

ONTAP에서 MetroCluster FC 소프트웨어 구성
 변경 제안
변경 제안
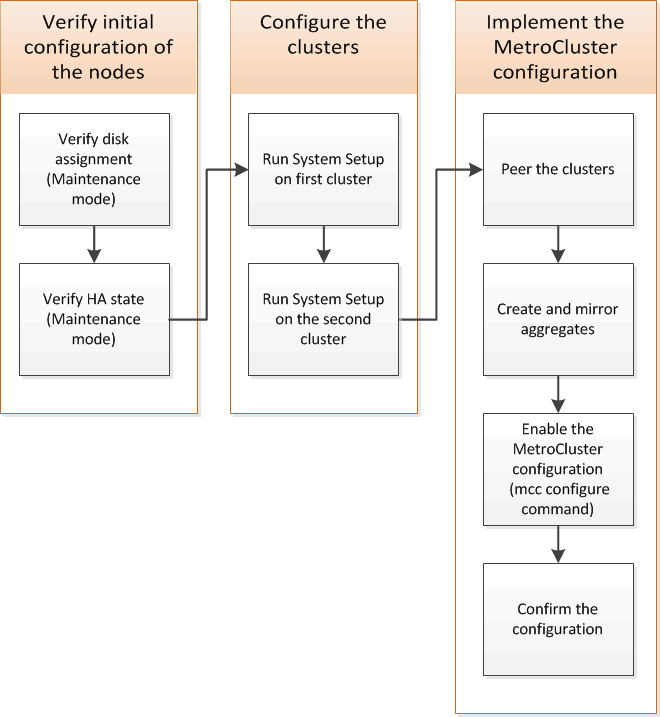
ONTAP의 MetroCluster FC 구성에서 각 노드를 설정해야 합니다. 여기에는 노드 수준 구성과 두 사이트로의 노드 구성이 포함됩니다. 또한 두 사이트 간의 MetroCluster 관계를 구현해야 합니다.
필요한 정보를 수집하는 중입니다
구성 프로세스를 시작하기 전에 컨트롤러 모듈에 필요한 IP 주소를 수집해야 합니다.
사이트 A의 IP 네트워크 정보 워크시트입니다
시스템을 구성하기 전에 네트워크 관리자로부터 첫 번째 MetroCluster 사이트(사이트 A)에 대한 IP 주소 및 기타 네트워크 정보를 얻어야 합니다.
사이트 A 스위치 정보(스위치 클러스터)
시스템에 케이블을 연결할 때는 각 클러스터 스위치에 대한 호스트 이름과 관리 IP 주소가 필요합니다. 스위치가 없는 2노드 클러스터를 사용하거나 2노드 MetroCluster 구성(각 사이트에 1개 노드)을 사용하는 경우에는 이 정보가 필요하지 않습니다.
클러스터 스위치 |
호스트 이름입니다 |
IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
상호 연결 1 |
||||
상호 연결 2 |
||||
관리 1 |
||||
관리 2 |
사이트 A 클러스터 생성 정보입니다
클러스터를 처음 생성할 때 다음 정보가 필요합니다.
정보 유형입니다 |
당신의 가치 |
클러스터 이름입니다 이 절차에서 사용되는 예: site_a |
|
DNS 도메인입니다 |
|
DNS 이름 서버 |
|
위치 |
|
관리자 암호입니다 |
사이트 A 노드 정보입니다
클러스터의 각 노드에 대해 관리 IP 주소, 네트워크 마스크 및 기본 게이트웨이가 필요합니다.
노드 |
포트 |
IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
노드 1 이 절차에서 사용되는 예: controller_a_1 |
||||
노드 2 2노드 MetroCluster 구성(각 사이트에 1개 노드)을 사용하는 경우에는 필요하지 않습니다. 이 절차에서 사용되는 예: controller_a_2 |
사이트 A 클러스터 피어링을 위한 LIF 및 포트
클러스터의 각 노드에 대해 네트워크 마스크와 기본 게이트웨이를 포함하여 2개의 인터클러스터 LIF의 IP 주소가 필요합니다. 인터클러스터 LIF는 클러스터를 피어로 사용하는 데 사용됩니다.
노드 |
포트 |
인터클러스터 LIF의 IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
노드 1 IC LIF 1 |
||||
노드 1 IC LIF 2 |
||||
노드 2 IC LIF 1 2노드 MetroCluster 구성에는 필요하지 않습니다(각 사이트에 1개 노드). |
||||
노드 2 IC LIF 2 2노드 MetroCluster 구성에는 필요하지 않습니다(각 사이트에 1개 노드). |
Site A 시간 서버 정보입니다
하나 이상의 NTP 시간 서버가 필요한 시간을 동기화해야 합니다.
노드 |
호스트 이름입니다 |
IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
NTP 서버 1 |
||||
NTP 서버 2 |
사이트 A nbsp;AutoSupport 정보
각 노드에서 AutoSupport를 구성해야 하며 여기에는 다음 정보가 필요합니다.
정보 유형입니다 |
당신의 가치 |
|
보낸 사람 이메일 주소 |
메일 호스트입니다 |
|
IP 주소 또는 이름입니다 |
전송 프로토콜 |
|
HTTP, HTTPS 또는 SMTP |
프록시 서버 |
|
받는 사람 전자 메일 주소 또는 메일 그룹 |
전체 길이 메시지 |
|
간결한 메시지 |
||
사이트 A nbsp;SP 정보
문제 해결 및 유지 관리를 위해 각 노드의 서비스 프로세서(SP)에 대한 액세스를 설정해야 하며, 이때 각 노드에 대해 다음 네트워크 정보가 필요합니다.
노드 |
IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
노드 1 |
|||
노드 2 2노드 MetroCluster 구성에는 필요하지 않습니다(각 사이트에 1개 노드). |
사이트 B에 대한 IP 네트워크 정보 워크시트입니다
시스템을 구성하기 전에 네트워크 관리자로부터 두 번째 MetroCluster 사이트(사이트 B)에 대한 IP 주소 및 기타 네트워크 정보를 얻어야 합니다.
사이트 B 스위치 정보(스위치 클러스터)
시스템에 케이블을 연결할 때는 각 클러스터 스위치에 대한 호스트 이름과 관리 IP 주소가 필요합니다. 스위치가 없는 2노드 클러스터를 사용하거나 2노드 MetroCluster 구성(각 사이트에 1개 노드)을 사용하는 경우에는 이 정보가 필요하지 않습니다.
클러스터 스위치 |
호스트 이름입니다 |
IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
상호 연결 1 |
||||
상호 연결 2 |
||||
관리 1 |
||||
관리 2 |
사이트 B 클러스터 생성 정보
클러스터를 처음 생성할 때 다음 정보가 필요합니다.
정보 유형입니다 |
당신의 가치 |
클러스터 이름입니다 이 절차에서 사용된 예: site_B |
|
DNS 도메인입니다 |
|
DNS 이름 서버 |
|
위치 |
|
관리자 암호입니다 |
사이트 B 노드 정보
클러스터의 각 노드에 대해 관리 IP 주소, 네트워크 마스크 및 기본 게이트웨이가 필요합니다.
노드 |
포트 |
IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
노드 1 이 절차에서 사용된 예: controller_B_1 |
||||
노드 2 2노드 MetroCluster 구성에는 필요하지 않습니다(각 사이트에 1개 노드). 이 절차에서 사용된 예: controller_B_2 |
사이트 B 클러스터 피어링을 위한 LIF 및 포트
클러스터의 각 노드에 대해 네트워크 마스크와 기본 게이트웨이를 포함하여 2개의 인터클러스터 LIF의 IP 주소가 필요합니다. 인터클러스터 LIF는 클러스터를 피어로 사용하는 데 사용됩니다.
노드 |
포트 |
인터클러스터 LIF의 IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
노드 1 IC LIF 1 |
||||
노드 1 IC LIF 2 |
||||
노드 2 IC LIF 1 2노드 MetroCluster 구성에는 필요하지 않습니다(각 사이트에 1개 노드). |
||||
노드 2 IC LIF 2 2노드 MetroCluster 구성에는 필요하지 않습니다(각 사이트에 1개 노드). |
사이트 B 시간 서버 정보
하나 이상의 NTP 시간 서버가 필요한 시간을 동기화해야 합니다.
노드 |
호스트 이름입니다 |
IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
NTP 서버 1 |
||||
NTP 서버 2 |
사이트 B nbsp;AutoSupport 정보
각 노드에서 AutoSupport를 구성해야 하며 여기에는 다음 정보가 필요합니다.
정보 유형입니다 |
당신의 가치 |
|
보낸 사람 이메일 주소 |
||
메일 호스트입니다 |
IP 주소 또는 이름입니다 |
|
전송 프로토콜 |
HTTP, HTTPS 또는 SMTP |
|
프록시 서버 |
받는 사람 전자 메일 주소 또는 메일 그룹 |
|
전체 길이 메시지 |
간결한 메시지 |
|
파트너가 재판매할 수 있습니다 |
||
사이트 B nbsp;SP 정보
문제 해결 및 유지 관리를 위해 각 노드의 서비스 프로세서(SP)에 대한 액세스를 설정해야 하며, 이때 각 노드에 대해 다음 네트워크 정보가 필요합니다.
노드 |
IP 주소입니다 |
네트워크 마스크 |
기본 게이트웨이 |
노드 1(controller_B_1) |
|||
노드 2(컨트롤러_B_2) 2노드 MetroCluster 구성에는 필요하지 않습니다(각 사이트에 1개 노드). |
표준 클러스터와 MetroCluster 구성의 유사점과 차이점
MetroCluster 구성에서 각 클러스터의 노드 구성은 표준 클러스터의 노드 구성과 비슷합니다.
MetroCluster 구성은 2개의 표준 클러스터를 기반으로 합니다. 물리적으로 구성은 동일한 하드웨어 구성을 갖는 각 노드에 대칭적이어야 하며, 모든 MetroCluster 구성요소를 케이블로 연결하고 구성해야 합니다. 그러나 MetroCluster 구성에서 노드의 기본 소프트웨어 구성은 표준 클러스터의 노드의 구성과 동일합니다.
