

Alcançar RPO zero com o StorageGRID: Um guia abrangente para replicação em vários locais
 Sugerir alterações
Sugerir alterações
Este relatório técnico fornece um guia completo para a implementação de estratégias de replicação do StorageGRID , visando atingir um Objetivo de Ponto de Recuperação (RPO) de zero em caso de falha do site. O documento detalha várias opções de implantação para o StorageGRID, incluindo replicação síncrona em vários locais e replicação assíncrona em várias grades. Este documento explica como as políticas de Gerenciamento do Ciclo de Vida da Informação (ILM) do StorageGRID podem ser configuradas para garantir a durabilidade e a disponibilidade dos dados em vários locais. Além disso, o relatório aborda considerações de desempenho, cenários de falha e processos de recuperação para manter as operações do cliente ininterruptas. O objetivo deste documento é fornecer informações para garantir que os dados permaneçam acessíveis e consistentes, mesmo em caso de falha total do site, utilizando técnicas de replicação síncrona e assíncrona.
Visão geral do StorageGRID
O NetApp StorageGRID é um sistema de storage baseado em objeto que dá suporte à API Amazon Simple Storage Service (Amazon S3) padrão do setor.
O StorageGRID fornece um namespace único em vários locais, com níveis de serviço variáveis orientados pelas políticas de gerenciamento do ciclo de vida das informações (ILM). Com essas políticas de ciclo de vida, você pode otimizar onde seus dados ficam ao longo de seu ciclo de vida.
O StorageGRID permite durabilidade e disponibilidade configuráveis de seus dados em soluções locais e distribuídas geograficamente. Não importa se seus dados estão no local ou em uma nuvem pública, os fluxos de trabalho de nuvem híbrida integrada permitem que sua empresa aproveite serviços de nuvem como Amazon Simple Notification Service (Amazon SNS), Google Cloud, Microsoft Azure Blob, Amazon S3 Glacier, Elasticsearch e muito mais.
StorageGRID Scale
Uma implementação mínima do StorageGRID consiste em um nó de administração e 3 nós de armazenamento em um único local. Uma única grade pode crescer até 220 nós. O StorageGRID pode ser implementado em um único local ou expandido para até 16 locais.
O nó Admin contém a interface de gerenciamento, um ponto central para métricas e registros, e mantém a configuração dos componentes do StorageGRID . O nó Admin também contém um balanceador de carga integrado para acesso à API S3.
O StorageGRID pode ser implantado somente como software, como dispositivos de máquina virtual VMware ou como dispositivos desenvolvidos especificamente para esse fim.
Um nó de armazenamento pode ser implantado da seguinte forma:
-
Um nó somente de metadados que maximiza a contagem de objetos
-
Um nó de armazenamento de objetos apenas maximizando o espaço do objeto
-
Um nó combinado de metadados e armazenamento de objetos que adiciona contagem de objetos e espaço de objetos
Cada nó de armazenamento pode ser dimensionado para capacidade de vários petabytes para armazenamento de objetos, permitindo um único namespace de centenas de petabytes. O StorageGRID também fornece um balanceador de carga integrado para operações da API S3, chamado de nó de gateway.
O StorageGRID consiste em uma coleção de nós colocados em uma topologia de site. Um site no StorageGRID pode ser um local físico exclusivo ou residir em um local físico compartilhado com outros sites na grade como uma construção lógica. Um site StorageGRID não deve abranger vários locais físicos. Um site representa uma infraestrutura de rede local (LAN) compartilhada e um domínio de falha.
Domínios de StorageGRID e falha
O StorageGRID contém várias camadas de domínios de falha a serem considerados para decidir como arquitetar sua solução, como armazenar seus dados e onde eles devem ser armazenados para reduzir os riscos de falhas.
-
Nível da grade - Uma grade composta por vários locais pode ter falhas ou isolamento do local e o(s) local(s) acessível(s) pode continuar operando como a grade.
-
Nível do local - falhas dentro de um local podem afetar as operações desse local, mas não afetarão o resto da grade.
-
Nível do nó - Uma falha do nó não afetará a operação do local.
-
Nível do disco - uma falha de disco não afetará a operação do nó.
Dados e metadados de objetos
Com o armazenamento de objetos, a unidade de armazenamento é um objeto, em vez de um arquivo ou um bloco. Ao contrário da hierarquia semelhante a uma árvore de um sistema de arquivos ou armazenamento em bloco, o armazenamento de objetos organiza os dados em um layout plano e não estruturado. O armazenamento de objetos separa a localização física dos dados do método usado para armazenar e recuperar esses dados.
