주요 AI, ML 및 DL 사용 사례 및 아키텍처
 변경 제안
변경 제안
주요 AI, ML, DL 사용 사례와 방법론은 다음 섹션으로 나눌 수 있습니다.
Spark NLP 파이프라인 및 TensorFlow 분산 추론
다음 목록은 다양한 개발 수준에서 데이터 과학 커뮤니티에서 채택된 가장 인기 있는 오픈소스 NLP 라이브러리를 포함합니다.
-
"자연어 툴킷(NLTK)" . 모든 NLP 기술을 위한 완벽한 툴킷입니다. 2000년대 초반부터 유지되어 왔습니다.
-
"텍스트블롭" . NLTK와 Pattern을 기반으로 구축된 사용하기 쉬운 NLP 도구 Python API입니다.
-
"스탠포드 코어 NLP" . Stanford NLP Group에서 개발한 Java로 작성된 NLP 서비스와 패키지입니다.
-
"젠심" . 인간을 위한 주제 모델링은 체코 디지털 수학 도서관 프로젝트를 위한 Python 스크립트 모음으로 시작되었습니다.
-
"스파시" . GPU 가속을 탑재한 Python 및 Cython을 사용한 엔드투엔드 산업용 NLP 워크플로우로 변압기를 구현합니다.
-
"패스트텍스트" . Facebook의 AI 연구(FAIR) 랩에서 만든 단어 임베딩 학습과 문장 분류를 위한 무료, 가벼운 오픈 소스 NLP 라이브러리입니다.
Spark NLP는 모든 NLP 작업과 요구 사항을 위한 단일 통합 솔루션으로, 실제 생산 사용 사례에서 확장 가능하고 성능이 뛰어나며 정확도가 높은 NLP 기반 소프트웨어를 구현합니다. 이는 전이 학습을 활용하고 연구와 산업 전반에 걸쳐 최신 첨단 알고리즘과 모델을 구현합니다. Spark에서 위 라이브러리에 대한 완전한 지원이 부족하기 때문에 Spark NLP는 다음 라이브러리를 기반으로 구축되었습니다. "스파크 ML" 미션 크리티컬 프로덕션 워크플로를 위한 엔터프라이즈급 NLP 라이브러리로 Spark의 범용 인메모리 분산 데이터 처리 엔진을 활용합니다. 주석자는 규칙 기반 알고리즘, 머신 러닝, TensorFlow를 활용해 딥 러닝 구현을 지원합니다. 여기에는 토큰화, 레마토제닉, 어간 추출, 품사 태깅, 명명된 엔터티 인식, 철자 검사, 감정 분석 등을 포함하되 이에 국한되지 않는 일반적인 NLP 작업이 포함됩니다.
BERT(Bidirectional Encoder Representations from Transformers)는 NLP를 위한 변환기 기반 머신 러닝 기술입니다. 이를 통해 사전 학습과 미세 조정이라는 개념이 대중화되었습니다. BERT의 변환기 아키텍처는 기계 번역에서 유래되었는데, 기계 번역은 RNN(Recurrent Neural Network) 기반 언어 모델보다 장기 종속성을 더 잘 모델링합니다. 또한 모든 토큰 중 무작위로 15%를 마스크 처리하고 모델이 이를 예측하여 진정한 양방향성을 구현하는 MLM(Masked Language Modelling) 작업을 도입했습니다.
