

포트 재매핑 사용 방법
 변경 제안
변경 제안
여러 가지 이유로 인해 수신 포트 또는 아웃바운드 포트를 다시 매핑해야 할 수 있습니다. 레거시 CLB 로드 밸런서 서비스에서 현재 nginx 서비스 로드 밸런서 끝점으로 이동하고 동일한 포트를 유지하여 클라이언트에 대한 영향을 줄이거나, 관리 노드 클라이언트 네트워크에서 클라이언트 S3에 포트 443을 사용하거나, 방화벽 제한 사항에 대해 사용할 수 있습니다.
포트 재맵을 사용하여 CLB에서 NGINX로 S3 클라이언트를 마이그레이션합니다
StorageGRID 11.3 이전의 릴리스에서는 게이트웨이 노드에 포함된 로드 밸런서 서비스가 CLB(연결 로드 밸런서)입니다. StorageGRID 11.3에서 NetApp은 HTTP(s) 트래픽 로드 밸런싱을 위한 기능이 풍부한 통합 솔루션으로 NGINX 서비스를 도입했습니다. CLB 서비스는 StorageGRID의 현재 릴리스에서 계속 사용할 수 있으므로 새 로드 밸런서 엔드포인트 구성에서 포트 8082를 다시 사용할 수 없습니다. 이 문제를 해결하려면 8082 인바운드 포트를 10443으로 다시 매핑합니다. 이렇게 하면 게이트웨이 리디렉션의 포트 8082에 들어오는 모든 HTTPS 요청이 포트 10443으로 리디렉션되고 CLB 서비스를 우회하여 NGINX 서비스에 연결됩니다. 다음 지침은 VMware에 대한 지침이지만 port_remap 기능은 모든 설치 방법을 사용하며 베어 메탈 배포 및 어플라이언스에 유사한 프로세스를 사용할 수 있습니다.
VMware 가상 머신 게이트웨이 노드 구축
다음 단계는 StorageGRID OVF(Open Virtualization Format)를 사용하여 VMware vSphere 7에서 VM으로 게이트웨이 노드를 구축하는 StorageGRID 구축 단계입니다. 이 프로세스에서는 VM을 소멸적으로 제거하고 동일한 이름 및 구성으로 VM을 다시 배포해야 합니다. VM의 전원을 켜기 전에 vApp 속성을 변경하여 포트를 다시 매핑한 다음 VM의 전원을 켜고 노드 복구 프로세스를 따르십시오.
필수 구성 요소
-
StorageGRID 11.3 이상을 실행하고 있습니다
-
설치된 StorageGRID 버전 VMware 설치 파일을 다운로드하여 액세스할 수 있습니다.
-
VM의 전원을 켜거나 끄고, VM 및 vApp의 설정을 변경하고, vCenter에서 VM을 제거하고, OVF로 VM을 구축할 수 있는 권한이 있는 vCenter 계정이 있습니다.
-
로드 밸런서 끝점을 만들었습니다
-
포트가 원하는 리디렉션 포트로 구성되어 있습니다
-
엔드포인트 SSL 인증서는 Configuration/Server Certificates/Object Storage API Service Endpoints Server Certificate의 CLB 서비스에 설치된 것과 동일하며, 그렇지 않은 경우 클라이언트는 인증서 변경을 수락할 수 있습니다.
-

|
If your existing certificate is self-signed, you cannot reuse it in the new endpoint. You must generate a new self-signed certificate when creating the endpoint and configure the clients to accept the new certificate. |
첫 번째 게이트웨이 노드를 제거합니다
첫 번째 게이트웨이 노드를 제거하려면 다음 단계를 수행하십시오.
-
그리드에 둘 이상의 노드가 있는 경우 시작할 게이트웨이 노드를 선택합니다.
-
해당되는 경우 모든 DNS 라운드 로빈 엔터티 또는 로드 밸런서 풀에서 노드 IP를 제거합니다.
-
TTL(Time-to-Live)과 열려 있는 세션이 만료될 때까지 기다립니다.
