

NetApp StorageGRID 및 빅데이터 분석
 변경 제안
변경 제안
NetApp StorageGRID 사용 사례
NetApp StorageGRID 오브젝트 스토리지 솔루션은 확장성, 데이터 가용성, 보안 및 고성능을 제공합니다. 모든 규모와 다양한 산업 분야의 조직이 광범위한 사용 사례에 StorageGRID S3를 사용합니다. 몇 가지 일반적인 시나리오를 살펴보겠습니다.
-
빅 데이터 분석: * StorageGRID S3는 기업에서 Apache Spark, Splunk Smartstore 및 Dremio와 같은 도구를 사용하여 분석을 위해 대량의 정형 및 비정형 데이터를 저장하는 데이터 레이크로 자주 사용됩니다.
-
데이터 계층화: * NetApp 고객은 ONTAP의 FabricPool 기능을 사용하여 고성능 로컬 계층 간에 데이터를 자동으로 StorageGRID로 이동합니다. 계층화하면 콜드 데이터를 저렴한 오브젝트 스토리지에서 즉시 사용 가능한 상태로 유지하면서 고가의 플래시 스토리지를 핫 데이터용으로 확보할 수 있습니다. 따라서 성능과 비용 절감 효과가 극대화됩니다.
-
데이터 백업 및 재해 복구: * 기업에서는 StorageGRID S3를 안정적이고 비용 효율적인 솔루션으로 사용하여 중요한 데이터를 백업하고 재해 발생 시 복구할 수 있습니다.
-
응용 프로그램용 데이터 저장: * StorageGRID S3는 응용 프로그램용 스토리지 백엔드로 사용할 수 있으므로 개발자가 파일, 이미지, 비디오 및 기타 유형의 데이터를 쉽게 저장하고 검색할 수 있습니다.
-
콘텐츠 전송: * StorageGRID S3를 사용하여 정적 웹 사이트 콘텐츠, 미디어 파일 및 소프트웨어 다운로드를 전 세계 사용자에게 저장하고 제공할 수 있으며, StorageGRID의 지리적 분산 및 글로벌 네임스페이스를 활용하여 빠르고 안정적인 콘텐츠 전송을 수행할 수 있습니다.
-
데이터 아카이브: * StorageGRID는 다양한 스토리지 유형을 제공하고 공용 장기 저비용 스토리지 옵션에 대한 계층화를 지원하며, 규정 준수 또는 기간별 목적으로 보존해야 하는 데이터의 보관 및 장기 보존에 이상적인 솔루션입니다.
-
오브젝트 스토리지 사용 사례 *
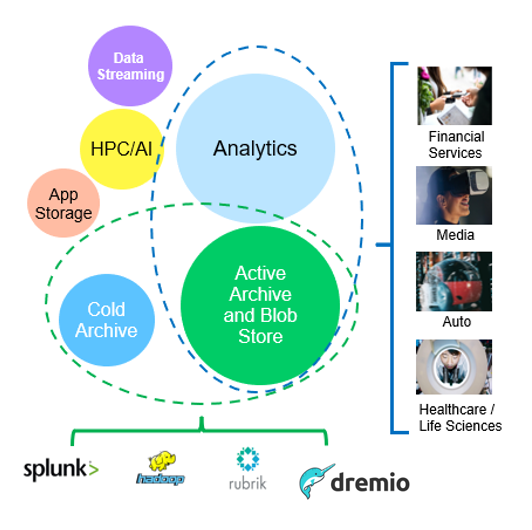
위 중 빅 데이터 분석은 최상위 사용 사례 중 하나이며 사용량이 증가하고 있습니다.
데이터 레이크에 StorageGRID를 사용해야 하는 이유
-
협업 증가 - 업계 표준 API 액세스를 지원하는 대규모 공유 멀티 사이트 멀티 테넌시
-
운영 비용 절감 - 자동 복구, 자동화된 단일 스케일아웃 아키텍처를 통해 운영 간소화
-
확장성 - 기존 Hadoop 및 데이터 웨어하우스 솔루션과 달리 StorageGRID S3 오브젝트 스토리지는 스토리지를 컴퓨팅과 데이터와 분리하므로 기업이 필요에 따라 스토리지 요구사항을 확장할 수 있습니다.
