Principais casos de uso e arquiteturas de IA, ML e DL
 Sugerir alterações
Sugerir alterações
Os principais casos de uso e metodologia de IA, ML e DL podem ser divididos nas seguintes seções:
Pipelines Spark NLP e inferência distribuída TensorFlow
A lista a seguir contém as bibliotecas de PNL de código aberto mais populares que foram adotadas pela comunidade de ciência de dados em diferentes níveis de desenvolvimento:
-
"Kit de ferramentas de linguagem natural (NLTK)" . O kit de ferramentas completo para todas as técnicas de PNL. Ela vem sendo mantida desde o início dos anos 2000.
-
"TextBlob" . Uma API Python de ferramentas de PNL fácil de usar, construída sobre NLTK e Pattern.
-
"Stanford Core NLP" . Serviços e pacotes de PNL em Java desenvolvidos pelo Stanford NLP Group.
-
"Gensim" . O Topic Modelling for Humans começou como uma coleção de scripts Python para o projeto da Biblioteca Matemática Digital Tcheca.
-
"SpaCy" . Fluxos de trabalho de PNL industrial de ponta a ponta com Python e Cython com aceleração de GPU para transformadores.
-
"Texto rápido" . Uma biblioteca de PNL gratuita, leve e de código aberto para aprendizado de incorporação de palavras e classificação de frases, criada pelo laboratório de pesquisa de IA (FAIR) do Facebook.
O Spark NLP é uma solução única e unificada para todas as tarefas e requisitos de PNL que permite software de PNL escalável, de alto desempenho e alta precisão para casos de uso de produção real. Ela aproveita a aprendizagem por transferência e implementa os algoritmos e modelos mais modernos em pesquisas e em todos os setores. Devido à falta de suporte total do Spark para as bibliotecas acima, o Spark NLP foi construído sobre "Spark ML" para aproveitar o mecanismo de processamento de dados distribuídos na memória de uso geral do Spark como uma biblioteca de PNL de nível empresarial para fluxos de trabalho de produção de missão crítica. Seus anotadores utilizam algoritmos baseados em regras, aprendizado de máquina e TensorFlow para impulsionar implementações de aprendizado profundo. Isso abrange tarefas comuns de PNL, incluindo, mas não se limitando a tokenização, lematização, definição de radicais, marcação de classes gramaticais, reconhecimento de entidades nomeadas, verificação ortográfica e análise de sentimentos.
Representações de codificador bidirecional de transformadores (BERT) é uma técnica de aprendizado de máquina baseada em transformadores para PNL. Popularizou o conceito de pré-treinamento e ajuste fino. A arquitetura do transformador no BERT originou-se da tradução automática, que modela dependências de longo prazo melhor do que modelos de linguagem baseados em Redes Neurais Recorrentes (RNN). Ele também introduziu a tarefa de Modelagem de Linguagem Mascarada (MLM), onde 15% aleatórios de todos os tokens são mascarados e o modelo os prevê, permitindo verdadeira bidirecionalidade.
A análise do sentimento financeiro é desafiadora devido à linguagem especializada e à falta de dados rotulados nesse domínio. FinBERT, um modelo de linguagem baseado em BERT pré-treinado, foi adaptado ao domínio em "Reuters TRC2" , um corpus financeiro e ajustado com dados rotulados ( "Banco de Frases Financeiro" ) para classificação de sentimento financeiro. Pesquisadores extraíram 4.500 frases de artigos de notícias com termos financeiros. Em seguida, 16 especialistas e estudantes de mestrado com formação em finanças rotularam as frases como positivas, neutras e negativas. Construímos um fluxo de trabalho Spark de ponta a ponta para analisar o sentimento das transcrições de teleconferências sobre os lucros das 10 maiores empresas da NASDAQ de 2016 a 2020 usando FinBERT e dois outros pipelines pré-treinados, "Explicar Documento DL" ) do Spark NLP.
O mecanismo de aprendizado profundo subjacente ao Spark NLP é o TensorFlow, uma plataforma de ponta a ponta e de código aberto para aprendizado de máquina que permite a construção fácil de modelos, produção robusta de ML em qualquer lugar e experimentação poderosa para pesquisa. Portanto, ao executar nossos pipelines no Spark yarn cluster modo, estávamos essencialmente executando o TensorFlow distribuído com paralelismo de dados e modelos em um nó mestre e vários nós de trabalho, bem como armazenamento conectado à rede montado no cluster.
