

TR-4886: Inferência de IA na Borda - NetApp com Lenovo ThinkSystem - Design de Solução
 Sugerir alterações
Sugerir alterações
Sathish Thyagarajan, NetApp Miroslav Hodak, Lenovo
Este documento descreve uma arquitetura de computação e armazenamento para implantar inferência de inteligência artificial (IA) baseada em GPU em controladores de armazenamento NetApp e servidores Lenovo ThinkSystem em um ambiente de ponta que atende a cenários de aplicativos emergentes.
Resumo
Vários cenários de aplicação emergentes, como sistemas avançados de assistência ao motorista (ADAS), Indústria 4.0, cidades inteligentes e Internet das Coisas (IoT), exigem o processamento de fluxos de dados contínuos sob uma latência próxima de zero. Este documento descreve uma arquitetura de computação e armazenamento para implantar inferência de inteligência artificial (IA) baseada em GPU em controladores de armazenamento NetApp e servidores Lenovo ThinkSystem em um ambiente de ponta que atende a esses requisitos. Este documento também fornece dados de desempenho para o benchmark MLPerf Inference padrão do setor, avaliando várias tarefas de inferência em servidores de ponta equipados com GPUs NVIDIA T4. Investigamos o desempenho de cenários de inferência offline, de fluxo único e multifluxo e mostramos que a arquitetura com um sistema de armazenamento em rede compartilhado e econômico tem alto desempenho e fornece um ponto central para gerenciamento de dados e modelos para vários servidores de ponta.
Introdução
As empresas estão gerando cada vez mais grandes volumes de dados na borda da rede. Para obter o máximo valor de sensores inteligentes e dados de IoT, as organizações estão buscando uma solução de streaming de eventos em tempo real que permita computação de ponta. Portanto, trabalhos computacionalmente exigentes são cada vez mais realizados na borda, fora dos data centers. A inferência de IA é um dos impulsionadores dessa tendência. Os servidores de borda fornecem poder computacional suficiente para essas cargas de trabalho, especialmente ao usar aceleradores, mas o armazenamento limitado geralmente é um problema, especialmente em ambientes multisservidor. Neste documento, mostramos como você pode implantar um sistema de armazenamento compartilhado no ambiente de ponta e como ele beneficia cargas de trabalho de inferência de IA sem impor uma penalidade de desempenho.
Este documento descreve uma arquitetura de referência para inferência de IA na borda. Ele combina vários servidores de ponta Lenovo ThinkSystem com um sistema de armazenamento NetApp para criar uma solução fácil de implantar e gerenciar. O objetivo é servir de guia básico para implementações práticas em diversas situações, como no chão de fábrica com diversas câmeras e sensores industriais, sistemas de ponto de venda (POS) em transações de varejo ou sistemas de direção totalmente autônoma (FSD) que identificam anomalias visuais em veículos autônomos.
Este documento abrange testes e validação de uma configuração de computação e armazenamento composta pelo Lenovo ThinkSystem SE350 Edge Server e um sistema de armazenamento NetApp AFF e EF-Series de nível básico. As arquiteturas de referência fornecem uma solução eficiente e econômica para implantações de IA, ao mesmo tempo em que fornecem serviços de dados abrangentes, proteção de dados integrada, escalabilidade perfeita e armazenamento de dados conectado à nuvem com o software de gerenciamento de dados NetApp ONTAP e NetApp SANtricity .
Público-alvo
Este documento é destinado aos seguintes públicos:
-
Líderes empresariais e arquitetos corporativos que desejam produzir IA na ponta.
-
Cientistas de dados, engenheiros de dados, pesquisadores de IA/aprendizado de máquina (ML) e desenvolvedores de sistemas de IA.
-
Arquitetos corporativos que projetam soluções para o desenvolvimento de modelos e aplicativos de IA/ML.
-
Cientistas de dados e engenheiros de IA buscam maneiras eficientes de implantar modelos de aprendizado profundo (DL) e ML.
-
Gerentes de dispositivos de borda e administradores de servidores de borda responsáveis pela implantação e gerenciamento de modelos de inferência de borda.