구성 단계 |
표준 클러스터 구성 |
MetroCluster 구성 |
각 노드에서 관리, 클러스터 및 데이터 LIF를 구성합니다. |
두 클러스터 유형에서도 동일합니다 |
|
루트 애그리게이트 구성 |
두 클러스터 유형에서도 동일합니다 |
|
클러스터의 노드를 HA 쌍으로 구성합니다 |
두 클러스터 유형에서도 동일합니다 |
|
클러스터의 한 노드에서 클러스터 설정 |
두 클러스터 유형에서도 동일합니다 |
|
다른 노드를 클러스터에 연결합니다. |
두 클러스터 유형에서도 동일합니다 |
|
미러링된 루트 애그리게이트를 생성합니다. |
선택 사항 |
필수 요소입니다 |
클러스터를 피합니다. |
선택 사항 |
필수 요소입니다 |
MetroCluster 구성을 활성화합니다. |
적용되지 않습니다 |
필수 요소입니다 |
유지보수 모드에서 구성요소의 HA 상태 확인 및 구성
MetroCluster FC 구성에서 스토리지 시스템을 구성할 경우 컨트롤러 모듈 및 섀시 구성 요소의 HA(고가용성) 상태가 MCC 또는 MCC-2n인지 확인하여 구성 요소가 올바르게 부팅되도록 해야 합니다. 이 값은 공장에서 받은 시스템에서 미리 구성되어야 하지만 계속하기 전에 설정을 확인해야 합니다.

|
컨트롤러 모듈 및 섀시의 HA 상태가 잘못된 경우 노드를 다시 초기화하지 않고 MetroCluster을 구성할 수 없습니다. 이 절차를 사용하여 설정을 수정한 후 다음 절차 중 하나를 사용하여 시스템을 초기화해야 합니다.
|
시스템이 유지 관리 모드인지 확인합니다.
-
유지보수 모드에서 컨트롤러 모듈 및 섀시의 HA 상태를 표시합니다.
하구성 쇼
올바른 HA 상태는 MetroCluster 구성에 따라 다릅니다.
MetroCluster 구성 유형입니다
모든 구성 요소의 HA 상태…
8 또는 4노드 MetroCluster FC 구성
MCC
2노드 MetroCluster FC 구성
MCC - 2n
8 또는 4노드 MetroCluster IP 구성
mcip
-
컨트롤러의 표시된 시스템 상태가 올바르지 않으면 컨트롤러 모듈의 구성에 맞는 올바른 HA 상태를 설정합니다.
MetroCluster 구성 유형입니다
명령
8 또는 4노드 MetroCluster FC 구성
하구성 수정 컨트롤러 MCC
2노드 MetroCluster FC 구성
ha-config modify controller MCC-2n
8 또는 4노드 MetroCluster IP 구성
ha-config modify controller mcip.(컨트롤러 mccip 수정
-
섀시의 표시된 시스템 상태가 올바르지 않은 경우 섀시 구성에 대한 올바른 HA 상태를 설정합니다.
MetroCluster 구성 유형입니다
명령
8 또는 4노드 MetroCluster FC 구성
하구성 수정 새시 MCC
2노드 MetroCluster FC 구성
ha-config modify chassis MCC-2n
8 또는 4노드 MetroCluster IP 구성
ha-config modify chassis mccip.(섀시 mcip 수정
-
노드를 ONTAP로 부팅합니다.
부트 ONTAP
-
이 전체 절차를 반복하여 MetroCluster 구성의 각 노드에서 HA 상태를 확인합니다.
시스템 기본값을 복원하고 컨트롤러 모듈에서 HBA 유형을 구성합니다
MetroCluster를 성공적으로 설치하려면 컨트롤러 모듈에서 기본값을 재설정 및 복원합니다.
이 작업은 FC-to-SAS 브리지를 사용하는 확장 구성에만 필요합니다.
-
LOADER 프롬프트에서 환경 변수를 기본 설정으로 되돌립니다.
세트 기본값
-
노드를 유지 관리 모드로 부팅한 다음 시스템에 있는 모든 HBA에 대한 설정을 구성합니다.
-
유지보수 모드로 부팅:
boot_ONTAP maint를 선택합니다
-
포트의 현재 설정을 확인합니다.
'ucadmin 쇼'
-
필요에 따라 포트 설정을 업데이트합니다.
이 유형의 HBA와 원하는 모드가 있는 경우…
이 명령 사용…
CNA FC
'ucadmin modify -m fc -t initiator_adapter_name_'
CNA 이더넷
'ucadmin modify-mode CNA_adapter_name _'
FC 타겟
'fcadmin config -t target_adapter_name_'
FC 이니시에이터
'fcadmin config -t initiator_adapter_name_'
-
-
유지 관리 모드 종료:
"중지"
명령을 실행한 후 LOADER 프롬프트에서 노드가 중지될 때까지 기다립니다.
-
노드를 유지보수 모드로 다시 부팅하여 구성 변경 사항이 적용되도록 합니다.
boot_ONTAP maint를 선택합니다
-
변경 사항을 확인합니다.
이 유형의 HBA가 있는 경우…
이 명령 사용…
CNA
'ucadmin 쇼'
FC
fcadmin 쇼
-
유지 관리 모드 종료:
"중지"
명령을 실행한 후 LOADER 프롬프트에서 노드가 중지될 때까지 기다립니다.
-
노드를 부팅 메뉴로 부팅합니다.
boot_ontap 메뉴
명령을 실행한 후 부팅 메뉴가 표시될 때까지 기다립니다.
-
부팅 메뉴 프롬프트에 ""wpeconfig""를 입력하여 노드 구성을 지우고 Enter 키를 누릅니다.
다음 화면에는 부팅 메뉴 프롬프트가 표시됩니다.
Please choose one of the following:
(1) Normal Boot.
(2) Boot without /etc/rc.
(3) Change password.
(4) Clean configuration and initialize all disks.
(5) Maintenance mode boot.
(6) Update flash from backup config.
(7) Install new software first.
(8) Reboot node.
(9) Configure Advanced Drive Partitioning.
Selection (1-9)? wipeconfig
This option deletes critical system configuration, including cluster membership.
Warning: do not run this option on a HA node that has been taken over.
Are you sure you want to continue?: yes
Rebooting to finish wipeconfig request.
FAS8020 시스템에서 X1132A-R6 4중 포트 카드의 FC-VI 포트를 구성합니다
FAS8020 시스템에서 X1132A-R6 4포트 카드를 사용하는 경우, 유지 관리 모드로 전환하여 FC-VI 및 이니시에이터 사용을 위한 1a 및 1b 포트를 구성할 수 있습니다. 출하 시 받은 MetroCluster 시스템에는 필요하지 않으며, 이 경우 포트가 구성에 맞게 적절하게 설정됩니다.
이 작업은 유지보수 모드에서 수행해야 합니다.

|
ucadmin 명령을 사용하여 FC 포트를 FC-VI 포트로 변환하는 작업은 FAS8020 및 AFF 8020 시스템에서만 지원됩니다. 다른 플랫폼에서는 FC 포트를 FCVI 포트로 변환할 수 없습니다. |
-
포트 비활성화:
'스토리지 비활성화 어댑터 1a'
'스토리지 비활성화 어댑터 1b'
*> storage disable adapter 1a Jun 03 02:17:57 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1a. Host adapter 1a disable succeeded Jun 03 02:17:57 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1a is now offline. *> storage disable adapter 1b Jun 03 02:18:43 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1b. Host adapter 1b disable succeeded Jun 03 02:18:43 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1b is now offline. *>
-
포트가 비활성화되었는지 확인합니다.
'ucadmin 쇼'
*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - - offline 1b fc initiator - - offline 1c fc initiator - - online 1d fc initiator - - online -
A 및 b 포트를 FC-VI 모드로 설정합니다.
'ucadmin modify-adapter 1a-type fcvi'
명령은 포트 쌍 1a 및 1b의 두 포트 모두에서 모드를 설정합니다(명령에 1a만 지정됨).
*> ucadmin modify -t fcvi 1a Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1a. Reboot the controller for the changes to take effect. Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1b. Reboot the controller for the changes to take effect.
-
변경 사항이 보류 중인지 확인합니다.
'ucadmin 쇼'
*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - fcvi offline 1b fc initiator - fcvi offline 1c fc initiator - - online 1d fc initiator - - online -
컨트롤러를 종료한 다음 유지보수 모드로 재부팅합니다.
-
구성 변경을 확인합니다.
'ucadmin show local'
Node Adapter Mode Type Mode Type Status ------------ ------- ------- --------- ------- --------- ----------- ... controller_B_1 1a fc fcvi - - online controller_B_1 1b fc fcvi - - online controller_B_1 1c fc initiator - - online controller_B_1 1d fc initiator - - online 6 entries were displayed.
8노드 또는 4노드 구성의 유지보수 모드에서 디스크 할당 확인
시스템을 ONTAP로 완전히 부팅하기 전에 선택적으로 유지보수 모드로 부팅하고 노드의 디스크 할당을 확인할 수 있습니다. 각 풀에는 동일한 수의 디스크가 할당되어 있는 완전 대칭 액티브-액티브 구성을 생성하도록 디스크를 할당해야 합니다.
새 MetroCluster 시스템에는 배송 전에 디스크 할당이 완료되었습니다.
다음 표에서는 MetroCluster 구성의 풀 할당 예를 보여 줍니다. 디스크는 쉘프별로 풀에 할당됩니다.
사이트 A * 의 디스크 쉘프
디스크 쉘프(sample_shelf_name)… |
소속 대상… |
그리고 이 노드의… |
디스크 쉘프 1(쉘프_A_1_1) |
노드 A 1 |
풀 0 |
디스크 쉘프 2(쉘프_A_1_3) |
||
디스크 쉘프 3(쉘프_B_1_1) |
노드 B 1 |
풀 1 |
디스크 쉘프 4(쉘프_B_1_3) |
||
디스크 쉘프 5(쉘프_A_2_1) |
노드 A 2 |
풀 0 |
디스크 쉘프 6(쉘프_A_2_3) |
||
디스크 쉘프 7(쉘프_B_2_1) |
노드 B 2 |
풀 1 |
디스크 쉘프 8(쉘프_B_2_3) |
||
디스크 쉘프 1(쉘프_A_3_1) |
노드 A 3 |
풀 0 |
디스크 쉘프 2(쉘프_A_3_3) |
||
디스크 쉘프 3(쉘프_B_3_1) |
노드 B 3 |
풀 1 |
디스크 쉘프 4(쉘프_B_3_3) |
||
디스크 쉘프 5(쉘프_A_4_1) |
노드 A 4 |
풀 0 |
디스크 쉘프 6(쉘프_A_4_3) |
||
디스크 쉘프 7(쉘프_B_4_1) |
노드 B 4 |
풀 1 |
디스크 쉘프 8(쉘프_B_4_3) |
-
사이트 B의 디스크 쉘프 *
디스크 쉘프(sample_shelf_name)… |
소속 대상… |
그리고 이 노드의… |
디스크 쉘프 9(쉘프_B_1_2) |
노드 B 1 |
풀 0 |
디스크 쉘프 10(쉘프_B_1_4) |
디스크 쉘프 11(쉘프_A_1_2) |
노드 A 1 |
풀 1 |
디스크 쉘프 12(쉘프_A_1_4) |
디스크 쉘프 13(쉘프_B_2_2) |
노드 B 2 |
풀 0 |
디스크 쉘프 14(쉘프_B_2_4) |
디스크 쉘프 15(쉘프_A_2_2) |
노드 A 2 |
풀 1 |
디스크 쉘프 16(쉘프_A_2_4) |
디스크 쉘프 1(쉘프_B_3_2) |
노드 A 3 |
풀 0 |
디스크 쉘프 2(쉘프_B_3_4) |
디스크 쉘프 3(쉘프_A_3_2) |
노드 B 3 |
풀 1 |
디스크 쉘프 4(쉘프_A_3_4) |
디스크 쉘프 5(쉘프_B_4_2) |
노드 A 4 |
풀 0 |
디스크 쉘프 6(쉘프_B_4_4) |
디스크 쉘프 7(쉘프_A_4_2) |
노드 B 4 |
-
셸프 할당을 확인합니다.