Treinamento distribuído Horovod
A validação principal do Hadoop para desempenho relacionado ao MapReduce é realizada com TeraGen, TeraSort, TeraValidate e DFSIO (leitura e gravação). Os resultados da validação do TeraGen e do TeraSort são apresentados em "Solução NetApp E-Series para Hadoop" e na seção "Storage Tiering" para AFF.
Com base nas solicitações dos clientes, consideramos o treinamento distribuído com Spark um dos mais importantes entre os vários casos de uso. Neste documento, utilizamos o "Hovorod no Spark" para validar o desempenho do Spark com soluções NetApp locais, nativas da nuvem e de nuvem híbrida usando controladores de armazenamento NetApp All Flash FAS (AFF), Azure NetApp Files e StorageGRID.
O pacote Horovod no Spark fornece um wrapper conveniente em torno do Horovod que simplifica a execução de cargas de trabalho de treinamento distribuídas em clusters Spark, permitindo um loop de design de modelo preciso no qual o processamento de dados, o treinamento do modelo e a avaliação do modelo são todos feitos no Spark, onde residem os dados de treinamento e inferência.
Há duas APIs para executar o Horovod no Spark: uma API Estimator de alto nível e uma API Run de nível inferior. Embora ambos usem o mesmo mecanismo subjacente para iniciar o Horovod nos executores do Spark, a API Estimator abstrai o processamento de dados, o loop de treinamento do modelo, o ponto de verificação do modelo, a coleta de métricas e o treinamento distribuído. Usamos Horovod Spark Estimators, TensorFlow e Keras para uma preparação de dados de ponta a ponta e um fluxo de trabalho de treinamento distribuído com base no "Vendas da loja Kaggle Rossmann" concorrência.
O roteiro keras_spark_horovod_rossmann_estimator.py pode ser encontrado na seção"Scripts Python para cada caso de uso principal." Ele contém três partes:
-
A primeira parte executa várias etapas de pré-processamento de dados em um conjunto inicial de arquivos CSV fornecidos pelo Kaggle e coletados pela comunidade. Os dados de entrada são separados em um conjunto de treinamento com um
Validationsubconjunto e um conjunto de dados de teste. -
A segunda parte define um modelo de Rede Neural Profunda (DNN) de Keras com função de ativação sigmoide logarítmica e um otimizador de Adam, e realiza o treinamento distribuído do modelo usando Horovod no Spark.
-
A terceira parte realiza a previsão no conjunto de dados de teste usando o melhor modelo que minimiza o erro absoluto médio geral do conjunto de validação. Em seguida, ele cria um arquivo CSV de saída.
Veja a seção"Aprendizado de máquina" para vários resultados de comparação de tempo de execução.
Aprendizado profundo multi-trabalhador usando Keras para previsão de CTR
Com os avanços recentes em plataformas e aplicativos de ML, muita atenção agora está voltada para o aprendizado em escala. A taxa de cliques (CTR) é definida como o número médio de cliques por cem impressões de anúncios on-line (expresso como uma porcentagem). Ela é amplamente adotada como uma métrica-chave em vários setores e casos de uso, incluindo marketing digital, varejo, comércio eletrônico e provedores de serviços. Para obter mais detalhes sobre as aplicações do CTR e os resultados do desempenho do treinamento distribuído, consulte o"Modelos de aprendizado profundo para desempenho de previsão de CTR" seção.
Neste relatório técnico, usamos uma variação do "Conjunto de dados de registros de cliques de terabytes da Criteo" (consulte TR-4904) para aprendizado profundo distribuído por vários trabalhadores usando Keras para criar um fluxo de trabalho Spark com modelos Deep and Cross Network (DCN), comparando seu desempenho em termos de função de erro de perda de log com um modelo de regressão logística Spark ML de base. O DCN captura eficientemente interações de recursos eficazes de graus limitados, aprende interações altamente não lineares, não requer engenharia de recursos manual ou pesquisa exaustiva e tem baixo custo computacional.
