

Configure o software FC do MetroCluster no ONTAP
 Sugerir alterações
Sugerir alterações
Você deve configurar cada nó na configuração FC do MetroCluster no ONTAP, incluindo as configurações em nível de nó e a configuração dos nós em dois sites. Você também deve implementar o relacionamento MetroCluster entre os dois sites.
Recolha de informações necessárias
Você precisa reunir os endereços IP necessários para os módulos do controlador antes de iniciar o processo de configuração.
Folha de cálculo de informações de rede IP para o local A
Você deve obter endereços IP e outras informações de rede para o primeiro site do MetroCluster (site A) do administrador da rede antes de configurar o sistema.
Informações do switch local A (clusters comutados)
Quando você faz o cabo do sistema, você precisa de um nome de host e endereço IP de gerenciamento para cada switch de cluster. Essas informações não são necessárias se você estiver usando um cluster sem switch de dois nós ou tiver uma configuração de MetroCluster de dois nós (um nó em cada local).
Interrutor do cluster |
Nome do host |
Endereço IP |
Máscara de rede |
Gateway predefinido |
Interconexão 1 |
||||
Interconexão 2 |
||||
Gestão 1 |
||||
Gestão 2 |
Site Um cluster de criação de informações
Quando você cria o cluster pela primeira vez, você precisa das seguintes informações:
Tipo de informação |
Seus valores |
Nome do cluster Exemplo usado neste procedimento: Site_A |
|
Domínio DNS |
|
Servidores de nomes DNS |
|
Localização |
|
Senha do administrador |
Informações do nó do site A.
Para cada nó no cluster, é necessário um endereço IP de gerenciamento, uma máscara de rede e um gateway padrão.
Nó |
Porta |
Endereço IP |
Máscara de rede |
Gateway predefinido |
Nó 1 Exemplo usado neste procedimento: Controller_A_1 |
||||
Nó 2 Não é necessário se estiver usando a configuração MetroCluster de dois nós (um nó em cada local). Exemplo usado neste procedimento: Controller_A_2 |
Crie um site LIFs e portas para peering de cluster
Para cada nó no cluster, você precisa dos endereços IP de duas LIFs entre clusters, incluindo uma máscara de rede e um gateway padrão. Os LIFs entre clusters são usados para fazer o peer dos clusters.
Nó |
Porta |
Endereço IP do LIF entre clusters |
Máscara de rede |
Gateway predefinido |
Nó 1 IC LIF 1 |
||||
Nó 1 IC LIF 2 |
||||
Nó 2 IC LIF 1 Não é necessário para configurações de MetroCluster de dois nós (um nó em cada local). |
||||
Nó 2 IC LIF 2 Não é necessário para configurações de MetroCluster de dois nós (um nó em cada local). |
Site A informações do servidor de tempo
É necessário sincronizar a hora, que requer um ou mais servidores de hora NTP.
Nó |
Nome do host |
Endereço IP |
Máscara de rede |
Gateway predefinido |
Servidor NTP 1 |
||||
Servidor NTP 2 |
Local A Informação AutoSupport
Você deve configurar o AutoSupport em cada nó, o que requer as seguintes informações:
Tipo de informação |
Seus valores |
|
Do endereço de e-mail |
Anfitriões de correio |
|
Endereços IP ou nomes |
Protocolo de transporte |
|
HTTP, HTTPS OU SMTP |
Servidor proxy |
|
Endereços de e-mail do destinatário ou listas de distribuição |
Mensagens completas |
|
Mensagens concisas |
||
Local A Informação SP
Você deve habilitar o acesso ao processador de serviço (SP) de cada nó para solução de problemas e manutenção, o que requer as seguintes informações de rede para cada nó:
Nó |
Endereço IP |
Máscara de rede |
Gateway predefinido |
Nó 1 |
|||
Nó 2 Não é necessário para configurações de MetroCluster de dois nós (um nó em cada local). |
Folha de cálculo de informações de rede IP para o local B.
Você deve obter endereços IP e outras informações de rede para o segundo site da MetroCluster (site B) do administrador da rede antes de configurar o sistema.
Informações do switch local B (clusters comutados)
Quando você faz o cabo do sistema, você precisa de um nome de host e endereço IP de gerenciamento para cada switch de cluster. Essas informações não são necessárias se você estiver usando um cluster sem switch de dois nós ou se você tiver uma configuração de MetroCluster de dois nós (um nó em cada local).
Interrutor do cluster |
Nome do host |
Endereço IP |
Máscara de rede |
Gateway predefinido |
Interconexão 1 |
||||
Interconexão 2 |
||||
Gestão 1 |
||||
Gestão 2 |
Informações sobre a criação do cluster do local B.
Quando você cria o cluster pela primeira vez, você precisa das seguintes informações:
Tipo de informação |
Seus valores |
Nome do cluster Exemplo utilizado neste procedimento: site_B |
|
Domínio DNS |
|
Servidores de nomes DNS |
|
Localização |
|
Senha do administrador |
Informações do nó do local B.
Para cada nó no cluster, é necessário um endereço IP de gerenciamento, uma máscara de rede e um gateway padrão.
Nó |
Porta |
Endereço IP |
Máscara de rede |
Gateway predefinido |
Nó 1 Exemplo usado neste procedimento: controller_B_1 |
||||
Nó 2 Não é necessário para configurações de MetroCluster de dois nós (um nó em cada local). Exemplo usado neste procedimento: controller_B_2 |
LIFs do local B e portas para peering de cluster
Para cada nó no cluster, você precisa dos endereços IP de duas LIFs entre clusters, incluindo uma máscara de rede e um gateway padrão. Os LIFs entre clusters são usados para fazer o peer dos clusters.
Nó |
Porta |
Endereço IP do LIF entre clusters |
Máscara de rede |
Gateway predefinido |
Nó 1 IC LIF 1 |
||||
Nó 1 IC LIF 2 |
||||
Nó 2 IC LIF 1 Não é necessário para configurações de MetroCluster de dois nós (um nó em cada local). |
||||
Nó 2 IC LIF 2 Não é necessário para configurações de MetroCluster de dois nós (um nó em cada local). |
Informações do servidor de hora local B.
É necessário sincronizar a hora, que requer um ou mais servidores de hora NTP.
Nó |
Nome do host |
Endereço IP |
Máscara de rede |
Gateway predefinido |
Servidor NTP 1 |
||||
Servidor NTP 2 |
Local B Informação AutoSupport
Você deve configurar o AutoSupport em cada nó, o que requer as seguintes informações:
Tipo de informação |
Seus valores |
|
Do endereço de e-mail |
||
Anfitriões de correio |
Endereços IP ou nomes |
|
Protocolo de transporte |
HTTP, HTTPS OU SMTP |
|
Servidor proxy |
Endereços de e-mail do destinatário ou listas de distribuição |
|
Mensagens completas |
Mensagens concisas |
|
Parceiros |
||
Local B Informação SP
Você deve habilitar o acesso ao processador de serviço (SP) de cada nó para solução de problemas e manutenção, o que requer as seguintes informações de rede para cada nó:
Nó |
Endereço IP |
Máscara de rede |
Gateway predefinido |
Nó 1 (controlador_B_1) |
|||
Nó 2 (controlador_B_2) Não é necessário para configurações de MetroCluster de dois nós (um nó em cada local). |
Semelhanças e diferenças entre configurações padrão de cluster e MetroCluster
A configuração dos nós em cada cluster em uma configuração MetroCluster é semelhante à dos nós em um cluster padrão.
A configuração do MetroCluster é baseada em dois clusters padrão. Fisicamente, a configuração deve ser simétrica, com cada nó tendo a mesma configuração de hardware e todos os componentes do MetroCluster devem ser cabeados e configurados. No entanto, a configuração básica de software para nós em uma configuração MetroCluster é a mesma para nós em um cluster padrão.
Etapa de configuração |
Configuração padrão de cluster |
Configuração do MetroCluster |
Configurar LIFs de gerenciamento, cluster e dados em cada nó. |
O mesmo em ambos os tipos de clusters |
|
Configure o agregado raiz. |
O mesmo em ambos os tipos de clusters |
|
Configurar nós no cluster como pares de HA |
O mesmo em ambos os tipos de clusters |
|
Configure o cluster em um nó no cluster. |
O mesmo em ambos os tipos de clusters |
|
Junte o outro nó ao cluster. |
O mesmo em ambos os tipos de clusters |
|
Crie um agregado de raiz espelhado. |
Opcional |
Obrigatório |
Espreite os clusters. |
Opcional |
Obrigatório |
Ative a configuração do MetroCluster. |
Não se aplica |
Obrigatório |
Verificar e configurar o estado HA dos componentes no modo Manutenção
Ao configurar um sistema de storage em uma configuração MetroCluster FC, você deve garantir que o estado de alta disponibilidade (HA) dos componentes do chassi e do módulo da controladora seja mcc ou mcc-2n para que esses componentes sejam inicializados corretamente. Embora esse valor deva ser pré-configurado em sistemas recebidos de fábrica, você ainda deve verificar a configuração antes de continuar.

|
Se o estado HA do módulo do controlador e do chassis estiver incorreto, não poderá configurar o MetroCluster sem reiniciar o nó. Deve corrigir a definição utilizando este procedimento e, em seguida, inicializar o sistema utilizando um dos seguintes procedimentos:
|
Verifique se o sistema está no modo Manutenção.
-
No modo de manutenção, apresentar o estado HA do módulo do controlador e do chassis:
ha-config showO estado de HA correto depende da configuração do MetroCluster.