Cada objeto em um sistema de storage baseado em objeto tem duas partes: Dados de objeto e metadados de objeto.
-
Os dados de objeto representam os dados subjacentes reais, por exemplo, uma fotografia, um filme ou um registro médico.
-
Metadados de objetos são qualquer informação que descreva um objeto.
O StorageGRID usa metadados de objetos para rastrear os locais de todos os objetos na grade e gerenciar o ciclo de vida de cada objeto ao longo do tempo.
Os metadados de objeto incluem informações como as seguintes:
-
Metadados do sistema, incluindo um ID exclusivo para cada objeto, o nome do objeto, o nome do bucket do S3, o nome ou ID da conta do locatário, o tamanho lógico do objeto, a data e a hora em que o objeto foi criado pela primeira vez e a data e a hora em que o objeto foi modificado pela última vez.
-
Local de armazenamento atual da cópia replicada ou do fragmento codificado por apagamento de cada objeto.
-
Quaisquer pares de valor-chave de metadados de usuário personalizados associados ao objeto.
-
Para objetos S3D, qualquer par de chave-valor de marca de objeto associado ao objeto
-
Para objetos segmentados e objetos multipartes, identificadores de segmento e tamanhos de dados.
Os metadados de objetos são personalizáveis e expansíveis, tornando-os flexíveis para uso dos aplicativos. Para obter informações detalhadas sobre como e onde o StorageGRID armazena metadados de objetos, vá para "Gerenciar o storage de metadados de objetos".
O sistema de gerenciamento do ciclo de vida das informações (ILM) da StorageGRID é usado para orquestrar o posicionamento, a duração e o comportamento de ingestão de todos os dados de objetos em seu sistema StorageGRID. As regras do ILM determinam como o StorageGRID armazena objetos ao longo do tempo usando réplicas dos objetos ou codificando o objeto de apagamento em nós e sites. Este sistema ILM é responsável pela consistência de dados do objeto dentro de uma grade.
Codificação de apagamento
O StorageGRID oferece a capacidade de apagar dados de código no nível do nó e no nível da unidade. Com os dispositivos StorageGRID , apagamos o código dos dados armazenados em cada nó em todas as unidades dentro do nó, fornecendo proteção local contra falhas de múltiplos discos que causam perda de dados ou interrupções. Reconstruções a partir de falhas de unidade são locais no nó e não exigem dados replicados pela rede.
Além disso, os dispositivos StorageGRID usam esquemas de codificação de eliminação para armazenar dados de objetos nos nós de um site ou distribuídos em três ou mais sites no sistema StorageGRID , por meio das regras de ILM do StorageGRID, que protegem contra falhas de nós.
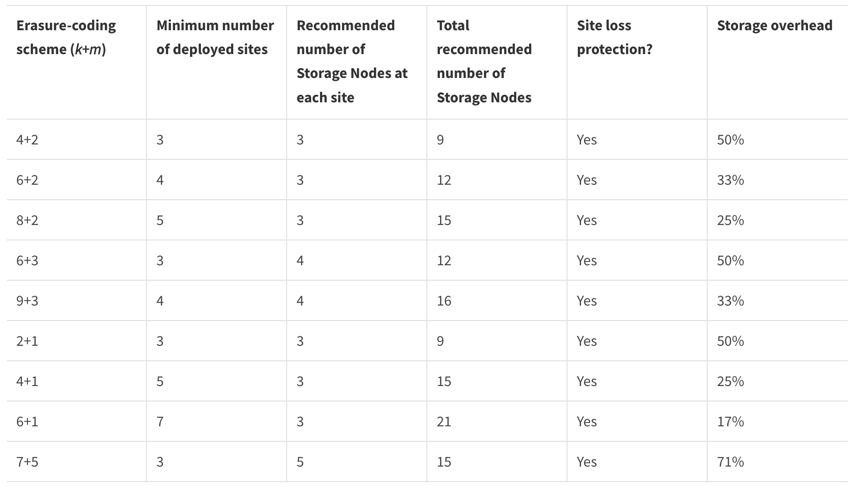
A codificação de apagamento fornece um layout de armazenamento resiliente a falhas de nós e sites, com uma sobrecarga menor do que a replicação. Todos os esquemas de codificação de apagamento do StorageGRID podem ser implementados em um único local, desde que o número mínimo de nós necessários para armazenar os blocos de dados seja atendido. Isso significa que, para um esquema EC de 4+2, é necessário haver no mínimo 6 nós disponíveis para receber os dados.
