

Procedimento de teste
 Sugerir alterações
Sugerir alterações
Esta seção descreve as tarefas necessárias para concluir a validação.
Pré-requisitos
Para executar as tarefas descritas nesta seção, você deve ter acesso a um host Linux ou macOS com as seguintes ferramentas instaladas e configuradas:
Cenário 1 – Inferência sob demanda no JupyterLab
-
Crie um namespace do Kubernetes para cargas de trabalho de inferência de IA/ML.
$ kubectl create namespace inference namespace/inference created
-
Use o NetApp DataOps Toolkit para provisionar um volume persistente para armazenar os dados nos quais você executará a inferência.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Use o NetApp DataOps Toolkit para criar um novo espaço de trabalho do JupyterLab. Monte o volume persistente que foi criado na etapa anterior usando o
--mount- pvcopção. Aloque GPUs NVIDIA para o espaço de trabalho conforme necessário usando o-- nvidia-gpuopção.No exemplo a seguir, o volume persistente
inference-dataé montado no contêiner do espaço de trabalho JupyterLab em/home/jovyan/data. Ao usar imagens oficiais do contêiner do Projeto Jupyter,/home/jovyané apresentado como o diretório de nível superior dentro da interface web do JupyterLab.$ netapp_dataops_k8s_cli.py create jupyterlab --namespace=inference --workspace-name=live-inference --size=50Gi --nvidia-gpu=2 --mount-pvc=inference-data:/home/jovyan/data Set workspace password (this password will be required in order to access the workspace): Re-enter password: Creating persistent volume for workspace... Creating PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Creating Service 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Service successfully created. Attaching Additional PVC: 'inference-data' at mount_path: '/home/jovyan/data'. Creating Deployment 'ntap-dsutil-jupyterlab-live-inference' in namespace 'inference'. Deployment 'ntap-dsutil-jupyterlab-live-inference' created. Waiting for Deployment 'ntap-dsutil-jupyterlab-live-inference' to reach Ready state. Deployment successfully created. Workspace successfully created. To access workspace, navigate to http://192.168.0.152:32721
-
Acesse o espaço de trabalho do JupyterLab usando o URL especificado na saída do
create jupyterlabcomando. O diretório de dados representa o volume persistente que foi montado no espaço de trabalho.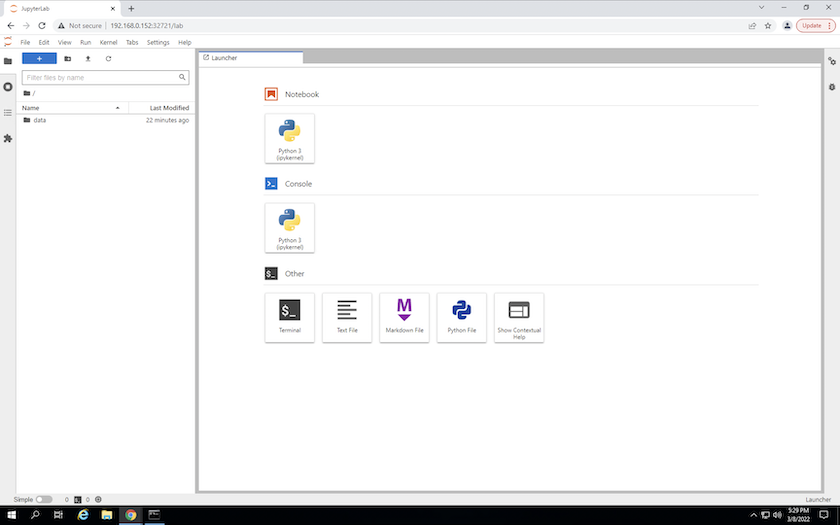
-
Abra o
datadiretório e carregue os arquivos nos quais a inferência será realizada. Quando os arquivos são carregados no diretório de dados, eles são armazenados automaticamente no volume persistente que foi montado no espaço de trabalho. Para carregar arquivos, clique no ícone Carregar arquivos, conforme mostrado na imagem a seguir.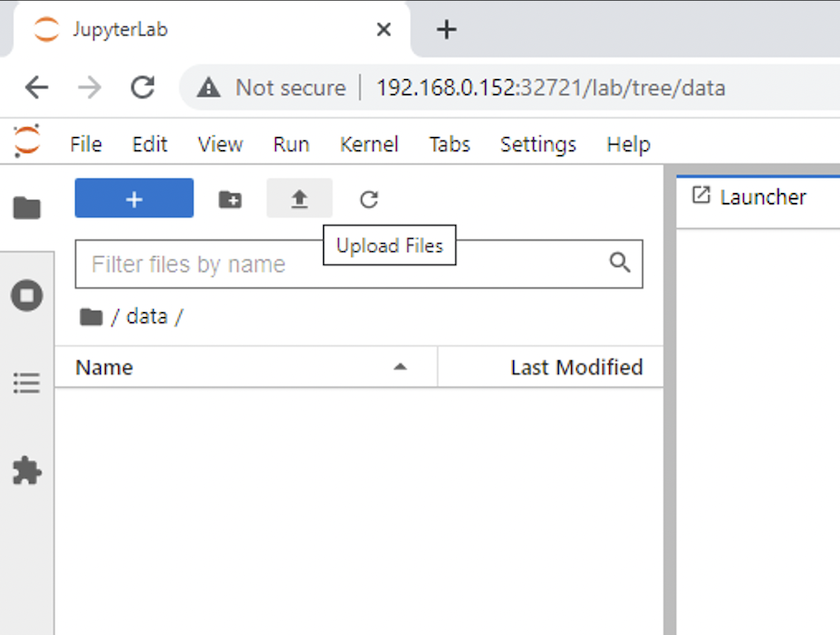
-
Retorne ao diretório de nível superior e crie um novo notebook.