Tipo de configuração MetroCluster
Estado HA para todos os componentes…
Configuração de FC MetroCluster de oito ou quatro nós
mcc
Configuração de FC MetroCluster de dois nós
mcc-2n
Configuração IP MetroCluster de oito ou quatro nós
mccip
-
Se o estado do sistema apresentado do controlador não estiver correto, defina o estado HA correto para a sua configuração no módulo do controlador:
Tipo de configuração MetroCluster
Comando
Configuração de FC MetroCluster de oito ou quatro nós
ha-config modify controller mccConfiguração de FC MetroCluster de dois nós
ha-config modify controller mcc-2nConfiguração IP MetroCluster de oito ou quatro nós
ha-config modify controller mccip -
Se o estado do sistema apresentado do chassis não estiver correto, defina o estado HA correto para a sua configuração no chassis:
Tipo de configuração MetroCluster
Comando
Configuração de FC MetroCluster de oito ou quatro nós
ha-config modify chassis mccConfiguração de FC MetroCluster de dois nós
ha-config modify chassis mcc-2nConfiguração IP MetroCluster de oito ou quatro nós
ha-config modify chassis mccip -
Inicialize o nó no ONTAP:
boot_ontap -
Repita todo esse procedimento para verificar o estado de HA em cada nó na configuração do MetroCluster.
Restaurando os padrões do sistema e configurando o tipo HBA em um módulo do controlador
Para garantir uma instalação bem-sucedida do MetroCluster, redefina e restaure padrões nos módulos do controlador.
Essa tarefa só é necessária para configurações Stretch usando bridges FC-para-SAS.
-
No prompt Loader, retorne as variáveis ambientais à configuração padrão:
set-defaults -
Inicialize o nó no modo Manutenção e, em seguida, configure as configurações para quaisquer HBAs no sistema:
-
Arranque no modo de manutenção:
boot_ontap maint -
Verifique as definições atuais das portas:
ucadmin show -
Atualize as definições da porta conforme necessário.
Se você tem este tipo de HBA e modo desejado…
Use este comando…
CNA FC
ucadmin modify -m fc -t initiator adapter_nameCNA Ethernet
ucadmin modify -mode cna adapter_nameDestino de FC
fcadmin config -t target adapter_nameIniciador FC
fcadmin config -t initiator adapter_name -
-
Sair do modo de manutenção:
haltDepois de executar o comando, aguarde até que o nó pare no prompt DO Loader.
-
Inicialize o nó novamente no modo Manutenção para permitir que as alterações de configuração entrem em vigor:
boot_ontap maint -
Verifique as alterações feitas:
Se você tem este tipo de HBA…
Use este comando…
CNA
ucadmin showFC
fcadmin show -
Sair do modo de manutenção:
haltDepois de executar o comando, aguarde até que o nó pare no prompt DO Loader.
-
Inicialize o nó no menu de inicialização:
boot_ontap menuDepois de executar o comando, aguarde até que o menu de inicialização seja exibido.
-
Limpe a configuração do nó digitando "wipeconfig" no prompt do menu de inicialização e pressione Enter.
A tela a seguir mostra o prompt do menu de inicialização:
Please choose one of the following:
(1) Normal Boot.
(2) Boot without /etc/rc.
(3) Change password.
(4) Clean configuration and initialize all disks.
(5) Maintenance mode boot.
(6) Update flash from backup config.
(7) Install new software first.
(8) Reboot node.
(9) Configure Advanced Drive Partitioning.
Selection (1-9)? wipeconfig
This option deletes critical system configuration, including cluster membership.
Warning: do not run this option on a HA node that has been taken over.
Are you sure you want to continue?: yes
Rebooting to finish wipeconfig request.
Configurando portas FC-VI em uma placa quad-port X1132A-R6 em sistemas FAS8020
Se você estiver usando a placa quad-port X1132A-R6 em um sistema FAS8020, você pode entrar no modo de manutenção para configurar as portas 1a e 1b para uso de FC-VI e iniciador. Isso não é necessário nos sistemas MetroCluster recebidos de fábrica, nos quais as portas são definidas adequadamente para sua configuração.
Esta tarefa deve ser executada no modo Manutenção.

|
A conversão de uma porta FC para uma porta FC-VI com o comando uadministrador só é compatível com os sistemas FAS8020 e AFF 8020. A conversão de portas FC para portas FCVI não é compatível em nenhuma outra plataforma. |
-
Desative as portas:
storage disable adapter 1astorage disable adapter 1b*> storage disable adapter 1a Jun 03 02:17:57 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1a. Host adapter 1a disable succeeded Jun 03 02:17:57 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1a is now offline. *> storage disable adapter 1b Jun 03 02:18:43 [controller_B_1:fci.adapter.offlining:info]: Offlining Fibre Channel adapter 1b. Host adapter 1b disable succeeded Jun 03 02:18:43 [controller_B_1:fci.adapter.offline:info]: Fibre Channel adapter 1b is now offline. *>
-
Verifique se as portas estão desativadas:
ucadmin show*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - - offline 1b fc initiator - - offline 1c fc initiator - - online 1d fc initiator - - online -
Defina as portas a e b para o modo FC-VI:
ucadmin modify -adapter 1a -type fcviO comando define o modo em ambas as portas no par de portas, 1a e 1b (mesmo que apenas 1a seja especificado no comando).
*> ucadmin modify -t fcvi 1a Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1a. Reboot the controller for the changes to take effect. Jun 03 02:19:13 [controller_B_1:ucm.type.changed:info]: FC-4 type has changed to fcvi on adapter 1b. Reboot the controller for the changes to take effect.
-
Confirme se a alteração está pendente:
ucadmin show*> ucadmin show Current Current Pending Pending Admin Adapter Mode Type Mode Type Status ------- ------- --------- ------- --------- ------- ... 1a fc initiator - fcvi offline 1b fc initiator - fcvi offline 1c fc initiator - - online 1d fc initiator - - online -
Desligue o controlador e reinicie-o no modo de manutenção.
-
Confirme a alteração de configuração:
ucadmin show localNode Adapter Mode Type Mode Type Status ------------ ------- ------- --------- ------- --------- ----------- ... controller_B_1 1a fc fcvi - - online controller_B_1 1b fc fcvi - - online controller_B_1 1c fc initiator - - online controller_B_1 1d fc initiator - - online 6 entries were displayed.
Verificando a atribuição de discos no modo Manutenção em uma configuração de oito nós ou quatro nós
Antes de iniciar totalmente o sistema no ONTAP, você pode opcionalmente inicializar no modo Manutenção e verificar a atribuição de disco nos nós. Os discos devem ser atribuídos para criar uma configuração ativo-ativo totalmente simétrica, onde cada pool tem um número igual de discos atribuídos a eles.
Os novos sistemas MetroCluster têm atribuição de disco concluída antes do envio.
A tabela a seguir mostra exemplos de atribuições de pool para uma configuração do MetroCluster. Os discos são atribuídos a pools por compartimento.
Prateleiras de disco no local A
Compartimento de disco (sample_shelf_name)… |
Pertence a… |
E é atribuído a esse nó… |
Compartimento de disco 1 (shelf_A_1_1) |
Nó A 1 |
Piscina 0 |
Compartimento de disco 2 (shelf_A_1_3) |
||
Compartimento de disco 3 (gaveta_B_1_1) |
Nó B 1 |
Piscina 1 |
Compartimento de disco 4 (gaveta_B_1_3) |
||
Compartimento de disco 5 (shelf_A_2_1) |
Nó A 2 |
Piscina 0 |
Compartimento de disco 6 (shelf_A_2_3) |
||
Compartimento de disco 7 (gaveta_B_2_1) |
Nó B 2 |
Piscina 1 |
Compartimento de disco 8 (gaveta_B_2_3) |
||
Compartimento de disco 1 (shelf_A_3_1) |
Nó A 3 |
Piscina 0 |
Compartimento de disco 2 (shelf_A_3_3) |
||
Compartimento de disco 3 (gaveta_B_3_1) |
Nó B 3 |
Piscina 1 |
Compartimento de disco 4 (gaveta_B_3_3) |
||
Compartimento de disco 5 (shelf_A_4_1) |
Nó A 4 |
Piscina 0 |
Compartimento de disco 6 (shelf_A_4_3) |
||
Compartimento de disco 7 (gaveta_B_4_1) |
Nó B 4 |
Piscina 1 |
Compartimento de disco 8 (gaveta_B_4_3) |
Prateleiras de disco no local B
Compartimento de disco (sample_shelf_name)… |
Pertence a… |
E é atribuído a esse nó… |
Compartimento de disco 9 (gaveta_B_1_2) |
Nó B 1 |
Piscina 0 |
Compartimento de disco 10 (gaveta_B_1_4) |
Compartimento de disco 11 (shelf_A_1_2) |
Nó A 1 |
Piscina 1 |
Compartimento de disco 12 (shelf_A_1_4) |
Compartimento de disco 13 (gaveta_B_2_2) |
Nó B 2 |
Piscina 0 |
Compartimento de disco 14 (gaveta_B_2_4) |
Compartimento de disco 15 (shelf_A_2_2) |
Nó A 2 |
Piscina 1 |
Compartimento de disco 16 (shelf_A_2_4) |
Compartimento de disco 1 (gaveta_B_3_2) |
Nó A 3 |
Piscina 0 |
Compartimento de disco 2 (gaveta_B_3_4) |
Compartimento de disco 3 (shelf_A_3_2) |
Nó B 3 |
Piscina 1 |
Compartimento de disco 4 (shelf_A_3_4) |
Compartimento de disco 5 (gaveta_B_4_2) |
Nó A 4 |
Piscina 0 |
Compartimento de disco 6 (gaveta_B_4_4) |
Compartimento de disco 7 (shelf_A_4_2) |
Nó B 4 |
-
Confirme as atribuições do compartimento:
disk show –v -
Se necessário, atribua explicitamente discos nas gavetas de disco conetadas ao pool apropriado:
disk assignO uso de curingas no comando permite atribuir todos os discos em um compartimento de disco com um único comando. É possível identificar as IDs e os compartimentos do compartimento de disco para cada disco com o
storage show disk -xcomando.
Atribuição de propriedade de disco em sistemas que não sejam AFF
Se os nós do MetroCluster não tiverem os discos corretamente atribuídos ou se você estiver usando DS460C compartimentos de disco na sua configuração, será necessário atribuir discos a cada um dos nós na configuração do MetroCluster de acordo com compartimento a compartimento. Você criará uma configuração na qual cada nó tem o mesmo número de discos em seus pools de discos locais e remotos.