Consistência de metadados
No StorageGRID, os metadados geralmente são armazenados com três réplicas por local para garantir consistência e disponibilidade. Essa redundância ajuda a manter a integridade e a acessibilidade dos dados mesmo em caso de falha.
A consistência padrão é definida em um nível amplo de grade. Os usuários podem alterar a consistência no nível do balde a qualquer momento.
As opções de consistência de bucket disponíveis no StorageGRID são:
-
Todos: Fornece o mais alto nível de consistência. Todos os nós na grade recebem os dados imediatamente, ou a solicitação falhará.
-
Forte-global:
-
Legado Global Robusto: Garante consistência de leitura após gravação para todas as solicitações do cliente em todos os sites.
-
Este é o comportamento padrão para todos os sistemas atualizados da versão 11.9 ou anterior para a versão 12.0 sem a alteração manual para o novo Quorum Strong Global.
-
-
Quorum Strong-global: Garante consistência de leitura após gravação para todas as solicitações de clientes em todos os sites. Oferece consistência para vários nós ou até mesmo uma falha de site se o quorum de réplica de metadados for alcançável.
-
Este é o comportamento padrão para todos os sistemas recém-instalados na versão 12.0 ou superior.
-
A consistência do QUORUM é definida como um quorum de réplicas de metadados do nó de armazenamento, onde cada site tem 3 réplicas de metadados. Pode ser calculado da seguinte forma: 1+((N*3)/2) onde N é o número total de sites
-
Por exemplo, um mínimo de 5 réplicas devem ser feitas a partir de uma grade de 3 sites, com um máximo de 3 réplicas dentro de um site.
-
-
-
* Strong-site*: Garante consistência de leitura-após-gravação para todas as solicitações de clientes dentro de um site.
-
Read-after-novo-write (padrão): Fornece consistência de leitura-após-gravação para novos objetos e consistência para atualizações de objetos. Oferece alta disponibilidade e garantias de proteção de dados. Recomendado para a maioria dos casos.
-
Disponível: Fornece consistência eventual para novos objetos e atualizações de objetos. Para buckets do S3, use somente conforme necessário (por exemplo, para um bucket que contém valores de log raramente lidos, ou para operações HEAD ou GET em chaves que não existem). Não compatível com buckets do FabricPool S3.
Consistência de dados do objeto
Embora os metadados sejam replicados automaticamente dentro e entre locais, cabe a você decidir sobre a disposição do storage de objetos. Os dados de objetos podem ser armazenados em réplicas dentro e entre sites, codificados para apagamento dentro ou entre sites, ou uma combinação ou réplicas e esquemas de armazenamento codificados para apagamento. As regras de ILM podem se aplicar a todos os objetos ou ser filtradas para se aplicar apenas a determinados objetos, buckets ou locatários. As regras do ILM definem como os objetos são armazenados, réplicas e/ou codificados para apagamento, quanto tempo os objetos são armazenados nesses locais, se o número de réplicas ou esquema de codificação de apagamento deve mudar ou os locais devem mudar com o tempo.
Cada regra de ILM será configurada com um dos três comportamentos de ingestão para proteger objetos: Commit duplo, balanceado ou rigoroso.
A opção de confirmação dupla criará duas cópias em quaisquer dois nós de armazenamento diferentes na grade imediatamente e retornará a solicitação como bem-sucedida ao cliente. A seleção do nó será tentada dentro do site da solicitação, mas poderá usar nós de outro site em algumas circunstâncias. O objeto é adicionado à fila ILM para ser avaliado e posicionado de acordo com as regras do ILM.
A opção balanceada avalia o objeto em relação à política ILM imediatamente e o coloca de forma síncrona antes de retornar a solicitação como bem-sucedida ao cliente. Caso a regra ILM não possa ser atendida imediatamente devido a uma interrupção ou armazenamento inadequado para atender aos requisitos de alocação, o protocolo de confirmação dupla será utilizado em seu lugar. Assim que o problema for resolvido, o ILM posicionará automaticamente o objeto com base na regra definida.
