

Saiba mais sobre a NetApp Data Classification
 Sugerir alterações
Sugerir alterações
O NetApp Data Classification é um serviço de governança de dados para o NetApp Console que verifica suas fontes de dados corporativas locais e na nuvem para mapear e classificar dados e identificar informações privadas. Isso pode ajudar a reduzir seus riscos de segurança e conformidade, diminuir custos de armazenamento e auxiliar em seus projetos de migração de dados.

|
A partir da versão 1.31, a Classificação de Dados está disponível como um recurso principal no NetApp Console. Não há custo adicional. Não é necessária nenhuma licença de classificação ou assinatura. + Se você estiver usando a versão legada 1.30 ou anterior, essa versão estará disponível até sua assinatura expirar. |
NetApp Console
A classificação de dados pode ser acessada por meio do NetApp Console.
O NetApp Console fornece gerenciamento centralizado de serviços de armazenamento e dados da NetApp em ambientes locais e na nuvem em nível empresarial. O Console é necessário para acessar e usar os serviços de dados do NetApp . Como uma interface de gerenciamento, ele permite que você gerencie muitos recursos de armazenamento a partir de uma única interface. Os administradores do console podem controlar o acesso ao armazenamento e aos serviços de todos os sistemas da empresa.
Você não precisa de uma licença ou assinatura para começar a usar o NetApp Console e só incorrerá em cobranças quando precisar implantar agentes do Console na sua nuvem para garantir a conectividade com seus sistemas de armazenamento ou serviços de dados do NetApp . No entanto, alguns serviços de dados da NetApp acessíveis pelo Console são licenciados ou baseados em assinatura.
Saiba mais sobre o"NetApp Console" .
Características
A classificação de dados usa inteligência artificial (IA), processamento de linguagem natural (PLN) e aprendizado de máquina (ML) para entender o conteúdo que ela verifica, a fim de extrair entidades e categorizar o conteúdo adequadamente. Isso permite que a Classificação de Dados forneça as seguintes áreas de funcionalidade.
A Classificação de Dados fornece diversas ferramentas que podem ajudar em seus esforços de conformidade. Você pode usar a Classificação de Dados para:
-
Identifique Informações Pessoais Identificáveis (PII).
-
Identifique uma ampla gama de informações pessoais confidenciais, conforme exigido pelos regulamentos de privacidade GDPR, CCPA, PCI e HIPAA.
-
Responda às solicitações de acesso do titular dos dados (DSAR) com base no nome ou endereço de e-mail.
A Classificação de Dados pode identificar dados que correm risco potencial de serem acessados para fins criminosos. Você pode usar a Classificação de Dados para:
-
Identifique todos os arquivos e diretórios (compartilhamentos e pastas) com permissões abertas que estão expostos a toda a sua organização ou ao público.
-
Identifique dados confidenciais que residem fora do local inicial dedicado.
-
Cumpra as políticas de retenção de dados.
-
Use Políticas para detectar automaticamente novos problemas de segurança para que a equipe de segurança possa agir imediatamente.
A Classificação de Dados fornece ferramentas que podem ajudar com o custo total de propriedade (TCO) do seu armazenamento. Você pode usar a Classificação de Dados para:
-
Aumente a eficiência do armazenamento identificando dados duplicados ou não relacionados aos negócios.
-
Economize custos de armazenamento identificando dados inativos que você pode colocar em camadas para armazenamento de objetos mais barato. "Saiba mais sobre camadas dos sistemas Cloud Volumes ONTAP" . "Saiba mais sobre camadas de sistemas ONTAP locais" .
Sistemas e fontes de dados suportados
A Classificação de Dados pode escanear e analisar dados estruturados e não estruturados dos seguintes tipos de sistemas e fontes de dados:
Sistemas
-
Amazon FSx for NetApp ONTAP
-
Azure NetApp Files
-
Cloud Volumes ONTAP (implantado na AWS, Azure ou GCP)
-
Google Cloud NetApp Volumes
-
Clusters ONTAP locais
-
StorageGRID
Fontes de dados
-
Compartilhamentos de arquivos NetApp
-
Bancos de dados:
-
Serviço de banco de dados relacional da Amazon (Amazon RDS)
-
MongoDB
-
MySQL
-
Oráculo
-
PostgreSQL
-
SAP HANA
-
Servidor SQL (MSSQL)
-
A Classificação de Dados oferece suporte às versões 3.x, 4.0 e 4.1 do NFS e às versões 1.x, 2.0, 2.1 e 3.0 do CIFS.
Custo
A Classificação de Dados é de uso gratuito. Não é necessária nenhuma licença de classificação ou assinatura paga.