Os controladores de armazenamento têm de estar no modo de manutenção.
Se a configuração não incluir DS460C compartimentos de disco, essa tarefa não será necessária se os discos tiverem sido atribuídos corretamente quando recebidos de fábrica.
|
|
O pool 0 sempre contém os discos que são encontrados no mesmo local do sistema de armazenamento que os possui. O pool 1 sempre contém os discos que são remotos para o sistema de storage que os possui. |
Se a configuração incluir DS460C compartimentos de disco, você deve atribuir manualmente os discos usando as seguintes diretrizes para cada gaveta de 12 discos:
Atribuir estes discos na gaveta… |
Para este nó e pool… |
0 - 2 |
Pool do nó local 0 |
3 - 5 |
Pool do nó de PARCEIRO HA 0 |
6 - 8 |
Parceiro de DR do pool de nós locais 1 |
9 - 11 |
Parceiro de DR do pool de parceiros de HA 1 |
Esse padrão de atribuição de disco garante que um agregado seja minimamente afetado caso uma gaveta fique offline.
-
Se você não tiver feito isso, inicialize cada sistema no modo Manutenção.
-
Atribua os compartimentos de disco aos nós localizados no primeiro local (local A):
Os compartimentos de disco no mesmo local que o nó são atribuídos ao pool 0 e os compartimentos de disco localizados no local do parceiro são atribuídos ao pool 1.
Você deve atribuir um número igual de prateleiras a cada pool.
-
No primeiro nó, atribua sistematicamente as gavetas de disco locais ao pool 0 e às gavetas de disco remotas ao pool 1:
disk assign -shelf local-switch-name:shelf-name.port -p poolSe o controlador de storage Controller_A_1 tiver quatro compartimentos, você emitirá os seguintes comandos:
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1
-
Repita o processo para o segundo nó no local, atribuindo sistematicamente as gavetas de disco locais ao pool 0 e as gavetas de disco remotas ao pool 1:
disk assign -shelf local-switch-name:shelf-name.port -p poolSe o controlador de storage Controller_A_2 tiver quatro compartimentos, você emitirá os seguintes comandos:
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1
-
-
Atribua os compartimentos de disco aos nós localizados no segundo local (local B):
Os compartimentos de disco no mesmo local que o nó são atribuídos ao pool 0 e os compartimentos de disco localizados no local do parceiro são atribuídos ao pool 1.
Você deve atribuir um número igual de prateleiras a cada pool.
-
No primeiro nó no local remoto, atribua sistematicamente suas gavetas de disco locais ao pool 0 e suas gavetas de disco remotas ao pool 1:
disk assign -shelf local-switch-nameshelf-name -p poolSe o controlador de storage Controller_B_1 tiver quatro compartimentos, você emitirá os seguintes comandos:
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1
-
Repita o processo para o segundo nó no local remoto, atribuindo sistematicamente suas gavetas de disco locais ao pool 0 e suas gavetas de disco remotas ao pool 1:
disk assign -shelf shelf-name -p poolSe o controlador de storage Controller_B_2 tiver quatro compartimentos, você emitirá os seguintes comandos:
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1
-
-
Confirme as atribuições do compartimento:
storage show shelf -
Sair do modo de manutenção:
halt -
Apresentar o menu de arranque:
boot_ontap menu -
Em cada nó, selecione a opção 4 para inicializar todos os discos.
Atribuição de propriedade de disco em sistemas AFF
Se você estiver usando sistemas AFF em uma configuração com agregados espelhados e os nós não tiverem os discos (SSDs) corretamente atribuídos, atribua metade dos discos em cada gaveta a um nó local e a outra metade dos discos a seu nó de parceiro de HA. Você deve criar uma configuração na qual cada nó tenha o mesmo número de discos em seus pools de discos locais e remotos.
Os controladores de armazenamento têm de estar no modo de manutenção.
Isso não se aplica a configurações que tenham agregados sem espelhamento, uma configuração ativo/passivo ou que tenham um número desigual de discos em pools locais e remotos.
Esta tarefa não é necessária se os discos tiverem sido corretamente atribuídos quando recebidos de fábrica.
|
|
O pool 0 sempre contém os discos que são encontrados no mesmo local do sistema de armazenamento que os possui. O pool 1 sempre contém os discos que são remotos para o sistema de storage que os possui. |
-
Se você não tiver feito isso, inicialize cada sistema no modo Manutenção.
-
Atribua os discos aos nós localizados no primeiro local (local A):
Você deve atribuir um número igual de discos a cada pool.
-
No primeiro nó, atribua sistematicamente metade dos discos em cada gaveta ao pool 0 e a outra metade ao pool 0 do parceiro de HA:
disk assign -shelf <shelf-name> -p <pool> -n <number-of-disks>Se o controlador de storage Controller_A_1 tiver quatro gavetas, cada uma com SSDs de 8 TB, você emitirá os seguintes comandos:
*> disk assign -shelf FC_switch_A_1:1-4.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf2 -p 1 -n 4
-
Repita o processo para o segundo nó no local, atribuindo sistematicamente metade dos discos em cada gaveta ao pool 1 e a outra metade ao pool 1 do parceiro de HA:
disk assign -disk disk-name -p poolSe o controlador de storage Controller_A_1 tiver quatro gavetas, cada uma com SSDs de 8 TB, você emitirá os seguintes comandos:
*> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-4.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-4.shelf4 -p 1 -n 4
-
-
Atribua os discos aos nós localizados no segundo local (local B):
Você deve atribuir um número igual de discos a cada pool.
-
No primeiro nó no local remoto, atribua sistematicamente metade dos discos em cada gaveta ao pool 0 e a outra metade ao pool 0 do parceiro de HA:
disk assign -disk disk-name -p poolSe o controlador de storage Controller_B_1 tiver quatro gavetas, cada uma com SSDs de 8 TB, você emitirá os seguintes comandos:
*> disk assign -shelf FC_switch_B_1:1-5.shelf1 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf2 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf1 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf2 -p 1 -n 4
-
Repita o processo para o segundo nó no local remoto, atribuindo sistematicamente metade dos discos em cada gaveta ao pool 1 e a outra metade ao pool 1 do parceiro de HA:
disk assign -disk disk-name -p poolSe o controlador de storage Controller_B_2 tiver quatro gavetas, cada uma com SSDs de 8 TB, você emitirá os seguintes comandos:
*> disk assign -shelf FC_switch_B_1:1-5.shelf3 -p 0 -n 4 *> disk assign -shelf FC_switch_B_1:1-5.shelf4 -p 0 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf3 -p 1 -n 4 *> disk assign -shelf FC_switch_A_1:1-5.shelf4 -p 1 -n 4
-
-
Confirme as atribuições de disco:
storage show disk -
Sair do modo de manutenção:
halt -
Apresentar o menu de arranque:
boot_ontap menu -
Em cada nó, selecione a opção 4 para inicializar todos os discos.
Verificando a atribuição de discos no modo Manutenção em uma configuração de dois nós
Antes de iniciar totalmente o sistema no ONTAP, você pode opcionalmente inicializar o sistema no modo Manutenção e verificar a atribuição de disco nos nós. Os discos devem ser atribuídos para criar uma configuração totalmente simétrica, com os dois locais que possuem suas próprias gavetas de disco e fornecimento de dados, em que cada nó e cada pool têm um número igual de discos espelhados atribuídos a eles.
O sistema tem de estar no modo de manutenção.
Os novos sistemas MetroCluster têm atribuição de disco concluída antes do envio.
A tabela a seguir mostra exemplos de atribuições de pool para uma configuração do MetroCluster. Os discos são atribuídos a pools por compartimento.
Compartimento de disco (nome do exemplo)… |
No local… |
Pertence a… |
E é atribuído a esse nó… |
Compartimento de disco 1 (shelf_A_1_1) |
Local A |
Nó A 1 |
Piscina 0 |
Compartimento de disco 2 (shelf_A_1_3) |
|||
Compartimento de disco 3 (gaveta_B_1_1) |
Nó B 1 |
Piscina 1 |
|
Compartimento de disco 4 (gaveta_B_1_3) |
|||
Compartimento de disco 9 (gaveta_B_1_2) |
Local B |
Nó B 1 |
Piscina 0 |
Compartimento de disco 10 (gaveta_B_1_4) |
|||
Compartimento de disco 11 (shelf_A_1_2) |
Nó A 1 |
Piscina 1 |
|
Compartimento de disco 12 (shelf_A_1_4) |
Se a configuração incluir DS460C compartimentos de disco, você deve atribuir manualmente os discos usando as seguintes diretrizes para cada gaveta de 12 discos:
Atribuir estes discos na gaveta… |
Para este nó e pool… |
1 - 6 |
Pool do nó local 0 |
7 - 12 |
Pool do parceiro DR 1 |
Esse padrão de atribuição de disco minimiza o efeito em um agregado se uma gaveta ficar offline.
-
Se o seu sistema foi recebido de fábrica, confirme as atribuições de prateleira:
disk show –v -
Se necessário, você pode atribuir explicitamente discos nas gavetas de disco conetadas ao pool apropriado usando o comando Disk Assign.
Os compartimentos de disco no mesmo local que o nó são atribuídos ao pool 0 e os compartimentos de disco localizados no local do parceiro são atribuídos ao pool 1. Você deve atribuir um número igual de prateleiras a cada pool.
-
Se você não tiver feito isso, inicialize cada sistema no modo Manutenção.
