

동기식 분산 AI 워크로드 실행
 변경 제안
변경 제안
Kubernetes 클러스터에서 동기식 멀티노드 AI 및 ML 작업을 실행하려면 배포 점프 호스트에서 다음 작업을 수행하세요. 이 프로세스를 사용하면 NetApp 볼륨에 저장된 데이터를 활용하고 단일 작업자 노드가 제공할 수 있는 것보다 많은 GPU를 사용할 수 있습니다. 동기식 분산 AI 작업을 묘사한 다음 그림을 참조하세요.

|
동기 분산 작업은 비동기 분산 작업에 비해 성능과 교육 정확도를 높이는 데 도움이 될 수 있습니다. 동기 작업과 비동기 작업의 장단점에 대한 논의는 이 문서의 범위를 벗어납니다. |
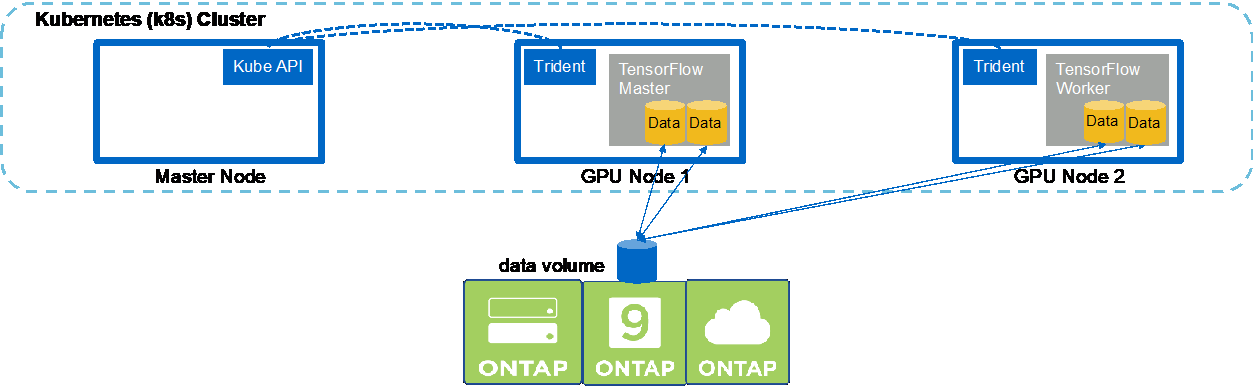
-
다음 예제 명령은 섹션의 예제에서 단일 노드에서 실행된 동일한 TensorFlow 벤치마크 작업의 동기 분산 실행에 참여하는 하나의 작업자 생성을 보여줍니다."단일 노드 AI 워크로드 실행" . 이 특정 예에서 작업은 두 개의 작업자 노드에서 실행되므로 단일 작업자만 배포됩니다.
이 예제 워커 배포에서는 8개의 GPU를 요청하므로 8개 이상의 GPU가 있는 단일 GPU 워커 노드에서 실행될 수 있습니다. GPU 워커 노드에 8개 이상의 GPU가 있는 경우 성능을 극대화하려면 워커 노드가 제공하는 GPU 수와 같도록 이 숫자를 늘리는 것이 좋습니다. Kubernetes 배포에 대한 자세한 내용은 다음을 참조하세요. "공식 Kubernetes 문서" .
이 예에서는 특정 컨테이너화된 작업자가 스스로 완료될 수 없기 때문에 Kubernetes 배포가 생성됩니다. 따라서 Kubernetes 작업 구조를 사용하여 배포하는 것은 의미가 없습니다. 작업자가 자체적으로 완료되도록 설계되거나 작성된 경우, 작업 구성을 사용하여 작업자를 배치하는 것이 합리적일 수 있습니다.