Os dados para sistemas de recomendação em escala da web são, em sua maioria, discretos e categóricos, o que leva a um espaço de recursos grande e esparso, o que é desafiador para a exploração de recursos. Isso limitou a maioria dos sistemas de larga escala a modelos lineares, como a regressão logística. No entanto, identificar características frequentemente preditivas e, ao mesmo tempo, explorar características cruzadas raras ou invisíveis é a chave para fazer boas previsões. Os modelos lineares são simples, interpretáveis e fáceis de escalar, mas são limitados em seu poder expressivo.
Por outro lado, recursos transversais demonstraram ser significativos na melhoria da expressividade dos modelos. Infelizmente, muitas vezes é necessária engenharia de recursos manual ou pesquisa exaustiva para identificar tais recursos. Generalizar para interações de recursos invisíveis costuma ser difícil. Usar uma rede neural cruzada como a DCN evita a engenharia de recursos específicos da tarefa ao aplicar explicitamente o cruzamento de recursos de forma automática. A rede cruzada consiste em múltiplas camadas, onde o maior grau de interações é provavelmente determinado pela profundidade da camada. Cada camada produz interações de ordem superior com base nas existentes e mantém as interações das camadas anteriores.
Uma rede neural profunda (DNN) tem a promessa de capturar interações muito complexas entre recursos. Entretanto, comparado ao DCN, ele requer quase uma ordem de magnitude a mais de parâmetros, não é capaz de formar recursos cruzados explicitamente e pode falhar em aprender eficientemente alguns tipos de interações de recursos. A rede cruzada é eficiente em termos de memória e fácil de implementar. O treinamento conjunto dos componentes cruzados e DNN captura com eficiência interações de recursos preditivos e oferece desempenho de última geração no conjunto de dados CTR da Criteo.
Um modelo DCN começa com uma camada de incorporação e empilhamento, seguida por uma rede cruzada e uma rede profunda em paralelo. Estes, por sua vez, são seguidos por uma camada de combinação final que combina as saídas das duas redes. Seus dados de entrada podem ser um vetor com recursos esparsos e densos. No Spark, as bibliotecas contêm o tipo SparseVector . Portanto, é importante que os usuários diferenciem os dois e tenham cuidado ao chamar suas respectivas funções e métodos. Em sistemas de recomendação em escala web, como a previsão de CTR, as entradas são principalmente características categóricas, por exemplo 'country=usa' . Tais características são frequentemente codificadas como vetores one-hot, por exemplo, '[0,1,0, …]' . Codificação one-hot (OHE) com SparseVector é útil ao lidar com conjuntos de dados do mundo real com vocabulários em constante mudança e crescimento. Nós modificamos exemplos em "DeepCTR" para processar vocabulários grandes, criando vetores de incorporação na camada de incorporação e empilhamento do nosso DCN.
O "Conjunto de dados de anúncios gráficos da Criteo" prevê a taxa de cliques dos anúncios. Ele tem 13 características inteiras e 26 características categóricas, nas quais cada categoria tem uma alta cardinalidade. Para este conjunto de dados, uma melhoria de 0,001 na perda logarítmica é praticamente significativa devido ao grande tamanho de entrada. Uma pequena melhoria na precisão da previsão para uma grande base de usuários pode potencialmente levar a um grande aumento na receita de uma empresa. O conjunto de dados contém 11 GB de registros de usuários de um período de 7 dias, o que equivale a cerca de 41 milhões de registros. Nós usamos Spark dataFrame.randomSplit()function dividir aleatoriamente os dados para treinamento (80%), validação cruzada (10%) e os 10% restantes para teste.
O DCN foi implementado no TensorFlow com Keras. Há quatro componentes principais na implementação do processo de treinamento de modelo com DCN:
-
Processamento e incorporação de dados. Os recursos de valor real são normalizados pela aplicação de uma transformação logarítmica. Para recursos categóricos, incorporamos os recursos em vetores densos de dimensão 6×(cardinalidade da categoria)1/4. Concatenar todos os embeddings resulta em um vetor de dimensão 1026.
-
Otimização. Aplicamos otimização estocástica de minilote com o otimizador Adam. O tamanho do lote foi definido como 512. A normalização em lote foi aplicada à rede profunda e a norma de corte de gradiente foi definida em 100.
-
Regularização. Usamos a parada antecipada, pois a regularização ou o abandono da L2 não se mostraram eficazes.