-
No nó no Local A, atribua sistematicamente as gavetas de disco locais ao pool 0 e às gavetas de disco remotas ao pool 1:
disk assign -shelf disk_shelf_name -p poolSe o nó_A_1 do controlador de storage tiver quatro compartimentos, você emitirá os seguintes comandos:
*> disk assign -shelf shelf_A_1_1 -p 0 *> disk assign -shelf shelf_A_1_3 -p 0 *> disk assign -shelf shelf_A_1_2 -p 1 *> disk assign -shelf shelf_A_1_4 -p 1
-
No nó do local remoto (local B), atribua sistematicamente seus compartimentos de disco locais ao pool 0 e suas gavetas de disco remotas ao pool 1:
disk assign -shelf disk_shelf_name -p poolSe o nó_B_1 do controlador de storage tiver quatro compartimentos, você emitirá os seguintes comandos:
*> disk assign -shelf shelf_B_1_2 -p 0 *> disk assign -shelf shelf_B_1_4 -p 0 *> disk assign -shelf shelf_B_1_1 -p 1 *> disk assign -shelf shelf_B_1_3 -p 1
-
Mostrar as IDs e os compartimentos do compartimento de disco para cada disco:
disk show –v
-
Configurar o ONTAP
Tem de configurar o ONTAP em cada módulo do controlador.
Se você precisar netboot dos novos controladores, consulte "Netbooting os novos módulos do controlador" no MetroCluster Upgrade, Transition e Expansion Guide.
Configurando o ONTAP em uma configuração de MetroCluster de dois nós
Em uma configuração de MetroCluster de dois nós, em cada cluster, você deve inicializar o nó, sair do assistente de configuração de cluster e usar o comando de configuração de cluster para configurar o nó em um cluster de nó único.
Você não deve ter configurado o processador de serviço.
Essa tarefa é para configurações de MetroCluster de dois nós que usam storage nativo do NetApp.
Essa tarefa deve ser executada em ambos os clusters na configuração do MetroCluster.
Para obter mais informações gerais sobre a configuração do ONTAP, "Configure o ONTAP"consulte .
-
Ligue o primeiro nó.
Repita esta etapa no nó no local de recuperação de desastres (DR). O nó é inicializado e, em seguida, o assistente Configuração de cluster é iniciado no console, informando que o AutoSupport será ativado automaticamente.
::> Welcome to the cluster setup wizard. You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the cluster setup wizard. Any changes you made before quitting will be saved. You can return to cluster setup at any time by typing "cluster setup". To accept a default or omit a question, do not enter a value. This system will send event messages and periodic reports to NetApp Technical Support. To disable this feature, enter autosupport modify -support disable within 24 hours. Enabling AutoSupport can significantly speed problem determination and resolution, should a problem occur on your system. For further information on AutoSupport, see: http://support.netapp.com/autosupport/ Type yes to confirm and continue {yes}: yes Enter the node management interface port [e0M]: Enter the node management interface IP address [10.101.01.01]: Enter the node management interface netmask [101.010.101.0]: Enter the node management interface default gateway [10.101.01.0]: Do you want to create a new cluster or join an existing cluster? {create, join}: -
Criar um novo cluster:
create -
Escolha se o nó deve ser usado como um cluster de nó único.
Do you intend for this node to be used as a single node cluster? {yes, no} [yes]: -
Aceite o padrão do sistema
yespressionando Enter ou insira seus próprios valores digitando `no`e pressionando Enter. -
Siga as instruções para concluir o assistente Configuração de cluster, pressione Enter para aceitar os valores padrão ou digitar seus próprios valores e pressione Enter.
Os valores padrão são determinados automaticamente com base na sua plataforma e configuração de rede.
-
Depois de concluir o assistente Cluster Setup e ele sair, verifique se o cluster está ativo e se o primeiro nó está saudável: "
cluster showO exemplo a seguir mostra um cluster no qual o primeiro nó (cluster1-01) está íntegro e qualificado para participar:
cluster1::> cluster show Node Health Eligibility --------------------- ------- ------------ cluster1-01 true true
Se for necessário alterar qualquer uma das configurações inseridas para o SVM admin ou nó SVM, você poderá acessar o assistente Configuração de cluster usando o comando de configuração de cluster.
Configuração do ONTAP em uma configuração de MetroCluster de oito ou quatro nós
Depois de inicializar cada nó, você será solicitado a executar a ferramenta Configuração do sistema para executar a configuração básica do nó e do cluster. Depois de configurar o cluster, você retorna à CLI do ONTAP para criar agregados e criar a configuração do MetroCluster.
Você deve ter cabeado a configuração do MetroCluster.
Essa tarefa é para configurações de MetroCluster de oito ou quatro nós que usam storage NetApp nativo.
Os novos sistemas MetroCluster estão pré-configurados; não é necessário executar estas etapas. No entanto, você deve configurar a ferramenta AutoSupport.
Essa tarefa deve ser executada em ambos os clusters na configuração do MetroCluster.
Este procedimento utiliza a ferramenta System Setup (Configuração do sistema). Se desejar, você pode usar o assistente de configuração do cluster da CLI.
-
Se você ainda não fez isso, ligue cada nó e deixe-os inicializar completamente.
Se o sistema estiver no modo Manutenção, emita o comando halt para sair do modo Manutenção e, em seguida, emita o seguinte comando a partir do prompt Loader:
boot_ontapA saída deve ser semelhante ao seguinte:
Welcome to node setup You can enter the following commands at any time: "help" or "?" - if you want to have a question clarified, "back" - if you want to change previously answered questions, and "exit" or "quit" - if you want to quit the setup wizard. Any changes you made before quitting will be saved. To accept a default or omit a question, do not enter a value. . . .
-
Ative a ferramenta AutoSupport seguindo as instruções fornecidas pelo sistema.
-
Responda aos prompts para configurar a interface de gerenciamento de nós.
Os prompts são semelhantes aos seguintes:
Enter the node management interface port: [e0M]: Enter the node management interface IP address: 10.228.160.229 Enter the node management interface netmask: 225.225.252.0 Enter the node management interface default gateway: 10.228.160.1
-
Confirme se os nós estão configurados no modo de alta disponibilidade:
storage failover show -fields modeCaso contrário, você deve emitir o seguinte comando em cada nó e reinicializar o nó:
storage failover modify -mode ha -node localhostEste comando configura o modo de alta disponibilidade, mas não ativa o failover de armazenamento. O failover de storage é ativado automaticamente quando a configuração do MetroCluster é executada posteriormente no processo de configuração.
-
Confirme se você tem quatro portas configuradas como interconexões de cluster:
network port showO exemplo a seguir mostra a saída para cluster_A:
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ node_A_1 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 node_A_2 **e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000** e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
Se você estiver criando um cluster de dois nós (um cluster sem switches de interconexão de cluster), ative o modo de rede sem switch-cluster:
-
Mude para o nível de privilégio avançado:
set -privilege advanced
Você pode responder
yquando solicitado a continuar no modo avançado. O prompt do modo avançado é exibido (*>).-
Ativar o modo sem switch-cluster:
network options switchless-cluster modify -enabled true -
Voltar ao nível de privilégio de administrador:
set -privilege admin
-
-
Inicie a ferramenta System Setup (Configuração do sistema) conforme indicado pelas informações que aparecem no console do sistema após a inicialização.
-
Use a ferramenta Configuração do sistema para configurar cada nó e criar o cluster, mas não criar agregados.
Você cria agregados espelhados em tarefas posteriores.
Retorne à interface da linha de comando ONTAP e conclua a configuração do MetroCluster executando as tarefas a seguir.
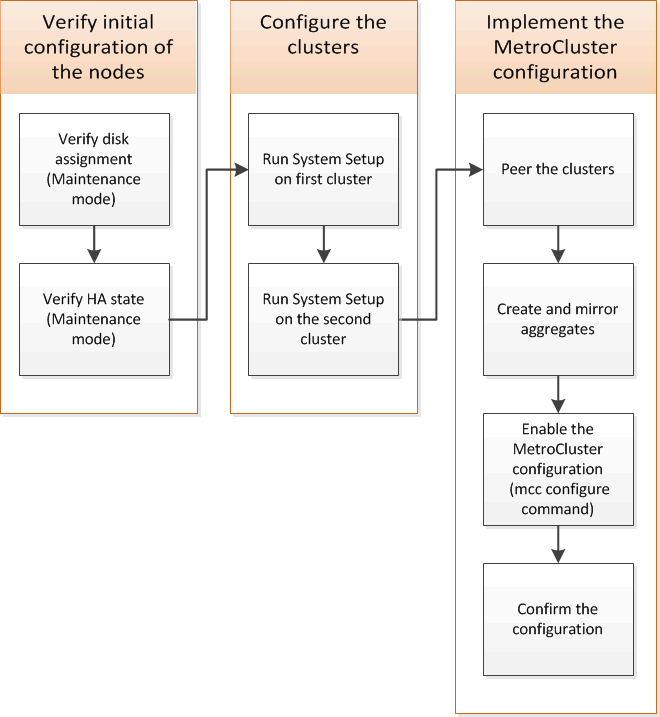
Configuração dos clusters em uma configuração do MetroCluster
É necessário fazer peer nos clusters, espelhar os agregados raiz, criar um agregado de dados espelhados e, em seguida, emitir o comando para implementar as operações do MetroCluster.
Antes de executar metrocluster configure`o , o modo HA e o espelhamento de DR não estão ativados e você pode ver uma mensagem de erro relacionada a esse comportamento esperado. Você ativa o modo HA e o espelhamento de DR mais tarde quando executa o comando `metrocluster configure para implementar a configuração.
Peering dos clusters
Os clusters na configuração do MetroCluster precisam estar em um relacionamento de mesmo nível para que possam se comunicar uns com os outros e executar o espelhamento de dados essencial para a recuperação de desastres do MetroCluster.
Configurando LIFs entre clusters
É necessário criar LIFs entre clusters nas portas usadas para comunicação entre os clusters de parceiros da MetroCluster. Você pode usar portas dedicadas ou portas que também têm tráfego de dados.
Configurando LIFs entre clusters em portas dedicadas
Você pode configurar LIFs entre clusters em portas dedicadas. Isso normalmente aumenta a largura de banda disponível para o tráfego de replicação.
-
Liste as portas no cluster:
network port showPara obter a sintaxe completa do comando, consulte a página man.
O exemplo a seguir mostra as portas de rede em "cluster01":
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 -
Determine quais portas estão disponíveis para se dedicar à comunicação entre clusters:
network interface show -fields home-port,curr-portPara obter a sintaxe completa do comando, consulte a página man.