-
VM 노드의 전원을 끕니다.
-
디스크에서 VM 노드를 제거합니다.
교체용 게이트웨이 노드를 배포합니다
교체 게이트웨이 노드를 배포하려면 다음 단계를 수행하십시오.
-
OVF에서 새 VM을 구축하고 지원 사이트에서 다운로드한 설치 패키지에서 .ovf, .mf 및 .vmdk 파일을 선택합니다.
-
vsphere - gateway.mf
-
vsphere - gateway.ovf
-
NetApp-SG-11.4.0-20200721.1338.d3969b3.vmdk
-
-
VM이 구축된 후 VM 목록에서 해당 VM을 선택하고 Configure 탭 vApp Options를 선택합니다.
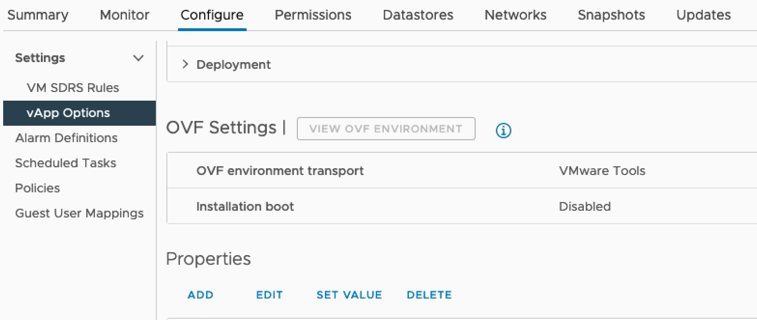
-
속성 섹션으로 스크롤하고 port_remap_inbound 속성을 선택합니다
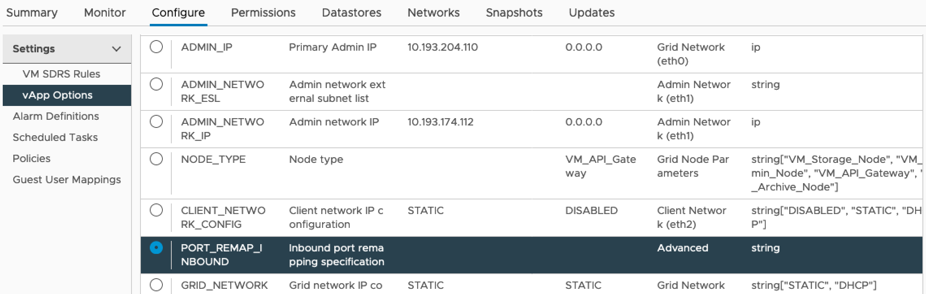
-
속성 목록 맨 위로 스크롤하여 편집 을 클릭합니다
-
유형 탭을 선택하고 사용자 구성 가능 확인란이 선택되어 있는지 확인한 다음 저장을 클릭합니다.
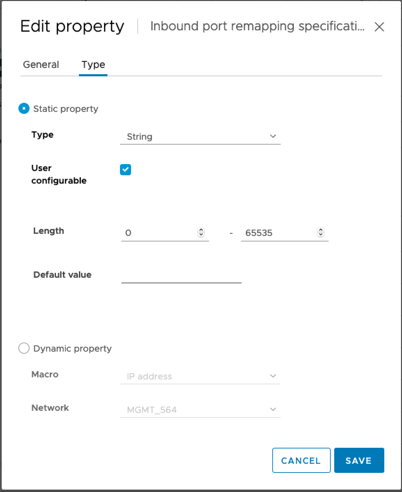
-
속성 목록 상단에서 "port_remap_inbound" 속성을 선택한 상태에서 값 설정 을 클릭합니다.
-
속성 값 필드에 네트워크(그리드, 관리자 또는 클라이언트), TCP, 원래 포트(8082) 및 새 포트(10443)를 입력합니다(아래 그림에 표시된 대로 각 값 사이에 “/”가 있음).
