

Hierarquização de dados de clusters ONTAP locais para StorageGRID no NetApp Cloud Tiering
 Sugerir alterações
Sugerir alterações
Libere espaço em seus clusters ONTAP locais hierarquizando dados inativos no StorageGRID no NetApp Cloud Tiering.
Início rápido
Comece rapidamente seguindo estas etapas ou role para baixo até as seções restantes para obter detalhes completos.
 Preparar para hierarquizar dados no StorageGRID
Preparar para hierarquizar dados no StorageGRIDVocê precisa do seguinte:
-
Um cluster ONTAP local de origem que executa o ONTAP 9.4 ou posterior que você adicionou ao NetApp Console e uma conexão por uma porta especificada pelo usuário para o StorageGRID. "Aprenda como descobrir um cluster" .
-
StorageGRID 10.3 ou posterior com chaves de acesso da AWS que tenham permissões S3.
-
Um agente do Console instalado em suas instalações.
-
Rede para o agente que permite uma conexão HTTPS de saída para o cluster ONTAP , para o StorageGRID e para o serviço Cloud Tiering.
 Configurar níveis
Configurar níveisNo NetApp Console, selecione um sistema local, selecione Ativar para Camadas de Nuvem e siga as instruções para colocar os dados em camadas no StorageGRID.
Requisitos
Verifique o suporte para seu cluster ONTAP , configure sua rede e prepare seu armazenamento de objetos.
A imagem a seguir mostra cada componente e as conexões que você precisa preparar entre eles:
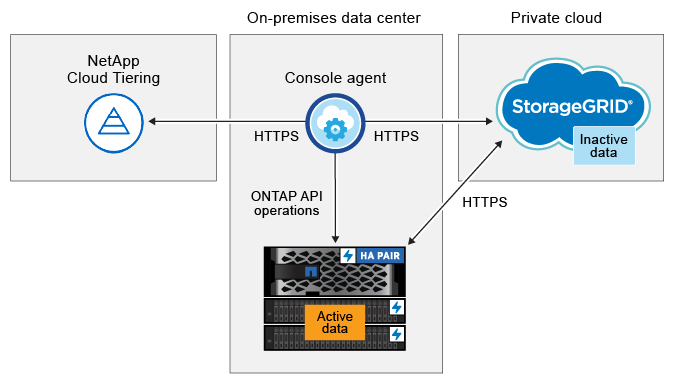

|
A comunicação entre o agente e o StorageGRID é somente para configuração de armazenamento de objetos. |
Prepare seus clusters ONTAP
Seus clusters ONTAP devem atender aos seguintes requisitos ao hierarquizar dados no StorageGRID.
- Plataformas ONTAP suportadas
-
-
Ao usar o ONTAP 9.8 e posterior: você pode hierarquizar dados de sistemas AFF ou sistemas FAS com agregados totalmente SSD ou totalmente HDD.
-
Ao usar o ONTAP 9.7 e versões anteriores: você pode hierarquizar dados de sistemas AFF ou sistemas FAS com agregados totalmente SSD.
-
- Versão ONTAP suportada
-
ONTAP 9.4 ou posterior
- Licenciamento
-
Uma licença de Cloud Tiering não é necessária na sua organização do NetApp Console , nem uma licença FabricPool é necessária no cluster ONTAP ao hierarquizar dados no StorageGRID.
- Requisitos de rede do cluster
-
-
O cluster ONTAP inicia uma conexão HTTPS por meio de uma porta especificada pelo usuário para o nó do StorageGRID Gateway (a porta é configurável durante a configuração de camadas).
ONTAP lê e grava dados de e para armazenamento de objetos. O armazenamento de objetos nunca inicia, ele apenas responde.
-
É necessária uma conexão de entrada do agente, que deve residir em suas instalações.
Não é necessária uma conexão entre o cluster e o serviço Cloud Tiering.
-
Um LIF intercluster é necessário em cada nó ONTAP que hospeda os volumes que você deseja hierarquizar. O LIF deve ser associado ao IPspace que o ONTAP deve usar para se conectar ao armazenamento de objetos.
Ao configurar o armazenamento em camadas de dados, o Cloud Tiering solicita o IPspace a ser usado. Você deve escolher o IPspace ao qual cada LIF está associado. Pode ser o IPspace "padrão" ou um IPspace personalizado que você criou. Saiba mais sobre "LIFs" e "Espaços IP" .