'디스크 쇼 – v'
-
필요한 경우 연결된 디스크 쉘프의 디스크를 적절한 풀에 명시적으로 할당합니다.
"디스크 할당"을 선택합니다
명령에서 와일드카드를 사용하면 하나의 명령으로 디스크 쉘프의 모든 디스크를 할당할 수 있습니다. 'storage show disk-x' 명령을 사용하여 각 디스크의 디스크 쉘프 ID와 베이를 식별할 수 있습니다.
비 AFF 시스템에서 디스크 소유권 할당
MetroCluster 노드에 디스크가 올바르게 할당되지 않았거나 구성에서 DS460C 디스크 쉘프를 사용하는 경우 쉘프 단위로 MetroCluster 구성의 각 노드에 디스크를 할당해야 합니다. 각 노드의 로컬 및 원격 디스크 풀에서 디스크 수가 동일한 구성을 생성합니다.
스토리지 컨트롤러가 유지보수 모드여야 합니다.
구성에 DS460C 디스크 쉘프가 포함되어 있지 않은 경우, 공장 출하 시 디스크를 올바르게 할당한 경우에는 이 작업이 필요하지 않습니다.
|
|
풀 0에는 항상 디스크를 소유하는 스토리지 시스템과 동일한 사이트에서 찾은 디스크가 포함됩니다. 풀 1에는 항상 디스크를 소유한 스토리지 시스템에 원격으로 상주하는 디스크가 포함되어 있습니다. |
구성에 DS460C 디스크 쉘프가 포함된 경우 각 12-디스크 드로어에 대해 다음 지침을 사용하여 디스크를 수동으로 할당해야 합니다.
드로어에 이러한 디스크 할당… |
이 노드 및 풀로… |
0-2입니다 |
로컬 노드의 풀 0 |
3-5 |
HA 파트너 노드의 풀 0 |
6-8 |
로컬 노드 풀 1의 DR 파트너 |
9-11로 이동합니다 |
HA 파트너 풀 1의 DR 파트너 |
이 디스크 할당 패턴은 드로어가 오프라인 상태가 될 때 애그리게이트의 영향을 최소한으로 유지합니다.
-
그렇지 않은 경우 각 시스템을 유지보수 모드로 부팅합니다.
-
디스크 쉘프를 첫 번째 사이트(사이트 A)에 있는 노드에 할당합니다.
노드와 같은 사이트의 디스크 쉘프는 풀 0에 할당되고 파트너 사이트에 있는 디스크 쉘프는 풀 1에 할당됩니다.
각 풀에 동일한 수의 셸프를 할당해야 합니다.
-
첫 번째 노드에서 체계적으로 로컬 디스크 쉘프를 풀 0에 할당하고 원격 디스크 쉘프를 풀 1에 할당합니다.
Disk assign-shelf_local-switch-name: shelf-name.port_-p_pool_
스토리지 컨트롤러 Controller_A_1에 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1
-
로컬 사이트의 두 번째 노드에 대해 이 프로세스를 반복하여 로컬 디스크 쉘프를 풀 0에 체계적으로 할당하고 원격 디스크 쉘프를 풀 1에 할당합니다.
Disk assign-shelf_local-switch-name: shelf-name.port_-p_pool_
스토리지 컨트롤러 Controller_A_2에 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1
-
-
디스크 쉘프를 두 번째 사이트(사이트 B)에 있는 노드에 할당합니다.
노드와 같은 사이트의 디스크 쉘프는 풀 0에 할당되고 파트너 사이트에 있는 디스크 쉘프는 풀 1에 할당됩니다.
각 풀에 동일한 수의 셸프를 할당해야 합니다.
-
원격 사이트의 첫 번째 노드에서 체계적으로 로컬 디스크 쉘프를 풀 0에 할당하고 원격 디스크 쉘프를 풀 1에 할당합니다.
Disk assign-shelf_local-switch-nameshelf-name_-p_pool_
스토리지 컨트롤러 Controller_B_1에 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1
-
원격 사이트의 두 번째 노드에 대해 이 프로세스를 반복하여 로컬 디스크 쉘프를 풀 0에 체계적으로 할당하고 원격 디스크 쉘프를 풀 1에 할당합니다.
Disk assign-shelf_shelf-name_-p_pool_'입니다
스토리지 컨트롤러 Controller_B_2에 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1
-
-
셸프 할당을 확인합니다.
'Storage show shelf'
-
유지 관리 모드 종료:
"중지"
-
부팅 메뉴를 표시합니다.
boot_ontap 메뉴
-
각 노드에서 옵션 * 4 * 를 선택하여 모든 디스크를 초기화합니다.
AFF 시스템에서 디스크 소유권을 할당합니다
미러링된 Aggregate가 있는 구성에서 AFF 시스템을 사용하고 있고 노드에 디스크(SSD)가 올바르게 할당되지 않은 경우, 각 쉘프의 디스크 절반을 로컬 노드 1개에 할당하고 나머지 절반은 HA 파트너 노드에 할당해야 합니다. 각 노드의 로컬 및 원격 디스크 풀에서 디스크 수가 동일한 구성을 생성해야 합니다.
스토리지 컨트롤러가 유지보수 모드여야 합니다.
미러링되지 않은 애그리게이트, 액티브/패시브 구성이 있거나 로컬 및 원격 풀에서 디스크 수가 동일하지 않은 구성에는 적용되지 않습니다.
출하 시 디스크를 받았을 때 디스크를 올바르게 할당한 경우에는 이 작업이 필요하지 않습니다.
|
|
풀 0에는 항상 디스크를 소유하는 스토리지 시스템과 동일한 사이트에서 찾은 디스크가 포함됩니다. 풀 1에는 항상 디스크를 소유한 스토리지 시스템에 원격으로 상주하는 디스크가 포함되어 있습니다. |
-
그렇지 않은 경우 각 시스템을 유지보수 모드로 부팅합니다.
-
첫 번째 사이트(사이트 A)에 있는 노드에 디스크를 할당합니다.
각 풀에 동일한 수의 디스크를 할당해야 합니다.
-
첫 번째 노드에서 체계적으로 각 쉘프의 디스크 절반을 풀 0에 할당하고 나머지 절반은 HA 파트너의 풀 0에 할당합니다.
disk assign -shelf <shelf-name> -p <pool> -n <number-of-disks>스토리지 컨트롤러 컨트롤러_A_1에 각각 8개의 SSD가 장착된 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1 -n 4
-
로컬 사이트의 두 번째 노드에 대해 이 프로세스를 반복하여 각 쉘프의 디스크 절반을 풀 1에 체계적으로 할당하고 나머지 절반은 HA 파트너의 풀 1에 할당합니다.
디스크-디스크-이름-p 풀'입니다
스토리지 컨트롤러 컨트롤러_A_1에 각각 8개의 SSD가 장착된 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4
-
-
두 번째 사이트(사이트 B)에 있는 노드에 디스크를 할당합니다.
각 풀에 동일한 수의 디스크를 할당해야 합니다.
-
원격 사이트의 첫 번째 노드에서 각 쉘프의 디스크 절반을 풀 0에 체계적으로 할당하며 다른 절반은 HA 파트너의 풀 0에 할당합니다.
디스크 할당 - disk_disk-name_-p_pool_'입니다
스토리지 컨트롤러 컨트롤러 컨트롤러_B_1에 각각 8개의 SSD가 장착된 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1 -n 4
-
원격 사이트의 두 번째 노드에 대해 이 프로세스를 반복하여 각 쉘프의 디스크 절반을 풀 1에 체계적으로 할당하고 나머지 절반은 HA 파트너의 풀 1에 할당합니다.
디스크 할당 - disk_disk-name_-p_pool_'입니다
스토리지 컨트롤러 컨트롤러 컨트롤러_B_2에 각각 8개의 SSD가 장착된 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1 -n 4
-
-
디스크 할당을 확인합니다.
'스토리지 표시 디스크'
-
유지 관리 모드 종료:
"중지"
-
부팅 메뉴를 표시합니다.
boot_ontap 메뉴
-
각 노드에서 옵션 * 4 * 를 선택하여 모든 디스크를 초기화합니다.
2노드 구성의 유지보수 모드에서 디스크 할당 확인
시스템을 ONTAP로 완전히 부팅하기 전에 필요에 따라 시스템을 유지보수 모드로 부팅하고 노드의 디스크 할당을 확인할 수 있습니다. 디스크를 할당하여 자체 디스크 쉘프를 소유하고 데이터를 제공하는 두 사이트를 모두 포함하는 완전 대칭 구성을 생성해야 합니다. 각 노드와 각 풀에는 동일한 수의 미러링된 디스크가 할당됩니다.
시스템이 유지보수 모드여야 합니다.
새 MetroCluster 시스템에는 배송 전에 디스크 할당이 완료되었습니다.
다음 표에서는 MetroCluster 구성의 풀 할당 예를 보여 줍니다. 디스크는 쉘프별로 풀에 할당됩니다.