금융 감정 분석은 해당 분야의 전문 용어와 라벨이 지정된 데이터의 부족으로 인해 어렵습니다. 사전 학습된 BERT를 기반으로 하는 언어 모델인 FinBERT는 도메인에 적응되었습니다. "로이터 TRC2" , 금융 자산 및 레이블이 지정된 데이터로 미세 조정됨( "금융 문구 은행" ) 금융 감정 분류를 위해. 연구자들은 금융 용어가 포함된 뉴스 기사에서 4,500개의 문장을 추출했습니다. 그런 다음 금융 분야 경력이 있는 16명의 전문가와 석사과정 학생들이 문장을 긍정적, 중립적, 부정적으로 분류했습니다. 우리는 FinBERT와 두 개의 다른 사전 훈련된 파이프라인을 사용하여 2016년부터 2020년까지 상위 10개 NASDAQ 회사 수익 전화 회의록에 대한 감정을 분석하기 위한 종단 간 Spark 워크플로를 구축했습니다. "문서 DL 설명" ) Spark NLP에서.
Spark NLP의 기반이 되는 딥 러닝 엔진은 TensorFlow입니다. TensorFlow는 머신 러닝을 위한 종단 간 오픈 소스 플랫폼으로, 쉬운 모델 구축, 어디서나 강력한 ML 생산, 연구를 위한 강력한 실험을 가능하게 합니다. 따라서 Spark에서 파이프라인을 실행할 때 yarn cluster 모드에서는 기본적으로 하나의 마스터 노드와 여러 개의 워커 노드, 그리고 클러스터에 마운트된 네트워크 연결 스토리지에서 데이터와 모델을 병렬화하여 분산형 TensorFlow를 실행했습니다.
Horovod 분산 훈련
MapReduce 관련 성능에 대한 핵심 Hadoop 검증은 TeraGen, TeraSort, TeraValidate 및 DFSIO(읽기 및 쓰기)를 사용하여 수행됩니다. TeraGen 및 TeraSort 검증 결과는 다음과 같습니다. "Hadoop을 위한 NetApp E-Series 솔루션" AFF 의 "스토리지 계층화" 섹션에 있습니다.
고객 요청에 따라, 우리는 Spark를 활용한 분산 학습을 다양한 사용 사례 중 가장 중요한 것 중 하나로 생각합니다. 이 문서에서는 다음을 사용했습니다. "스파크의 호보로드" NetApp All Flash FAS (AFF) 스토리지 컨트롤러, Azure NetApp Files 및 StorageGRID 사용하여 NetApp 온프레미스, 클라우드 네이티브 및 하이브리드 클라우드 솔루션으로 Spark 성능을 검증합니다.
Spark 패키지의 Horovod는 Horovod를 둘러싼 편리한 래퍼를 제공하여 Spark 클러스터에서 분산형 학습 워크로드를 간편하게 실행하고, 데이터 처리, 모델 학습, 모델 평가가 모두 학습 및 추론 데이터가 있는 Spark에서 수행되는 긴밀한 모델 설계 루프를 구현합니다.
Spark에서 Horovod를 실행하기 위한 두 가지 API가 있습니다. 상위 수준 Estimator API와 하위 수준 Run API입니다. 둘 다 Spark 실행자에서 Horovod를 실행하기 위해 동일한 기본 메커니즘을 사용하지만 Estimator API는 데이터 처리, 모델 학습 루프, 모델 검사점, 메트릭 수집 및 분산 학습을 추상화합니다. 우리는 종단 간 데이터 준비 및 분산 학습 워크플로를 위해 Horovod Spark Estimators, TensorFlow 및 Keras를 사용했습니다. "Kaggle Rossmann 매장 판매" 경쟁.
대본 keras_spark_horovod_rossmann_estimator.py 섹션에서 찾을 수 있습니다"주요 사용 사례별로 Python 스크립트가 제공됩니다." 이 글은 세 부분으로 구성되어 있습니다.
-
첫 번째 부분에서는 Kaggle에서 제공하고 커뮤니티에서 수집한 초기 CSV 파일 세트에 대해 다양한 데이터 전처리 단계를 수행합니다. 입력 데이터는 다음과 같은 훈련 세트로 분리됩니다.
Validation하위 집합과 테스트 데이터 세트. -
두 번째 부분에서는 로그 시그모이드 활성화 함수와 Adam 옵티마이저를 갖춘 Keras 딥 신경망(DNN) 모델을 정의하고, Spark에서 Horovod를 사용하여 모델의 분산 학습을 수행합니다.
