

Atualizar uma configuração IP MetroCluster de quatro ou oito nós (ONTAP 9.8 e posterior)
 Sugerir alterações
Sugerir alterações
Você pode usar este procedimento para atualizar controladores e storage em configurações de quatro nós ou oito nós.
A partir do ONTAP 9.13,1, é possível atualizar os controladores e o armazenamento em uma configuração IP MetroCluster de oito nós expandindo a configuração para se tornar uma configuração temporária de doze nós e, em seguida, remover os grupos de recuperação de desastres (DR) antigos.
A partir do ONTAP 9.8, é possível atualizar os controladores e o armazenamento em uma configuração IP MetroCluster de quatro nós expandindo a configuração para se tornar uma configuração temporária de oito nós e, em seguida, remover o antigo grupo de DR.
A orientação a seguir é para um cenário incomum em que você precisa adicionar um modelo de plataforma mais antigo (plataformas lançadas antes do ONTAP 9.15.1) a uma configuração existente do MetroCluster que contém um modelo de plataforma mais recente (plataformas lançadas no ONTAP 9.15.1 ou posterior).
Se a sua configuração existente do MetroCluster contiver uma plataforma que usa portas de cluster/HA compartilhadas (plataformas lançadas no ONTAP 9.15.1 ou posterior), você não poderá adicionar uma plataforma que usa portas de MetroCluster/HA compartilhadas (plataformas lançadas antes do ONTAP 9.15.1) sem atualizar todos os nós na configuração para o ONTAP 9.15.1P11 ou ONTAP 9.16.1P4 ou posterior.

|
Adicionar um modelo de plataforma mais antigo que usa portas HA compartilhadas/ do MetroCluster * a um MetroCluster que contém um modelo de plataforma mais novo que usa *portas HA/do cluster compartilhadas é um cenário incomum e a maioria das combinações não é afetada. |
Use a tabela a seguir para verificar se sua combinação é afetada. Se sua plataforma existente estiver listada na primeira coluna e a plataforma que você deseja adicionar à configuração estiver listada na segunda coluna, todos os nós na configuração deverão estar executando o ONTAP 9.15.1P11 ou ONTAP 9.16.1P4 ou posterior para adicionar o novo grupo de DR.
| Se o seu MetroCluster existente contiver… | E a plataforma que você está adicionando é… | Então… | ||
|---|---|---|---|---|
Um sistema AFF usando portas de cluster/HA compartilhadas:
|
Um sistema FAS usando portas de cluster/HA compartilhadas:
|
Um sistema AFF usando portas MetroCluster/HA compartilhadas:
|
Um sistema FAS usando portas MetroCluster/HA compartilhadas:
|
Antes de adicionar a nova plataforma à sua configuração existente do MetroCluster, atualize todos os nós na configuração existente e nova para ONTAP 9.15.1P11 ou ONTAP 9.16.1P4 ou posterior. |
-
Se você tiver uma configuração de oito nós, seu sistema deve estar executando o ONTAP 9.13,1 ou posterior.
-
Se você tiver uma configuração de quatro nós, seu sistema deve estar executando o ONTAP 9.8 ou posterior.
-
Se você também estiver atualizando os switches IP, deverá atualizá-los antes de executar este procedimento de atualização.
-
Este procedimento descreve as etapas necessárias para atualizar um grupo de RD de quatro nós. Se você tiver uma configuração de oito nós (dois grupos de DR), poderá atualizar um ou ambos os grupos de DR.
Refresh DR groups one at a time. * References to "old nodes" mean the nodes that you intend to replace. * For eight-node configurations, the source and target eight-node MetroCluster platform combination must be supported.

Se você atualizar ambos os grupos de DR, a combinação de plataforma pode não ser suportada depois de atualizar o primeiro grupo de DR. É necessário atualizar os dois grupos de DR para obter uma configuração de oito nós compatível. -
Você só pode atualizar modelos de plataforma específicos usando este procedimento em uma configuração IP do MetroCluster.
-
Para obter informações sobre quais combinações de atualização de plataforma são suportadas, consulte a tabela de atualização de IP do MetroCluster no "Escolher um método de atualização do sistema".
-
-
Aplicam-se os limites inferiores das plataformas de origem e destino. Se você fizer a transição para uma plataforma superior, os limites da nova plataforma serão aplicados somente após a conclusão da atualização técnica de todos os grupos de DR.