-
- Volumes e agregados suportados
-
O número total de volumes que o Cloud Tiering pode hierarquizar pode ser menor que o número de volumes no seu sistema ONTAP . Isso ocorre porque os volumes não podem ser hierarquizados a partir de alguns agregados. Consulte a documentação do ONTAP para "funcionalidade ou recursos não suportados pelo FabricPool" .
|
|
O Cloud Tiering oferece suporte a volumes FlexGroup , a partir do ONTAP 9.5. A configuração funciona da mesma forma que qualquer outro volume. |
Descubra um cluster ONTAP
Você precisa adicionar um sistema ONTAP local ao NetApp Console antes de começar a hierarquizar dados frios.
Preparar StorageGRID
O StorageGRID deve atender aos seguintes requisitos.
- Versões do StorageGRID suportadas
-
O StorageGRID 10.3 e versões posteriores são suportados.
- Credenciais S3
-
Ao configurar o hierarquização para o StorageGRID, você precisa fornecer ao Cloud Tiering uma chave de acesso S3 e uma chave secreta. O Cloud Tiering usa as chaves para acessar seus buckets.
Essas chaves de acesso devem ser associadas a um usuário que tenha as seguintes permissões:
"s3:ListAllMyBuckets", "s3:ListBucket", "s3:GetObject", "s3:PutObject", "s3:DeleteObject", "s3:CreateBucket" - Controle de versão de objetos
-
Você não deve habilitar o controle de versão do objeto StorageGRID no bucket do armazenamento de objetos.
Criar ou alternar agentes do Console
O agente do Console é necessário para hierarquizar dados na nuvem. Ao hierarquizar dados no StorageGRID, um agente deve estar disponível em suas instalações.
Você deve ter a função de administrador da organização para criar um agente.
Preparar a rede para o agente do Console
Certifique-se de que o agente tenha as conexões de rede necessárias.
-
Certifique-se de que a rede onde o agente está instalado habilite as seguintes conexões:
-
Uma conexão HTTPS pela porta 443 para o serviço Cloud Tiering("veja a lista de pontos de extremidade" )
-
Uma conexão HTTPS pela porta 443 para seu sistema StorageGRID
-
Uma conexão HTTPS pela porta 443 para seu LIF de gerenciamento de cluster ONTAP
-
Dados inativos em camadas do seu primeiro cluster para o StorageGRID
Depois de preparar seu ambiente, comece a hierarquizar os dados inativos do seu primeiro cluster.
-
O FQDN do nó do gateway StorageGRID e a porta que será usada para comunicações HTTPS.
-
Uma chave de acesso da AWS que tenha as permissões S3 necessárias.
-
Selecione o sistema ONTAP local.
-
Clique em Ativar para Camadas de Nuvem no painel direito.
Se o destino de camadas do StorageGRID existir como um sistema no NetApp Console, você poderá arrastar o cluster para o sistema StorageGRID para iniciar o assistente de configuração.
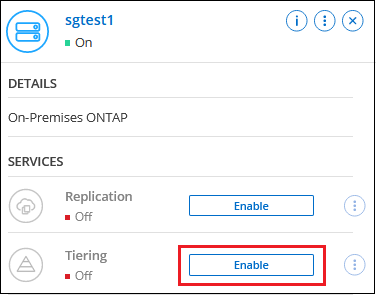
-
Definir nome do armazenamento de objetos: insira um nome para este armazenamento de objetos. Ele deve ser exclusivo de qualquer outro armazenamento de objetos que você possa estar usando com agregados neste cluster.
-
Selecionar Provedor: Selecione * StorageGRID* e selecione Continuar.
-
Conclua as etapas nas páginas Criar armazenamento de objetos:
-
Servidor: Insira o FQDN do nó do gateway StorageGRID , a porta que o ONTAP deve usar para comunicação HTTPS com o StorageGRID e a chave de acesso e a chave secreta para uma conta que tenha as permissões S3 necessárias.
-
Bucket: adicione um novo bucket ou selecione um bucket existente que comece com o prefixo fabric-pool e selecione Continuar.
O prefixo fabric-pool é necessário porque a política do IAM para o agente permite que a instância execute ações do S3 em buckets nomeados com esse prefixo exato. Por exemplo, você pode nomear o bucket S3 fabric-pool-AFF1, onde AFF1 é o nome do cluster.
-
Rede de cluster: Selecione o espaço IP que o ONTAP deve usar para se conectar ao armazenamento de objetos e selecione Continuar.