-
내구성 및 안정성 - StorageGRID는 99.9999999%의 내구성을 제공하여 저장된 데이터가 데이터 손실에 대한 저항성이 높습니다. 또한 고가용성을 제공하여 데이터에 항상 액세스할 수 있도록 보장합니다.
-
보안-StorageGRID는 암호화, 액세스 제어 정책, 데이터 라이프사이클 관리, 오브젝트 잠금 및 버전 관리와 같은 다양한 보안 기능을 제공하여 S3 버킷에 저장된 데이터를 보호합니다
-
StorageGRID S3 데이터 레이크 *
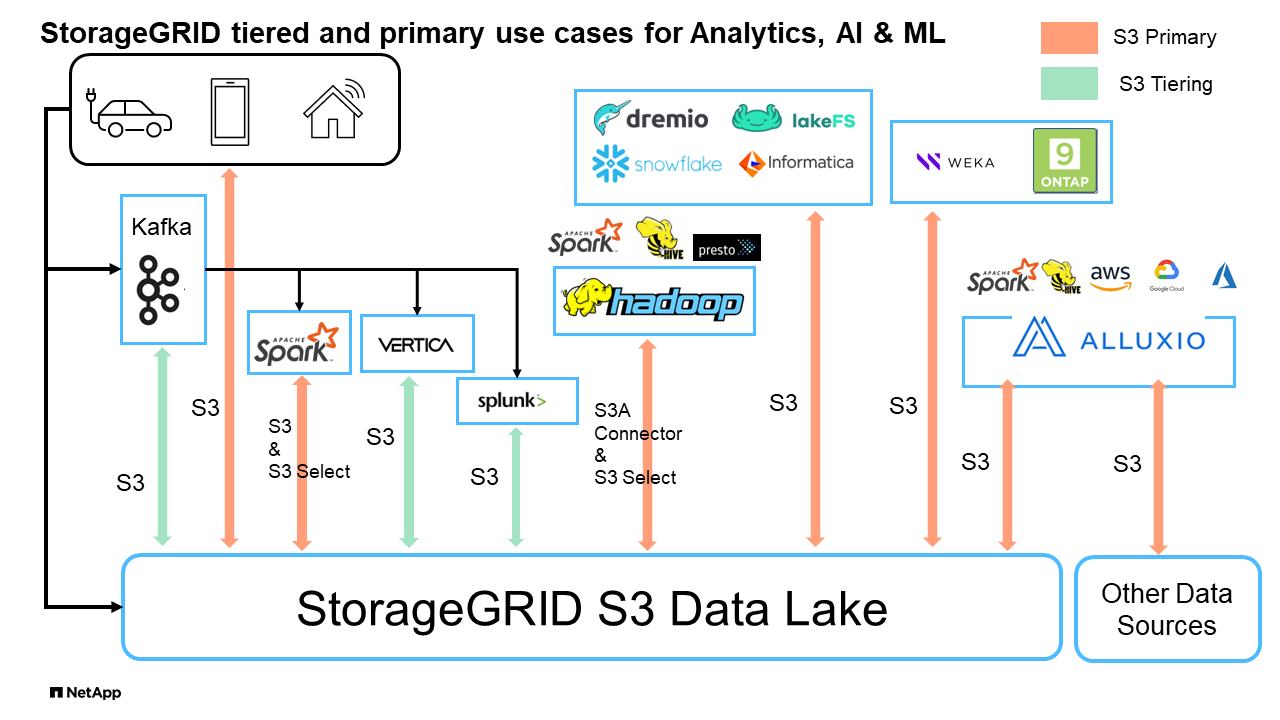
S3 오브젝트 스토리지를 사용한 벤치마킹 데이터 웨어하우스 및 레이크하우스: 비교 연구
이 문서는 NetApp StorageGRID를 사용하는 다양한 데이터 웨어하우스 및 레이크하우스 에코시스템에 대한 포괄적인 벤치마크를 제공합니다. 목표는 S3 객체 스토리지를 사용하는 시스템에서 어떤 시스템이 가장 우수한 성능을 보이는지 파악하는 것입니다. 데이터 웨어하우스/레이크하우스 아키텍처 및 테이블 형식(Parquet 및 Iceberg)에 대한 자세한 내용은 이 "아파치 아이스버그: 확실한 가이드"을 참조하십시오.