A opção estrita avalia o objeto em relação à política ILM imediatamente e o coloca de forma síncrona antes de retornar a solicitação como bem-sucedida ao cliente. Se a regra ILM não puder ser atendida imediatamente devido a uma interrupção ou armazenamento inadequado para atender aos requisitos de posicionamento, a solicitação falhará e o cliente precisará tentar novamente.
Balanceamento de carga
StorageGRID pode ser implantado com acesso de cliente através de nós de gateway integrado, um balanceador de carga externo de 3 a de terceiros, round robin DNS ou diretamente para um nó de storage. Vários nós de gateway podem ser implantados em um local e configurados em grupos de alta disponibilidade, fornecendo failover automatizado e failback no caso de uma interrupção do nó de gateway. Você pode combinar métodos de balanceamento de carga em uma solução para fornecer um único ponto de acesso para todos os sites em uma solução.
Por padrão, os nós de gateway irão balancear a carga entre os nós de armazenamento no site onde o nó de gateway reside. O StorageGRID pode ser configurado para permitir que os nós de gateway equilibrem a carga usando nós de vários locais. Essa configuração adicionaria a latência entre esses sites à latência de resposta das solicitações do cliente. Essa configuração só deve ser feita se a latência total for aceitável para os clientes.
Garantir um RTO (tempo de resposta) igual a zero pode ser alcançado com uma combinação de balanceamento de carga local e global. Garantir o acesso ininterrupto do cliente requer balanceamento de carga das solicitações do cliente. Uma solução StorageGRID pode conter vários nós de gateway e grupos de alta disponibilidade em cada local. Para garantir acesso ininterrupto aos clientes em qualquer local, mesmo em caso de falha de um dos locais, você deve configurar uma solução externa de balanceamento de carga em conjunto com os nós do StorageGRID Gateway. Configure grupos de alta disponibilidade para os nós de gateway, que gerenciam a carga em cada site, e utilize o balanceador de carga externo para distribuir a carga entre os grupos de alta disponibilidade. O balanceador de carga externo deve ser configurado para realizar uma verificação de integridade, garantindo que as solicitações sejam enviadas apenas para sites operacionais. Para obter mais informações sobre balanceamento de carga com StorageGRID, consulte o seguinte: "Relatório técnico do balanceador de carga StorageGRID".
Requisitos para RPO Zero com StorageGRID
Para alcançar o objetivo do ponto de restauração (RPO) zero em um sistema de storage de objetos, é crucial que, no momento da falha:
-
Os metadados e o conteúdo do objeto estão em sincronia e são considerados consistentes
-
O conteúdo do objeto permanece acessível apesar da falha.
Para uma implantação em vários sites, o Quorum Strong Global é o modelo de consistência preferido para garantir que os metadados sejam sincronizados em todos os sites, o que o torna essencial para atender ao requisito de RPO zero.
Os objetos no sistema de armazenamento são armazenados com base em regras de Gerenciamento do Ciclo de Vida da Informação (ILM, na sigla em inglês), que ditam como e onde os dados são armazenados ao longo de seu ciclo de vida. Para replicação síncrona, pode-se optar entre execução estrita ou execução balanceada.
-
A execução estrita dessas regras ILM é necessária para RPO zero, pois garante que os objetos sejam colocados nos locais definidos sem qualquer atraso ou retorno, mantendo a disponibilidade e a consistência dos dados.
-
O comportamento de ingestão de equilíbrio de ILM da StorageGRID fornece um equilíbrio entre alta disponibilidade e resiliência, permitindo que os usuários continuem ingerindo dados mesmo em caso de falha do site.
Implantações síncronas em vários locais
Soluções multisite: O StorageGRID permite que você replique objetos em vários sites dentro da grade de forma síncrona. Ao configurar regras de Gerenciamento do Ciclo de Vida da Informação (ILM) com comportamento equilibrado ou rigoroso, os objetos são colocados imediatamente nos locais especificados. Configurar o nível de consistência do bucket para Quorum Strong Global também garantirá a replicação síncrona de metadados. O StorageGRID usa um único namespace global, armazenando locais de posicionamento de objetos como metadados, para que cada nó saiba onde todas as cópias ou partes codificadas para eliminação estão localizadas. Se um objeto não puder ser recuperado do site onde a solicitação foi feita, ele será recuperado automaticamente de um site remoto sem a necessidade de procedimentos de failover.