-
Se você executar uma atualização técnica para uma plataforma com limites inferiores à plataforma de origem, você deve ajustar e reduzir os limites para estar em, ou abaixo, os limites da plataforma de destino antes de executar este procedimento.
Ativar o registo da consola
O NetApp recomenda fortemente que você ative o log do console nos dispositivos que você está usando e execute as seguintes ações ao executar este procedimento:
-
Deixe o AutoSupport ativado durante a manutenção.
-
Acione uma mensagem de manutenção do AutoSupport antes e depois da manutenção para desativar a criação de casos durante a atividade de manutenção.
Consulte o artigo da base de dados de Conhecimento "Como suprimir a criação automática de casos durante as janelas de manutenção programada".
-
Ative o registo de sessão para qualquer sessão CLI. Para obter instruções sobre como ativar o registo de sessão, consulte a secção "saída de sessão de registo" no artigo da base de dados de conhecimento "Como configurar o PuTTY para uma conetividade ideal aos sistemas ONTAP".
Execute o procedimento de atualização
Siga as etapas a seguir para atualizar a configuração IP do MetroCluster.
-
Verifique se você tem um domínio de broadcast padrão criado nos nós antigos.
Quando você adiciona novos nós a um cluster existente sem um domínio de broadcast padrão, as LIFs de gerenciamento de nós são criadas para os novos nós usando identificadores únicos universais (UUIDs) em vez dos nomes esperados. Para obter mais informações, consulte o artigo da base de dados de Conhecimento "LIFs de gerenciamento de nós em nós recém-adicionados gerados com nomes UUID" .
-
Reúna informações dos nós antigos.
Nesta fase, a configuração de quatro nós aparece como mostrado na seguinte imagem:
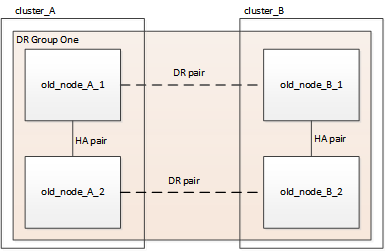
A configuração de oito nós aparece como mostrado na imagem a seguir:
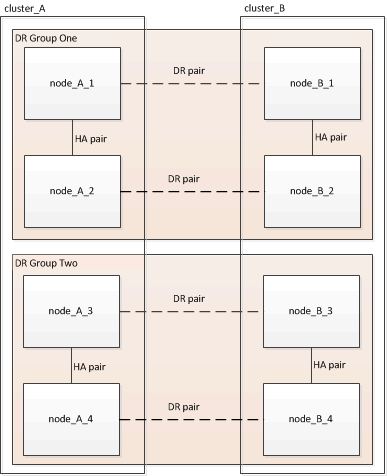
-
Para impedir a geração automática de casos de suporte, envie uma mensagem AutoSupport para indicar que a atualização está em andamento.
-
Execute o seguinte comando
system node autosupport invoke -node * -type all -message "MAINT=10h Upgrading old-model to new-model"O exemplo a seguir especifica uma janela de manutenção de 10 horas. Reserve um tempo adicional dependendo do seu plano.
Se a manutenção for concluída antes do tempo decorrido, você poderá invocar uma mensagem AutoSupport indicando o fim do período de manutenção:
system node autosupport invoke -node * -type all -message MAINT=end-
Repita o comando no cluster de parceiros.
-
-
Se a criptografia de ponta a ponta estiver ativada, siga as etapas para "Desative a criptografia de ponta a ponta".
-
Remova a configuração do MetroCluster existente do tiebreaker, Mediator ou outro software que possa iniciar o switchover.
Se você estiver usando…
Use este procedimento…
Desempate
-
Use o comando tiebreaker CLI
monitor removepara remover a configuração do MetroCluster.No exemplo a seguir, "'cluster_A" é removido do software:
NetApp MetroCluster Tiebreaker :> monitor remove -monitor-name cluster_A Successfully removed monitor from NetApp MetroCluster Tiebreaker software.
-
Confirme se a configuração do MetroCluster foi removida corretamente usando o comando tiebreaker CLI
monitor show -status.NetApp MetroCluster Tiebreaker :> monitor show -status
Mediador
Execute o seguinte comando no prompt do ONTAP:
metrocluster configuration-settings mediator removeAplicativos de terceiros
Consulte a documentação do produto.
