

StorageGRID 스토리지 볼륨 재마운트 및 재포맷(수동 단계)
 변경 제안
변경 제안
자동 절차가 보존된 스토리지 볼륨을 다시 마운트하거나 포맷에 실패한 스토리지 볼륨을 다시 포맷하지 못하는 경우, 해당 작업을 완료하려면 두 개의 스크립트를 수동으로 실행해야 합니다. 첫 번째 스크립트는 StorageGRID 스토리지 볼륨으로 올바르게 포맷된 볼륨을 다시 마운트합니다. 두 번째 스크립트는 마운트 해제된 볼륨을 다시 포맷하고, 필요한 경우 Cassandra 데이터베이스를 재구축하고, 서비스를 시작합니다.
스토리지 노드 복구 중에 Grid Manager에 "수동 단계 대기 중" 메시지가 나타나면 다음 단계를 따라 스토리지 볼륨을 다시 마운트하고 포맷하십시오. 이 메시지가 표시되지 않으면 다시 마운트 및 포맷 작업이 자동으로 완료된 것이므로 이 절차를 건너뛸 수 있습니다. "객체 데이터 복원"
-
장애가 발생한 스토리지 볼륨의 하드웨어를 교체하도록 이미 교체했습니다.
스크립트를 실행하면
sn-remount-volumes오류가 발생한 추가 스토리지 볼륨을 식별하는 데 도움이 될 수 있습니다. -
스토리지 노드 해체가 진행 중이 아닌지 확인했거나 노드 해체 절차를 일시 중지했습니다. (그리드 관리자에서 유지관리 > 작업 > *해제*를 선택합니다.)
-
확장이 진행 중이 아님을 확인했습니다. (그리드 관리자에서 유지관리 > 작업 > *확장*을 선택합니다.)
-
있습니다. "스토리지 노드 시스템 드라이브 복구에 대한 경고를 검토했습니다"

두 개 이상의 스토리지 노드가 오프라인인 경우 기술 지원팀에 문의하세요. 실행하지 마십시오 sn-recovery-postinstall.sh스크립트.
이 절차를 완료하려면 다음과 같은 고급 작업을 수행해야 합니다.
-
복구된 스토리지 노드에 로그인합니다.
-
`sn-remount-volumes`스크립트를 실행하여 올바르게 포맷된 스토리지 볼륨을 다시 마운트합니다. 이 스크립트가 실행되면 다음 작업을 수행합니다.
-
각 스토리지 볼륨을 마운트 및 마운트 해제하고 XFS 저널을 재생합니다.
-
XFS 파일 일관성 검사를 수행합니다.
-
파일 시스템의 정합성이 보장되면 스토리지 볼륨이 제대로 포맷된 StorageGRID 스토리지 볼륨인지 확인합니다.
-
저장소 볼륨이 제대로 포맷된 경우 저장소 볼륨을 다시 마운트합니다. 볼륨의 기존 데이터는 그대로 유지됩니다.
-
-
스크립트 출력을 검토하고 문제를 해결합니다.
-
`sn-recovery-postinstall.sh`스크립트를 실행합니다. 이 스크립트가 실행되면 다음 작업을 수행합니다.
복구 중에는 실패한 스토리지 볼륨을 다시 포맷하고 객체 메타데이터를 복구하기 위해 실행하기 전에 스토리지 노드를 재부팅하지 마십시오 sn-recovery-postinstall.sh. 완료되기 전에 스토리지 노드를 재부팅하면sn-recovery-postinstall.sh시작을 시도하고 StorageGRID 어플라이언스 노드가 유지보수 모드를 종료하는 서비스에 오류가 발생합니다. 의 단계를 설치 후 스크립트참조하십시오.-
스크립트가 마운트하지 못했거나 잘못 포맷된 스토리지 볼륨을 다시
sn-remount-volumes포맷합니다.
저장소 볼륨이 다시 포맷되면 해당 볼륨의 모든 데이터가 손실됩니다. ILM 규칙이 두 개 이상의 개체 복사본을 저장하도록 구성되었다고 가정하여 그리드의 다른 위치에서 개체 데이터를 복원하려면 추가 절차를 수행해야 합니다. -
필요한 경우 노드에서 Cassandra 데이터베이스를 재구축합니다.