O exemplo a seguir mostra que as portas "e0e" e "e0f" não foram atribuídas LIFs:
cluster01::> network interface show -fields home-port,curr-port vserver lif home-port curr-port ------- -------------------- --------- --------- Cluster cluster01-01_clus1 e0a e0a Cluster cluster01-01_clus2 e0b e0b Cluster cluster01-02_clus1 e0a e0a Cluster cluster01-02_clus2 e0b e0b cluster01 cluster_mgmt e0c e0c cluster01 cluster01-01_mgmt1 e0c e0c cluster01 cluster01-02_mgmt1 e0c e0c -
Crie um grupo de failover para as portas dedicadas:
network interface failover-groups create -vserver system_SVM -failover-group failover_group -targets physical_or_logical_portsO exemplo a seguir atribui as portas "e0e" e "e0f" ao grupo de failover intercluster01 no sistema "SVMcluster01":
cluster01::> network interface failover-groups create -vserver cluster01 -failover-group intercluster01 -targets cluster01-01:e0e,cluster01-01:e0f,cluster01-02:e0e,cluster01-02:e0f
-
Verifique se o grupo de failover foi criado:
network interface failover-groups showPara obter a sintaxe completa do comando, consulte a página man.
cluster01::> network interface failover-groups show Failover Vserver Group Targets ---------------- ---------------- -------------------------------------------- Cluster Cluster cluster01-01:e0a, cluster01-01:e0b, cluster01-02:e0a, cluster01-02:e0b cluster01 Default cluster01-01:e0c, cluster01-01:e0d, cluster01-02:e0c, cluster01-02:e0d, cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f intercluster01 cluster01-01:e0e, cluster01-01:e0f cluster01-02:e0e, cluster01-02:e0f -
Crie LIFs entre clusters no sistema e atribua-os ao grupo de failover.
ONTAP 9 F.6 e mais tardenetwork interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmask -failover-group failover_groupONTAP 9 F.5 e anterioresnetwork interface create -vserver system_SVM -lif LIF_name -role intercluster -home-node node -home-port port -address port_IP -netmask netmask -failover-group failover_groupPara obter a sintaxe completa do comando, consulte a página man.
O exemplo a seguir cria LIFs entre clusters "cluster01_icl01" e "cluster01_icl02" no grupo de failover "intercluster01":
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0e -address 192.168.1.201 -netmask 255.255.255.0 -failover-group intercluster01 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0e -address 192.168.1.202 -netmask 255.255.255.0 -failover-group intercluster01
-
Verifique se as LIFs entre clusters foram criadas:
ONTAP 9 F.6 e mais tardeExecute o comando:
network interface show -service-policy default-interclusterONTAP 9 F.5 e anterioresExecute o comando:
network interface show -role interclusterPara obter a sintaxe completa do comando, consulte a página man.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0e true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0f true -
Verifique se as LIFs entre clusters são redundantes:
ONTAP 9 F.6 e mais tardeExecute o comando:
network interface show -service-policy default-intercluster -failoverONTAP 9 F.5 e anterioresExecute o comando:
network interface show -role intercluster -failoverPara obter a sintaxe completa do comando, consulte a página man.
O exemplo a seguir mostra que os LIFs entre clusters "cluster01_icl01" e "cluster01_icl02" na porta SVM "e0e" falharão para a porta "e0f".
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0e local-only intercluster01 Failover Targets: cluster01-01:e0e, cluster01-01:e0f cluster01_icl02 cluster01-02:e0e local-only intercluster01 Failover Targets: cluster01-02:e0e, cluster01-02:e0f
Ao determinar se o uso de uma porta dedicada para replicação entre clusters é a solução de rede entre clusters correta, você deve considerar configurações e requisitos, como tipo de LAN, banda WAN disponível, intervalo de replicação, taxa de alteração e número de portas.
Configurando LIFs entre clusters em portas de dados compartilhados
Você pode configurar LIFs entre clusters em portas compartilhadas com a rede de dados. Isso reduz o número de portas de que você precisa para redes entre clusters.
-
Liste as portas no cluster:
network port showPara obter a sintaxe completa do comando, consulte a página man.
O exemplo a seguir mostra as portas de rede no cluster01:
cluster01::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- ------------ ---------------- ----- ------- ------------ cluster01-01 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 cluster01-02 e0a Cluster Cluster up 1500 auto/1000 e0b Cluster Cluster up 1500 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 -
Criar LIFs entre clusters no sistema:
ONTAP 9 F.6 e mais tardeExecute o comando:
network interface create -vserver system_SVM -lif LIF_name -service-policy default-intercluster -home-node node -home-port port -address port_IP -netmask netmaskONTAP 9 F.5 e anterioresExecute o comando:
network interface create -vserver system_SVM -lif LIF_name -role intercluster -home-node node -home-port port -address port_IP -netmask netmaskPara obter a sintaxe completa do comando, consulte a página man. O exemplo a seguir cria LIFs entre clusters cluster01_icl01 e cluster01_icl02:
cluster01::> network interface create -vserver cluster01 -lif cluster01_icl01 -service- policy default-intercluster -home-node cluster01-01 -home-port e0c -address 192.168.1.201 -netmask 255.255.255.0 cluster01::> network interface create -vserver cluster01 -lif cluster01_icl02 -service- policy default-intercluster -home-node cluster01-02 -home-port e0c -address 192.168.1.202 -netmask 255.255.255.0
-
Verifique se as LIFs entre clusters foram criadas:
ONTAP 9 F.6 e mais tardeExecute o comando:
network interface show -service-policy default-interclusterONTAP 9 F.5 e anterioresExecute o comando:
network interface show -role interclusterPara obter a sintaxe completa do comando, consulte a página man.
cluster01::> network interface show -service-policy default-intercluster Logical Status Network Current Current Is Vserver Interface Admin/Oper Address/Mask Node Port Home ----------- ---------- ---------- ------------------ ------------- ------- ---- cluster01 cluster01_icl01 up/up 192.168.1.201/24 cluster01-01 e0c true cluster01_icl02 up/up 192.168.1.202/24 cluster01-02 e0c true -
Verifique se as LIFs entre clusters são redundantes:
ONTAP 9 F.6 e mais tardeExecute o comando:
network interface show –service-policy default-intercluster -failoverONTAP 9 F.5 e anterioresExecute o comando:
network interface show -role intercluster -failoverPara obter a sintaxe completa do comando, consulte a página man.
O exemplo a seguir mostra que os LIFs entre clusters "cluster01_icl01" e "cluster01_icl02" na porta "e0c" falharão para a porta "e0d".
cluster01::> network interface show -service-policy default-intercluster –failover Logical Home Failover Failover Vserver Interface Node:Port Policy Group -------- --------------- --------------------- --------------- -------- cluster01 cluster01_icl01 cluster01-01:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-01:e0c, cluster01-01:e0d cluster01_icl02 cluster01-02:e0c local-only 192.168.1.201/24 Failover Targets: cluster01-02:e0c, cluster01-02:e0d
Criando um relacionamento de cluster peer
É necessário criar o relacionamento de peers de clusters entre os clusters do MetroCluster.
Você pode usar o cluster peer create comando para criar uma relação entre pares entre um cluster local e remoto. Após a criação da relação de pares, você pode executar cluster peer create no cluster remoto para autenticá-la no cluster local.
-
Você precisa ter criado LIFs entre clusters em todos os nós nos clusters que estão sendo perados.
-
Os clusters precisam estar executando o ONTAP 9.3 ou posterior.
-
No cluster de destino, crie uma relação de pares com o cluster de origem:
cluster peer create -generate-passphrase -offer-expiration MM/DD/YYYY HH:MM:SS|1…7days|1…168hours -peer-addrs peer_LIF_IPs -ipspace ipspaceSe você especificar ambos
-generate-passphrasee-peer-addrs, somente o cluster cujos LIFs entre clusters são especificados em-peer-addrspoderá usar a senha gerada.Você pode ignorar a
-ipspaceopção se não estiver usando um IPspace personalizado. Para obter a sintaxe completa do comando, consulte a página man.O exemplo a seguir cria um relacionamento de peer de cluster em um cluster remoto não especificado:
cluster02::> cluster peer create -generate-passphrase -offer-expiration 2days Passphrase: UCa+6lRVICXeL/gq1WrK7ShR Expiration Time: 6/7/2017 08:16:10 EST Initial Allowed Vserver Peers: - Intercluster LIF IP: 192.140.112.101 Peer Cluster Name: Clus_7ShR (temporary generated) Warning: make a note of the passphrase - it cannot be displayed again. -
No cluster de origem, autentique o cluster de origem no cluster de destino:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspacePara obter a sintaxe completa do comando, consulte a página man.
O exemplo a seguir autentica o cluster local para o cluster remoto em endereços IP de LIF "192.140.112.101" e "192.140.112.102":
cluster01::> cluster peer create -peer-addrs 192.140.112.101,192.140.112.102 Notice: Use a generated passphrase or choose a passphrase of 8 or more characters. To ensure the authenticity of the peering relationship, use a phrase or sequence of characters that would be hard to guess. Enter the passphrase: Confirm the passphrase: Clusters cluster02 and cluster01 are peered.Digite a senha para o relacionamento de pares quando solicitado.
-
Verifique se o relacionamento de pares de cluster foi criado:
cluster peer show -instancecluster01::> cluster peer show -instance Peer Cluster Name: cluster02 Remote Intercluster Addresses: 192.140.112.101, 192.140.112.102 Availability of the Remote Cluster: Available Remote Cluster Name: cluster2 Active IP Addresses: 192.140.112.101, 192.140.112.102 Cluster Serial Number: 1-80-123456 Address Family of Relationship: ipv4 Authentication Status Administrative: no-authentication Authentication Status Operational: absent Last Update Time: 02/05 21:05:41 IPspace for the Relationship: Default -
Verifique a conetividade e o status dos nós no relacionamento de pares:
cluster peer health showcluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
Criando um relacionamento de cluster peer (ONTAP 9.2 e anterior)
Você pode usar o cluster peer create comando para iniciar uma solicitação de um relacionamento de peering entre um cluster local e remoto. Depois que o relacionamento de pares tiver sido solicitado pelo cluster local, você pode executar cluster peer create no cluster remoto para aceitar o relacionamento.