디스크 쉘프(예: 이름)… |
시험기관에서… |
소속 대상… |
그리고 이 노드의… |
디스크 쉘프 1(쉘프_A_1_1) |
사이트 A |
노드 A 1 |
풀 0 |
디스크 쉘프 2(쉘프_A_1_3) |
|||
디스크 쉘프 3(쉘프_B_1_1) |
노드 B 1 |
풀 1 |
|
디스크 쉘프 4(쉘프_B_1_3) |
|||
디스크 쉘프 9(쉘프_B_1_2) |
사이트 B |
노드 B 1 |
풀 0 |
디스크 쉘프 10(쉘프_B_1_4) |
|||
디스크 쉘프 11(쉘프_A_1_2) |
노드 A 1 |
풀 1 |
|
디스크 쉘프 12(쉘프_A_1_4) |
구성에 DS460C 디스크 쉘프가 포함된 경우 각 12-디스크 드로어에 대해 다음 지침을 사용하여 디스크를 수동으로 할당해야 합니다.
드로어에 이러한 디스크 할당… |
이 노드 및 풀로… |
1-6번 |
로컬 노드의 풀 0 |
7-12를 참조하십시오 |
DR 파트너의 풀 1 |
이 디스크 할당 패턴은 드로어가 오프라인 상태가 될 경우 Aggregate에 미치는 영향을 최소화합니다.
-
시스템이 공장에서 수령된 경우 쉘프 할당을 확인합니다.
'디스크 쇼 – v'
-
필요한 경우 disk assign 명령을 사용하여 연결된 디스크 쉘프의 디스크를 적절한 풀에 명시적으로 할당할 수 있습니다.
노드와 같은 사이트의 디스크 쉘프는 풀 0에 할당되고 파트너 사이트에 있는 디스크 쉘프는 풀 1에 할당됩니다. 각 풀에 동일한 수의 셸프를 할당해야 합니다.
-
그렇지 않은 경우 각 시스템을 유지보수 모드로 부팅합니다.
-
사이트 A의 노드에서 체계적으로 로컬 디스크 쉘프를 풀 0에 할당하고 원격 디스크 쉘프를 풀 1에 할당합니다.
"디스크 할당 - 쉘프_디스크_쉘프_이름_-p_pool_"
스토리지 컨트롤러 node_a_1에 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf shelf_A_1_1 -p 0 *> disk assign -shelf shelf_A_1_3 -p 0 *> disk assign -shelf shelf_A_1_2 -p 1 *> disk assign -shelf shelf_A_1_4 -p 1
-
원격 사이트(사이트 B)의 노드에서 로컬 디스크 쉘프를 풀 0에 체계적으로 할당하고 원격 디스크 쉘프를 풀 1에 할당합니다.
"디스크 할당 - 쉘프_디스크_쉘프_이름_-p_pool_"
스토리지 컨트롤러 node_B_1에 4개의 쉘프가 있는 경우 다음 명령을 실행합니다.
*> disk assign -shelf shelf_B_1_2 -p 0 *> disk assign -shelf shelf_B_1_4 -p 0 *> disk assign -shelf shelf_B_1_1 -p 1 *> disk assign -shelf shelf_B_1_3 -p 1
-
각 디스크의 디스크 쉘프 ID 및 베이를 표시합니다.
'디스크 쇼 – v'
-
ONTAP 설정
각 컨트롤러 모듈에 ONTAP를 설정해야 합니다.
새 컨트롤러를 netboot에 연결해야 하는 경우 를 참조하십시오 "새 컨트롤러 모듈을 Netbooting 합니다" MetroCluster 업그레이드, 전환 및 확장 가이드 _.
2노드 MetroCluster 구성에서 ONTAP 설정
2노드 MetroCluster 구성에서는 각 클러스터에서 노드를 부팅하고 클러스터 설정 마법사를 종료한 다음, 클러스터 설정 명령을 사용하여 노드를 단일 노드 클러스터로 구성해야 합니다.
서비스 프로세서를 구성하지 않아야 합니다.
이 작업은 네이티브 NetApp 스토리지를 사용하는 2노드 MetroCluster 구성에 사용됩니다.
이 작업은 MetroCluster 구성의 두 클러스터 모두에서 수행해야 합니다.
ONTAP 설정에 대한 자세한 내용은 을 참조하십시오 "ONTAP를 설정합니다".
-
첫 번째 노드의 전원을 켭니다.
DR(재해 복구) 사이트의 노드에서 이 단계를 반복해야 합니다. 노드가 부팅된 다음 콘솔에서 클러스터 설정 마법사가 시작되어 AutoSupport가 자동으로 활성화됨을 알립니다.
::> Welcome to the cluster setup wizard. You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the cluster setup wizard. Any changes you made before quitting will be saved. You can return to cluster setup at any time by typing "cluster setup". To accept a default or omit a question, do not enter a value. This system will send event messages and periodic reports to NetApp Technical Support. To disable this feature, enter autosupport modify -support disable within 24 hours. Enabling AutoSupport can significantly speed problem determination and resolution, should a problem occur on your system. For further information on AutoSupport, see: http://support.netapp.com/autosupport/ Type yes to confirm and continue {yes}: yes Enter the node management interface port [e0M]: Enter the node management interface IP address [10.101.01.01]: Enter the node management interface netmask [101.010.101.0]: Enter the node management interface default gateway [10.101.01.0]: Do you want to create a new cluster or join an existing cluster? {create, join}: -
새 클러스터 생성:
창조해
-
노드를 단일 노드 클러스터로 사용할지 여부를 선택합니다.
Do you intend for this node to be used as a single node cluster? {yes, no} [yes]: -
Enter를 눌러 시스템 기본값을 그대로 사용하거나 no를 입력하여 값을 입력한 다음 Enter 키를 누릅니다.
-
프롬프트에 따라 * Cluster Setup * 마법사를 완료하고 Enter 키를 눌러 기본값을 적용하거나 값을 직접 입력한 다음 Enter 키를 누릅니다.
기본값은 플랫폼과 네트워크 구성에 따라 자동으로 결정됩니다.
-
클러스터 설정 * 마법사를 완료하고 종료한 후 클러스터가 활성 상태이고 첫 번째 노드가 정상 상태인지 확인합니다
'클러스터 쇼'
다음 예에서는 첫 번째 노드(cluster1-01)가 정상이고 참여할 자격이 있는 클러스터를 보여 줍니다.
cluster1::> cluster show Node Health Eligibility --------------------- ------- ------------ cluster1-01 true true
admin SVM 또는 node SVM에 대해 입력한 설정을 변경해야 하는 경우 클러스터 설정 명령을 사용하여 클러스터 설정 마법사에 액세스할 수 있습니다.
8노드 또는 4노드 MetroCluster 구성에서 ONTAP 설정
각 노드를 부팅하면 System Setup 도구를 실행하여 기본 노드 및 클러스터 구성을 수행할 것인지 묻는 메시지가 표시됩니다. 클러스터를 구성한 후 ONTAP CLI로 돌아가 애그리게이트를 생성하고 MetroCluster 구성을 생성합니다.
MetroCluster 구성에 케이블로 연결되어 있어야 합니다.
이 작업은 네이티브 NetApp 스토리지를 사용하는 8노드 또는 4노드 MetroCluster 구성에 사용됩니다.
새로운 MetroCluster 시스템은 사전 구성되어 있으므로 이 단계를 수행할 필요가 없습니다. 그러나 AutoSupport 도구를 구성해야 합니다.
이 작업은 MetroCluster 구성의 두 클러스터 모두에서 수행해야 합니다.
이 절차에서는 System Setup 도구를 사용합니다. 필요한 경우 CLI 클러스터 설정 마법사를 대신 사용할 수 있습니다.
-
아직 수행하지 않은 경우 각 노드의 전원을 켜고 완전히 부팅하십시오.
시스템이 유지보수 모드인 경우 중지 명령을 실행하여 유지보수 모드를 종료한 다음 LOADER 프롬프트에서 다음 명령을 실행합니다.
부트 ONTAP
출력은 다음과 비슷해야 합니다.
Welcome to node setup You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the setup wizard. Any changes you made before quitting will be saved. To accept a default or omit a question, do not enter a value. . . .
-
시스템에서 제공하는 지침에 따라 AutoSupport 도구를 활성화합니다.
-
프롬프트에 응답하여 노드 관리 인터페이스를 구성합니다.
프롬프트는 다음과 유사합니다.
Enter the node management interface port: [e0M]: Enter the node management interface IP address: 10.228.160.229 Enter the node management interface netmask: 225.225.252.0 Enter the node management interface default gateway: 10.228.160.1
-
노드가 고가용성 모드로 구성되었는지 확인합니다.
'스토리지 페일오버 표시 필드 모드'
그렇지 않은 경우 각 노드에서 다음 명령을 실행하고 노드를 재부팅해야 합니다.
'Storage failover modify-mode ha-node localhost'
이 명령은 고가용성 모드를 구성하지만 스토리지 페일오버를 사용하도록 설정하지는 않습니다. MetroCluster 구성이 구성 프로세스 후반부에 수행되면 스토리지 페일오버가 자동으로 설정됩니다.
-
클러스터 인터커넥트에 4개의 포트가 구성되어 있는지 확인합니다.
네트워크 포트 쇼
다음 예에서는 cluster_A에 대한 출력을 보여 줍니다.
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ node_A_1 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 node_A_2 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
스위치가 없는 2노드 클러스터(클러스터 인터커넥트 스위치가 없는 클러스터)를 생성하는 경우 스위치가 없는 클러스터 네트워킹 모드를 활성화합니다.
-
고급 권한 레벨로 변경:
세트 프리빌리지 고급
고급 모드로 계속하라는 메시지가 나타나면 y를 응답할 수 있습니다. 고급 모드 프롬프트가 나타납니다(*>).
-
스위치가 없는 클러스터 모드 활성화:
'network options switchless-cluster modify -enabled true'
-
관리자 권한 레벨로 돌아갑니다.
'Set-Privilege admin'입니다
-
-
초기 부팅 후 시스템 콘솔에 나타나는 정보에 따라 System Setup 도구를 실행합니다.
-
시스템 설정 툴을 사용하여 각 노드를 구성하고 클러스터를 생성할 수 있지만 애그리게이트를 생성하지 마십시오.
이후 작업에서 미러링된 애그리게이트를 생성할 수 있습니다.
ONTAP 명령줄 인터페이스로 돌아가서 다음 작업을 수행하여 MetroCluster 구성을 완료합니다.
클러스터를 MetroCluster 구성으로 구성합니다
클러스터를 피어로 사용하고, 루트 애그리게이트를 미러링하고, 미러링된 데이터 애그리게이트를 생성한 다음, 명령을 실행하여 MetroCluster 작업을 구현해야 합니다.