Selecionar o IPspace correto garante que o Cloud Tiering possa configurar uma conexão do ONTAP para o armazenamento de objetos StorageGRID .
Você também pode definir a largura de banda de rede disponível para carregar dados inativos no armazenamento de objetos definindo a "Taxa máxima de transferência". Selecione o botão de opção Limitado e insira a largura de banda máxima que pode ser usada ou selecione Ilimitado para indicar que não há limite.
-
-
Na página Volumes em camadas, selecione os volumes para os quais você deseja configurar o escalonamento e inicie a página Política de escalonamento:
-
Para selecionar todos os volumes, marque a caixa na linha de título (
 ) e selecione Configurar volumes.
) e selecione Configurar volumes. -
Para selecionar vários volumes, marque a caixa para cada volume (
 ) e selecione Configurar volumes.
) e selecione Configurar volumes. -
Para selecionar um único volume, selecione a linha (ou
 ícone) para o volume.
ícone) para o volume.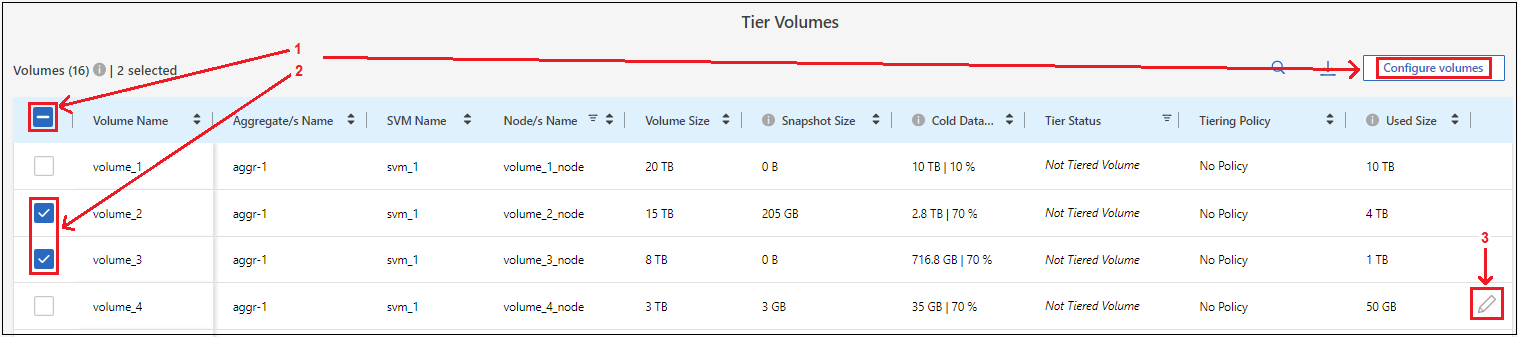
-
-
Na caixa de diálogo Política de níveis, selecione uma política de níveis, ajuste opcionalmente os dias de resfriamento para os volumes selecionados e selecione Aplicar.
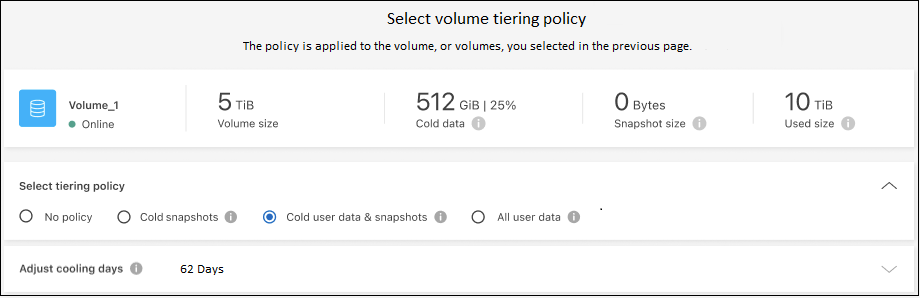
Você pode revisar informações sobre os dados ativos e inativos no cluster. "Saiba mais sobre como gerenciar suas configurações de níveis" .
Você também pode criar armazenamento de objetos adicional nos casos em que deseja hierarquizar dados de determinados agregados em um cluster para diferentes armazenamentos de objetos. Ou se você planeja usar o FabricPool Mirroring, onde seus dados em camadas são replicados para um armazenamento de objetos adicional. "Saiba mais sobre como gerenciar armazenamentos de objetos" .