-
세 번째 부분에서는 검증 세트의 전체 평균 절대 오차를 최소화하는 최상의 모델을 사용하여 테스트 데이터 세트에 대한 예측을 수행합니다. 그런 다음 출력 CSV 파일을 생성합니다.
섹션을 참조하세요"머신 러닝" 다양한 런타임 비교 결과를 위해.
CTR 예측을 위한 Keras를 사용한 멀티 워커 딥 러닝
최근 ML 플랫폼과 애플리케이션이 발전함에 따라 대규모 학습에 많은 관심이 쏠리고 있습니다. 클릭률(CTR)은 온라인 광고 노출 100회당 평균 클릭 수(백분율로 표시)로 정의됩니다. 이는 디지털 마케팅, 소매, 전자상거래, 서비스 제공업체를 포함한 다양한 산업 분야와 사용 사례에서 핵심 지표로 널리 채택되고 있습니다. CTR 및 분산형 교육 성능 결과의 적용에 대한 자세한 내용은 다음을 참조하세요."CTR 예측 성능을 위한 딥러닝 모델" 부분.
이 기술 보고서에서는 다음 변형을 사용했습니다. "Criteo 테라바이트 클릭 로그 데이터 세트" (TR-4904 참조) Keras를 사용하여 다중 작업자 분산 딥 러닝을 통해 딥 및 교차 네트워크(DCN) 모델을 포함하는 Spark 워크플로를 구축하고, 로그 손실 오차 함수 측면에서 기준 Spark ML 로지스틱 회귀 모델과 성능을 비교합니다. DCN은 제한된 차수의 효과적인 기능 상호작용을 효율적으로 포착하고, 높은 비선형 상호작용을 학습하며, 수동 기능 엔지니어링이나 철저한 검색이 필요 없고, 계산 비용이 낮습니다.
웹 규모 추천 시스템에 사용되는 데이터는 대부분 이산적이고 범주형이어서 기능 탐색이 어려운 크고 희소한 기능 공간이 발생합니다. 이로 인해 대부분의 대규모 시스템은 로지스틱 회귀와 같은 선형 모델로 제한되었습니다. 그러나 자주 예측 가능한 특징을 식별하고 동시에 보이지 않거나 드문 교차 특징을 탐색하는 것이 좋은 예측을 하는 데 중요합니다. 선형 모델은 간단하고, 해석 가능하며, 확장하기 쉽지만, 표현력이 제한적입니다.
반면, 교차 특징은 모델의 표현력을 향상시키는 데 중요한 것으로 나타났습니다. 안타깝게도 이러한 기능을 식별하려면 수동 기능 엔지니어링이나 철저한 검색이 필요한 경우가 많습니다. 보이지 않는 특징의 상호작용을 일반화하는 것은 종종 어렵습니다. DCN과 같은 교차 신경망을 사용하면 자동으로 기능 교차를 명시적으로 적용하여 작업별 기능 엔지니어링을 피할 수 있습니다. 교차 네트워크는 여러 계층으로 구성되어 있으며, 가장 높은 수준의 상호작용은 계층 깊이에 의해 결정됩니다. 각 계층은 기존 계층의 상호작용을 기반으로 고차원 상호작용을 생성하고 이전 계층의 상호작용은 유지합니다.
심층 신경망(DNN)은 여러 기능 간의 매우 복잡한 상호작용을 포착할 수 있는 잠재력을 가지고 있습니다. 그러나 DCN과 비교하면 거의 10배 더 많은 매개변수가 필요하고, 교차 특징을 명확하게 형성할 수 없으며, 일부 유형의 특징 상호 작용을 효율적으로 학습하지 못할 수 있습니다. 크로스 네트워크는 메모리 효율성이 높고 구현하기 쉽습니다. 교차 분석과 DNN 구성 요소를 함께 공동으로 훈련하면 예측 기능 상호작용을 효율적으로 포착하고 Criteo CTR 데이터 세트에서 최첨단 성능을 제공합니다.