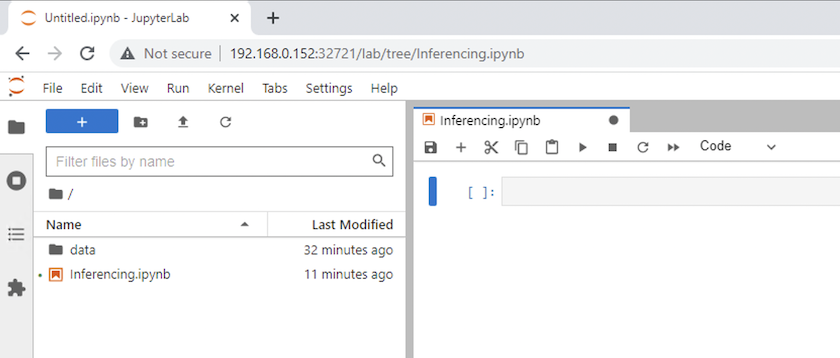
-
Adicione código de inferência ao notebook. O exemplo a seguir mostra o código de inferência para um caso de uso de detecção de imagem.
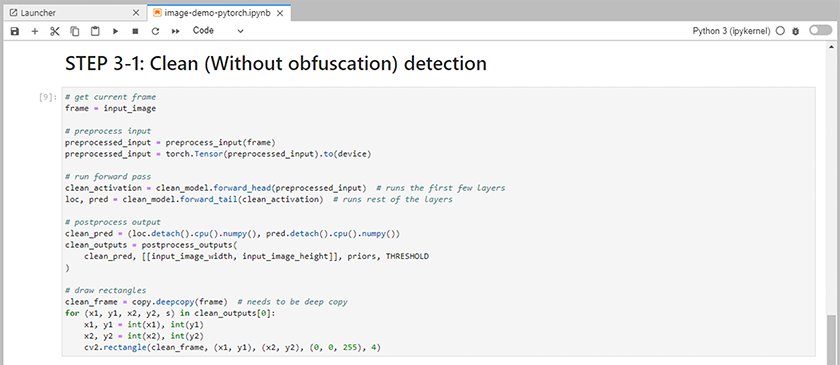
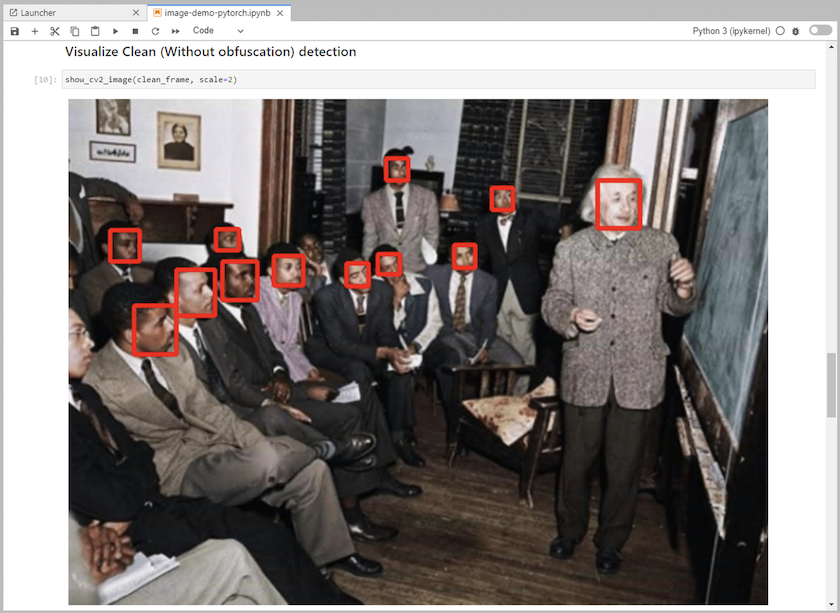
-
Adicione a ofuscação Protopia ao seu código de inferência. A Protopia trabalha diretamente com os clientes para fornecer documentação específica para casos de uso e está fora do escopo deste relatório técnico. O exemplo a seguir mostra o código de inferência para um caso de uso de detecção de imagem com ofuscação Protopia adicionada.