-
스토리지 노드에서 서비스를 시작합니다.
-
-
복구된 스토리지 노드에 로그인:
-
다음 명령을 입력합니다.
ssh admin@grid_node_IP -
파일에 나열된 암호를
Passwords.txt입력합니다. -
다음 명령을 입력하여 루트로 전환합니다.
su - -
파일에 나열된 암호를
Passwords.txt입력합니다.
루트로 로그인하면 프롬프트가 에서
$로 `#`변경됩니다. -
-
첫 번째 스크립트를 실행하여 적절하게 포맷된 스토리지 볼륨을 다시 마운트합니다.
모든 스토리지 볼륨이 새 볼륨이고 포맷해야 하거나 모든 스토리지 볼륨이 실패한 경우 이 단계를 건너뛰고 두 번째 스크립트를 실행하여 마운트 해제된 모든 스토리지 볼륨을 다시 포맷할 수 있습니다. -
다음 스크립트를 실행합니다.
sn-remount-volumes이 스크립트는 데이터가 포함된 스토리지 볼륨에서 실행되는 데 몇 시간이 걸릴 수 있습니다.
-
스크립트가 실행되면 출력을 검토하고 프롬프트에 응답합니다.
필요한 경우 명령을 사용하여 스크립트의 로그 파일 내용을 모니터링할 수 tail -f(/var/local/log/sn-remount-volumes.log있습니다. 로그 파일에는 명령줄 출력보다 자세한 정보가 들어 있습니다.root@SG:~ # sn-remount-volumes The configured LDR noid is 12632740 ====== Device /dev/sdb ====== Mount and unmount device /dev/sdb and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sdb: Mount device /dev/sdb to /tmp/sdb-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12632740, volume number 0 in the volID file Attempting to remount /dev/sdb Device /dev/sdb remounted successfully ====== Device /dev/sdc ====== Mount and unmount device /dev/sdc and checking file system consistency: Error: File system consistency check retry failed on device /dev/sdc. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policies. Don't continue to the next step if you believe that the data remaining on this volume can't be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sdd ====== Mount and unmount device /dev/sdd and checking file system consistency: Failed to mount device /dev/sdd This device could be an uninitialized disk or has corrupted superblock. File system check might take a long time. Do you want to continue? (y or n) [y/N]? y Error: File system consistency check retry failed on device /dev/sdd. You can see the diagnosis information in the /var/local/log/sn-remount-volumes.log. This volume could be new or damaged. If you run sn-recovery-postinstall.sh, this volume and any data on this volume will be deleted. If you only had two copies of object data, you will temporarily have only a single copy. StorageGRID will attempt to restore data redundancy by making additional replicated copies or EC fragments, according to the rules in the active ILM policies. Don't continue to the next step if you believe that the data remaining on this volume can't be rebuilt from elsewhere in the grid (for example, if your ILM policy uses a rule that makes only one copy or if volumes have failed on multiple nodes). Instead, contact support to determine how to recover your data. ====== Device /dev/sde ====== Mount and unmount device /dev/sde and checking file system consistency: The device is consistent. Check rangedb structure on device /dev/sde: Mount device /dev/sde to /tmp/sde-654321 with rangedb mount options This device has all rangedb directories. Found LDR node id 12000078, volume number 9 in the volID file Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
예제 출력에서 한 스토리지 볼륨이 성공적으로 다시 마운트되었으며 세 개의 스토리지 볼륨에 오류가 발생했습니다.
-
/dev/sdbXFS 파일 시스템 일관성 검사를 통과했으며 유효한 볼륨 구조가 있어 성공적으로 다시 마운트되었습니다. 스크립트에 의해 다시 마운트된 디바이스의 데이터는 보존됩니다. -
/dev/sdc스토리지 볼륨이 새 볼륨이거나 손상되었기 때문에 XFS 파일 시스템 일관성 검사에 실패했습니다. -
/dev/sdd디스크가 초기화되지 않았거나 디스크의 슈퍼블록이 손상되었기 때문에 마운트할 수 없습니다. 스크립트가 스토리지 볼륨을 마운트할 수 없는 경우 파일 시스템 정합성 검사를 실행할 것인지 묻는 메시지가 표시됩니다.-
스토리지 볼륨이 새 디스크에 연결되어 있는 경우 프롬프트에 * N * 으로 응답합니다. 새 디스크에서 파일 시스템을 확인할 필요가 없습니다.