러닝을 시작하기 전에 metrocluster configure`HA 모드 및 DR 미러링이 활성화되어 있지 않으며 이 예상 동작과 관련된 오류 메시지가 표시될 수 있습니다. 나중에 명령을 실행할 때 HA 모드 및 DR 미러링을 사용하도록 설정할 수 있습니다 `metrocluster configure 구성을 구현합니다.
클러스터 피어링
MetroCluster 구성의 클러스터는 서로 통신하고 MetroCluster 재해 복구에 필요한 데이터 미러링을 수행할 수 있도록 피어 관계에 있어야 합니다.
인터클러스터 LIF 구성
MetroCluster 파트너 클러스터 간 통신에 사용되는 포트에 대한 인터클러스터 LIF를 생성해야 합니다. 데이터 트래픽도 있는 전용 포트 또는 포트를 사용할 수 있습니다.
전용 포트에 대한 인터클러스터 LIF 구성
전용 포트에 대한 인터클러스터 LIF를 구성할 수 있습니다. 이렇게 하면 일반적으로 복제 트래픽에 사용할 수 있는 대역폭이 증가합니다.
-
클러스터의 포트 나열:
네트워크 포트 쇼
전체 명령 구문은 man 페이지를 참조하십시오.
다음 예에서는 "cluster01"의 네트워크 포트를 보여 줍니다.
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
인터클러스터 통신 전용으로 사용할 수 있는 포트를 확인합니다.
네트워크 인터페이스 보기 필드 홈 포트, 통화 포트
전체 명령 구문은 man 페이지를 참조하십시오.
다음 예에서는 포트 "e0e" 및 "e0f"에 LIF가 할당되지 않은 것을 보여 줍니다.
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
전용 포트에 대한 페일오버 그룹을 생성합니다.
'network interface failover-groups create-vserver_system_SVM_-failover-group_failover_group_-targets_physical_or_logical_ports_'
다음 예에서는 "SVMcluster01" 시스템의 페일오버 그룹 intercluster01에 포트 "e0e" 및 "e0f"를 할당합니다.
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
페일오버 그룹이 생성되었는지 확인합니다.
네트워크 인터페이스 페일오버 그룹들이 보여줌
전체 명령 구문은 man 페이지를 참조하십시오.
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
시스템 SVM에 대한 인터클러스터 LIF를 생성한 다음 이를 페일오버 그룹에 할당합니다.
ONTAP 9.6 이상"네트워크 인터페이스 create-vserver_system_SVM_-lif_LIF_name_-service-policy default-인터클러스터-home-node_node_-home-port_port_-address_port_ip_-netmask_mask_-failover-group_group_"
ONTAP 9.5 이하'network interface create -vserver_system_SVM_-lif_LIF_name_-role 인터클러스터 -home-node_node_-home-port_port_-address_port_ip_-netmask_mask_-failover -group_failover_group_'
전체 명령 구문은 man 페이지를 참조하십시오.
다음 예에서는 페일오버 그룹 "intercluster01"에 인터클러스터 LIF "cluster01_icl01" 및 "cluster01_icl02"를 생성합니다.
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
인터클러스터 LIF가 생성되었는지 확인합니다.
ONTAP 9.6 이상다음 명령을 실행합니다.
network interface show -service-policy default-interclusterONTAP 9.5 이하다음 명령을 실행합니다.
network interface show -role intercluster전체 명령 구문은 man 페이지를 참조하십시오.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0f true -
인터클러스터 LIF가 중복되는지 확인합니다.
ONTAP 9.6 이상다음 명령을 실행합니다.
network interface show -service-policy default-intercluster -failoverONTAP 9.5 이하다음 명령을 실행합니다.
network interface show -role intercluster -failover전체 명령 구문은 man 페이지를 참조하십시오.
다음 예에서는 SVM "e0e" 포트에 대한 인터클러스터 LIF "cluster01_icl01" 및 "cluster01_icl02"가 "e0f" 포트로 페일오버된다는 것을 보여 줍니다.
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
인터클러스터 복제를 위한 전용 포트를 사용하는 것이 올바른 인터클러스터 네트워크 솔루션인지 결정할 때 LAN 유형, 사용 가능한 WAN 대역폭, 복제 간격, 변경률 및 포트 수와 같은 구성 및 요구 사항을 고려해야 합니다.
공유 데이터 포트에 대한 인터클러스터 LIF 구성
데이터 네트워크와 공유하는 포트에 대한 인터클러스터 LIF를 구성할 수 있습니다. 이렇게 하면 인터클러스터 네트워킹에 필요한 포트 수가 줄어듭니다.
-
클러스터의 포트 나열:
네트워크 포트 쇼
전체 명령 구문은 man 페이지를 참조하십시오.
다음 예는 cluster01의 네트워크 포트를 보여줍니다.
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
시스템 SVM에 대한 인터클러스터 LIF 생성:
ONTAP 9.6 이상다음 명령을 실행합니다.
network interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmaskONTAP 9.5 이하다음 명령을 실행합니다.
network interface create -vserver system_SVM -lif LIF_name -role intercluster -home-node node -home-port port -address port_IP -netmask netmask전체 명령 구문은 man 페이지를 참조하십시오. 다음 예에서는 인터클러스터 LIF cluster01_icl01 및 cluster01_icl02를 생성합니다.
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
인터클러스터 LIF가 생성되었는지 확인합니다.
ONTAP 9.6 이상다음 명령을 실행합니다.
network interface show -service-policy default-interclusterONTAP 9.5 이하다음 명령을 실행합니다.
network interface show -role intercluster전체 명령 구문은 man 페이지를 참조하십시오.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
인터클러스터 LIF가 중복되는지 확인합니다.
ONTAP 9.6 이상다음 명령을 실행합니다.
network interface show –service-policy default-intercluster -failoverONTAP 9.5 이하다음 명령을 실행합니다.
network interface show -role intercluster -failover전체 명령 구문은 man 페이지를 참조하십시오.
다음 예에서는 "e0c" 포트의 인터클러스터 LIF "cluster01_icl01" 및 "cluster01_icl02"가 "e0d" 포트로 페일오버되는 것을 보여 줍니다.
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-02:e0c, cluster01-02:e0d
클러스터 피어 관계 생성
MetroCluster 클러스터 간에 클러스터 피어 관계를 생성해야 합니다.
'cluster peer create' 명령을 사용하여 로컬 클러스터와 원격 클러스터 간의 피어 관계를 생성할 수 있습니다. 피어 관계가 생성된 후 원격 클러스터에서 '클러스터 피어 생성'을 실행하여 로컬 클러스터에 인증할 수 있습니다.
-
피어링될 클러스터의 모든 노드에 대한 인터클러스터 LIF를 생성해야 합니다.
-
클러스터는 ONTAP 9.3 이상을 실행해야 합니다.
-
대상 클러스터에서 소스 클러스터와의 피어 관계를 생성합니다.
'클러스터 피어 생성 - 생성 - 패스프레이즈 - 오퍼 - EXPIRATION_MM/DD/YYYY HH:MM:SS|1…7일|1…168시간_-피어-addrs_peer_LIF_IPIP_-IPSpace_IPSpace_'
'-generate-passphrase와 '-peer-addrs'를 모두 지정하면 '-peer-addrs'에 지정된 인터클러스터 LIF가 있는 클러스터만 생성된 암호를 사용할 수 있습니다.
사용자 지정 IPspace를 사용하지 않는 경우 '-IPSpace' 옵션을 무시할 수 있습니다. 전체 명령 구문은 man 페이지를 참조하십시오.
다음 예에서는 지정되지 않은 원격 클러스터에 클러스터 피어 관계를 생성합니다.
cluster02::> cluster peer create -generate-passphrase -offer-expiration 2days Passphrase: UCa+6lRVICXeL/gq1WrK7ShR Expiration Time: 6/7/2017 08:16:10 EST Initial Allowed Vserver Peers: - Intercluster LIF IP: 192.140.112.101 Peer Cluster Name: Clus_7ShR (temporary generated) Warning: make a note of the passphrase - it cannot be displayed again. -
소스 클러스터에서 소스 클러스터를 대상 클러스터에 인증합니다.
'클러스터 피어 생성 - 피어-addrs peer_LIF_IPs - IPSpace IPSpace'
전체 명령 구문은 man 페이지를 참조하십시오.
다음 예에서는 인터클러스터 LIF IP 주소 "192.140.112.101" 및 "192.140.112.102"에서 원격 클러스터에 대한 로컬 클러스터를 인증합니다.
cluster01::> cluster peer create -peer-addrs 192.140.112.101,192.140.112.102 Notice: Use a generated passphrase or choose a passphrase of 8 or more characters. To ensure the authenticity of the peering relationship, use a phrase or sequence of characters that would be hard to guess. Enter the passphrase: Confirm the passphrase: Clusters cluster02 and cluster01 are peered.메시지가 나타나면 피어 관계에 대한 암호를 입력합니다.
-
클러스터 피어 관계가 생성되었는지 확인합니다.
클러스터 피어 쇼 인스턴스
cluster01::> cluster peer show -instance Peer Cluster Name: cluster02 Remote Intercluster Addresses: 192.140.112.101, 192.140.112.102 Availability of the Remote Cluster: Available Remote Cluster Name: cluster2 Active IP Addresses: 192.140.112.101, 192.140.112.102 Cluster Serial Number: 1-80-123456 Address Family of Relationship: ipv4 Authentication Status Administrative: no-authentication Authentication Status Operational: absent Last Update Time: 02/05 21:05:41 IPspace for the Relationship: Default -
피어 관계에서 노드의 접속 상태와 상태를 확인합니다.
클러스터 피어 상태 쇼
cluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
클러스터 피어 관계 생성(ONTAP 9.2 이하)
'cluster peer create' 명령을 사용하여 로컬 클러스터와 원격 클러스터 간의 피어링 관계에 대한 요청을 시작할 수 있습니다. 로컬 클러스터에서 피어 관계를 요청한 후에는 원격 클러스터에서 '클러스터 피어 생성'을 실행하여 관계를 수락할 수 있습니다.
-
피어링된 클러스터의 모든 노드에 대한 인터클러스터 LIF를 생성해야 합니다.
-
클러스터 관리자는 각 클러스터가 다른 클러스터에 자신을 인증하는 데 사용할 암호에 동의해야 합니다.