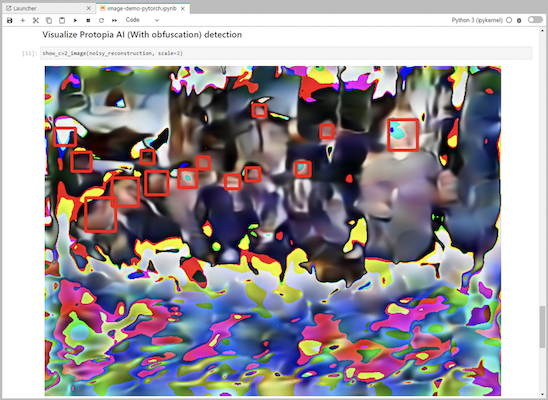
Cenário 2 – Inferência em lote no Kubernetes
-
Crie um namespace do Kubernetes para cargas de trabalho de inferência de IA/ML.
$ kubectl create namespace inference namespace/inference created
-
Use o NetApp DataOps Toolkit para provisionar um volume persistente para armazenar os dados nos quais você executará a inferência.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=inference-data --size=50Gi Creating PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'. PersistentVolumeClaim (PVC) 'inference-data' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'inference-data' in namespace 'inference'.
-
Preencha o novo volume persistente com os dados nos quais você executará a inferência.
Existem vários métodos para carregar dados em um PVC. Se seus dados estiverem armazenados atualmente em uma plataforma de armazenamento de objetos compatível com S3, como NetApp StorageGRID ou Amazon S3, você poderá usar "Recursos do NetApp DataOps Toolkit S3 Data Mover" . Outro método simples é criar um espaço de trabalho do JupyterLab e, em seguida, carregar os arquivos por meio da interface da web do JupyterLab, conforme descrito nas Etapas 3 a 5 na seção "Cenário 1 – Inferência sob demanda no JupyterLab ."
-
Crie um trabalho do Kubernetes para sua tarefa de inferência em lote. O exemplo a seguir mostra um trabalho de inferência em lote para um caso de uso de detecção de imagem. Este trabalho realiza inferências em cada imagem em um conjunto de imagens e grava métricas de precisão de inferência no stdout.
$ vi inference-job-raw.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-raw namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-raw.yaml job.batch/netapp-inference-raw created -
Confirme se o trabalho de inferência foi concluído com sucesso.
$ kubectl -n inference logs netapp-inference-raw-255sp 100%|██████████| 89/89 [00:52<00:00, 1.68it/s] Reading Predictions : 100%|██████████| 10/10 [00:01<00:00, 6.23it/s] Predicting ... : 100%|██████████| 10/10 [00:16<00:00, 1.64s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.9491256561145955 FDDB-fold-2 Val AP: 0.9205024466101926 FDDB-fold-3 Val AP: 0.9253013871078468 FDDB-fold-4 Val AP: 0.9399781485863011 FDDB-fold-5 Val AP: 0.9504280149478732 FDDB-fold-6 Val AP: 0.9416473519339292 FDDB-fold-7 Val AP: 0.9241631566241117 FDDB-fold-8 Val AP: 0.9072663297546659 FDDB-fold-9 Val AP: 0.9339648715035469 FDDB-fold-10 Val AP: 0.9447707905560152 FDDB Dataset Average AP: 0.9337148153739079 ================================================= mAP: 0.9337148153739079
-
Adicione a ofuscação do Protopia ao seu trabalho de inferência. Você pode encontrar instruções específicas de casos de uso para adicionar ofuscação do Protopia diretamente do Protopia, o que está fora do escopo deste relatório técnico. O exemplo a seguir mostra um trabalho de inferência em lote para um caso de uso de detecção de rosto com ofuscação Protopia adicionada usando um valor ALPHA de 0,8. Este trabalho aplica a ofuscação do Protopia antes de realizar a inferência para cada imagem em um conjunto de imagens e, em seguida, grava as métricas de precisão da inferência no stdout.
