

Como o Unified Manager usa a latência do workload para identificar problemas de performance
 Sugerir alterações
Sugerir alterações
A latência do workload (tempo de resposta) é o tempo necessário para um volume em um cluster responder a solicitações de e/S de aplicativos clientes. O Unified Manager usa a latência para detectar e alertar você sobre eventos de performance.
Uma alta latência significa que as solicitações de aplicativos para um volume em um cluster estão demorando mais do que o normal. A causa da alta latência pode estar no próprio cluster, devido à contenção em um ou mais componentes do cluster. A alta latência também pode ser causada por problemas fora do cluster, como gargalos de rede, problemas com o cliente que hospeda os aplicativos ou problemas com os próprios aplicativos.

|
O Unified Manager monitora apenas a atividade do workload no cluster. Ele não monitora os aplicativos, os clientes ou os caminhos entre os aplicativos e o cluster. |
As operações no cluster, como fazer backups ou executar deduplicação, que aumentam a demanda por componentes de cluster compartilhados por outros workloads, também podem contribuir para a alta latência. Se a latência real exceder o limite de desempenho dinâmico do intervalo esperado (previsão de latência), o Unified Manager analisa o evento para determinar se é um evento de desempenho que talvez você precise resolver. A latência é medida em milissegundos por operação (ms/op).
No gráfico total de latência na página análise de workload, é possível visualizar uma análise das estatísticas de latência para ver como a atividade de processos individuais, como solicitações de leitura e gravação, se compara às estatísticas de latência geral. A comparação ajuda você a determinar quais operações têm a atividade mais alta ou se operações específicas têm atividade anormal que está afetando a latência de um volume. Ao analisar eventos de desempenho, você pode usar as estatísticas de latência para determinar se um evento foi causado por um problema no cluster. Você também pode identificar as atividades específicas de workload ou os componentes de cluster envolvidos no evento.
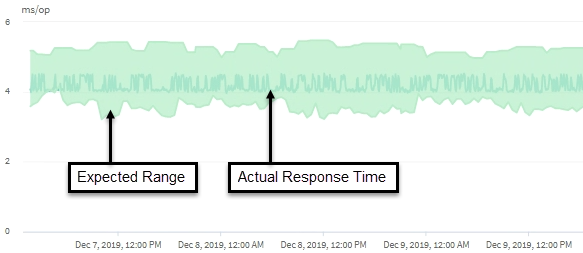
Este exemplo mostra o gráfico de latência . A atividade de tempo de resposta real (latência) é uma linha azul e a previsão de latência (intervalo esperado) é verde.
|
|
Pode haver lacunas na linha azul se o Unified Manager não conseguir coletar dados. Isso pode ocorrer porque o cluster ou o volume estava inalcançável, o Unified Manager foi desativado durante esse tempo ou a coleção demorava mais do que o período de coleta de 5 minutos. |