-
데이터 보호 대상 클러스터에서 데이터 보호 소스 클러스터와의 피어 관계를 생성합니다.
'cluster peer create-peer-addrs_peer_LIF_ips_-IPSpace_IPSpace_'
사용자 지정 IPspace를 사용하지 않는 경우 _-IPSpace_옵션을 무시해도 됩니다. 전체 명령 구문은 man 페이지를 참조하십시오.
다음 예에서는 인터클러스터 LIF IP 주소 "192.168.2.201" 및 "192.168.2.202"에서 원격 클러스터와 클러스터 피어 관계를 생성합니다.
cluster02::> cluster peer create -peer-addrs 192.168.2.201,192.168.2.202 Enter the passphrase: Please enter the passphrase again:
메시지가 나타나면 피어 관계에 대한 암호를 입력합니다.
-
데이터 보호 소스 클러스터에서 소스 클러스터를 대상 클러스터에 인증합니다.
'cluster peer create-peer-addrs_peer_LIF_ips_-IPSpace_IPSpace_'
전체 명령 구문은 man 페이지를 참조하십시오.
다음 예에서는 인터클러스터 LIF IP 주소 "192.140.112.203" 및 "192.140.112.204"에서 원격 클러스터에 대한 로컬 클러스터를 인증합니다.
cluster01::> cluster peer create -peer-addrs 192.168.2.203,192.168.2.204 Please confirm the passphrase: Please confirm the passphrase again:
메시지가 나타나면 피어 관계에 대한 암호를 입력합니다.
-
클러스터 피어 관계가 생성되었는지 확인합니다.
'클러스터 피어 쇼 – 인스턴스'
전체 명령 구문은 man 페이지를 참조하십시오.
cluster01::> cluster peer show –instance Peer Cluster Name: cluster01 Remote Intercluster Addresses: 192.168.2.201,192.168.2.202 Availability: Available Remote Cluster Name: cluster02 Active IP Addresses: 192.168.2.201,192.168.2.202 Cluster Serial Number: 1-80-000013
-
피어 관계에서 노드의 접속 상태와 상태를 확인합니다.
클러스터 피어 상태 쇼
전체 명령 구문은 man 페이지를 참조하십시오.
cluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
루트 애그리게이트를 미러링합니다
루트 애그리게이트를 미러링하여 데이터를 보호해야 합니다.
기본적으로 루트 애그리게이트는 RAID-DP 유형 Aggregate로 생성됩니다. 루트 애그리게이트를 RAID-DP에서 RAID4 유형 애그리게이트로 변경할 수 있습니다. 다음 명령을 실행하면 RAID4 유형 애그리게이트의 루트 애그리게이트가 수정됩니다.
storage aggregate modify –aggregate aggr_name -raidtype raid4
|
|
ADP가 아닌 시스템에서는 aggregate가 미러링되기 전이나 후에 기본 RAID-DP에서 RAID4로 애그리게이트의 RAID 유형을 수정할 수 있습니다. |
-
루트 애그리게이트 미러링:
'스토리지 애그리게이트 미러 aggr_name'
다음 명령은 controller_a_1의 루트 애그리게이트를 미러링합니다.
controller_A_1::> storage aggregate mirror aggr0_controller_A_1
이 구성은 애그리게이트를 미러링하므로 원격 MetroCluster 사이트에 있는 로컬 플렉스와 원격 플렉스로 구성됩니다.
-
MetroCluster 구성의 각 노드에 대해 이전 단계를 반복합니다.
각 노드에서 미러링된 데이터 애그리게이트 생성
DR 그룹의 각 노드에 미러링된 데이터 애그리게이트를 만들어야 합니다.
-
새 애그리게이트에 어떤 드라이브가 사용되는지 알아야 합니다.
-
시스템에 여러 드라이브 유형(이기종 스토리지)이 있는 경우 올바른 드라이브 유형을 선택할 수 있는 방법을 이해해야 합니다.
-
드라이브는 특정 노드에 의해 소유되며, 애그리게이트를 생성할 경우, 애그리게이트에 있는 모든 드라이브는 동일한 노드에 의해 소유되어야 하며, 이 노드는 해당 애그리게이트의 홈 노드가 됩니다.
-
애그리게이트 이름은 MetroCluster 구성을 계획할 때 지정한 명명 규칙에 따라야 합니다. 을 참조하십시오 "디스크 및 애그리게이트 관리".
-
애그리게이트 이름은 MetroCluster 사이트 전체에서 고유해야 합니다. 즉, 사이트 A와 사이트 B에 동일한 이름을 가진 두 개의 서로 다른 애그리게이트를 생성할 수 없습니다.
-
사용 가능한 스페어 목록을 표시합니다.
'storage disk show-spare-owner node_name'입니다
-
스토리지 Aggregate create-mirror true 명령을 사용하여 애그리게이트를 생성합니다.
클러스터 관리 인터페이스에서 클러스터에 로그인한 경우 클러스터의 모든 노드에 대해 애그리게이트를 생성할 수 있습니다. Aggregate가 특정 노드에서 생성되도록 하려면 '-node' 매개 변수를 사용하거나 해당 노드가 소유하는 드라이브를 지정합니다.
다음 옵션을 지정할 수 있습니다.
-
Aggregate의 홈 노드(즉, 정상 운영 시 Aggregate를 소유한 노드)
-
Aggregate에 추가될 특정 드라이브 목록입니다
-
포함할 드라이브 수입니다
드라이브 수가 제한된 최소 구성에서는 'force-small-aggregate' 옵션을 사용하여 디스크 RAID-DP Aggregate 3개를 생성해야 합니다. -
집계에 사용할 체크섬 스타일
-
사용할 드라이브 유형입니다
-
사용할 드라이브의 크기입니다
-
주행 속도를 사용하십시오
-
Aggregate의 RAID 그룹에 적합한 RAID 유형입니다
-
RAID 그룹에 포함될 수 있는 최대 드라이브 수입니다
-
RPM이 다른 드라이브가 허용되는지 여부
이러한 옵션에 대한 자세한 내용은 '저장소 집계 만들기' man 페이지를 참조하십시오.
다음 명령을 실행하면 10개의 디스크로 미러링된 Aggregate가 생성됩니다.
cluster_A::> storage aggregate create aggr1_node_A_1 -diskcount 10 -node node_A_1 -mirror true [Job 15] Job is queued: Create aggr1_node_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
새 애그리게이트의 RAID 그룹 및 드라이브를 확인합니다.
'Storage aggregate show-status-aggregate_aggregate-name_'
미러링되지 않은 데이터 애그리게이트를 생성합니다
선택적으로 MetroCluster 구성에서 제공되는 이중 미러링이 필요하지 않은 데이터에 대해 미러링되지 않은 데이터 애그리게이트를 만들 수 있습니다.
-
새로운 집계에서 어떤 드라이브가 사용될지 확인하세요.
-
시스템에 여러 드라이브 유형(이기종 스토리지)이 있는 경우 올바른 드라이브 유형이 선택되었는지 확인하는 방법을 이해해야 합니다.

|
MetroCluster FC 구성에서는 aggregate의 원격 디스크에 액세스할 수 있는 경우, 미러링되지 않은 애그리게이트가 스위치오버 이후 온라인만 됩니다. ISL에 장애가 발생하면 로컬 노드가 미러링되지 않은 원격 디스크의 데이터를 액세스할 수 없습니다. Aggregate에 장애가 발생하면 로컬 노드가 재부팅될 수 있습니다. |
-
드라이브는 특정 노드에 의해 소유되며, 애그리게이트를 생성할 경우, 애그리게이트에 있는 모든 드라이브는 동일한 노드에 의해 소유되어야 하며, 이 노드는 해당 애그리게이트의 홈 노드가 됩니다.
|
|
미러링되지 않은 애그리게이트는 해당 애그리게이트를 소유하는 노드에 로컬이어야 합니다. |
-
애그리게이트 이름은 MetroCluster 구성을 계획할 때 지정한 명명 규칙에 따라야 합니다.
-
_ 디스크 및 애그리게이트 관리 _ 는 미러링 Aggregate에 대한 자세한 정보를 포함합니다.
-
사용 가능한 스페어 목록을 표시합니다.
'storage disk show-spare-owner_node_name_'
-
애그리게이트 생성:
'스토리지 애그리게이트 생성'
클러스터 관리 인터페이스에서 클러스터에 로그인한 경우 클러스터의 모든 노드에 대해 애그리게이트를 생성할 수 있습니다. Aggregate가 특정 노드에 생성되었는지 확인하려면 '-node' 매개 변수를 사용하거나 해당 노드가 소유하는 드라이브를 지정해야 합니다.
다음 옵션을 지정할 수 있습니다.
-
Aggregate의 홈 노드(즉, 정상 운영 시 Aggregate를 소유한 노드)
-
Aggregate에 추가될 특정 드라이브 목록입니다
-
포함할 드라이브 수입니다
-
집계에 사용할 체크섬 스타일
-
사용할 드라이브 유형입니다
-
사용할 드라이브의 크기입니다
-
주행 속도를 사용하십시오
-
Aggregate의 RAID 그룹에 적합한 RAID 유형입니다
-
RAID 그룹에 포함될 수 있는 최대 드라이브 수입니다
-
RPM이 다른 드라이브가 허용되는지 여부
이러한 옵션에 대한 자세한 내용은 스토리지 애그리게이트 생성 man 페이지를 참조하십시오.
다음 명령을 실행하면 10개의 디스크로 구성된 미러링되지 않은 Aggregate가 생성됩니다.
controller_A_1::> storage aggregate create aggr1_controller_A_1 -diskcount 10 -node controller_A_1 [Job 15] Job is queued: Create aggr1_controller_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
새 애그리게이트의 RAID 그룹 및 드라이브를 확인합니다.
'Storage aggregate show-status-aggregate_aggregate-name_'
MetroCluster 구성 구현
MetroCluster 구성에서 데이터 보호를 시작하려면 'MetroCluster configure' 명령을 실행해야 합니다.
-
각 클러스터에 루트가 아닌 미러링된 데이터 Aggregate가 2개 이상 있어야 합니다.
추가 데이터 애그리게이트는 미러링할 수도, 미러링되지 않은 데이터일 수도 있습니다.
'storage aggregate show' 명령을 사용하여 이를 확인할 수 있습니다.
미러링된 단일 데이터 애그리게이트를 사용하려면 를 참조하십시오 1단계 를 참조하십시오. -
컨트롤러 및 섀시의 ha-config 상태는 "MCC"여야 합니다.
