

Identificar o problema e executar ações corretivas para um trabalho de proteção com falha
 Sugerir alterações
Sugerir alterações
Você analisa a mensagem de erro de falha do trabalho no campo causa na página de detalhes do evento e determina que o trabalho falhou devido a um erro de cópia Snapshot. Em seguida, avance para a página de detalhes de volume / Saúde para obter mais informações.
Tem de ter a função Administrador de aplicações.
A mensagem de erro fornecida no campo causa na página de detalhes do evento contém o seguinte texto sobre o trabalho com falha:
Protection Job Failed. Reason: (Transfer operation for relationship 'cluster2_src_svm:cluster2_src_vol2->cluster3_dst_svm: managed_svc2_vol3' ended unsuccessfully. Last error reported by Data ONTAP: Failed to create Snapshot copy 0426cluster2_src_vol2snap on volume cluster2_src_svm:cluster2_src_vol2. (CSM: An operation failed due to an ONC RPC failure.) Job Details
Esta mensagem fornece as seguintes informações:
-
Um trabalho de cópia de segurança ou espelho não foi concluído com êxito.
A tarefa envolveu uma relação de proteção entre o volume de origem
cluster2_src_vol2no servidor virtualcluster2_src_svme o volume de destinomanaged_svc2_vol3no servidor virtual chamadocluster3_dst_svm. -
Um trabalho de cópia Snapshot falhou para o
0426cluster2_src_vol2snapvolume de origemcluster2_src_svm:/cluster2_src_vol2.
Nesse cenário, você pode identificar a causa e as possíveis ações corretivas da falha do trabalho. No entanto, a resolução da falha requer que você acesse a IU da Web do Gerenciador do sistema ou os comandos da CLI do ONTAP.
-
Você analisa a mensagem de erro e determina que uma tarefa de cópia Snapshot falhou no volume de origem, indicando que provavelmente há um problema com o volume de origem.
Opcionalmente, você pode clicar no link Detalhes da tarefa no final da mensagem de erro, mas para os fins deste cenário, você escolhe não fazer isso.
-
Você decide que deseja tentar resolver o evento, para fazer o seguinte:
-
Clique no botão Assign to e selecione me no menu.
-
Clique no botão confirmar para que você não continue a receber notificações de alerta repetidas, se os alertas tiverem sido definidos para o evento.
-
Opcionalmente, você também pode adicionar notas sobre o evento.
-
-
Clique no campo fonte no painel Resumo para ver detalhes sobre o volume de origem.
O campo Source contém o nome do objeto de origem: Neste caso, o volume no qual o trabalho de cópia Snapshot foi agendado.
A página de detalhes de volume / Saúde é exibida para
cluster2_src_vol2, mostrando o conteúdo da guia proteção. -
Olhando para o gráfico de topologia de proteção, você vê um ícone de erro associado ao primeiro volume na topologia, que é o volume de origem da relação SnapMirror.
Você também vê as barras horizontais no ícone de volume de origem, indicando os limites de aviso e erro definidos para esse volume.
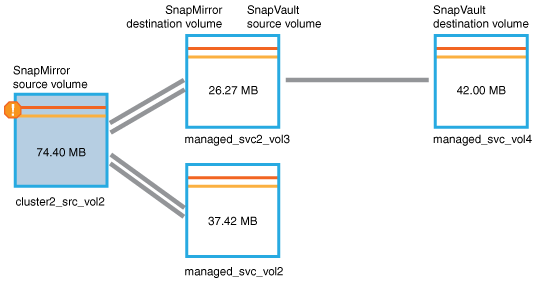
-
Coloque o cursor sobre o ícone de erro para ver a caixa de diálogo pop-up que exibe as configurações de limite e ver que o volume excedeu o limite de erro, indicando um problema de capacidade.
-
Clique na guia capacidade.
Informações sobre a capacidade sobre as exibições de volume
cluster2_src_vol2. -
No painel Capacity, você vê que há um ícone de erro no gráfico de barras, indicando novamente que a capacidade do volume ultrapassou o nível de limite definido para o volume.
-
Abaixo do gráfico de capacidade, você vê que o crescimento automático de volume foi desativado e que uma garantia de espaço de volume foi definida.
Você pode decidir ativar o crescimento automático, mas para os fins desse cenário, você decide investigar mais antes de tomar uma decisão sobre como resolver o problema de capacidade.
-
Role para baixo até a lista Eventos e veja que os eventos Falha no trabalho de proteção, dias de volume até cheio e espaço de volume cheio foram gerados.
-
Na lista Eventos, você clica no evento espaço em volume completo para obter mais informações, tendo decidido que esse evento parece mais relevante para o seu problema de capacidade.
A página Detalhes do evento exibe o evento espaço de volume completo para o volume de origem.
-
Na área Resumo, você lê o campo causa do evento:
The full threshold set at 90% is breached. 45.38 MB (95.54%) of 47.50 MB is used. -
Abaixo da área Resumo, você verá ações corretivas sugeridas.

As ações corretivas sugeridas são exibidas apenas para alguns eventos, para que você não veja essa área para todos os tipos de eventos.
Você clica na lista de ações sugeridas que você pode executar para resolver o evento espaço de volume cheio:
-
Ative o crescimento automático neste volume.
-
Redimensione o volume.
-
Habilite e execute a deduplicação nesse volume.
-
Ative e execute a compactação neste volume.
-
-
Você decide ativar o crescimento automático no volume, mas para isso, você deve determinar o espaço livre disponível no agregado pai e a taxa de crescimento do volume atual:
-
Observe o agregado pai,
cluster2_src_aggr1, no painel Related Devices (dispositivos relacionados).
Você pode clicar no nome do agregado para obter mais detalhes sobre o agregado.
Você determina que o agregado tem espaço suficiente para ativar o volume com crescimento automático.
-
Na parte superior da página, olhe para o ícone que indica um incidente crítico e reveja o texto abaixo do ícone.
Você determina que "dias completos: Menos de um dia | taxa de crescimento diária: 5,4%".
-
-
Vá para o Gerenciador do sistema ou acesse a CLI do ONTAP para ativar a
volume autogrowopção.
Anote os nomes do volume e do agregado para que você os tenha disponíveis ao ativar o crescimento automático.
-
Depois de resolver o problema de capacidade, retorne à página de detalhes do evento do Unified Manager e marque o evento como resolvido.