이 예제 배포 사양에 지정된 포드는 다음과 같습니다.
hostNetwork의 가치true. 이 값은 Kubernetes가 일반적으로 각 Pod에 대해 생성하는 가상 네트워킹 스택 대신, Pod가 호스트 워커 노드의 네트워킹 스택을 사용한다는 것을 의미합니다. 이 주석이 사용되는 이유는 특정 워크로드가 동기식 분산 방식으로 워크로드를 실행하기 위해 Open MPI, NCCL 및 Horovod에 의존하기 때문입니다. 따라서 호스트 네트워킹 스택에 액세스해야 합니다. Open MPI, NCCL, Horovod에 대한 논의는 이 문서의 범위를 벗어납니다. 이것이든 아니든hostNetwork: true주석이 필요한지는 실행 중인 특정 작업 부하의 요구 사항에 따라 달라집니다. 자세한 내용은hostNetwork필드에서 확인하세요 "공식 Kubernetes 문서" .$ cat << EOF > ./netapp-tensorflow-multi-imagenet-worker.yaml apiVersion: apps/v1 kind: Deployment metadata: name: netapp-tensorflow-multi-imagenet-worker spec: replicas: 1 selector: matchLabels: app: netapp-tensorflow-multi-imagenet-worker template: metadata: labels: app: netapp-tensorflow-multi-imagenet-worker spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["bash", "/netapp/scripts/start-slave-multi.sh", "22122"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-worker.yaml deployment.apps/netapp-tensorflow-multi-imagenet-worker created $ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 4s -
1단계에서 생성한 작업자 배포가 성공적으로 시작되었는지 확인하세요. 다음 예제 명령은 배포 정의에 표시된 대로 배포에 대해 단일 워커 포드가 생성되었으며, 이 포드가 현재 GPU 워커 노드 중 하나에서 실행 중인지 확인합니다.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 60s 10.61.218.154 10.61.218.154 <none> $ kubectl logs netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 22122
-
동기식 멀티노드 작업을 시작하고, 참여하고, 실행을 추적하는 마스터에 대한 Kubernetes 작업을 만듭니다. 다음 예제 명령은 예제 섹션의 단일 노드에서 실행된 동일한 TensorFlow 벤치마크 작업의 동기 분산 실행을 시작하고 참여하고 추적하는 하나의 마스터를 생성합니다."단일 노드 AI 워크로드 실행" .
이 예제 마스터 작업은 8개의 GPU를 요청하므로 8개 이상의 GPU가 있는 단일 GPU 워커 노드에서 실행될 수 있습니다. GPU 워커 노드에 8개 이상의 GPU가 있는 경우 성능을 극대화하려면 워커 노드가 제공하는 GPU 수와 같도록 이 숫자를 늘리는 것이 좋습니다.
이 예제 작업 정의에 지정된 마스터 포드에는 다음이 제공됩니다.
hostNetwork의 가치true, 작업자 포드에 다음과 같은 것이 주어진 것처럼hostNetwork의 가치true1단계에서. 이 값이 필요한 이유에 대한 자세한 내용은 1단계를 참조하세요.$ cat << EOF > ./netapp-tensorflow-multi-imagenet-master.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-tensorflow-multi-imagenet-master spec: backoffLimit: 5 template: spec: hostNetwork: true volumes: - name: dshm emptyDir: medium: Memory - name: testdata-iface1 persistentVolumeClaim: claimName: pb-fg-all-iface1 - name: testdata-iface2 persistentVolumeClaim: claimName: pb-fg-all-iface2 - name: results persistentVolumeClaim: claimName: tensorflow-results containers: - name: netapp-tensorflow-py2 image: netapp/tensorflow-py2:19.03.0 command: ["python", "/netapp/scripts/run.py", "--dataset_dir=/mnt/mount_0/dataset/imagenet", "--port=22122", "--num_devices=16", "--dgx_version=dgx1", "--nodes=10.61.218.152,10.61.218.154"] resources: limits: nvidia.com/gpu: 8 volumeMounts: - mountPath: /dev/shm name: dshm - mountPath: /mnt/mount_0 name: testdata-iface1 - mountPath: /mnt/mount_1 name: testdata-iface2 - mountPath: /tmp name: results securityContext: privileged: true restartPolicy: Never EOF $ kubectl create -f ./netapp-tensorflow-multi-imagenet-master.yaml job.batch/netapp-tensorflow-multi-imagenet-master created $ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 0/1 25s 25s -
3단계에서 생성한 마스터 작업이 올바르게 실행되는지 확인하세요. 다음 예제 명령은 작업 정의에 표시된 대로 작업에 대한 단일 마스터 포드가 생성되었으며, 이 포드가 현재 GPU 워커 노드 중 하나에서 실행 중인지 확인합니다. 1단계에서 처음 본 워커 포드가 여전히 실행 중인지, 마스터 포드와 워커 포드가 다른 노드에서 실행 중인지도 확인해야 합니다.
$ kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE netapp-tensorflow-multi-imagenet-master-ppwwj 1/1 Running 0 45s 10.61.218.152 10.61.218.152 <none> netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 26m 10.61.218.154 10.61.218.154 <none>
-
3단계에서 생성한 마스터 작업이 성공적으로 완료되는지 확인하세요. 다음 예제 명령은 작업이 성공적으로 완료되었음을 확인합니다.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 9m18s $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 9m38s netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 35m $ kubectl logs netapp-tensorflow-multi-imagenet-master-ppwwj [10.61.218.152:00008] WARNING: local probe returned unhandled shell:unknown assuming bash rm: cannot remove '/lib': Is a directory [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.154:00033] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 702 [10.61.218.152:00008] PMIX ERROR: NO-PERMISSIONS in file gds_dstore.c at line 711 Total images/sec = 12881.33875 ================ Clean Cache !!! ================== mpirun -allow-run-as-root -np 2 -H 10.61.218.152:1,10.61.218.154:1 -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" bash -c 'sync; echo 1 > /proc/sys/vm/drop_caches' ========================================= mpirun -allow-run-as-root -np 16 -H 10.61.218.152:8,10.61.218.154:8 -bind-to none -map-by slot -x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH -mca pml ob1 -mca btl ^openib -mca btl_tcp_if_include enp1s0f0 -x NCCL_IB_HCA=mlx5 -x NCCL_NET_GDR_READ=1 -x NCCL_IB_SL=3 -x NCCL_IB_GID_INDEX=3 -x NCCL_SOCKET_IFNAME=enp5s0.3091,enp12s0.3092,enp132s0.3093,enp139s0.3094 -x NCCL_IB_CUDA_SUPPORT=1 -mca orte_base_help_aggregate 0 -mca plm_rsh_agent ssh -mca plm_rsh_args "-p 22122" python /netapp/tensorflow/benchmarks_190205/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --model=resnet50 --batch_size=256 --device=gpu --force_gpu_compatible=True --num_intra_threads=1 --num_inter_threads=48 --variable_update=horovod --batch_group_size=20 --num_batches=500 --nodistortions --num_gpus=1 --data_format=NCHW --use_fp16=True --use_tf_layers=False --data_name=imagenet --use_datasets=True --data_dir=/mnt/mount_0/dataset/imagenet --datasets_parallel_interleave_cycle_length=10 --datasets_sloppy_parallel_interleave=False --num_mounts=2 --mount_prefix=/mnt/mount_%d --datasets_prefetch_buffer_size=2000 -- datasets_use_prefetch=True --datasets_num_private_threads=4 --horovod_device=gpu > /tmp/20190814_161609_tensorflow_horovod_rdma_resnet50_gpu_16_256_b500_imagenet_nodistort_fp16_r10_m2_nockpt.txt 2>&1
-
더 이상 필요하지 않으면 작업자 배포를 삭제하세요. 다음 예제 명령은 1단계에서 생성된 작업자 배포 개체를 삭제하는 방법을 보여줍니다.
워커 배포 객체를 삭제하면 쿠버네티스는 연관된 모든 워커 포드를 자동으로 삭제합니다.
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE netapp-tensorflow-multi-imagenet-worker 1 1 1 1 43m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 17m netapp-tensorflow-multi-imagenet-worker-654fc7f486-v6725 1/1 Running 0 43m $ kubectl delete deployment netapp-tensorflow-multi-imagenet-worker deployment.extensions "netapp-tensorflow-multi-imagenet-worker" deleted $ kubectl get deployments No resources found. $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 18m
-
선택 사항: 마스터 작업 아티팩트를 정리합니다. 다음 예제 명령은 3단계에서 생성된 마스터 작업 개체를 삭제하는 방법을 보여줍니다.
마스터 작업 객체를 삭제하면 Kubernetes는 연관된 모든 마스터 포드를 자동으로 삭제합니다.
$ kubectl get jobs NAME COMPLETIONS DURATION AGE netapp-tensorflow-multi-imagenet-master 1/1 5m50s 19m $ kubectl get pods NAME READY STATUS RESTARTS AGE netapp-tensorflow-multi-imagenet-master-ppwwj 0/1 Completed 0 19m $ kubectl delete job netapp-tensorflow-multi-imagenet-master job.batch "netapp-tensorflow-multi-imagenet-master" deleted $ kubectl get jobs No resources found. $ kubectl get pods No resources found.