-
Você precisa ter criado LIFs entre clusters em todos os nós nos clusters que estão sendo perados.
-
Os administradores de cluster devem ter concordado com a frase-passe que cada cluster usará para se autenticar com o outro.
-
No cluster de destino de proteção de dados, crie uma relação de mesmo nível com o cluster de origem de proteção de dados:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspaceVocê pode ignorar a opção -ipspace se não estiver usando um IPspace personalizado. Para obter a sintaxe completa do comando, consulte a página man.
O exemplo a seguir cria uma relação de peer de cluster com o cluster remoto em endereços IP de LIF "192.168.2.201" e "192.168.2.202":
cluster02::> cluster peer create -peer-addrs 192.168.2.201,192.168.2.202 Enter the passphrase: Please enter the passphrase again:
Digite a senha para o relacionamento de pares quando solicitado.
-
No cluster de origem de proteção de dados, autentique o cluster de origem no cluster de destino:
cluster peer create -peer-addrs peer_LIF_IPs -ipspace ipspacePara obter a sintaxe completa do comando, consulte a página man.
O exemplo a seguir autentica o cluster local para o cluster remoto em endereços IP de LIF "192.140.112.203" e "192.140.112.204":
cluster01::> cluster peer create -peer-addrs 192.168.2.203,192.168.2.204 Please confirm the passphrase: Please confirm the passphrase again:
Digite a senha para o relacionamento de pares quando solicitado.
-
Verifique se o relacionamento de pares de cluster foi criado:
cluster peer show –instancePara obter a sintaxe completa do comando, consulte a página man.
cluster01::> cluster peer show –instance Peer Cluster Name: cluster01 Remote Intercluster Addresses: 192.168.2.201,192.168.2.202 Availability: Available Remote Cluster Name: cluster02 Active IP Addresses: 192.168.2.201,192.168.2.202 Cluster Serial Number: 1-80-000013
-
Verifique a conetividade e o status dos nós no relacionamento de pares:
cluster peer health show`Para obter a sintaxe completa do comando, consulte a página man.
cluster01::> cluster peer health show Node cluster-Name Node-Name Ping-Status RDB-Health Cluster-Health Avail… ---------- --------------------------- --------- --------------- -------- cluster01-01 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true cluster01-02 cluster02 cluster02-01 Data: interface_reachable ICMP: interface_reachable true true true cluster02-02 Data: interface_reachable ICMP: interface_reachable true true true
Espelhamento dos agregados de raiz
É necessário espelhar os agregados raiz para fornecer proteção de dados.
Por padrão, o agregado raiz é criado como agregado do tipo RAID-DP. Você pode alterar o agregado raiz de RAID-DP para o agregado do tipo RAID4. O comando a seguir modifica o agregado raiz para o agregado do tipo RAID4:
storage aggregate modify –aggregate aggr_name -raidtype raid4
|
|
Em sistemas que não sejam ADP, o tipo RAID do agregado pode ser modificado do RAID-DP padrão para RAID4 antes ou depois que o agregado é espelhado. |
-
Espelhar o agregado raiz:
storage aggregate mirror aggr_nameO comando a seguir espelha o agregado raiz para controller_A_1:
controller_A_1::> storage aggregate mirror aggr0_controller_A_1
Isso reflete o agregado, por isso consiste em um Plex local e um Plex remoto localizado no local remoto de MetroCluster.
-
Repita a etapa anterior para cada nó na configuração do MetroCluster.
Criando um agregado de dados espelhados em cada nó
Você precisa criar um agregado de dados espelhados em cada nó no grupo de DR.
-
Você deve saber quais unidades serão usadas no novo agregado.
-
Se você tiver vários tipos de unidade no sistema (armazenamento heterogêneo), você deve entender como pode garantir que o tipo de unidade correto esteja selecionado.
-
As unidades são de propriedade de um nó específico; quando você cria um agregado, todas as unidades nesse agregado precisam ser de propriedade do mesmo nó, que se torna o nó inicial desse agregado.
-
Os nomes agregados devem estar em conformidade com o esquema de nomenclatura que você determinou quando você planejou sua configuração do MetroCluster. "Gerenciamento de disco e agregado"Consulte .
-
Os nomes dos agregados devem ser únicos em todos os sites MetroCluster. Isso significa que você não pode ter dois agregados diferentes com o mesmo nome no site A e no site B.
-
Apresentar uma lista de peças sobresselentes disponíveis:
storage disk show -spare -owner node_name -
Crie o agregado usando o comando storage Aggregate create -mirror true.
Se você estiver conetado ao cluster na interface de gerenciamento de cluster, poderá criar um agregado em qualquer nó do cluster. Para garantir que o agregado seja criado em um nó específico, use o
-nodeparâmetro ou especifique as unidades que são de propriedade desse nó.Você pode especificar as seguintes opções:
-
Nó inicial do agregado (ou seja, o nó que possui o agregado em operação normal)
-
Lista de unidades específicas que devem ser adicionadas ao agregado
-
Número de unidades a incluir
Na configuração com suporte mínimo, na qual um número limitado de unidades está disponível, você deve usar a force-small-aggregateopção para permitir a criação de um agregado RAID-DP de três discos.-
Estilo de checksum para usar para o agregado
-
Tipo de unidades a utilizar
-
Tamanho das unidades a utilizar
-
Velocidade de condução a utilizar
-
Tipo RAID para grupos RAID no agregado
-
Número máximo de unidades que podem ser incluídas em um grupo RAID
-
Se unidades com RPM diferentes são permitidas
Para obter mais informações sobre essas opções, consulte a
storage aggregate createpágina de manual.O comando a seguir cria um agregado espelhado com 10 discos:
cluster_A::> storage aggregate create aggr1_node_A_1 -diskcount 10 -node node_A_1 -mirror true [Job 15] Job is queued: Create aggr1_node_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Verifique o grupo RAID e as unidades do seu novo agregado:
storage aggregate show-status -aggregate aggregate-name
Criação de agregados de dados sem espelhamento
Você pode, opcionalmente, criar agregados de dados sem espelhamento para dados que não exigem o espelhamento redundante fornecido pelas configurações do MetroCluster.
-
Verifique se você sabe quais unidades serão usadas no novo agregado.
-
Se você tiver vários tipos de unidade no sistema (armazenamento heterogêneo), você deve entender como pode verificar se o tipo de unidade correto está selecionado.

|
Nas configurações de FC MetroCluster, os agregados sem espelhamento só estarão online após um switchover se os discos remotos no agregado estiverem acessíveis. Se os ISLs falharem, o nó local poderá não conseguir aceder aos dados nos discos remotos sem espelhamento. A falha de um agregado pode levar a uma reinicialização do nó local. |
-
As unidades são de propriedade de um nó específico; quando você cria um agregado, todas as unidades nesse agregado precisam ser de propriedade do mesmo nó, que se torna o nó inicial desse agregado.
|
|
Os agregados sem espelhamento devem ser locais para o nó que os possui. |
-
Os nomes agregados devem estar em conformidade com o esquema de nomenclatura que você determinou quando você planejou sua configuração do MetroCluster.
-
Gerenciamento de discos e agregados contém mais informações sobre o espelhamento de agregados.
-
Apresentar uma lista de peças sobresselentes disponíveis:
storage disk show -spare -owner node_name -
Criar o agregado:
storage aggregate createSe você estiver conetado ao cluster na interface de gerenciamento de cluster, poderá criar um agregado em qualquer nó do cluster. Para verificar se o agregado é criado em um nó específico, você deve usar o
-nodeparâmetro ou especificar unidades que são de propriedade desse nó.Você pode especificar as seguintes opções:
-
Nó inicial do agregado (ou seja, o nó que possui o agregado em operação normal)
-
Lista de unidades específicas que devem ser adicionadas ao agregado
-
Número de unidades a incluir
-
Estilo de checksum para usar para o agregado
-
Tipo de unidades a utilizar
-
Tamanho das unidades a utilizar
-
Velocidade de condução a utilizar
-
Tipo RAID para grupos RAID no agregado
-
Número máximo de unidades que podem ser incluídas em um grupo RAID
-
Se unidades com RPM diferentes são permitidas
Para obter mais informações sobre essas opções, consulte a página de manual criar agregado de armazenamento.
O comando a seguir cria um agregado sem espelhamento com 10 discos:
controller_A_1::> storage aggregate create aggr1_controller_A_1 -diskcount 10 -node controller_A_1 [Job 15] Job is queued: Create aggr1_controller_A_1. [Job 15] The job is starting. [Job 15] Job succeeded: DONE
-
-
Verifique o grupo RAID e as unidades do seu novo agregado:
storage aggregate show-status -aggregate aggregate-name
Implementando a configuração do MetroCluster
Você deve executar o metrocluster configure comando para iniciar a proteção de dados em uma configuração do MetroCluster.
-
Deve haver pelo menos dois agregados de dados espelhados não-raiz em cada cluster.
Agregados de dados adicionais podem ser espelhados ou sem espelhamento.
Você pode verificar isso com o
storage aggregate showcomando.
Se você quiser usar um único agregado de dados espelhados, consulte Passo 1 para obter instruções. -
O estado ha-config dos controladores e chassis deve ser "mcc".
Você emite o metrocluster configure comando uma vez, em qualquer um dos nós, para ativar a configuração do MetroCluster. Você não precisa emitir o comando em cada um dos sites ou nós, e não importa em qual nó ou site você escolher emitir o comando.
