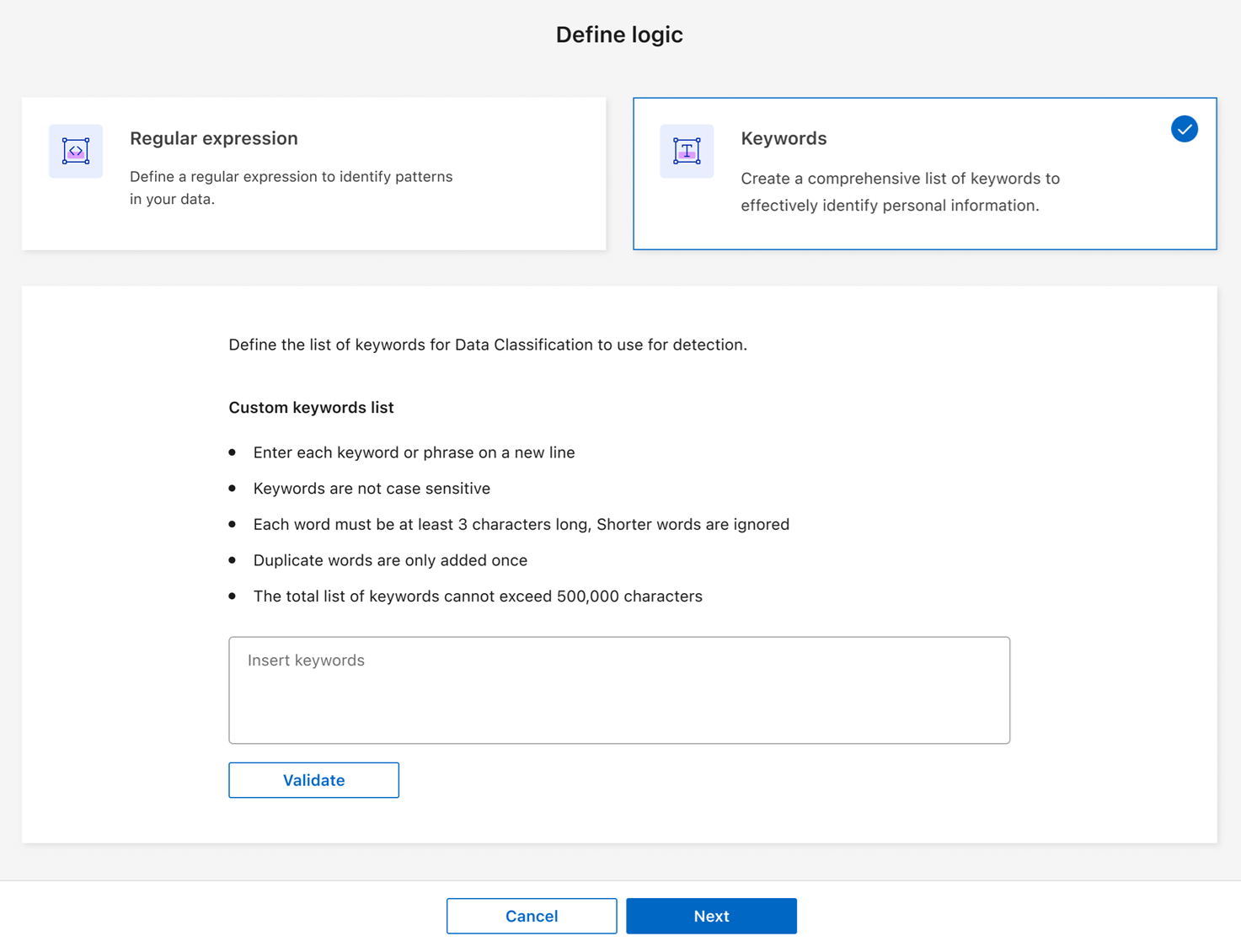
키워드를 사용하여 분류기를 추가하려면 키워드를 선택하십시오. 각 항목을 한 줄씩 입력하여 키워드 목록을 작성하세요. 키워드가 요구 사항을 충족하는지 확인하십시오.