Repetimos esta etapa para os valores ALFA 0,05, 0,1, 0,2, 0,4, 0,6, 0,8, 0,9 e 0,95. Você pode ver os resultados em"Comparação de precisão de inferência."
$ vi inference-job-protopia-0.8.yaml apiVersion: batch/v1 kind: Job metadata: name: netapp-inference-protopia-0.8 namespace: inference spec: backoffLimit: 5 template: spec: volumes: - name: data persistentVolumeClaim: claimName: inference-data - name: dshm emptyDir: medium: Memory containers: - name: inference image: netapp-protopia-inference:latest imagePullPolicy: IfNotPresent env: - name: ALPHA value: "0.8" command: ["python3", "run-accuracy-measurement.py", "--dataset", "/data/netapp-face-detection/FDDB", "--alpha", "$(ALPHA)", "--noisy"] resources: limits: nvidia.com/gpu: 2 volumeMounts: - mountPath: /data name: data - mountPath: /dev/shm name: dshm restartPolicy: Never $ kubectl create -f inference-job-protopia-0.8.yaml job.batch/netapp-inference-protopia-0.8 created -
Confirme se o trabalho de inferência foi concluído com sucesso.
$ kubectl -n inference logs netapp-inference-protopia-0.8-b4dkz 100%|██████████| 89/89 [01:05<00:00, 1.37it/s] Reading Predictions : 100%|██████████| 10/10 [00:02<00:00, 3.67it/s] Predicting ... : 100%|██████████| 10/10 [00:22<00:00, 2.24s/it] ==================== Results ==================== FDDB-fold-1 Val AP: 0.8953066115834589 FDDB-fold-2 Val AP: 0.8819580264029936 FDDB-fold-3 Val AP: 0.8781107458462862 FDDB-fold-4 Val AP: 0.9085731346308461 FDDB-fold-5 Val AP: 0.9166445508275378 FDDB-fold-6 Val AP: 0.9101178994188819 FDDB-fold-7 Val AP: 0.8383443678423771 FDDB-fold-8 Val AP: 0.8476311547659464 FDDB-fold-9 Val AP: 0.8739624502111121 FDDB-fold-10 Val AP: 0.8905468076424851 FDDB Dataset Average AP: 0.8841195749171925 ================================================= mAP: 0.8841195749171925
Cenário 3 – Servidor de Inferência NVIDIA Triton
-
Crie um namespace do Kubernetes para cargas de trabalho de inferência de IA/ML.
$ kubectl create namespace inference namespace/inference created
-
Use o NetApp DataOps Toolkit para provisionar um volume persistente a ser usado como um repositório de modelo para o NVIDIA Triton Inference Server.
$ netapp_dataops_k8s_cli.py create volume --namespace=inference --pvc-name=triton-model-repo --size=100Gi Creating PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'. PersistentVolumeClaim (PVC) 'triton-model-repo' created. Waiting for Kubernetes to bind volume to PVC. Volume successfully created and bound to PersistentVolumeClaim (PVC) 'triton-model-repo' in namespace 'inference'.
-
Armazene seu modelo no novo volume persistente em um "formatar" que é reconhecido pelo NVIDIA Triton Inference Server.
Existem vários métodos para carregar dados em um PVC. Um método simples é criar um espaço de trabalho do JupyterLab e, em seguida, carregar os arquivos por meio da interface da web do JupyterLab, conforme descrito nas etapas 3 a 5 em "Cenário 1 – Inferência sob demanda no JupyterLab . "
-
Use o NetApp DataOps Toolkit para implantar uma nova instância do NVIDIA Triton Inference Server.