`metrocluster configure`O comando emparelhará automaticamente os dois nós com as IDs de sistema mais baixas em cada um dos dois clusters como parceiros de recuperação de desastres (DR). Em uma configuração de MetroCluster de quatro nós, há dois pares de parceiros de DR. O segundo par de DR é criado a partir dos dois nós com IDs de sistema mais altas.
|
|
Você deve configurar o OKM (Onboard Key Manager) ou o gerenciamento de chaves externas antes de executar o comando metrocluster configure.
|
-
Configure o MetroCluster no seguinte formato:
Se a sua configuração do MetroCluster tiver…
Então faça isso…
Vários agregados de dados
A partir do prompt de qualquer nó, configure o MetroCluster:
metrocluster configure node-nameUm único agregado de dados espelhados
-
A partir do prompt de qualquer nó, altere para o nível de privilégio avançado:
set -privilege advancedVocê precisa responder
yquando for solicitado a continuar no modo avançado e você vir o prompt do modo avançado (*>). -
Configure o MetroCluster com o
-allow-with-one-aggregate trueparâmetro:metrocluster configure -allow-with-one-aggregate true node-name -
Voltar ao nível de privilégio de administrador:
set -privilege admin
A prática recomendada é ter vários agregados de dados. Se o primeiro grupo de DR tiver apenas um agregado e quiser adicionar um grupo de DR com um agregado, mova o volume de metadados do agregado de dados único. Para obter mais informações sobre este procedimento, "Movimentação de um volume de metadados nas configurações do MetroCluster"consulte . O comando a seguir habilita a configuração do MetroCluster em todos os nós do grupo DR que contém controller_A_1:
cluster_A::*> metrocluster configure -node-name controller_A_1 [Job 121] Job succeeded: Configure is successful.
-
-
Verifique o status da rede no local A:
network port showO exemplo a seguir mostra o uso da porta de rede em uma configuração MetroCluster de quatro nós:
cluster_A::> network port show Speed (Mbps) Node Port IPspace Broadcast Domain Link MTU Admin/Oper ------ --------- --------- ---------------- ----- ------- ------------ controller_A_1 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 controller_A_2 e0a Cluster Cluster up 9000 auto/1000 e0b Cluster Cluster up 9000 auto/1000 e0c Default Default up 1500 auto/1000 e0d Default Default up 1500 auto/1000 e0e Default Default up 1500 auto/1000 e0f Default Default up 1500 auto/1000 e0g Default Default up 1500 auto/1000 14 entries were displayed. -
Verifique a configuração do MetroCluster de ambos os sites na configuração do MetroCluster.
-
Verifique a configuração do local A:
metrocluster showcluster_A::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
Verifique a configuração a partir do local B:
metrocluster show
cluster_B::> metrocluster show Cluster Entry Name State ------------------------- ------------------- ----------- Local: cluster_B Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster Remote: cluster_A Configuration state configured Mode normal AUSO Failure Domain auso-on-cluster-disaster -
Configuração da entrega em ordem ou entrega fora de ordem de quadros no software ONTAP
Você deve configurar a entrega em ordem (IOD) ou entrega fora de ordem (OOD) de quadros de acordo com a configuração do switch Fibre Channel (FC).
Se o switch FC estiver configurado para IOD, o software ONTAP deverá ser configurado para IOD. Da mesma forma, se o switch FC estiver configurado para ODE, o ONTAP deverá ser configurado para ODE.
|
|
É necessário reiniciar o controlador para alterar a configuração. |
-
Configure o ONTAP para operar IOD ou OID de quadros.
-
Por padrão, o IOD de quadros é ativado no ONTAP. Para verificar os detalhes de configuração:
-
Entrar no modo avançado:
set advanced -
Verifique as configurações:
metrocluster interconnect adapter show
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
-
As etapas a seguir devem ser executadas em cada nó para configurar OID de quadros:
-
Entrar no modo avançado:
set advanced -
Verifique as configurações do MetroCluster:
metrocluster interconnect adapter showmcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up false 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up false 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up false 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up false 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
Ative O OOD no nó "CC4-B1" e no nó "CC4-B2":
metrocluster interconnect adapter modify -node node_name -is-ood-enabled true
mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b1 -is-ood-enabled true mcc4-b12_siteB::*> metrocluster interconnect adapter modify -node mcc4-b2 -is-ood-enabled true
-
Reinicie o controlador executando um takeover de alta disponibilidade (HA) em ambas as direções.
-
Verifique as configurações:
metrocluster interconnect adapter show
-
mcc4-b12_siteB::*> metrocluster interconnect adapter show Adapter Link Is OOD Node Adapter Name Type Status Enabled? IP Address Port Number ------------ --------------- ------- ------ -------- ----------- ----------- mcc4-b1 fcvi_device_0 FC-VI Up true 17.0.1.2 6a mcc4-b1 fcvi_device_1 FC-VI Up true 18.0.0.2 6b mcc4-b1 mlx4_0 IB Down false 192.0.5.193 ib2a mcc4-b1 mlx4_0 IB Up false 192.0.5.194 ib2b mcc4-b2 fcvi_device_0 FC-VI Up true 17.0.2.2 6a mcc4-b2 fcvi_device_1 FC-VI Up true 18.0.1.2 6b mcc4-b2 mlx4_0 IB Down false 192.0.2.9 ib2a mcc4-b2 mlx4_0 IB Up false 192.0.2.10 ib2b 8 entries were displayed. -
Configurando o SNMPv3 em uma configuração FC MetroCluster
Os protocolos de autenticação e privacidade nos switches e no sistema ONTAP devem ser os mesmos.
ONTAP atualmente suporta AES-128 para privacidade (criptografia) e SHA-256 para autenticação.
|
|
|
-
Crie um usuário SNMP para cada switch a partir do prompt do controlador:
security login createController_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10.10.10.10
-
Responda às seguintes instruções, conforme necessário, no seu site:
Para EngineID, pressione ENTER para atribuir o valor padrão. Enter the authoritative entity's EngineID [remote EngineID]: Which authentication protocol do you want to choose (none, md5, sha, sha2-256) [none]: sha Enter the authentication protocol password (minimum 8 characters long): Enter the authentication protocol password again: Which privacy protocol do you want to choose (none, des, aes128) [none]: aes128 Enter privacy protocol password (minimum 8 characters long): Enter privacy protocol password again:
O mesmo nome de usuário pode ser adicionado a diferentes switches com endereços IP diferentes. -
Crie um usuário SNMP para o resto dos switches.
O exemplo a seguir mostra como criar um nome de usuário para um switch com o endereço IP 10.10.10.11.
Controller_A_1::> security login create -user-or-group-name snmpv3user -application snmp -authentication-method usm -role none -remote-switch-ipaddress 10. 10.10.11
-
Verifique se há uma entrada de login para cada switch:
security login showController_A_1::> security login show -user-or-group-name snmpv3user -fields remote-switch-ipaddress vserver user-or-group-name application authentication-method remote-switch-ipaddress ------------ ------------------ ----------- --------------------- ----------------------- node_A_1 SVM 1 snmpv3user snmp usm 10.10.10.10 node_A_1 SVM 2 snmpv3user snmp usm 10.10.10.11 node_A_1 SVM 3 snmpv3user snmp usm 10.10.10.12 node_A_1 SVM 4 snmpv3user snmp usm 10.10.10.13 4 entries were displayed.
-
Configure o SNMPv3 nos switches a partir do prompt do switch:
Switches Brocade (FOS 9.x)snmpconfig --add snmpv3 -index <index> -user <user_name> -groupname <rw/ro> -auth_proto <auth_protocol> -auth_passwd <auth_password> -priv_proto <priv_protocol> -priv_passwd <priv_password>Interruptores Brocade (FOS 8.x e anteriores)snmpconfig --set snmpv3O exemplo mostra como configurar um usuário somente leitura. Você pode ajustar os usuários RW, se necessário. Se você precisar de acesso RO, após "Usuário (ro):" especifique "snmpv3user".
Switch-A1:admin> snmpconfig --set snmpv3 SNMP Informs Enabled (true, t, false, f): [false] true SNMPv3 user configuration(snmp user not configured in FOS user database will have physical AD and admin role as the default): User (rw): [snmpadmin1] Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [3] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [2] Engine ID: [00:00:00:00:00:00:00:00:00] User (ro): [snmpuser2] snmpv3user Auth Protocol [MD5(1)/SHA(2)/noAuth(3)]: (1..3) [2] Priv Protocol [DES(1)/noPriv(2)/AES128(3)/AES256(4)]): (2..2) [3]
Switches Ciscosnmp-server user <user_name> auth [md5/sha/sha-256] <auth_password> priv (aes-128) <priv_password>
Você também deve definir senhas em contas não utilizadas para protegê-las e usar a melhor criptografia disponível em sua versão do ONTAP. -
Configure criptografia e senhas nos demais usuários do switch, conforme necessário em seu site.
Configuração de componentes do MetroCluster para monitoramento de integridade
Você deve executar algumas etapas especiais de configuração antes de monitorar os componentes em uma configuração do MetroCluster.
|
|
Para maior segurança, a NetApp recomenda que você configure SNMPv2 ou SNMPv3 para monitorar o estado do switch. |
Essas tarefas se aplicam somente a sistemas com pontes FC para SAS.
A partir do Fabric OS 9.0.1, o SNMPv2 não é suportado para monitoramento de integridade em switches Brocade, você deve usar o SNMPv3 em vez disso. Se você estiver usando o SNMPv3, deve configurar o SNMPv3 no ONTAP antes de prosseguir para a seção a seguir. Para mais detalhes, consulte Configurando o SNMPv3 em uma configuração FC MetroCluster.
|
|
|
O NetApp oferece suporte apenas às seguintes ferramentas para monitorar os componentes em uma configuração do MetroCluster FC:
-
Consultor de rede Brocade (BNA)
-
Brocade SANnav
-
Active IQ Config Advisor
-
Monitoramento NetApp de Saúde (ONTAP)
-
Coletor de dados MetroCluster (MC_DC)
Configuração dos switches MetroCluster FC para monitoramento de integridade
Em uma configuração do MetroCluster conectado à malha, você precisa executar algumas etapas adicionais de configuração para monitorar os switches FC.
|
|
A partir de ONTAP 9.8, o storage switch comando é substituído por system switch fibre-channel. As etapas a seguir mostram o storage switch comando, mas se você estiver executando o ONTAP 9.8 ou posterior, o system switch fibre-channel comando é preferido.
|
-
Adicione um switch com um endereço IP a cada nó do MetroCluster:
O comando executado depende se você está usando SNMPv2 ou SNMPv3.