-
벤치마크 도구 - TPC-DS - https://www.tpc.org/tpcds/
-
빅 데이터 에코시스템
-
VM 클러스터, 각각 128G RAM 및 24개의 vCPU, 시스템 디스크용 SSD 스토리지
-
Hive 3.1.3 포함 Hadoop 3.3.5(이름 노드 1개 + 데이터 노드 4개)
-
Spark 3.0.0(마스터 1명 + 작업자 4명) 및 Hadoop 3.3.5 지원 델타 레이크
-
Dremio v25.2(코디네이터 1명 + 실행자 5명)
-
Trino v438(코디네이터 1명 + 작업자 5명)
-
Starburst v453(코디네이터 1명 + 작업자 5명)
-
-
오브젝트 스토리지
-
NetApp ® StorageGRID ® 11.8(SG6060 + SG1000 로드 밸런서 3개 포함
-
개체 보호 - 복사본 2개(결과는 EC 2+1과 유사함)
-
-
데이터베이스 크기 1000GB
-
Parquet 형식을 사용하여 각 쿼리 테스트에 대한 모든 에코시스템에서 캐시가 비활성화되었습니다. Iceberg 형식의 경우 캐시 사용 안 함 시나리오와 캐시 사용 시나리오 간에 S3 GET 요청 수와 총 쿼리 시간을 비교했습니다.
TPC-DS에는 벤치마킹을 위해 설계된 99개의 복잡한 SQL 쿼리가 포함되어 있습니다. 99개의 쿼리를 실행하는 데 걸린 총 시간을 측정하고 S3 요청의 유형과 수를 조사하여 상세 분석을 수행했습니다. 이 테스트에서는 널리 사용되는 두 가지 테이블 형식인 Parquet과 Iceberg의 효율성을 비교했습니다.
*파케 테이블 형식의 TPC-DS 쿼리 결과 *
| 에코시스템 | 하이브 | 델타 레이크 | 드리미오 | 트리노 | 별 모양 |
|---|---|---|---|---|---|
TPCDS 99 쿼리 |
10841 |
55 |
36 |
32 |
28 |
S3 요청 분석 |
가져오기 |
1,117,184 |
2,074,610 |
3,939,690 |
1,504,212 |
1,495,039입니다 |
관찰: |
80% 범위 32MB 객체에서 2KB ~ 2MB, 초당 50 ~ 100회의 요청 |
73% 범위는 32MB 개체에서 100KB 미만으로, 초당 1000 - 1400개의 요청 수입니다 |
90% 1M 바이트 범위는 256MB 객체, 초당 2500-3000개 요청에서 가져옵니다 |
범위 가져오기 크기: 100KB 미만 50%, 1MB 주위 16%, 2MB-9MB 27%, 초당 3500-4000개 요청 |
범위 가져오기 크기: 100KB 미만 50%, 1MB 주위 16%, 2MB-9MB 27%, 4000-5000 요청/초 |
개체 나열 |
312,053입니다 |
24,158입니다 |
120 |
509 |
512 |
머리 |
156,027 |
12,103 |
96 |
0 |
0 |
머리 |
982,126 |
922,732 |
0 |
0 |
0 |
총 요청 수입니다 |
2,567,390입니다 |
3,033,603입니다 |
3,939.906 |
1,504,721번 |
-
조회 번호 72를 완료할 수 없습니다
-
Iceberg 테이블 형식의 TPC-DS 쿼리 결과 *
-
| 에코시스템 | 드리미오 | 트리노 | 별 모양 |
|---|---|---|---|
TPCDS 99 쿼리 + 총 시간(캐시 사용 안 함) |
22 |
28 |
22 |
TPCDS 99 쿼리 + 총 2분(캐시 사용) |
16 |
28 |
21.5입니다 |
S3 요청 분석 |
가져오기(캐시 사용 안 함) |
1,985,922 |
938,639입니다 |
931,582를 참조하십시오 |
가져오기(캐시 사용) |
611,347 |
30,158명 |
3,281 |
관찰: |
범위 가져오기 크기: 67% 1MB, 15% 100KB, 10% 500KB, 3500 - 4500개 요청/초 |
범위 가져오기 크기: 100KB 미만 42%, 1MB 주위 17%, 2MB-9MB 33%, 초당 3500-4000개의 요청 |
범위 가져오기 크기: 100KB 미만 43%, 1MB 주위 17%, 2MB-9MB 33%, 4000-5000개의 요청/초 |
개체 나열 |
1465 |
0 |
0 |
머리 |
1464 |
0 |
0 |
머리 |
3,702 |
509 |
509 |
총 요청 수(캐시 사용 안 함) |
1,992,553 |
939,148입니다 |
Trino/Starburst 성능은 컴퓨팅 리소스에 의해 병목 현상이 발생했습니다. 클러스터에 RAM을 추가하면 총 쿼리 시간이 줄어듭니다.