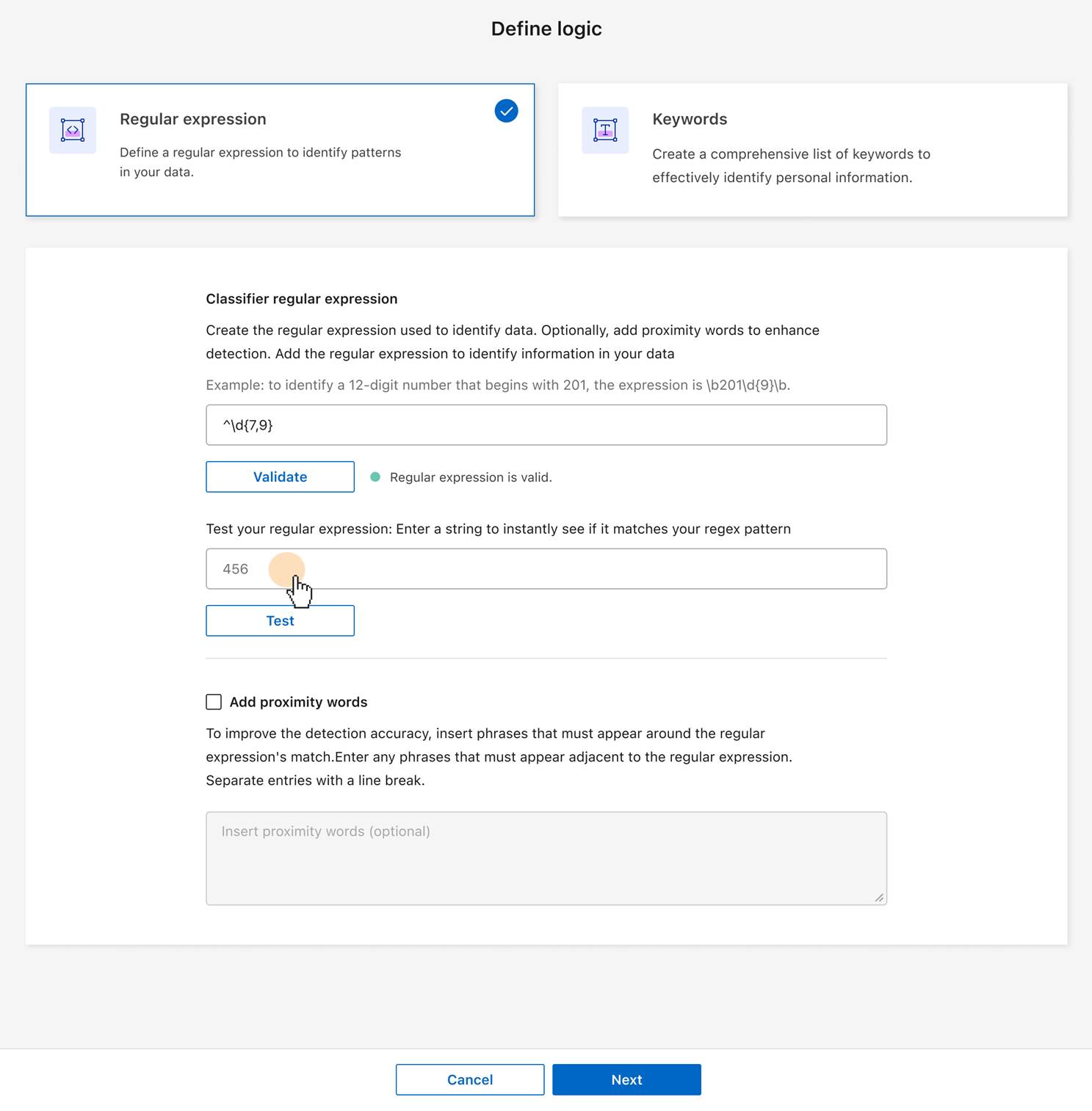
분류기를 정규 표현식으로 추가하려면 정규 표현식을 선택한 다음 데이터의 특정 정보를 감지하는 패턴을 추가하세요. 입력 내용의 구문을 확인하려면 유효성 검사를 선택하세요.
-
선택적으로, 정규 표현식 패턴과 일치해야 하는 샘플 문자열을 입력한 다음 테스트를 선택하여 확인하십시오.