-
-
Execute todas as etapas em "Expandindo uma configuração IP do MetroCluster"para adicionar os novos nós e o storage à configuração.
Quando o procedimento de expansão estiver concluído, a configuração temporária é apresentada conforme ilustrado nas seguintes imagens:
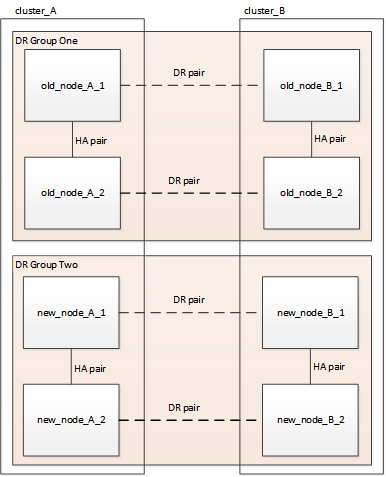 Figura 1. Configuração temporária de oito nós
Figura 1. Configuração temporária de oito nós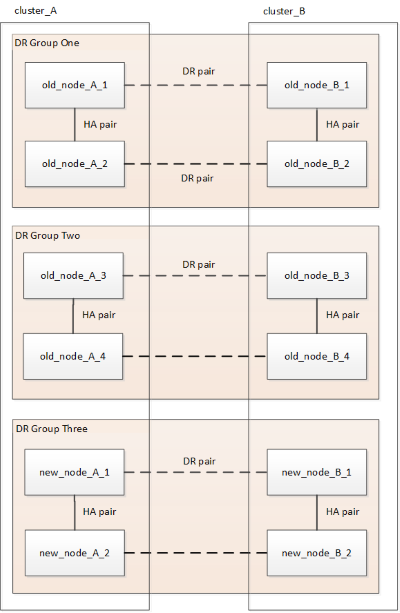 Figura 2. Configuração temporária de doze nós
Figura 2. Configuração temporária de doze nós -
Confirme se o takeover é possível e os nós estão conectados executando o seguinte comando em ambos os clusters:
storage failover showcluster_A::> storage failover show Takeover Node Partner Possible State Description -------------- -------------------- --------- ------------------ Node_FC_1 Node_FC_2 true Connected to Node_FC_2 Node_FC_2 Node_FC_1 true Connected to Node_FC_1 Node_IP_1 Node_IP_2 true Connected to Node_IP_2 Node_IP_2 Node_IP_1 true Connected to Node_IP_1 -
Mova os volumes CRS.
Execute as etapas em "Movimentação de um volume de metadados nas configurações do MetroCluster".
-
Mova os dados dos nós antigos para os novos nós usando os seguintes procedimentos:
-
Execute todas as etapas em "Crie um agregado e mova volumes para os novos nós".
Você pode optar por espelhar o agregado quando ou depois que ele é criado. -
Execute todas as etapas em "Mova LIFs de dados que não são SAN e LIFs de gerenciamento de cluster para os novos nós".
-
-
Modifique o endereço IP para o ponto de cluster dos nós transicionados para cada cluster:
-
Identifique o peer cluster_A usando o
cluster peer showcomando:cluster_A::> cluster peer show Peer Cluster Name Cluster Serial Number Availability Authentication ------------------------- --------------------- -------------- -------------- cluster_B 1-80-000011 Unavailable absent
-
Modifique o endereço IP peer cluster_A:
cluster peer modify -cluster cluster_A -peer-addrs node_A_3_IP -address-family ipv4
-
-
Identifique o peer cluster_B usando o
cluster peer showcomando:cluster_B::> cluster peer show Peer Cluster Name Cluster Serial Number Availability Authentication ------------------------- --------------------- -------------- -------------- cluster_A 1-80-000011 Unavailable absent
-
Modifique o endereço IP peer cluster_B:
cluster peer modify -cluster cluster_B -peer-addrs node_B_3_IP -address-family ipv4
-
-
Verifique se o endereço IP do peer do cluster está atualizado para cada cluster:
-
Verifique se o endereço IP é atualizado para cada cluster usando o
cluster peer show -instancecomando.O
Remote Intercluster Addressescampo nos exemplos a seguir exibe o endereço IP atualizado.Exemplo para cluster_A:
cluster_A::> cluster peer show -instance Peer Cluster Name: cluster_B Remote Intercluster Addresses: 172.21.178.204, 172.21.178.212 Availability of the Remote Cluster: Available Remote Cluster Name: cluster_B Active IP Addresses: 172.21.178.212, 172.21.178.204 Cluster Serial Number: 1-80-000011 Remote Cluster Nodes: node_B_3-IP, node_B_4-IP Remote Cluster Health: true Unreachable Local Nodes: - Address Family of Relationship: ipv4 Authentication Status Administrative: use-authentication Authentication Status Operational: ok Last Update Time: 4/20/2023 18:23:53 IPspace for the Relationship: Default Proposed Setting for Encryption of Inter-Cluster Communication: - Encryption Protocol For Inter-Cluster Communication: tls-psk Algorithm By Which the PSK Was Derived: jpake cluster_A::>+ Exemplo para cluster_B
-
cluster_B::> cluster peer show -instance Peer Cluster Name: cluster_A Remote Intercluster Addresses: 172.21.178.188, 172.21.178.196 <<<<<<<< Should reflect the modified address Availability of the Remote Cluster: Available Remote Cluster Name: cluster_A Active IP Addresses: 172.21.178.196, 172.21.178.188 Cluster Serial Number: 1-80-000011 Remote Cluster Nodes: node_A_3-IP, node_A_4-IP Remote Cluster Health: true Unreachable Local Nodes: - Address Family of Relationship: ipv4 Authentication Status Administrative: use-authentication Authentication Status Operational: ok Last Update Time: 4/20/2023 18:23:53 IPspace for the Relationship: Default Proposed Setting for Encryption of Inter-Cluster Communication: - Encryption Protocol For Inter-Cluster Communication: tls-psk Algorithm By Which the PSK Was Derived: jpake cluster_B::> -
-
Siga as etapas em "Removendo um grupo de recuperação de desastres" para remover o grupo de RD antigo.
-
Se você precisar atualizar ambos os grupos de DR em uma configuração de oito nós, repita todo o procedimento para cada grupo de DR.
Depois de remover o antigo grupo DR, a configuração aparece como mostrado nas seguintes imagens:
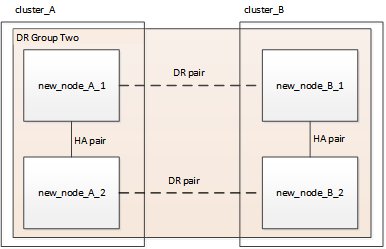 Figura 3. Configuração de quatro nós
Figura 3. Configuração de quatro nós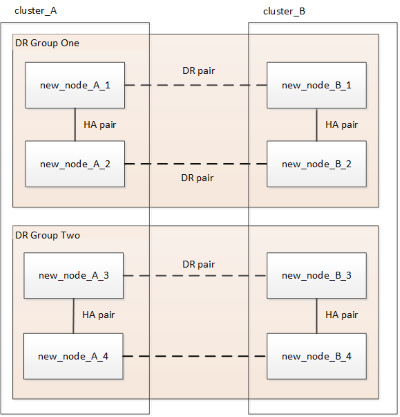 Figura 4. Configuração de oito nós
Figura 4. Configuração de oito nós -
Confirme o modo operacional da configuração do MetroCluster e efetue uma verificação do MetroCluster.
-
Confirme a configuração do MetroCluster e se o modo operacional está normal:
metrocluster show -
Confirme se todos os nós esperados são mostrados:
metrocluster node show -
Emita o seguinte comando:
metrocluster check run -
Apresentar os resultados da verificação MetroCluster:
metrocluster check show
-
-
Se você desativou a criptografia de ponta a ponta antes de adicionar os novos nós, poderá reativá-la seguindo as etapas em "Ative a criptografia de ponta a ponta".
-
Restaure o monitoramento, se necessário, usando o procedimento para sua configuração.
Se você estiver usando…
Use este procedimento
Desempate
"Adição de configurações do MetroCluster" na Instalação e Configuração do Desempate do MetroCluster.
Mediador
"Configurar o ONTAP Mediator a partir de uma configuração de IP do MetroCluster" Em Instalação e Configuração IP do MetroCluster.
Aplicativos de terceiros
Consulte a documentação do produto.
-
Para retomar a geração de casos de suporte automático, envie uma mensagem AutoSupport para indicar que a manutenção está concluída.
-
Emita o seguinte comando:
system node autosupport invoke -node * -type all -message MAINT=end -
Repita o comando no cluster de parceiros.
-