첫 번째 표에서 볼 수 있듯이 Hive는 다른 현대 데이터 레이크하우스 생태계보다 상당히 느립니다. Hive는 많은 수의 S3 목록 오브젝트 요청을 보냈으며, 이는 일반적으로 모든 오브젝트 스토리지 플랫폼에서 느리며, 특히 많은 오브젝트가 포함된 버킷을 처리할 때 매우 느립니다. 이렇게 하면 전체 쿼리 기간이 크게 늘어납니다. 또한 현대적인 레이크하우스 생태계는 Hive의 초당 50-100개 요청에 비해 초당 2,000개에서 5,000개의 요청에 이르는 수많은 GET 요청을 동시에 전송할 수 있습니다. Hive 및 Hadoop S3A의 표준 파일 시스템은 S3 오브젝트 스토리지와 상호 작용할 때 Hive의 느린 속도에 기여합니다.
Hive 또는 Spark와 함께 Hadoop(HDFS 또는 S3 오브젝트 스토리지)을 사용하려면 Hadoop 및 Hive/Spark에 대한 폭넓은 지식이 필요하며, 각 서비스의 설정이 상호 작용하는 방식에 대한 이해가 필요합니다. 모두 1,000개 이상의 설정이 있으며, 그 중 다수는 상호 연관되어 있으며 독립적으로 변경할 수 없습니다. 설정과 값을 최적으로 조합하려면 엄청난 시간과 노력이 필요합니다.
Parquet와 Iceberg 결과를 비교하면 테이블 형식이 중요한 성능 요인이라는 것을 알 수 있습니다. Iceberg 테이블 형식은 S3 요청 수 면에서 Parquet보다 더 효율적이며, Parquet 형식에 비해 요청 수가 35%~50% 적습니다.
Dremio, Trino 또는 Starburst의 성능은 주로 클러스터의 컴퓨팅 능력에 의해 구동됩니다. 이 세 가지 모두 S3 오브젝트 스토리지 연결에 S3A 커넥터를 사용하지만 Hadoop이 필요하지 않으며 Hadoop의 fs.s3a 설정 대부분은 이러한 시스템에서 사용되지 않습니다. 따라서 다양한 Hadoop S3A 설정을 학습하고 테스트할 필요가 없으므로 성능 조정이 간소화됩니다.
이 벤치마크 결과에서 알 수 있듯이, S3 기반 워크로드에 최적화된 빅데이터 분석 시스템이 주요 성능 요소라는 결론을 내릴 수 있습니다. 최신 레이크하우스는 쿼리 실행을 최적화하고 메타데이터를 효율적으로 사용하며 S3 데이터에 대한 원활한 액세스를 제공하므로 S3 스토리지로 작업할 때 Hive보다 성능이 향상됩니다.
StorageGRID를 사용하여 Dremio S3 데이터 소스를 구성하려면 이 항목을 "페이지" 참조하십시오.
아래 링크를 방문하여 StorageGRID와 Dremio가 함께 작동하여 현대적이고 효율적인 데이터 레이크 인프라를 제공하는 방법과 NetApp가 Hive+ HDFS에서 Dremio+ StorageGRID로 마이그레이션하여 빅데이터 분석 효율성을 획기적으로 개선한 방법에 대해 자세히 알아보십시오.