-
선택적으로 근접어를 추가할 수 있습니다. 근접어를 추가하면 데이터 분류는 근접어가 일치하는 문자열에 인접해 있는 경우에만 정규 표현식 패턴에 플래그를 지정합니다.
-
-
다음을 선택하세요.
-
대시보드에서 사용자 지정 카테고리를 식별하려면 분류기 이름과 설명을 입력하세요.
-
사용자 지정 개인 식별자를 생성하려면 저장을 선택하십시오.
사용자 지정 개인 식별자를 생성하면 해당 결과가 다음 예약된 검사에 반영됩니다. 결과를 더 빨리 얻으려면 필요할 때 스캔을 실행하세요. 결과를 보려면 다음을 참조하세요. 규정 준수 보고서 생성.
사용자 지정 카테고리를 만드세요
사용자 지정 카테고리를 사용하면 조직에 특화된 데이터 분류가 가능합니다. 사용자 지정 카테고리는 사용자가 업로드한 텍스트 파일을 기반으로 생성되며, 데이터 분류 기능은 이를 바탕으로 AI 모델을 만들어 다른 파일에서 유사한 정보를 식별합니다.
-
학습 데이터 세트는 최소 25개의 파일을 포함해야 합니다. 최대 파일 개수는 1,000개입니다.
-
모든 파일은 제공하신 파일 경로에 직접 위치해야 합니다.
-
모든 파일의 크기는 100바이트보다 커야 합니다.
-
데이터 분류 학습 데이터는 CSV, DOCX, DOC, GZ, JSON, PDF, PPTX, TXT, RTT, XLS 또는 XLSX 파일 형식 중 하나여야 합니다. 지원되는 모든 파일 형식을 조합하여 업로드할 수 있습니다.
-
NetApp Data Classification 에서 *사용자 지정 분류*를 선택합니다.
-
*+ 새 분류기*를 선택하세요.
-
분류 유형으로 *사용자 지정 카테고리*를 선택한 다음 다음을 클릭하세요.
-
텍스트 기반 파일 모음을 사용하여 사용자 지정 카테고리에 대한 로직을 정의하세요. *작업 주소*의 IP 주소를 입력한 다음 드롭다운 메뉴에서 *볼륨*을 선택하십시오.
학습 데이터가 포함된 디렉터리의 디렉터리 경로를 입력하십시오.
-