모든 노드에서 'MetroCluster configure' 명령을 한 번 실행하여 MetroCluster 설정을 활성화한다. 각 사이트나 노드에서 명령을 실행할 필요가 없으며 명령을 실행하기로 선택한 노드나 사이트는 중요하지 않습니다.
MetroCluster configure 명령은 두 클러스터 각각에서 가장 낮은 시스템 ID를 갖는 두 노드를 DR(재해 복구) 파트너로 자동 페어링합니다. 4노드 MetroCluster 구성에는 DR 파트너 쌍이 2개 있습니다. 두 번째 DR 쌍은 시스템 ID가 더 높은 두 노드에서 생성됩니다.
|
|
'MetroCluster configure' 명령을 실행하기 전에 Onboard Key Manager(OKM) 또는 외부 키 관리를 * 구성하지 않아야 합니다. |
-
MetroCluster 구성에 다음 기능이 있는 경우
다음을 수행하십시오.
데이터 애그리게이트가 여러 개 있습니다
노드의 프롬프트에서 MetroCluster를 구성합니다.
MetroCluster configure node-name
단일 미러링 데이터 애그리게이트
-
노드의 프롬프트에서 고급 권한 레벨로 변경합니다.
세트 프리빌리지 고급
고급 모드로 계속 진행하라는 메시지가 표시되고 고급 모드 프롬프트(*>)가 나타나면 "y"로 응답해야 합니다.
-
'-allow-with-one-aggregate TRUE' 파라미터를 사용하여 MetroCluster를 설정한다.
'MetroCluster configure-allow-with-one-aggregate TRUE_NODE-NAME_'
-
관리자 권한 레벨로 돌아갑니다.
'Set-Privilege admin'입니다
모범 사례는 데이터 애그리게이트를 여러 개 사용하는 것입니다. 첫 번째 DR 그룹에 애그리게이트만 있고 하나의 애그리게이트로 DR 그룹을 추가하려면 메타데이터 볼륨을 단일 데이터 애그리게이트로 이동해야 합니다. 이 절차에 대한 자세한 내용은 을 참조하십시오 "MetroCluster 구성에서 메타데이터 볼륨 이동". 다음 명령을 실행하면 controller_a_1이 포함된 DR 그룹의 모든 노드에서 MetroCluster 구성이 설정됩니다.
cluster_A::*> metrocluster configure -node-name controller_A_1 [Job 121] Job succeeded: Configure is successful.
-
-
사이트 A의 네트워킹 상태를 확인합니다.
네트워크 포트 쇼
다음 예는 4노드 MetroCluster 구성의 네트워크 포트 사용량을 보여 줍니다.
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- --------- ---------------- ----- ------- ------------ controller_A_1 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 controller_A_2 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
MetroCluster 구성의 두 사이트에서 MetroCluster 구성을 확인합니다.
-
사이트 A에서 구성을 확인합니다.
MetroCluster 쇼
cluster_A::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
사이트 B의 구성을 확인합니다.
MetroCluster 쇼
cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
ONTAP 소프트웨어에서 프레임의 주문 전달 또는 주문 후 전달 구성
파이버 채널(FC) 스위치 구성에 따라 IOD(In-Order Delivery) 또는 Food(Out-of-Order Delivery)를 구성해야 합니다.
FC 스위치가 IOD용으로 구성된 경우 IOD에 대해 ONTAP 소프트웨어를 구성해야 합니다. 마찬가지로 FC 스위치가 유드에 대해 구성된 경우 유드에 대해 ONTAP를 구성해야 합니다.
|
|
구성을 변경하려면 컨트롤러를 재부팅해야 합니다. |
-
IOD 또는 프레임 유목(Good)을 작동하도록 ONTAP를 구성합니다.
-
기본적으로 프레임의 IOD는 ONTAP에서 활성화됩니다. 구성 세부 정보를 확인하려면:
-
고급 모드 진입:
진일진일보한 것
-
설정을 확인합니다.
MetroCluster 상호 연결 어댑터가 표시됩니다
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
-
프레임 유목(Good)을 구성하려면 각 노드에서 다음 단계를 수행해야 합니다.
-
고급 모드 진입:
진일진일보한 것
-
MetroCluster 구성 설정을 확인합니다.
MetroCluster 상호 연결 어댑터가 표시됩니다
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
노드 " mcc4-B1 " 및 노드 " mcc4-B2 "에서 양호:
'MetroCluster interconnect adapter modify -node_node_name_-is-ood-enabled true
mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b1 -is-ood-enabled true mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b2 -is-ood-enabled true
-
양방향으로 고가용성(HA) 테이크오버 수행 하여 컨트롤러를 재부팅합니다.
-
설정을 확인합니다.
MetroCluster 상호 연결 어댑터가 표시됩니다
-
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up true 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up true 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up true 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up true 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
MetroCluster FC 구성에서 SNMPv3 구성하기
스위치와 ONTAP 시스템의 인증 및 개인 정보 보호 프로토콜은 동일해야 합니다.
ONTAP는 현재 개인 정보 보호(암호화)를 위해 AES-128을, 인증을 위해 SHA-256을 지원합니다.
|
|
|
-
컨트롤러 프롬프트에서 각 스위치에 대한 SNMP 사용자를 생성합니다.
'보안 로그인 생성'
Controller_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10.10.10.10
-
현장에서 필요에 따라 다음 프롬프트에 응답합니다.
EngineID의 경우 *ENTER*를 눌러 기본값을 지정합니다. Enter the authoritative entity's EngineID [remote EngineID]: Which authentication protocol do you want to choose (none, md5, sha, sha2-256) [none]: sha Enter the authentication protocol password (minimum 8 characters long): Enter the authentication protocol password again: Which privacy protocol do you want to choose (none, des, aes128) [none]: aes128 Enter privacy protocol password (minimum 8 characters long): Enter privacy protocol password again:
동일한 사용자 이름을 다른 IP 주소를 가진 다른 스위치에 추가할 수 있습니다. -
나머지 스위치에 대한 SNMP 사용자를 생성합니다.
다음 예에서는 IP 주소 10.10.10.11을 사용하여 스위치에 대한 사용자 이름을 생성하는 방법을 보여 줍니다.
Controller_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10. 10.10.11
-
각 스위치에 대해 하나의 로그인 항목이 있는지 확인합니다.
'보안 로그인 쇼'
Controller_A_1::> security login show -user-or-group-name snmpv3user -fields remote-switch-ipaddress vserver user-or-group-name application authentication-method remote-switch-ipaddress ------------ ------------------ ----------- --------------------- ----------------------- node_A_1 SVM 1 snmpv3user snmp usm 10.10.10.10 node_A_1 SVM 2 snmpv3user snmp usm 10.10.10.11 node_A_1 SVM 3 snmpv3user snmp usm 10.10.10.12 node_A_1 SVM 4 snmpv3user snmp usm 10.10.10.13 4 entries were displayed.
-
스위치 프롬프트에서 스위치에 SNMPv3을 구성합니다.
Brocade 스위치(FOS 9.x)snmpconfig --add snmpv3 -index <index> -user <user_name> -groupname <rw/ro> -auth_proto <auth_protocol> -auth_passwd <auth_password> -priv_proto <priv_protocol> -priv_passwd <priv_password>Brocade 스위치(FOS 8.x 및 이전 버전)'snmpconfig—set SNMPv3'을 선택합니다
이 예제에서는 읽기 전용 사용자를 구성하는 방법을 보여줍니다. 필요한 경우 RW 사용자를 조정할 수 있습니다. RO 액세스가 필요한 경우 "사용자(ro):" 뒤에 "snmpv3user"를 지정합니다.
Switch-A1:admin> snmpconfig --set snmpv3 SNMP Informs Enabled (true, t, false, f): [false] true SNMPv3 user configuration(snmp user not configured in FOS user database will have physical AD and admin role as the default): User (rw): [snmpadmin1] Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [3] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [2] Engine ID: [00:00:00:00:00:00:00:00:00] User (ro): [snmpuser2] snmpv3user Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [2] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [3]
Cisco 스위치snmp-server user <user_name> auth [md5/sha/sha-256] <auth_password> priv (aes-128) <priv_password>
또한 사용하지 않는 계정에 대한 암호를 설정하여 계정을 보호하고 ONTAP 릴리스에서 제공되는 최상의 암호화를 사용해야 합니다. -
사이트에서 필요에 따라 나머지 스위치 사용자의 암호화 및 암호를 구성합니다.
상태 모니터링을 위한 MetroCluster 구성 요소 구성
MetroCluster 구성에서 구성 요소를 모니터링하기 전에 몇 가지 특수 구성 단계를 수행해야 합니다.
|
|
보안을 강화하기 위해 NetApp 스위치 상태를 모니터링하도록 SNMPv2 또는 SNMPv3을 구성하는 것이 좋습니다. |
이러한 작업은 FC-to-SAS 브리지가 있는 시스템에만 적용됩니다.
Fabric OS 9.0.1부터 Brocade 스위치의 상태 모니터링에 SNMPv2는 지원되지 않으며, 대신 SNMPv3을 사용해야 합니다. SNMPv3을 사용하는 경우, 다음 섹션으로 진행하기 전에 ONTAP에서 SNMPv3을 구성해야 합니다. 자세한 내용은 MetroCluster FC 구성에서 SNMPv3 구성하기을 참조하십시오.
|
|
|
NetApp에서는 MetroCluster FC 구성의 구성 요소를 모니터링하기 위해 다음 툴만 지원합니다.
-
BNA(Brocade Network Advisor)
-
Brocade 산나브
-
Active IQ Config Advisor
-
NetApp 상태 모니터링(ONTAP)
-
MetroCluster 데이터 수집기(MC_DC)
상태 모니터링을 위해 MetroCluster FC 스위치 구성
패브릭 연결 MetroCluster 구성에서는 FC 스위치를 모니터링하기 위한 몇 가지 추가 구성 단계를 수행해야 합니다.
|
|
ONTAP 9.8부터 storage switch 명령이 로 대체됩니다. system switch fibre-channel 다음 단계에서는 storage switch 명령이 표시되지만 ONTAP 9.8 이상을 실행하는 경우에는 system switch fibre-channel 명령이 권장됩니다.
|
-
각 MetroCluster 노드에 IP 주소가 있는 스위치를 추가합니다.
실행하는 명령은 SNMPv2 또는 SNMPv3를 사용 중인지 여부에 따라 다릅니다.