Custos de infraestrutura
-
A instalação do Data Classification na nuvem requer a implantação de uma instância de nuvem, o que resulta em cobranças do provedor de nuvem onde ela é implantada. Ver o tipo de instância que é implantada para cada provedor de nuvem . Não há custo se você instalar o Data Classification em um sistema local.
-
A Classificação de Dados exige que você tenha implantado um agente do Console. Em muitos casos, você já tem um agente do Console por causa de outros armazenamentos e serviços que está usando no Console. A instância do agente do Console resulta em cobranças do provedor de nuvem onde é implantada. Veja o "tipo de instância que é implantada para cada provedor de nuvem" . Não há custo se você instalar o agente do Console em um sistema local.
Custos de transferência de dados
Os custos de transferência de dados dependem da sua configuração. Se a instância de Classificação de Dados e a fonte de dados estiverem na mesma Zona de Disponibilidade e região, não haverá custos de transferência de dados. Mas se a fonte de dados, como um sistema Cloud Volumes ONTAP , estiver em uma zona de disponibilidade ou região diferente, você será cobrado pelo seu provedor de nuvem pelos custos de transferência de dados. Veja estes links para mais detalhes:
A instância de classificação de dados
Quando você implanta a Classificação de Dados na nuvem, o Console implanta a instância na mesma sub-rede que o agente do Console. "Saiba mais sobre o agente do Console."
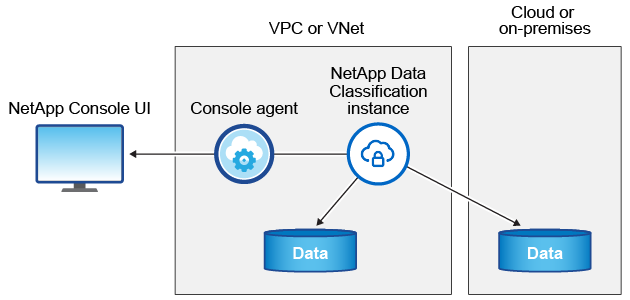
Observe o seguinte sobre a instância padrão:
-
Na AWS, a Classificação de Dados é executada em um "instância m6i.4xlarge" com um disco GP2 de 500 GiB. A imagem do sistema operacional é o Amazon Linux 2.
-
No Azure, a Classificação de Dados é executada em um"Standard_D16s_v3 VM" com um disco de 500 GiB. A imagem do sistema operacional é o Ubuntu 22.04.
-
No GCP, a Classificação de Dados é executada em um"VM n2-padrão-16" com um disco persistente padrão de 500 GiB. A imagem do sistema operacional é o Ubuntu 22.04.
-
Em regiões onde a instância padrão não está disponível, a Classificação de Dados é executada em uma instância alternativa. "Veja os tipos de instância alternativos" .
-
A instância é denominada CloudCompliance com um hash gerado (UUID) concatenado a ela. Por exemplo: CloudCompliance-16bb6564-38ad-4080-9a92-36f5fd2f71c7
-
Apenas uma instância de Classificação de Dados é implantada por Agente de Console.
Você também pode implantar a Classificação de Dados em um host Linux em suas instalações ou em um host em seu provedor de nuvem preferido. O software funciona exatamente da mesma maneira, independentemente do método de instalação escolhido. As atualizações do software de classificação de dados são automatizadas desde que a instância tenha acesso à Internet.

|
A instância deve permanecer em execução o tempo todo porque a Classificação de Dados verifica os dados continuamente. |
Implantar em diferentes tipos de instância
Revise as seguintes especificações para tipos de instância:
| Tamanho do sistema | Especificações | Limitações |
|---|---|---|
Extra grande |
32 CPUs, 128 GB de RAM, 1 TiB SSD |
Pode escanear até 500 milhões de arquivos. |
Grande (padrão) |
16 CPUs, 64 GB de RAM, SSD de 500 GiB |
Pode escanear até 250 milhões de arquivos. |
Como funciona a varredura de classificação de dados
Em um nível mais alto, a varredura de classificação de dados funciona assim:
-
Você implanta uma instância de Classificação de Dados no Console.
-
Você habilita as verificações em uma ou mais fontes de dados.
-
A Classificação de Dados analisa dados usando um processo de aprendizado de IA.
-
Use os painéis e ferramentas de relatórios fornecidos para ajudar em seus esforços de conformidade e governança.
Depois de habilitar a Classificação de Dados e selecionar os repositórios que você deseja verificar (volumes, esquemas de banco de dados ou outros dados do usuário), ele imediatamente inicia a verificação dos dados para identificar dados pessoais e confidenciais. Na maioria dos casos, você deve se concentrar na digitalização de dados de produção ao vivo, em vez de backups, espelhos ou sites de DR. Em seguida, a Classificação de Dados mapeia seus dados organizacionais, categoriza cada arquivo e identifica e extrai entidades e padrões predefinidos nos dados. O resultado da verificação é um índice de informações pessoais, informações pessoais confidenciais, categorias de dados e tipos de arquivo.