Uma vez que a falha é resolvida, não são necessários esforços de failback manual. O desempenho da replicação depende do local com a taxa de transferência de rede mais baixa, a latência mais alta e o desempenho mais baixo. O desempenho de um site é baseado no número de nós, contagem e velocidade de núcleos da CPU, memória, quantidade de unidades e tipos de unidades.
Soluções de várias grades: a StorageGRID pode replicar locatários, usuários e buckets entre vários sistemas StorageGRID usando replicação entre grades (CGR). O CGR pode estender dados selecionados para mais de 16 locais, aumentar a capacidade utilizável do seu armazenamento de objetos e fornecer recuperação de desastres. A replicação de buckets com CGR inclui objetos, versões de objetos e metadados e pode ser bidirecional ou unidirecional. O objetivo do ponto de restauração (RPO) depende do desempenho de cada sistema StorageGRID e das conexões de rede entre eles.
Resumo:
-
A replicação intra-grade inclui replicação síncrona e assíncrona, configurável usando o comportamento de ingestão de ILM e o controle de consistência de metadados.
-
A replicação inter-grid é assíncrona somente.
Uma implantação de Multi-site de Grade única
Nos cenários a seguir, as soluções StorageGRID são configuradas com um balanceador de carga externo opcional, que gerencia as solicitações para os grupos de alta disponibilidade do balanceador de carga integrado. Isso resultará em um RTO de zero, além de um RPO de zero. O ILM está configurado com proteção de ingestão balanceada para posicionamento síncrono. Cada bucket é configurado com a versão Quorum do modelo de consistência global forte para grids de 3 ou mais sites e com a versão Legacy do modelo de consistência global forte para 2 sites.
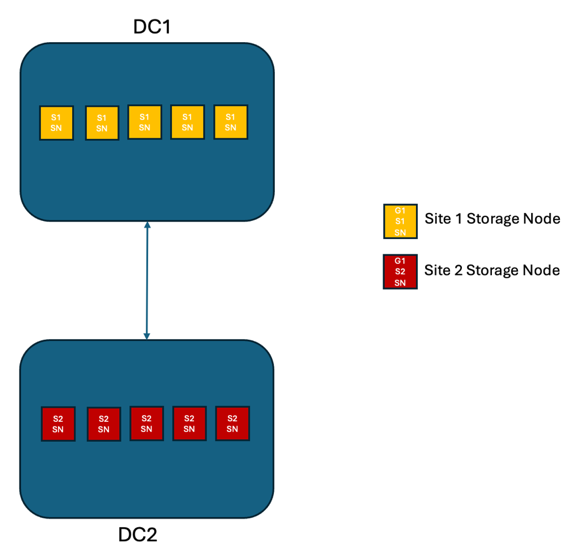
Cenário 1:
Em uma solução StorageGRID com dois sites, existem pelo menos duas réplicas de cada objeto e seis réplicas de todos os metadados. Após a recuperação da falha, as atualizações da interrupção serão sincronizadas automaticamente com o site/nós recuperados. Com apenas 2 sites, é improvável que se alcance um RPO zero em cenários de falha que ultrapassem a perda total de um dos sites.
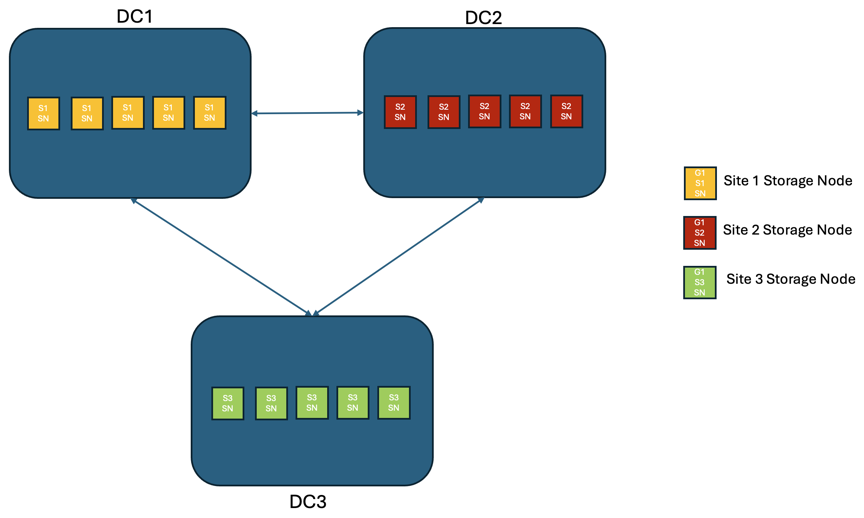
Cenário 2:
Em uma solução StorageGRID com três ou mais sites, existem pelo menos 3 réplicas ou 3 blocos EC de cada objeto e 9 réplicas de todos os metadados. Após a recuperação da falha, as atualizações da interrupção serão sincronizadas automaticamente com o site/nós recuperados. Com três ou mais locais, é possível atingir um RPO zero.