DCN 모델은 임베딩 및 스태킹 계층으로 시작하여, 이어서 교차 네트워크와 딥 네트워크가 병렬로 이어집니다. 이어서 두 네트워크의 출력을 결합하는 최종 결합 계층이 이어집니다. 입력 데이터는 희소 특성과 밀집 특성을 모두 갖춘 벡터일 수 있습니다. Spark에서는 라이브러리에 다음 유형이 포함되어 있습니다. SparseVector . 따라서 사용자는 두 가지를 구별하고 각각의 함수와 메서드를 호출할 때 주의하는 것이 중요합니다. CTR 예측과 같은 웹 규모 추천 시스템에서 입력은 대부분 범주형 기능입니다. 'country=usa' . 이러한 기능은 종종 원핫 벡터로 인코딩됩니다. 예를 들어, '[0,1,0, …]' . One-hot-encoding(OHE) SparseVector 끊임없이 변화하고 증가하는 어휘를 포함하는 실제 데이터 세트를 다룰 때 유용합니다. 우리는 예를 수정했습니다 "딥CTR" 대규모 어휘를 처리하여 DCN의 임베딩 및 스태킹 계층에서 임베딩 벡터를 생성합니다.
그만큼 "Criteo 디스플레이 광고 데이터 세트" 광고 클릭률을 예측합니다. 13개의 정수 특성과 26개의 범주형 특성이 있으며, 각 범주는 높은 카디널리티를 갖습니다. 이 데이터 세트의 경우 입력 크기가 크기 때문에 logloss가 0.001 향상되는 것은 실질적으로 의미가 있습니다. 대규모 사용자 기반의 예측 정확도가 약간만 향상되어도 회사 수익이 크게 증가할 가능성이 있습니다. 이 데이터 세트에는 7일간의 사용자 로그 11GB가 포함되어 있으며, 이는 약 4,100만 개의 레코드에 해당합니다. 우리는 Spark를 사용했습니다 dataFrame.randomSplit()function 데이터를 무작위로 분할하여 학습(80%), 교차 검증(10%), 나머지 10%를 테스트에 사용합니다.
DCN은 Keras를 사용하여 TensorFlow에서 구현되었습니다. DCN을 사용하여 모델 학습 프로세스를 구현하는 데는 4가지 주요 구성 요소가 있습니다.
-
데이터 처리 및 임베딩. 실수 값의 특징은 로그 변환을 적용하여 정규화됩니다. 범주형 특성의 경우 차원 6×(범주 카디널리티)1/4의 밀집 벡터에 특성을 포함합니다. 모든 임베딩을 연결하면 차원이 1026인 벡터가 생성됩니다.
-
최적화. 우리는 Adam 최적화 도구를 사용하여 미니 배치 확률적 최적화를 적용했습니다. 배치 크기는 512로 설정되었습니다. 딥 네트워크에 배치 정규화를 적용하고 그래디언트 클립 노름을 100으로 설정했습니다.
-
정규화. L2 정규화나 드롭아웃이 효과적이지 않은 것으로 나타났기 때문에 조기 중단을 사용했습니다.
-
하이퍼매개변수 우리는 숨겨진 계층의 수, 숨겨진 계층의 크기, 초기 학습률, 교차 계층의 수에 대한 그리드 검색을 기반으로 결과를 보고합니다. 숨겨진 레이어의 수는 2~5개이고, 숨겨진 레이어의 크기는 32~1024개입니다. DCN의 경우 교차 레이어의 수는 1~6입니다. 초기 학습률은 0.0001에서 0.001까지 0.0001씩 증가하며 조정되었습니다. 모든 실험은 150,000번째 훈련 단계에서 조기에 중단되었으며, 그 단계를 넘어서면 과잉 맞춤이 발생하기 시작했습니다.