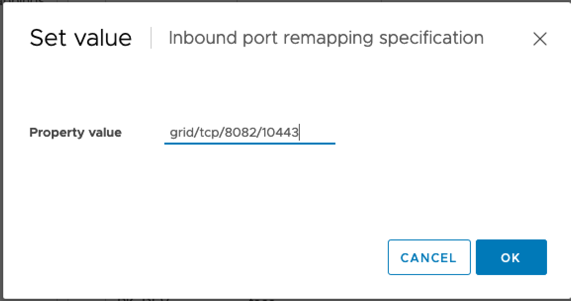
-
여러 네트워크를 사용하는 경우 네트워크 문자열을 구분하려면 쉼표(,)를 사용합니다(예: GRID/TCP/8082/10443, admin/TCP/8082/10443, client/TCP/8082/10443)
게이트웨이 노드를 복구합니다
게이트웨이 노드를 복구하려면 다음 단계를 수행하십시오.
-
Grid Management UI의 Maintenance/Recovery 섹션으로 이동합니다.
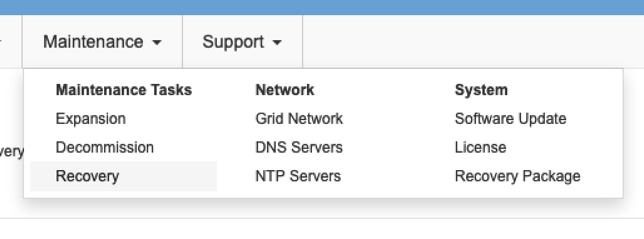
-
VM 노드의 전원을 켜고 Grid Management UI의 Maintenance/Recovery Pending Nodes 섹션에 노드가 나타날 때까지 기다립니다.

For information and directions for node recovery, see the https://docs.netapp.com/sgws-114/topic/com.netapp.doc.sg-maint/GUID-7E22B1B9-4169-4800-8727-75F25FC0FFB1.html[Recovery and Maintenance guide]
-
노드가 복구된 후에는 해당하는 경우 모든 DNS 라운드 로빈 엔터티 또는 로드 밸런서 풀에 IP를 포함할 수 있습니다.
이제 포트 8082의 모든 HTTPS 세션이 포트 10443으로 이동합니다
관리 노드에서 클라이언트 S3 액세스를 위한 포트 443을 다시 매핑합니다
관리 노드 또는 관리 노드가 포함된 HA 그룹에 대한 StorageGRID 시스템의 기본 구성은 포트 443 및 80을 관리 및 테넌트 관리자 UI용으로 예약하기 위한 것이며 로드 밸런서 끝점에 사용할 수 없습니다. 이에 대한 해결 방법은 포트 재매핑 기능을 사용하고 인바운드 포트 443을 로드 밸런서 끝점으로 구성할 새 포트로 리디렉션하는 것입니다. 이 작업이 완료되면 클라이언트 S3 트래픽에서 포트 443을 사용할 수 있고, 그리드 관리 UI는 포트 8443을 통해서만 액세스할 수 있으며, 테넌트 관리 UI는 포트 9443에서만 액세스할 수 있습니다. 재매핑 포트 기능은 노드 설치 시에만 구성할 수 있습니다. 활성 노드의 포트 재맵을 그리드에서 구현하려면 미리 설치된 상태로 재설정해야 합니다. 이 작업은 구성을 변경한 후 노드 복구를 포함하는 제거 절차입니다.
백업 로그 및 데이터베이스
관리 노드에는 속성, 경보 및 경고에 대한 내역 정보뿐만 아니라 감사 로그, Prometheus 메트릭이 포함됩니다. admin 노드가 여러 개인 경우 이 데이터의 복사본이 여러 개 있습니다. 그리드에 admin 노드가 여러 개 없는 경우, 이 프로세스가 끝날 때 노드를 복구한 후에 이 데이터를 보존하여 복원해야 합니다. 그리드에 다른 관리 노드가 있는 경우 복구 프로세스 중에 해당 노드의 데이터를 복사할 수 있습니다. 그리드에 다른 관리 노드가 없는 경우 노드를 삭제하기 전에 다음 지침에 따라 데이터를 복사할 수 있습니다.