-
스토리지 볼륨이 기존 디스크에 연결되어 있는 경우 프롬프트에 * Y * 로 응답합니다. 파일 시스템 검사 결과를 사용하여 손상의 원인을 확인할 수 있습니다. 결과는
/var/local/log/sn-remount-volumes.log로그 파일에 저장됩니다.
-
-
/dev/sdeXFS 파일 시스템 일관성 검사를 통과했으며 유효한 볼륨 구조를 가지고 있지만 volid 파일의 LDR 노드 ID가 이 스토리지 노드의 ID(맨 위에 표시됨)와 일치하지configured LDR noid않습니다. 이 메시지는 이 볼륨이 다른 스토리지 노드에 속함을 나타냅니다.
-
-
-
스크립트 출력을 검토하고 문제를 해결합니다.
스토리지 볼륨이 XFS 파일 시스템 일관성 검사에 실패했거나 마운트할 수 없는 경우 출력에서 오류 메시지를 자세히 검토합니다. 이러한 볼륨에 대한 스크립트 실행의 의미를 이해해야 sn-recovery-postinstall.sh합니다.-
결과에 예상한 모든 볼륨에 대한 항목이 포함되어 있는지 확인합니다. 목록에 볼륨이 없으면 스크립트를 다시 실행합니다.
-
마운트된 모든 디바이스에 대한 메시지를 검토합니다. 스토리지 볼륨이 이 스토리지 노드에 속해 있지 않음을 나타내는 오류가 없는지 확인합니다.
이 예제에서 의 출력에는
/dev/sde다음 오류 메시지가 포함됩니다.Error: This volume does not belong to this node. Fix the attached volume and re-run this script.
스토리지 볼륨이 다른 스토리지 노드에 속하는 것으로 보고되면 기술 지원 부서에 문의하십시오. 스크립트를 실행하면 sn-recovery-postinstall.sh스토리지 볼륨이 다시 포맷되어 데이터가 손실될 수 있습니다. -
스토리지 디바이스를 마운트할 수 없는 경우 디바이스 이름을 기록해 두고 디바이스를 복구하거나 교체합니다.
마운트할 수 없는 스토리지 디바이스를 복구하거나 교체해야 합니다. -
마운트 해제된 모든 디바이스를 복구하거나 교체한 후
sn-remount-volumes스크립트를 다시 실행하여 다시 마운트할 수 있는 모든 스토리지 볼륨이 다시 마운트되었는지 확인합니다.
스토리지 볼륨을 마운트할 수 없거나 잘못 포맷된 경우 다음 단계를 계속 수행하면 볼륨의 모든 데이터와 볼륨이 삭제됩니다. 오브젝트 데이터의 복사본이 2개인 경우 다음 절차(오브젝트 데이터 복원)를 완료할 때까지 복사본 하나가 유지됩니다.
장애가 발생한 스토리지 볼륨에 남아 있는 데이터를 그리드의 다른 위치에서 재구축할 수 없다고 생각하는 경우(예: ILM 정책이 하나의 복사본만 만드는 규칙을 사용하는 경우 또는 여러 노드에서 볼륨이 장애가 발생한 경우) 스크립트를 실행하지 마십시오 sn-recovery-postinstall.sh. 대신 기술 지원 부서에 문의하여 데이터 복구 방법을 확인하십시오. -
-
sn-recovery-postinstall.sh`다음 스크립트를 실행합니다. `sn-recovery-postinstall.sh이 스크립트는 마운트할 수 없거나 잘못 포맷된 스토리지 볼륨을 다시 포맷하고, 필요한 경우 노드에서 Cassandra 데이터베이스를 재구축하고, 스토리지 노드에서 서비스를 시작합니다.
다음 사항에 유의하십시오.
-
스크립트를 실행하는 데 몇 시간이 걸릴 수 있습니다.