Arquitetura da solução
Este servidor Lenovo ThinkSystem e a solução de armazenamento NetApp ONTAP ou NetApp SANtricity foram projetados para lidar com inferência de IA em grandes conjuntos de dados usando o poder de processamento de GPUs junto com CPUs tradicionais. Esta validação demonstra alto desempenho e gerenciamento de dados ideal com uma arquitetura que usa um ou vários servidores de borda Lenovo SR350 interconectados com um único sistema de armazenamento NetApp AFF , conforme mostrado nas duas figuras a seguir.
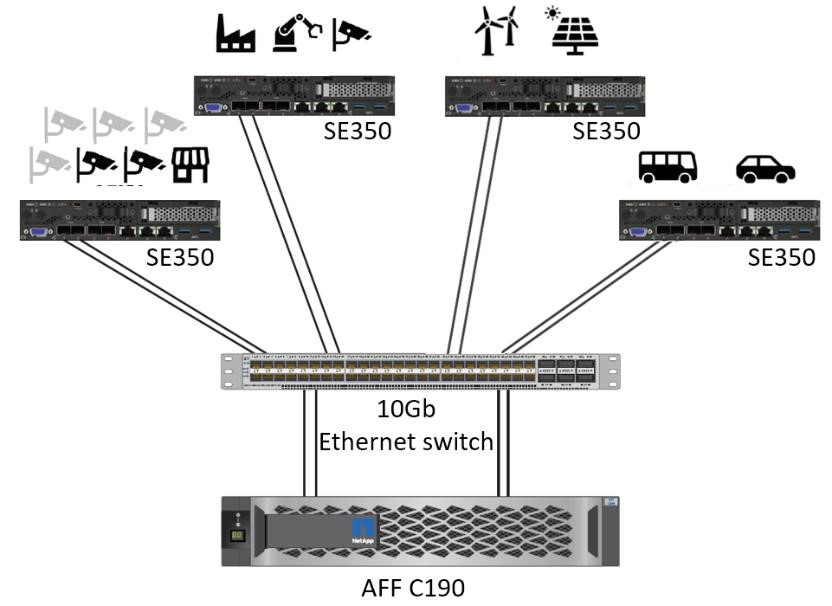
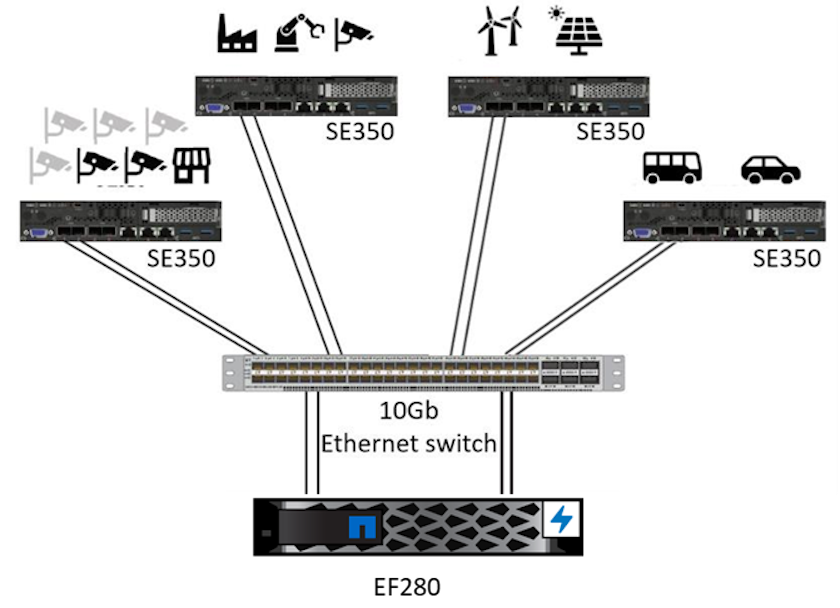
A visão geral da arquitetura lógica na figura a seguir mostra as funções dos elementos de computação e armazenamento nesta arquitetura. Especificamente, ele mostra o seguinte:
-
Dispositivos de computação de ponta que realizam inferências nos dados recebidos de câmeras, sensores e assim por diante.