검증에 사용되는 아키텍처
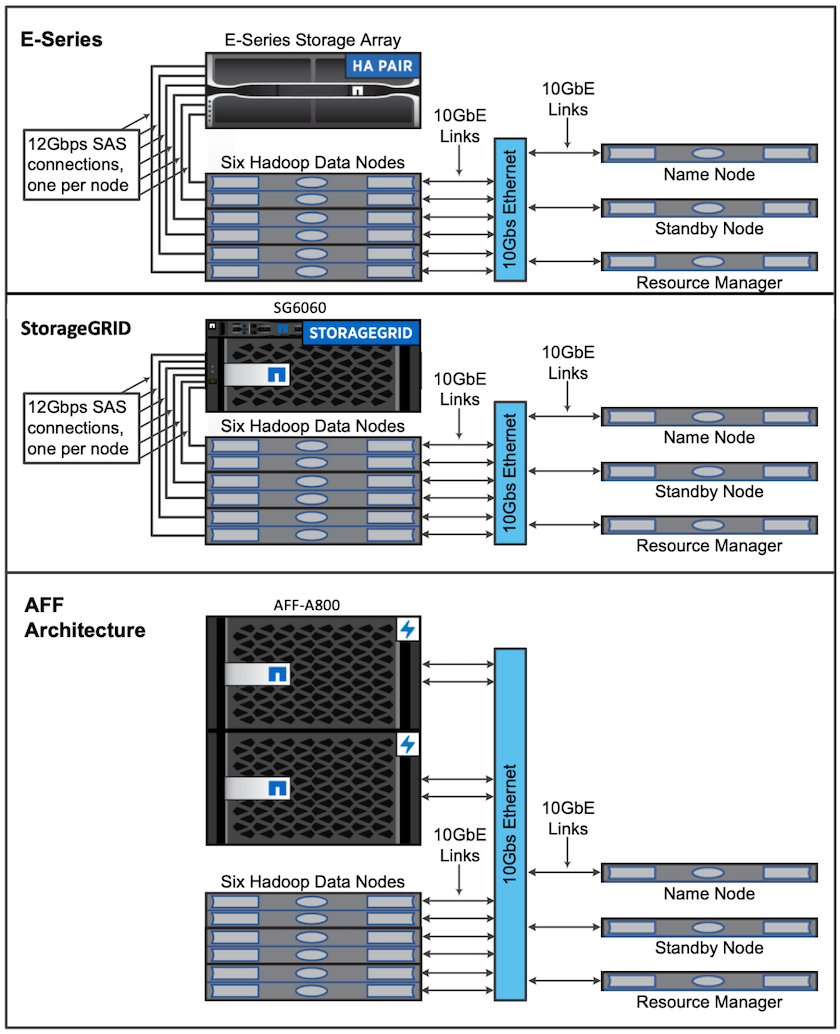
이러한 검증을 위해 우리는 AFF-A800 HA 쌍을 갖춘 4개의 워커 노드와 1개의 마스터 노드를 사용했습니다. 모든 클러스터 구성원은 10GbE 네트워크 스위치를 통해 연결되었습니다.
이 NetApp Spark 솔루션 검증을 위해 E5760, E5724, AFF-A800의 세 가지 스토리지 컨트롤러를 사용했습니다. E-시리즈 스토리지 컨트롤러는 12Gbps SAS 연결을 통해 5개의 데이터 노드에 연결되었습니다. AFF HA 쌍 스토리지 컨트롤러는 10GbE 연결을 통해 Hadoop 워커 노드에 내보낸 NFS 볼륨을 제공합니다. Hadoop 클러스터 멤버는 E-Series, AFF 및 StorageGRID Hadoop 솔루션에서 10GbE 연결을 통해 연결되었습니다.