-
일반적으로 스크립트가 실행되는 동안에는 SSH 세션만 남겨야 합니다.
-
SSH 세션이 활성화되어 있는 동안에는 * Ctrl + C * 를 누르지 마십시오.
-
네트워크 중단이 발생하여 SSH 세션을 종료하는 경우 스크립트는 백그라운드에서 실행되지만 복구 페이지에서 진행률을 볼 수 있습니다.
-
스토리지 노드가 RSM 서비스를 사용하는 경우 노드 서비스가 다시 시작됨에 따라 스크립트가 5분 동안 정지되는 것처럼 보일 수 있습니다. RSM 서비스가 처음 부팅될 때마다 5분 정도 지연될 수 있습니다.
RSM 서비스는 ADC 서비스를 포함하는 스토리지 노드에 있습니다.
일부 StorageGRID 복구 절차에서는 리퍼를 사용하여 Cassandra 수리를 처리합니다. 관련 또는 필수 서비스가 시작되는 즉시 수리가 자동으로 이루어집니다. "Reaper" 또는 "Cassandra repair"라는 스크립트 출력을 확인할 수 있습니다. 복구가 실패했음을 나타내는 오류 메시지가 표시되면 오류 메시지에 표시된 명령을 실행합니다. -
-
] 스크립트가 실행되면
sn-recovery-postinstall.sh그리드 관리자에서 복구 페이지를 모니터링합니다.복구 페이지의 진행 표시줄과 단계 열은 스크립트의 상위 수준 상태를
sn-recovery-postinstall.sh제공합니다.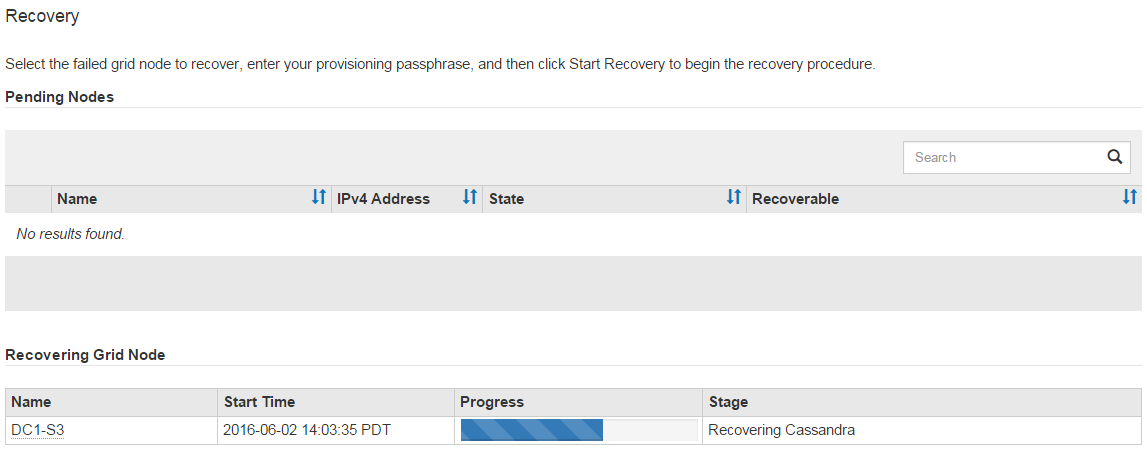
-
스크립트가 노드에서 서비스를 시작한 후에는
sn-recovery-postinstall.sh스크립트로 포맷된 모든 스토리지 볼륨에 오브젝트 데이터를 복원할 수 있습니다.이 스크립트는 Grid Manager 볼륨 복원 프로세스를 사용할 것인지 묻습니다.
-
대부분의 경우, "Grid Manager를 사용하여 개체 데이터를 복원합니다"해야 합니다. Grid Manager를 사용하려면 `y`에 답하십시오.
-
교체 노드의 객체 스토리지 사용 가능 볼륨 수가 원래 노드보다 적은 경우와 같은 드문 경우에는 기술 지원에 문의하여 객체 데이터를 수동으로 복원하십시오. 이러한 경우 중 하나에 해당하면 `n`로 답하고 아무 키나 눌러 명령줄로 돌아가십시오.
-