A Classificação de Dados se conecta aos dados como qualquer outro cliente montando volumes NFS e CIFS. Os volumes NFS são acessados automaticamente como somente leitura, enquanto você precisa fornecer credenciais do Active Directory para verificar volumes CIFS.
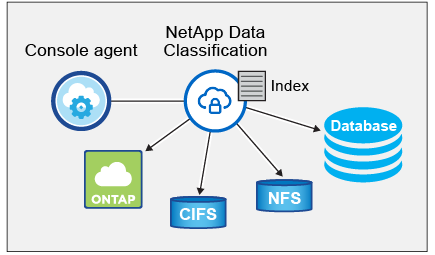
Após a verificação inicial, a Classificação de Dados verifica continuamente seus dados em um sistema round-robin para detectar alterações incrementais. É por isso que é importante manter a instância em execução.
Você pode habilitar e desabilitar verificações no nível do volume ou no nível do esquema do banco de dados.

|
A Classificação de Dados não impõe um limite à quantidade de dados que pode escanear. Cada agente do Console suporta a digitalização e a exibição de 500 TiB de dados. Para escanear mais de 500 TiB de dados,"instalar outro agente do Console" então"implantar outra instância de Classificação de Dados" . + A interface do usuário do console exibe dados de um único conector. Para obter dicas sobre como visualizar dados de vários agentes do Console, consulte"Trabalhar com vários agentes do Console" . |
Mapeamento e escaneamento completo
Você pode realizar dois tipos de varreduras na Classificação de Dados:
-
As varreduras somente de mapa fornecem apenas uma visão geral de alto nível dos seus dados e são realizadas em fontes de dados selecionadas. As varreduras somente de mapa levam menos tempo do que as varreduras completas porque não acessam os arquivos para ver os dados internos. Você pode optar por essa abordagem inicialmente para identificar áreas de pesquisa e, em seguida, realizar uma varredura completa nessas áreas.
-
As varreduras completas fornecem uma varredura em nível profundo dos seus dados. Uma varredura completa inclui uma varredura somente de mapa e uma classificação dos dados dentro dos arquivos.
Para uma análise detalhada das diferenças entre varreduras apenas com mapa e varreduras completas, consulte "Qual é a diferença entre varreduras de mapeamento e classificação?".
Informações que a Classificação de Dados categoriza
A Classificação de Dados coleta, indexa e atribui categorias aos seguintes dados:
-
Metadados padrão sobre arquivos: o tipo de arquivo, seu tamanho, datas de criação e modificação e assim por diante.
-
Dados pessoais: Informações de identificação pessoal (PII), como endereços de e-mail, números de identificação ou números de cartão de crédito, que a Classificação de Dados identifica usando palavras, sequências de caracteres e padrões específicos nos arquivos. "Saiba mais sobre dados pessoais" .
-
Dados pessoais sensíveis: Tipos especiais de informações pessoais sensíveis (SPII), como dados de saúde, origem étnica ou opiniões políticas, conforme definido pelo Regulamento Geral de Proteção de Dados (GDPR) e outros regulamentos de privacidade. "Saiba mais sobre dados pessoais sensíveis" .
-
Categorias: A classificação de dados pega os dados escaneados e os divide em diferentes tipos de categorias. Categorias são tópicos baseados na análise de IA do conteúdo e metadados de cada arquivo. "Saiba mais sobre categorias".
-
Reconhecimento de entidade de nome: A classificação de dados usa IA para extrair nomes naturais de pessoas de documentos. "Saiba mais sobre como responder às solicitações de acesso do titular dos dados" .
Visão geral da rede
A Classificação de Dados implanta um único servidor, ou cluster, onde você escolher: na nuvem ou no local. Os servidores se conectam por meio de protocolos padrão às fontes de dados e indexam as descobertas em um cluster do Elasticsearch, que também é implantado nos mesmos servidores. Isso permite suporte para ambientes multi-cloud, cross-cloud, nuvem privada e locais.
O Console implanta a instância de Classificação de Dados com um grupo de segurança que permite conexões HTTP de entrada do agente do Console.
Quando você usa o Console no modo SaaS, a conexão com o Console é feita por HTTPS, e os dados privados enviados entre seu navegador e a instância de Classificação de Dados são protegidos com criptografia de ponta a ponta usando TLS 1.2, o que significa que a NetApp e terceiros não podem lê-los.
As regras de saída são completamente abertas. O acesso à Internet é necessário para instalar e atualizar o software de classificação de dados e para enviar métricas de uso.
Se você tiver requisitos de rede rigorosos,"aprenda sobre os endpoints que a Classificação de Dados contata" .