Adicione um switch usando SNMPv3:storage switch add -address <ip_adddress> -snmp-version SNMPv3 -snmp-community-or-username <SNMP_user_configured_on_the_switch>Adicione um switch usando SNMPv2:storage switch add -address ipaddressEste comando deve ser repetido em todos os quatro switches na configuração MetroCluster.
Os switches Brocade 7840 FC e todos os alertas são compatíveis com monitoramento de integridade, exceto NoISLPresent_Alert. O exemplo a seguir mostra o comando para adicionar um switch com endereço IP 10.10.10.10:
controller_A_1::> storage switch add -address 10.10.10.10
-
Verifique se todos os switches estão configurados corretamente:
storage switch showPode levar até 15 minutos para refletir todos os dados devido ao intervalo de votação de 15 minutos.
O exemplo a seguir mostra o comando dado para verificar se os switches MetroCluster FC estão configurados:
controller_A_1::> storage switch show Fabric Switch Name Vendor Model Switch WWN Status ---------------- --------------- ------- ------------ ---------------- ------ 1000000533a9e7a6 brcd6505-fcs40 Brocade Brocade6505 1000000533a9e7a6 OK 1000000533a9e7a6 brcd6505-fcs42 Brocade Brocade6505 1000000533d3660a OK 1000000533ed94d1 brcd6510-fcs44 Brocade Brocade6510 1000000533eda031 OK 1000000533ed94d1 brcd6510-fcs45 Brocade Brocade6510 1000000533ed94d1 OK 4 entries were displayed. controller_A_1::>
Se o nome mundial (WWN) do switch for exibido, o monitor de integridade do ONTAP pode entrar em Contato e monitorar o switch FC.
Configuração de pontes FC para SAS para monitoramento de integridade
Em sistemas que executam versões do ONTAP anteriores a 9,8, você deve executar algumas etapas especiais de configuração para monitorar as pontes FC para SAS na configuração do MetroCluster.
-
Ferramentas de monitoramento SNMP de terceiros não são suportadas para bridges FibreBridge.
-
A partir do ONTAP 9.8, as bridges FC para SAS são monitoradas por meio de conexões na banda por padrão, e não é necessária configuração adicional.
|
|
A partir de ONTAP 9.8, o storage bridge comando é substituído por system bridge. As etapas a seguir mostram o storage bridge comando, mas se você estiver executando o ONTAP 9.8 ou posterior, o system bridge comando é preferido.
|
-
No prompt do cluster do ONTAP, adicione a ponte ao monitoramento de integridade:
-
Adicione a ponte, usando o comando para sua versão do ONTAP:
Versão de ONTAP
Comando
9,5 e mais tarde
storage bridge add -address 0.0.0.0 -managed-by in-band -name bridge-name9,4 e anteriores
storage bridge add -address bridge-ip-address -name bridge-name -
Verifique se a ponte foi adicionada e está configurada corretamente:
storage bridge showPode levar até 15 minutos para refletir todos os dados por causa do intervalo de votação. O monitor de integridade do ONTAP pode entrar em Contato e monitorar a ponte se o valor na coluna "Status" for "ok", e outras informações, como o nome mundial (WWN), forem exibidas.
O exemplo a seguir mostra que as bridges FC para SAS estão configuradas:
controller_A_1::> storage bridge show Bridge Symbolic Name Is Monitored Monitor Status Vendor Model Bridge WWN ------------------ ------------- ------------ -------------- ------ ----------------- ---------- ATTO_10.10.20.10 atto01 true ok Atto FibreBridge 7500N 20000010867038c0 ATTO_10.10.20.11 atto02 true ok Atto FibreBridge 7500N 20000010867033c0 ATTO_10.10.20.12 atto03 true ok Atto FibreBridge 7500N 20000010867030c0 ATTO_10.10.20.13 atto04 true ok Atto FibreBridge 7500N 2000001086703b80 4 entries were displayed controller_A_1::>
-
Verificar a configuração do MetroCluster
Você pode verificar se os componentes e as relações na configuração do MetroCluster estão funcionando corretamente.
Você deve fazer uma verificação após a configuração inicial e depois de fazer quaisquer alterações na configuração do MetroCluster. Você também deve fazer uma verificação antes de um switchover negociado (planejado) ou de uma operação de switchback.
Se o metrocluster check run comando for emitido duas vezes dentro de um curto espaço de tempo em um ou em ambos os clusters, um conflito pode ocorrer e o comando pode não coletar todos os dados. Comandos subsequentes metrocluster check show, então não mostrará a saída esperada.
-
Verificar a configuração:
metrocluster check runO comando é executado como um trabalho em segundo plano e pode não ser concluído imediatamente.
cluster_A::> metrocluster check run The operation has been started and is running in the background. Wait for it to complete and run "metrocluster check show" to view the results. To check the status of the running metrocluster check operation, use the command, "metrocluster operation history show -job-id 2245"
cluster_A::> metrocluster check show Component Result ------------------- --------- nodes ok lifs ok config-replication ok aggregates ok clusters ok connections ok volumes ok 7 entries were displayed.
-
Exibir resultados mais detalhados do comando mais recente
metrocluster check run:metrocluster check aggregate showmetrocluster check cluster showmetrocluster check config-replication showmetrocluster check lif showmetrocluster check node show
Os metrocluster check showcomandos mostram os resultados do comando mais recentemetrocluster check run. Você deve sempre executar ometrocluster check runcomando antes de usar osmetrocluster check showcomandos para que as informações exibidas sejam atuais.O exemplo a seguir mostra a
metrocluster check aggregate showsaída do comando para uma configuração de MetroCluster de quatro nós saudável:cluster_A::> metrocluster check aggregate show Last Checked On: 8/5/2014 00:42:58 Node Aggregate Check Result --------------- -------------------- --------------------- --------- controller_A_1 controller_A_1_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_1_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2 controller_A_2_aggr0 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr1 mirroring-status ok disk-pool-allocation ok ownership-state ok controller_A_2_aggr2 mirroring-status ok disk-pool-allocation ok ownership-state ok 18 entries were displayed.O exemplo a seguir mostra a
metrocluster check cluster showsaída do comando para uma configuração de MetroCluster de quatro nós saudável. Isso indica que os clusters estão prontos para executar um switchover negociado, se necessário.Last Checked On: 9/13/2017 20:47:04 Cluster Check Result --------------------- ------------------------------- --------- mccint-fas9000-0102 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok mccint-fas9000-0304 negotiated-switchover-ready not-applicable switchback-ready not-applicable job-schedules ok licenses ok periodic-check-enabled ok 10 entries were displayed.
Verificando erros de configuração do MetroCluster com o Config Advisor
Você pode acessar o site de suporte da NetApp e baixar a ferramenta Config Advisor para verificar se há erros de configuração comuns.
O Config Advisor é uma ferramenta de validação de configuração e verificação de integridade. Você pode implantá-lo em sites seguros e sites não seguros para coleta de dados e análise do sistema.
|
|
O suporte para Config Advisor é limitado e está disponível apenas online. |
-
Vá para a página de download do Config Advisor e baixe a ferramenta.
-
Execute o Config Advisor, revise a saída da ferramenta e siga as recomendações na saída para resolver quaisquer problemas descobertos.
Verificação da operação local de HA
Se você tiver uma configuração de MetroCluster de quatro nós, verifique a operação dos pares de HA locais na configuração do MetroCluster. Isso não é necessário para configurações de dois nós.
As configurações de MetroCluster de dois nós não consistem em pares de HA locais, e essa tarefa não se aplica.
Os exemplos nesta tarefa usam convenções de nomenclatura padrão:
-
Cluster_A
-
controller_A_1
-
controller_A_2
-
-
Cluster_B
-
controller_B_1
-
controller_B_2
-
-
Em cluster_A, execute um failover e giveback em ambas as direções.
-
Confirme se o failover de armazenamento está ativado:
storage failover showA saída deve indicar que a aquisição é possível para ambos os nós:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed. -
Assuma o comando controller_A_2 do controller_A_1:
storage failover takeover controller_A_2Você pode usar o
storage failover show-takeovercomando para monitorar o andamento da operação de aquisição. -
Confirme se a aquisição está concluída:
storage failover showA saída deve indicar que controller_A_1 está no estado de aquisição, o que significa que assumiu o seu parceiro HA:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- ----------------- controller_A_1 controller_A_2 false In takeover controller_A_2 controller_A_1 - Unknown 2 entries were displayed. -
Devolver o controlador_A_2:
storage failover giveback controller_A_2Você pode usar o
storage failover show-givebackcomando para monitorar o progresso da operação de giveback. -
Confirme se o failover de armazenamento retornou ao estado normal:
storage failover showA saída deve indicar que a aquisição é possível para ambos os nós:
cluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------- -------- --------------------------- controller_A_1 controller_A_2 true Connected to controller_A_2 controller_A_2 controller_A_1 true Connected to controller_A_1 2 entries were displayed.-
Repita as subetapas anteriores, desta vez assumindo controller_A_1 do controller_A_2.
-
-
Repita os passos anteriores no cluster_B.
Verificando switchover, cura e switchback
Você deve verificar as operações de switchover, recuperação e switchback da configuração do MetroCluster.
-
Use os procedimentos para comutação negociada, cura e switchback que são mencionados no "Recuperar de um desastre" .
Protegendo arquivos de backup de configuração
Você pode fornecer proteção adicional para os arquivos de backup de configuração de cluster especificando um URL remoto (HTTP ou FTP) onde os arquivos de backup de configuração serão carregados além dos locais padrão no cluster local.
-
Defina o URL do destino remoto para os arquivos de backup de configuração:
system configuration backup settings modify URL-of-destinationO "Gerenciamento de clusters com a CLI" contém informações adicionais na seção Gerenciando backups de configuração.