감사 로그를 복사합니다
-
관리자 노드에 로그인합니다.
-
다음 명령을 입력합니다.
ssh admin@grid_node_IP -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
루트로 전환하려면 다음 명령을 입력합니다.
su - -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
SSH 에이전트에 SSH 개인 키를 추가합니다. 입력:
ssh-add -
에 나열된 SSH 액세스 암호를 입력합니다
Passwords.txt파일.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
디렉토리를 생성하여 모든 감사 로그 파일을 별도의 그리드 노드의 임시 위치에 복사합니다. use_storage_node_01_:
-
ssh admin@storage_node_01_IP -
mkdir -p /var/local/tmp/saved-audit-logs
-
-
관리 노드로 돌아가서 AMS 서비스를 중지하여 새 로그 파일을 생성하지 않도록 합니다.
service ams stop -
audit.log 파일을 복구된 관리 노드에 복사할 때 기존 파일을 덮어쓰지 않도록 파일 이름을 바꿉니다.
-
audit.log 이름을 yyyy-mm-dd.txt.1과 같이 번호가 지정된 고유한 파일 이름으로 바꿉니다. 예를 들어 감사 로그 파일의 이름을 2015-10-25.txt.1로 바꿀 수 있습니다
cd /var/local/audit/export ls -l mv audit.log 2015-10-25.txt.1
-
-
AMS 서비스를 다시 시작합니다.
service ams start -
모든 감사 로그 파일 복사:
scp * admin@storage_node_01_IP:/var/local/tmp/saved-audit-logs
Prometheus 데이터를 복사합니다
|
|
Prometheus 데이터베이스를 복사하는 데 1시간 이상이 걸릴 수 있습니다. 일부 그리드 관리자 기능은 관리 노드에서 서비스가 중지되는 동안 사용할 수 없습니다. |
-
디렉토리를 생성하여 Prometheus 데이터를 별도의 그리드 노드의 임시 위치에 복사합니다. 다시 한 번 사용자_storage_node_01_입니다.
-
스토리지 노드에 로그인합니다.
-
다음 명령을 입력합니다.
ssh admin@storage_node_01_IP -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
mkdir -p /var/local/tmp/Prometheus'입니다
-
-
-
관리자 노드에 로그인합니다.
-
다음 명령을 입력합니다.
ssh admin@admin_node_IP -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
루트로 전환하려면 다음 명령을 입력합니다.
su - -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
SSH 에이전트에 SSH 개인 키를 추가합니다. 입력:
ssh-add -
에 나열된 SSH 액세스 암호를 입력합니다
Passwords.txt파일.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
관리 노드에서 Prometheus 서비스를 중지합니다.
service prometheus stop-
소스 관리 노드에서 스토리지 노드 백업 위치로 Prometheus 데이터베이스를 복사합니다. 노드:
/rsync -azh --stats "/var/local/mysql_ibdata/prometheus/data" "storage_node_01_IP:/var/local/tmp/prometheus/"
-
-
소스 관리 노드에서 Prometheus 서비스를 다시 시작합니다.
service prometheus start
내역 정보 백업
내역 정보는 MySQL 데이터베이스에 저장됩니다. 데이터베이스 복사본을 덤프하려면 NetApp의 사용자 및 암호가 필요합니다. 그리드에 다른 관리 노드가 있는 경우 이 단계는 필요하지 않으며 복구 프로세스 중에 나머지 관리 노드에서 데이터베이스를 복제할 수 있습니다.
-
관리자 노드에 로그인합니다.