SNMPv3을 사용하여 스위치 추가:storage switch add -address <ip_adddress> -snmp-version SNMPv3 -snmp-community-or-username <SNMP_user_configured_on_the_switch>SNMPv2를 사용하여 스위치 추가:스토리지 스위치 추가 주소 ipaddress
이 명령은 MetroCluster 구성의 4개 스위치 모두에서 반복해야 합니다.
Brocade 7840 FC 스위치 및 모든 경고는 NoISLPresent_Alert를 제외한 상태 모니터링에서 지원됩니다. 다음 예에서는 IP 주소 10.10.10.10이 있는 스위치를 추가하는 명령을 보여 줍니다.
controller_A_1::> storage switch add -address 10.10.10.10
-
모든 스위치가 올바르게 구성되었는지 확인합니다.
'스토리지 스위치 쇼'
15분 폴링 간격으로 인해 모든 데이터가 반영되는 데 최대 15분이 걸릴 수 있습니다.
다음 예에서는 제공된 명령을 사용하여 MetroCluster FC 스위치가 구성되었는지 확인합니다.
controller_A_1::> storage switch show Fabric Switch Name Vendor Model Switch WWN Status ---------------- --------------- ------- ------------ ---------------- ------ 1000000533a9e7a6 brcd6505-fcs40 Brocade Brocade6505 1000000533a9e7a6 OK 1000000533a9e7a6 brcd6505-fcs42 Brocade Brocade6505 1000000533d3660a OK 1000000533ed94d1 brcd6510-fcs44 Brocade Brocade6510 1000000533eda031 OK 1000000533ed94d1 brcd6510-fcs45 Brocade Brocade6510 1000000533ed94d1 OK 4 entries were displayed. controller_A_1::>
스위치의 WWN(Worldwide Name)이 표시되면 ONTAP 상태 모니터가 FC 스위치에 연결 및 모니터링할 수 있습니다.
상태 모니터링을 위한 FC-to-SAS 브리지 구성
9.8 이전의 ONTAP 버전을 실행하는 시스템에서는 MetroCluster 구성에서 FC-SAS 브리지를 모니터링하기 위한 몇 가지 특수 구성 단계를 수행해야 합니다.
-
FiberBridge 브리지는 타사 SNMP 모니터링 도구를 지원하지 않습니다.
-
ONTAP 9.8부터 FC-SAS 브리지는 기본적으로 대역내 연결을 통해 모니터링되며 추가 구성은 필요하지 않습니다.
|
|
ONTAP 9.8부터 스토리지 브리지 명령이 시스템 브리지로 바뀌었습니다. 다음 단계에서는 'Storage bridge' 명령어를 보여주지만, ONTAP 9.8 이상을 실행 중인 경우에는 'system bridge' 명령어를 사용한다. |
-
ONTAP 클러스터 프롬프트에서 상태 모니터링에 브리지를 추가합니다.
-
사용 중인 ONTAP 버전에 대한 명령을 사용하여 브리지를 추가합니다.
ONTAP 버전입니다
명령
9.5 이상
스토리지 브리지 추가 주소 0.0.0.0 - 대역내 관리 이름_브리지-이름_
9.4 이하
'Storage bridge add-address_bridge-ip-address_-name_bridge-name_'
-
브리지가 추가되었으며 올바르게 구성되었는지 확인합니다.
'스토리지 브리지 쇼'
폴링 간격 때문에 모든 데이터가 반영되는 데 15분 정도 걸릴 수 있습니다. ONTAP 상태 모니터는 "상태" 열의 값이 "확인"이고 WWN(Worldwide Name)과 같은 기타 정보가 표시되는 경우 브리지에 연결하고 모니터링할 수 있습니다.
다음 예는 FC-to-SAS 브리지가 구성된 경우를 보여줍니다.
controller_A_1::> storage bridge show Bridge Symbolic Name Is Monitored Monitor Status Vendor Model Bridge WWN ------------------ ------------- ------------ -------------- ------ ----------------- ---------- ATTO_10.10.20.10 atto01 true ok Atto FibreBridge 7500N 20000010867038c0 ATTO_10.10.20.11 atto02 true ok Atto FibreBridge 7500N 20000010867033c0 ATTO_10.10.20.12 atto03 true ok Atto FibreBridge 7500N 20000010867030c0 ATTO_10.10.20.13 atto04 true ok Atto FibreBridge 7500N 2000001086703b80 4 entries were displayed controller_A_1::>
-
MetroCluster 구성 확인
MetroCluster 설정의 구성 요소와 관계가 올바르게 작동하는지 확인할 수 있습니다.
초기 구성 후 MetroCluster 구성을 변경한 후 확인해야 합니다. 또한 협상된(계획된) 스위치오버 또는 스위치백 작업 전에 확인해야 합니다.
둘 중 하나 또는 두 클러스터에서 짧은 시간 내에 'MetroCluster check run' 명령을 두 번 실행하면 충돌이 발생하고 명령이 모든 데이터를 수집하지 못할 수 있습니다. 이후 'MetroCluster check show' 명령어는 예상 출력을 표시하지 않는다.
-
구성을 확인합니다.
'MetroCluster check run
명령은 백그라운드 작업으로 실행되며 즉시 완료되지 않을 수 있습니다.
cluster_A::> metrocluster check run The operation has been started and is running in the background. Wait for it to complete and run "metrocluster check show" to view the results. To check the status of the running metrocluster check operation, use the command, "metrocluster operation history show -job-id 2245"
cluster_A::> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
가장 최근의 'MetroCluster check run' 명령어를 통해 보다 상세한 결과를 출력한다.
'MetroCluster check aggregate show'
'MetroCluster check cluster show'를 선택합니다
'MetroCluster check config-replication show'를 선택합니다
'MetroCluster check lif show'
MetroCluster check node show
MetroCluster check show 명령은 최근 MetroCluster check run 명령의 결과를 보여준다. MetroCluster check show 명령을 사용하기 전에 항상 MetroCluster check run 명령을 실행하여 표시되는 정보가 최신 정보가 되도록 해야 합니다. 다음 예는 양호한 4노드 MetroCluster 구성을 위한 'MetroCluster check aggregate show' 명령 출력을 보여줍니다.
cluster_A::> metrocluster check aggregate show Last Checked On: 8/5/2014 00:42:58 Node Aggregate Check Result --------------- -------------------- --------------------- --------- controller_A_1 controller_A_1_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2 controller_A_2_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok 18 entries were displayed.다음 예에서는 양호한 4노드 MetroCluster 구성을 위한 'MetroCluster check cluster show' 명령 출력을 보여 줍니다. 이는 필요한 경우 클러스터가 협상된 전환을 수행할 준비가 되었음을 나타냅니다.
Last Checked On: 9/13/2017 20:47:04 Cluster Check Result --------------------- ------------------------------- --------- mccint-fas9000-0102 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok mccint-fas9000-0304 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok 10 entries were displayed.
Config Advisor에서 MetroCluster 구성 오류를 확인하는 중입니다
NetApp Support 사이트로 이동하여 Config Advisor 툴을 다운로드하여 일반적인 구성 오류를 확인할 수 있습니다.
Config Advisor는 구성 검증 및 상태 점검 툴입니다. 데이터 수집 및 시스템 분석을 위해 보안 사이트 및 비보안 사이트에 배포할 수 있습니다.
|
|
Config Advisor에 대한 지원은 제한적이며 온라인에서만 제공됩니다. |
-
Config Advisor 다운로드 페이지로 이동하여 도구를 다운로드합니다.
-
Config Advisor를 실행하고, 도구의 출력을 검토하고, 출력에서 권장 사항을 따라 발견된 문제를 해결합니다.
로컬 HA 작업을 확인하는 중입니다
4노드 MetroCluster 구성이 있는 경우 MetroCluster 구성에서 로컬 HA 쌍의 작동을 확인해야 합니다. 2노드 구성에는 이 작업이 필요하지 않습니다.
2노드 MetroCluster 구성은 로컬 HA 쌍으로 구성되지 않으며 이 작업은 적용되지 않습니다.
이 작업의 예에는 표준 명명 규칙이 사용됩니다.
-
클러스터_A
-
컨트롤러_A_1
-
컨트롤러_A_2
-
-
클러스터_B
-
컨트롤러_B_1
-
컨트롤러_B_2
-
-
cluster_a에서 두 방향으로 페일오버 및 반환을 수행합니다.
-
스토리지 페일오버가 설정되었는지 확인합니다.
'스토리지 페일오버 쇼'
결과는 양쪽 노드에서 테이크오버 가능 여부를 표시해야 합니다.
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed. -
controller_a_1에서 controller_A_2를 인수합니다.
스토리지 페일오버 컨트롤러_A_2
'storage failover show-takeover' 명령을 사용하여 인수 작업의 진행률을 모니터링할 수 있습니다.
-
테이크오버가 완료되었는지 확인:
'스토리지 페일오버 쇼'
결과물은 controller_a_1이 Takeover 상태에 있음을 나타내야 합니다. 즉, HA 파트너를 테이크오버했습니다.
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ----------------- controller_A_1 controller_A_2 false In takeover controller_A_2 controller_A_1 - Unknown 2 entries were displayed. -
컨트롤러_A_2 제공:
'Storage Failover 반환 컨트롤러_A_2'
'storage failover show-반환' 명령을 사용하여 반환 작업의 진행률을 모니터링할 수 있습니다.
-
스토리지 페일오버가 정상 상태로 복구되었는지 확인합니다.
'스토리지 페일오버 쇼'
결과는 양쪽 노드에서 테이크오버 가능 여부를 표시해야 합니다.
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed.-
controller_a_2에서 controller_a_1을 인수하는 데 앞서 설명한 하위 단계를 반복합니다.
-
-
cluster_B에서 위의 단계를 반복합니다
전환, 복구, 스위치백을 확인하는 중입니다
MetroCluster 구성의 전환, 복구 및 스위치백 작업을 확인해야 합니다.
-
에 나와 있는 협상된 전환, 복구 및 스위치백에 대한 절차를 사용합니다 "재해에 복구합니다".
구성 백업 파일을 보호합니다
로컬 클러스터의 기본 위치 외에 구성 백업 파일을 업로드할 원격 URL(HTTP 또는 FTP)을 지정하여 클러스터 구성 백업 파일에 대한 추가 보호를 제공할 수 있습니다.
-
구성 백업 파일의 원격 대상 URL을 설정합니다.
'System configuration backup settings modify_url-of-destination _'
를 클릭합니다 "CLI를 통한 클러스터 관리" 구성 백업 관리 섹션에 대한 추가 정보가 포함되어 있습니다.