-
Hiperparâmetros. Relatamos resultados com base em uma pesquisa de grade sobre o número de camadas ocultas, o tamanho da camada oculta, a taxa de aprendizado inicial e o número de camadas cruzadas. O número de camadas ocultas variou de 2 a 5, com tamanhos de camadas ocultas variando de 32 a 1024. Para DCN, o número de camadas cruzadas foi de 1 a 6. A taxa de aprendizagem inicial foi ajustada de 0,0001 para 0,001 com incrementos de 0,0001. Todos os experimentos aplicaram parada antecipada na etapa de treinamento 150.000, além da qual o overfitting começou a ocorrer.
Arquiteturas usadas para validação
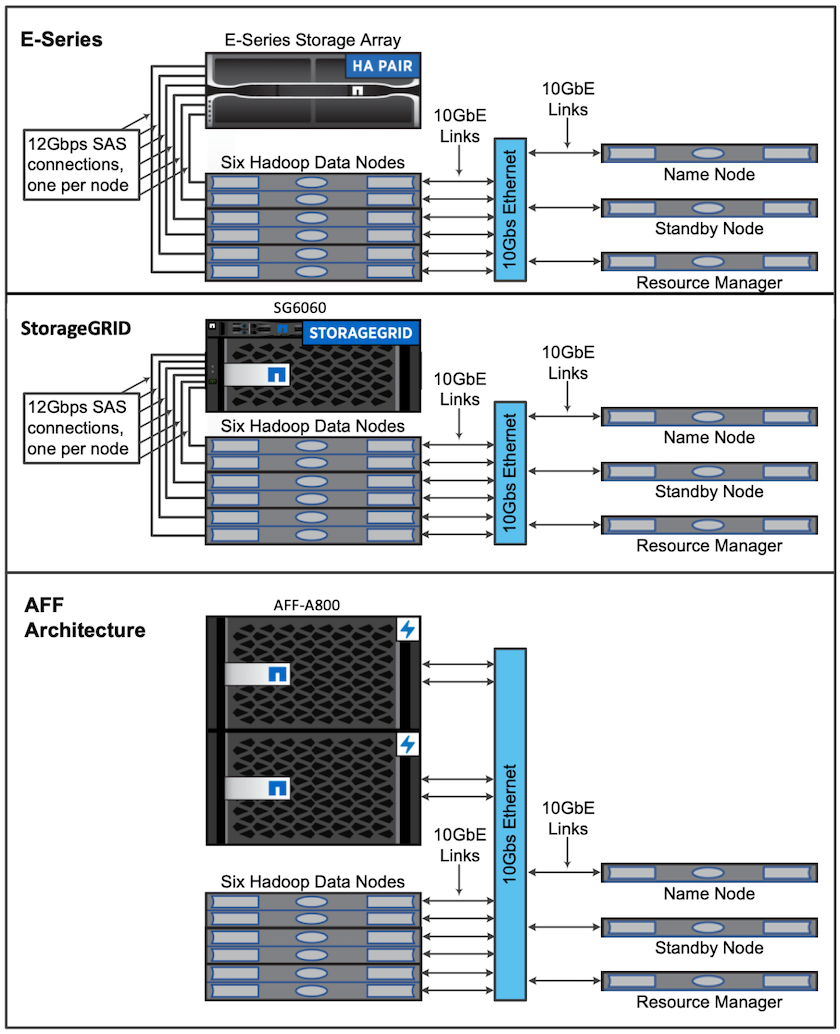
Para esta validação, usamos quatro nós de trabalho e um nó mestre com um par AFF-A800 HA. Todos os membros do cluster estavam conectados por meio de switches de rede de 10 GbE.
Para esta validação da solução NetApp Spark, usamos três controladores de armazenamento diferentes: o E5760, o E5724 e o AFF-A800. Os controladores de armazenamento da série E foram conectados a cinco nós de dados com conexões SAS de 12 Gbps. O controlador de armazenamento AFF HA-pair fornece volumes NFS exportados por meio de conexões de 10 GbE para nós de trabalho do Hadoop. Os membros do cluster Hadoop foram conectados por meio de conexões de 10 GbE nas soluções Hadoop E-Series, AFF e StorageGRID .