-
Um elemento de armazenamento compartilhado que atende a vários propósitos:
-
Fornece um local central para modelos de inferência e outros dados necessários para realizar a inferência. Os servidores de computação acessam o armazenamento diretamente e usam modelos de inferência na rede sem a necessidade de copiá-los localmente.
-
Modelos atualizados são enviados aqui.
-
Arquiva dados de entrada que os servidores de borda recebem para análise posterior. Por exemplo, se os dispositivos de borda estiverem conectados a câmeras, o elemento de armazenamento mantém os vídeos capturados pelas câmeras.
-

vermelho |
azul |
Sistema de computação Lenovo |
Sistema de armazenamento NetApp AFF |
Dispositivos de borda que realizam inferências em entradas de câmeras, sensores e assim por diante. |
Armazenamento compartilhado contendo modelos de inferência e dados de dispositivos de ponta para análise posterior. |
Esta solução da NetApp e da Lenovo oferece os seguintes benefícios principais:
-
Computação acelerada por GPU na borda.
-
Implantação de vários servidores de borda apoiados e gerenciados a partir de um armazenamento compartilhado.
-
Proteção de dados robusta para atender a objetivos de baixo ponto de recuperação (RPOs) e objetivos de tempo de recuperação (RTOs) sem perda de dados.
-
Gerenciamento de dados otimizado com cópias e clones do NetApp Snapshot para simplificar os fluxos de trabalho de desenvolvimento.
Como usar esta arquitetura
Este documento valida o design e o desempenho da arquitetura proposta. No entanto, não testamos certos componentes de nível de software, como gerenciamento de contêiner, carga de trabalho ou modelo e sincronização de dados com nuvem ou data center local, porque eles são específicos para um cenário de implantação. Aqui, existem várias escolhas.
No nível de gerenciamento de contêineres, o gerenciamento de contêineres do Kubernetes é uma boa escolha e tem bom suporte em uma versão totalmente upstream (Canonical) ou em uma versão modificada adequada para implantações corporativas (Red Hat). O"Plano de controle de IA da NetApp" que usa o NetApp Trident e o recém-adicionado "Kit de ferramentas NetApp DataOps" fornece rastreabilidade integrada, funções de gerenciamento de dados, interfaces e ferramentas para cientistas e engenheiros de dados integrarem com o armazenamento NetApp . O Kubeflow, o kit de ferramentas de ML para Kubernetes, fornece recursos adicionais de IA, além de suporte para controle de versão de modelo e KFServing em diversas plataformas, como TensorFlow Serving ou NVIDIA Triton Inference Server. Outra opção é a plataforma NVIDIA EGX, que fornece gerenciamento de carga de trabalho juntamente com acesso a um catálogo de contêineres de inferência de IA habilitados para GPU. No entanto, essas opções podem exigir esforço e experiência significativos para colocá-las em produção e podem exigir a assistência de um fornecedor de software independente (ISV) ou consultor.
Áreas de solução
O principal benefício da inferência de IA e da computação de ponta é a capacidade dos dispositivos de calcular, processar e analisar dados com um alto nível de qualidade sem latência. Há muitos exemplos de casos de uso de computação de ponta para descrever neste documento, mas aqui estão alguns dos principais:
Automóveis: Veículos autônomos
A ilustração clássica da computação de ponta está nos sistemas avançados de assistência ao motorista (ADAS) em veículos autônomos (VA). A IA em carros autônomos deve processar rapidamente uma grande quantidade de dados de câmeras e sensores para ser um motorista seguro e bem-sucedido. Demorar muito para interpretar a comunicação entre um objeto e um humano pode significar vida ou morte. Portanto, conseguir processar esses dados o mais próximo possível do veículo é crucial. Nesse caso, um ou mais servidores de computação de ponta manipulam a entrada de câmeras, RADAR, LiDAR e outros sensores, enquanto o armazenamento compartilhado mantém modelos de inferência e armazena dados de entrada de sensores.
Assistência médica: Monitoramento de pacientes
Um dos maiores impactos da IA e da computação de ponta é sua capacidade de melhorar o monitoramento contínuo de pacientes com doenças crônicas, tanto em cuidados domiciliares quanto em unidades de terapia intensiva (UTIs). Dados de dispositivos de ponta que monitoram níveis de insulina, respiração, atividade neurológica, ritmo cardíaco e funções gastrointestinais exigem análise instantânea de dados que devem ser acionados imediatamente porque há tempo limitado para agir e salvar a vida de alguém.