-
다음 명령을 입력합니다.
ssh admin@admin_node_IP -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
루트로 전환하려면 다음 명령을 입력합니다.
su - -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
SSH 에이전트에 SSH 개인 키를 추가합니다. 입력:
ssh-add -
에 나열된 SSH 액세스 암호를 입력합니다
Passwords.txt파일.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
관리자 노드에서 StorageGRID 서비스를 중지하고 NTP 및 MySQL을 시작합니다
-
모든 서비스 중지:
service servermanager stop -
NTP 서비스 다시 시작:
service ntp start.. MySQL 서비스를 다시 시작합니다.service mysql start
-
-
mi 데이터베이스를 /var/local/tmp에 덤프합니다
-
다음 명령을 입력합니다.
mysqldump –u username –p password mi > /var/local/tmp/mysql-mi.sql
-
-
MySQL dump 파일을 대체 노드에 복사합니다. storage_node_01을 사용합니다.
scp /var/local/tmp/mysql-mi.sql _storage_node_01_IP:/var/local/tmp/mysql-mi.sql-
다른 서버에 대한 암호 없는 액세스가 더 이상 필요하지 않으면 SSH 에이전트에서 개인 키를 제거합니다. 입력:
ssh-add -D
-
관리 노드를 재구축합니다
이제 원하는 모든 데이터의 백업 복사본이 있으며 그리드의 다른 관리 노드에 기록하거나 임시 위치에 저장되었으므로 어플라이언스를 재설정하여 포트 재맵을 구성할 수 있습니다.
-
어플라이언스를 재설정하면 사전 설치된 상태로 돌아가고 호스트 이름, IP 및 네트워크 구성만 유지됩니다. 모든 데이터가 손실되므로 중요한 정보를 백업하도록 했습니다.
-
다음 명령을 입력합니다.
sgareinstallroot@sg100-01:~ # sgareinstall WARNING: All StorageGRID Webscale services on this node will be shut down. WARNING: Data stored on this node may be lost. WARNING: You will have to reinstall StorageGRID Webscale to this node. After running this command and waiting a few minutes for the node to reboot, browse to one of the following URLs to reinstall StorageGRID Webscale on this node: https://10.193.174.192:8443 https://10.193.204.192:8443 https://169.254.0.1:8443 Are you sure you want to continue (y/n)? y Renaming SG installation flag file. Initiating a reboot to trigger the StorageGRID Webscale appliance installation wizard.
-
-
잠시 후 어플라이언스가 재부팅되고 노드 PGE UI에 액세스할 수 있습니다.
-
Configure Networking으로 이동합니다
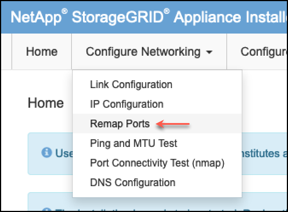
-
원하는 네트워크, 프로토콜, 방향 및 포트를 선택한 다음 규칙 추가 버튼을 클릭합니다.
그리드 네트워크에서 인바운드 포트 443을 다시 매핑하면 설치와 확장 절차가 중단됩니다. 그리드 네트워크에서 포트 443을 다시 매핑하지 않는 것이 좋습니다. 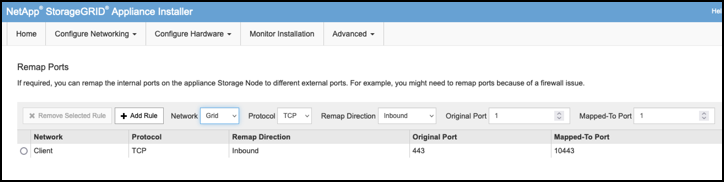
-
원하는 포트 재맵이 추가되었습니다. 홈 탭으로 돌아가 설치 시작 버튼을 클릭합니다.
이제 의 관리 노드 복구 절차를 수행할 수 있습니다 "제품 설명서"
데이터베이스 및 로그 복원
이제 관리 노드가 복구되었으므로 메트릭, 로그 및 기간별 정보를 복구할 수 있습니다. 그리드에 다른 관리 노드가 있는 경우, 에 따르십시오 "제품 설명서" Prometheus-clone-db.sh_and_mi-clone-db.sh_scripts를 사용합니다. 이 노드가 유일한 관리 노드이고 이 데이터를 백업하도록 선택한 경우 다음 단계에 따라 정보를 복원할 수 있습니다.