파일 검사를 수행하려면 데이터 분류에서 파일 불러오기를 선택하십시오. 파일이 교육용으로 적합하다고 판단되면 파일 이름, 크기, 유형 및 참고 사항이 나열된 파일 요약을 검토할 수 있습니다.
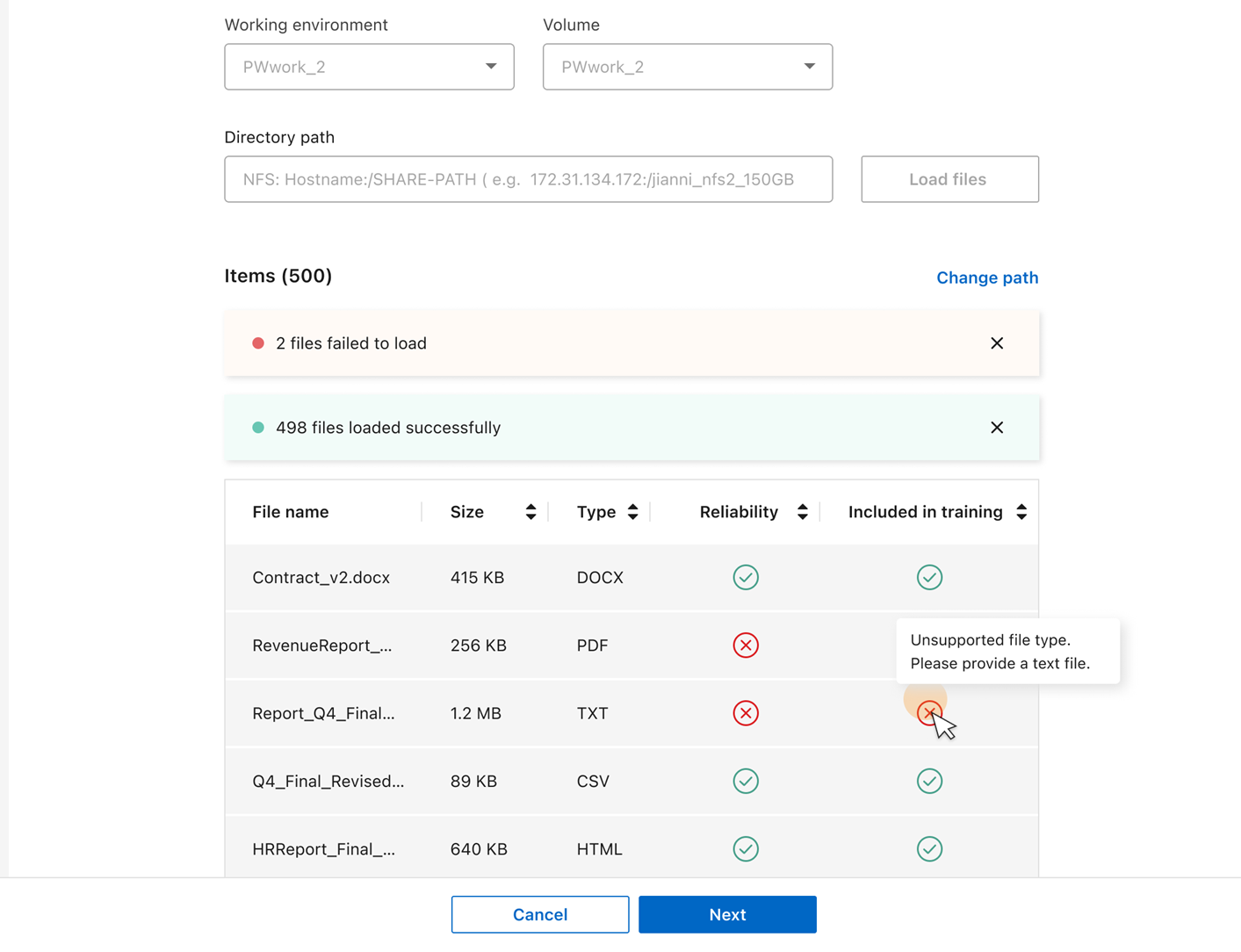
Data Classification은 데이터 학습에 필요한 예상 완료 시간을 표시합니다. .. 파일 경로를 변경하거나 파일을 다시 업로드하려면 Change path를 선택한 다음 데이터를 입력하고 파일을 다시 로드하십시오.
-
업로드된 파일에 만족하시면 다음을 선택하세요.
-
대시보드에서 사용자 지정 카테고리를 식별하려면 분류기 이름과 설명을 입력하세요.
-
저장을 선택하여 사용자 지정 카테고리를 만드세요.
사용자 지정 카테고리를 생성하면 해당 결과가 다음 예약된 스캔에 반영됩니다. 결과를 더 빨리 얻으려면 수동으로 스캔을 시작하세요.
사용자 지정 분류기를 편집합니다
개인 식별자를 생성한 후에도 해당 식별자의 로직을 수정할 수 있습니다. 개인 식별자의 유형이나 논리 유형은 변경할 수 없습니다. 예를 들어 사용자 지정 범주를 사용자 지정 개인 식별자로 변경할 수 없습니다. 키워드 기반 사용자 지정 식별자를 정규 표현식 기반 사용자 지정 식별자로 변경할 수도 없습니다.
-
NetApp Data Classification 에서 *사용자 지정 분류*를 선택합니다.
-
삭제하려는 분류기를 선택한 다음 작업 메뉴를 선택하세요.
…줄의 맨 끝에. -
논리 편집을 선택하세요.
-
키워드를 수정하려면 해당 키워드를 추가, 삭제 또는 편집하세요. 정규 표현식을 수정하는 경우 새 정규 표현식을 입력하고 유효성을 검사하십시오. 선택적으로 근접 키워드를 추가할 수 있습니다.
-
변경 사항을 적용하려면 저장을 선택하세요.
사용자 지정 분류기를 삭제합니다
-
NetApp Data Classification 에서 *사용자 지정 분류*를 선택합니다.
-
삭제하려는 분류기를 선택한 다음 작업 메뉴를 선택하세요.
…줄의 맨 끝에. -
분류자 삭제를 선택하세요.