$ netapp_dataops_k8s_cli.py create triton-server --namespace=inference --server-name=netapp-inference --model-repo-pvc-name=triton-model-repo Creating Service 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Service successfully created. Creating Deployment 'ntap-dsutil-triton-netapp-inference' in namespace 'inference'. Deployment 'ntap-dsutil-triton-netapp-inference' created. Waiting for Deployment 'ntap-dsutil-triton-netapp-inference' to reach Ready state. Deployment successfully created. Server successfully created. Server endpoints: http: 192.168.0.152: 31208 grpc: 192.168.0.152: 32736 metrics: 192.168.0.152: 30009/metrics
-
Use um SDK cliente Triton para executar uma tarefa de inferência. O trecho de código Python a seguir usa o SDK do cliente Triton Python para executar uma tarefa de inferência para um caso de uso de detecção de rosto. Este exemplo chama a API Triton e passa uma imagem para inferência. O Triton Inference Server então recebe a solicitação, invoca o modelo e retorna a saída de inferência como parte dos resultados da API.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass clean_activation = clean_model_head(preprocessed_input) # runs the first few layers ###################################################################################### # pass clean image to Triton Inference Server API for inferencing # ###################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_base" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(clean_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ###################################################################################### # postprocess output clean_pred = (loc_numpy, pred_numpy) clean_outputs = postprocess_outputs( clean_pred, [[input_image_width, input_image_height]], priors, THRESHOLD ) # draw rectangles clean_frame = copy.deepcopy(frame) # needs to be deep copy for (x1, y1, x2, y2, s) in clean_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(clean_frame, (x1, y1), (x2, y2), (0, 0, 255), 4) -
Adicione a ofuscação Protopia ao seu código de inferência. Você pode encontrar instruções específicas de casos de uso para adicionar ofuscação do Protopia diretamente do Protopia; no entanto, esse processo está fora do escopo deste relatório técnico. O exemplo a seguir mostra o mesmo código Python mostrado na etapa 5 anterior, mas com a ofuscação Protopia adicionada.
Observe que a ofuscação do Protopia é aplicada à imagem antes de ela ser passada para a API do Triton. Dessa forma, a imagem não ofuscada nunca sai da máquina local. Somente a imagem ofuscada é passada pela rede. Este fluxo de trabalho é aplicável a casos de uso em que os dados são coletados dentro de uma zona confiável, mas precisam ser passados para fora dessa zona confiável para inferência. Sem a ofuscação do Protopia, não é possível implementar esse tipo de fluxo de trabalho sem que dados confidenciais saiam da zona confiável.
# get current frame frame = input_image # preprocess input preprocessed_input = preprocess_input(frame) preprocessed_input = torch.Tensor(preprocessed_input).to(device) # run forward pass not_noisy_activation = noisy_model_head(preprocessed_input) # runs the first few layers ################################################################## # obfuscate image locally prior to inferencing # # SINGLE ADITIONAL LINE FOR PRIVATE INFERENCE # ################################################################## noisy_activation = noisy_model_noise(not_noisy_activation) ################################################################## ########################################################################################### # pass obfuscated image to Triton Inference Server API for inferencing # ########################################################################################### triton_client = httpclient.InferenceServerClient(url="192.168.0.152:31208", verbose=False) model_name = "face_detection_noisy" inputs = [] outputs = [] inputs.append(httpclient.InferInput("INPUT__0", [1, 128, 32, 32], "FP32")) inputs[0].set_data_from_numpy(noisy_activation.detach().cpu().numpy(), binary_data=False) outputs.append(httpclient.InferRequestedOutput("OUTPUT__0", binary_data=False)) outputs.append(httpclient.InferRequestedOutput("OUTPUT__1", binary_data=False)) results = triton_client.infer( model_name, inputs, outputs=outputs, #query_params=query_params, headers=None, request_compression_algorithm=None, response_compression_algorithm=None) #print(results.get_response()) statistics = triton_client.get_inference_statistics(model_name=model_name, headers=None) print(statistics) if len(statistics["model_stats"]) != 1: print("FAILED: Inference Statistics") sys.exit(1) loc_numpy = results.as_numpy("OUTPUT__0") pred_numpy = results.as_numpy("OUTPUT__1") ########################################################################################### # postprocess output noisy_pred = (loc_numpy, pred_numpy) noisy_outputs = postprocess_outputs( noisy_pred, [[input_image_width, input_image_height]], priors, THRESHOLD * 0.5 ) # get reconstruction of the noisy activation noisy_reconstruction = decoder_function(noisy_activation) noisy_reconstruction = noisy_reconstruction.detach().cpu().numpy()[0] noisy_reconstruction = unpreprocess_output( noisy_reconstruction, (input_image_width, input_image_height), True ).astype(np.uint8) # draw rectangles for (x1, y1, x2, y2, s) in noisy_outputs[0]: x1, y1 = int(x1), int(y1) x2, y2 = int(x2), int(y2) cv2.rectangle(noisy_reconstruction, (x1, y1), (x2, y2), (0, 0, 255), 4)