Varejo: Pagamento sem caixa
A computação de ponta pode impulsionar IA e ML para ajudar os varejistas a reduzir o tempo de checkout e aumentar o tráfego de pedestres. Os sistemas sem caixa oferecem suporte a vários componentes, como os seguintes:
-
Autenticação e acesso. Conectar o comprador físico a uma conta validada e permitir acesso ao espaço de varejo.
-
Monitoramento de estoque. Usando sensores, etiquetas RFID e sistemas de visão computacional para ajudar a confirmar a seleção ou desmarcação de itens pelos compradores.
Aqui, cada um dos servidores de borda gerencia cada caixa de pagamento e o sistema de armazenamento compartilhado serve como um ponto central de sincronização.
Serviços financeiros: Segurança humana em quiosques e prevenção de fraudes
As organizações bancárias estão usando IA e computação de ponta para inovar e criar experiências bancárias personalizadas. Quiosques interativos que usam análise de dados em tempo real e inferência de IA agora permitem que caixas eletrônicos não apenas ajudem os clientes a sacar dinheiro, mas monitorem proativamente os quiosques por meio de imagens capturadas por câmeras para identificar riscos à segurança humana ou comportamento fraudulento. Nesse cenário, servidores de computação de ponta e sistemas de armazenamento compartilhado são conectados a quiosques e câmeras interativos para ajudar os bancos a coletar e processar dados com modelos de inferência de IA.
Manufatura: Indústria 4.0
A quarta revolução industrial (Indústria 4.0) começou, junto com tendências emergentes como Fábrica Inteligente e impressão 3D. Para se preparar para um futuro orientado por dados, a comunicação máquina a máquina (M2M) em larga escala e a IoT são integradas para maior automação sem a necessidade de intervenção humana. A manufatura já é altamente automatizada e adicionar recursos de IA é uma continuação natural da tendência de longo prazo. A IA permite automatizar operações que podem ser automatizadas com a ajuda da visão computacional e outros recursos de IA. Você pode automatizar o controle de qualidade ou tarefas que dependem da visão humana ou da tomada de decisões para executar análises mais rápidas de materiais em linhas de montagem em fábricas para ajudar as fábricas a atender aos padrões ISO exigidos de segurança e gestão de qualidade. Aqui, cada servidor de borda de computação é conectado a uma série de sensores que monitoram o processo de fabricação e modelos de inferência atualizados são enviados ao armazenamento compartilhado, conforme necessário.
Telecomunicações: Detecção de ferrugem, inspeção de torres e otimização de rede
O setor de telecomunicações usa técnicas de visão computacional e IA para processar imagens que detectam automaticamente ferrugem e identificam torres de celular que contêm corrosão e, portanto, exigem inspeção mais aprofundada. O uso de imagens de drones e modelos de IA para identificar regiões distintas de uma torre para analisar ferrugem, rachaduras superficiais e corrosão aumentou nos últimos anos. A demanda continua crescendo por tecnologias de IA que permitam que a infraestrutura de telecomunicações e torres de celular sejam inspecionadas com eficiência, avaliadas regularmente quanto à degradação e reparadas prontamente quando necessário.
Além disso, outro caso de uso emergente em telecomunicações é o uso de algoritmos de IA e ML para prever padrões de tráfego de dados, detectar dispositivos compatíveis com 5G e automatizar e aumentar o gerenciamento de energia de múltiplas entradas e saídas (MIMO). O hardware MIMO é usado em torres de rádio para aumentar a capacidade da rede; no entanto, isso acarreta custos adicionais de energia. Modelos de ML para "modo de espera MIMO" implantados em estações de rádio podem prever o uso eficiente de rádios e ajudar a reduzir os custos de consumo de energia para operadoras de redes móveis (MNOs). As soluções de inferência de IA e computação de ponta ajudam as MNOs a reduzir a quantidade de dados transmitidos de um lado para o outro entre os data centers, diminuir seu TCO, otimizar as operações de rede e melhorar o desempenho geral para os usuários finais.