감사 로그를 다시 복사합니다
-
관리자 노드에 로그인합니다.
-
다음 명령을 입력합니다.
ssh admin@grid_node_IP -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
루트로 전환하려면 다음 명령을 입력합니다.
su - -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
SSH 에이전트에 SSH 개인 키를 추가합니다. 입력:
ssh-add -
에 나열된 SSH 액세스 암호를 입력합니다
Passwords.txt파일.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
보존된 감사 로그 파일을 복구된 관리 노드에 복사합니다.
scp admin@grid_node_IP:/var/local/tmp/saved-audit-logs/YYYY* . -
보안을 위해 장애가 발생한 그리드 노드에서 복구된 관리 노드에 성공적으로 복사되었는지 확인한 후 감사 로그를 삭제합니다.
-
복구된 관리 노드에서 감사 로그 파일의 사용자 및 그룹 설정을 업데이트합니다.
chown ams-user:bycast *
또한 감사 공유에 대한 기존 클라이언트 액세스도 복원해야 합니다. 자세한 내용은 StorageGRID 관리 지침을 참조하십시오.
Prometheus 메트릭을 복원합니다
|
|
Prometheus 데이터베이스를 복사하는 데 1시간 이상이 걸릴 수 있습니다. 일부 그리드 관리자 기능은 관리 노드에서 서비스가 중지되는 동안 사용할 수 없습니다. |
-
관리자 노드에 로그인합니다.
-
다음 명령을 입력합니다.
ssh admin@grid_node_IP -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
루트로 전환하려면 다음 명령을 입력합니다.
su - -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
SSH 에이전트에 SSH 개인 키를 추가합니다. 입력:
ssh-add -
에 나열된 SSH 액세스 암호를 입력합니다
Passwords.txt파일.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
관리 노드에서 Prometheus 서비스를 중지합니다.
service prometheus stop-
임시 백업 위치에서 관리자 노드로 Prometheus 데이터베이스를 복사합니다.
/rsync -azh --stats "backup_node:/var/local/tmp/prometheus/" "/var/local/mysql_ibdata/prometheus/" -
데이터가 올바른 경로에 있고 완전한지 확인합니다
ls /var/local/mysql_ibdata/prometheus/data/
-
-
소스 관리 노드에서 Prometheus 서비스를 다시 시작합니다.
service prometheus start
내역 정보를 복원합니다
-
관리자 노드에 로그인합니다.
-
다음 명령을 입력합니다.
ssh admin@grid_node_IP -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
루트로 전환하려면 다음 명령을 입력합니다.
su - -
에 나열된 암호를 입력합니다
Passwords.txt파일. -
SSH 에이전트에 SSH 개인 키를 추가합니다. 입력:
ssh-add -
에 나열된 SSH 액세스 암호를 입력합니다
Passwords.txt파일.When you are logged in as root, the prompt changes from `$` to `#`.
-
-
대체 노드에서 MySQL 덤프 파일을 복사합니다.
scp grid_node_IP_:/var/local/tmp/mysql-mi.sql /var/local/tmp/mysql-mi.sql -
관리자 노드에서 StorageGRID 서비스를 중지하고 NTP 및 MySQL을 시작합니다
-
모든 서비스 중지:
service servermanager stop -
NTP 서비스 다시 시작:
service ntp start.. MySQL 서비스를 다시 시작합니다.service mysql start
-
-
mi 데이터베이스를 드롭하고 비어 있는 새 데이터베이스를 생성합니다.
mysql -u username -p password -A mi -e "drop database mi; create database mi;" -
데이터베이스 덤프에서 MySQL 데이터베이스 복원:
mysql -u username -p password -A mi < /var/local/tmp/mysql-mi.sql -
다른 서비스를 모두 다시 시작합니다
service servermanager start
_ 아론 클라인 _