Cenários de falha em vários locais
| Falha | Resultado em 2 locais + Legado Forte Global | Resultado em 3 ou mais locais + Quorum Strong Global |
|---|---|---|
Falha da unidade de nó único |
Cada dispositivo usa vários grupos de discos e pode sustentar uma falha de pelo menos 1 unidade por grupo sem interrupção ou perda de dados. |
Cada dispositivo usa vários grupos de discos e pode sustentar uma falha de pelo menos 1 unidade por grupo sem interrupção ou perda de dados. |
Falha de nó único em um local |
Nenhuma interrupção das operações ou perda de dados. |
Nenhuma interrupção das operações ou perda de dados. |
Falha de vários nós em um local |
Interrupção das operações do cliente direcionadas para este site, mas sem perda de dados. As operações direcionadas para o outro site permanecem ininterruptas e sem perda de dados. |
As operações são direcionadas a todos os outros sites e permanecem ininterruptas e sem perda de dados. |
Falha de nó único em vários locais |
Sem interrupção ou perda de dados se:
Operações interrompidas e risco de perda de dados se:
|
Sem interrupção ou perda de dados se:
Operações interrompidas e risco de perda de dados se:
|
Falha única de local |
Algumas operações do cliente serão interrompidas até que a falha seja resolvida. As operações GET e HEAD continuarão sem interrupção. Reduza a consistência do bucket para leitura após nova gravação ou um nível inferior para continuar as operações sem interrupção nesse estado de falha. |
Nenhuma interrupção das operações ou perda de dados. |
Um único local e falhas de nó único |
Algumas operações do cliente serão interrompidas até que a falha seja resolvida. As operações da HEAD continuarão sem interrupção. As operações GET continuarão sem interrupção se existir uma cópia replicada ou blocos EC suficientes. Reduza a consistência do bucket para leitura após nova gravação ou um nível inferior para continuar as operações sem interrupção nesse estado de falha. |
Sem interrupção das operações ou perda de dados. Possível perda de dados dependendo do número de cópias replicadas. A codificação de apagamento local pode prevenir a perda de dados. |
Um único local mais um nó de cada local restante |
Existem apenas dois locais. Veja: Site único mais um nó único. |
As operações serão interrompidas se o quórum de réplicas de metadados não puder ser atingido. Reduza a consistência do bucket para leitura após nova gravação ou um nível inferior para continuar as operações sem interrupção nesse estado de falha. Possível perda de dados em caso de falha permanente, dependendo do número de cópias replicadas. A codificação de apagamento local pode prevenir a perda de dados. |
Falha em vários locais |
Não restam locais operacionais. Os dados serão perdidos se pelo menos um dos sites não puder ser recuperado em sua totalidade. |
As operações serão interrompidas se o quórum de réplicas de metadados não puder ser atingido. Reduza a consistência do bucket para leitura após nova gravação ou um nível inferior para continuar as operações sem interrupção nesse estado de falha. Possível perda de dados em caso de falha permanente se não restarem blocos codificados de apagamento suficientes. A codificação de apagamento local ou cópias replicadas podem evitar a perda de dados. |
Isolamento de rede de um site |
As operações do cliente serão interrompidas até que a falha seja resolvida. Reduza a consistência do bucket para leitura após nova gravação ou um nível inferior para continuar as operações sem interrupção nesse estado de falha. Sem perda de dados |
As operações serão interrompidas no local isolado, mas não haverá perda de dados. Reduza a consistência do bucket para leitura após nova gravação ou um nível inferior para continuar as operações sem interrupção nesse estado de falha. Não houve interrupção nas operações nos locais restantes nem perda de dados. |
Uma implantação multi-grade em vários locais
Para adicionar uma camada extra de redundância, este cenário empregará dois clusters StorageGRID e usará replicação entre grades para mantê-los sincronizados. Para esta solução, cada cluster StorageGRID terá três sites. Dois sites serão usados para armazenamento de objetos e metadados, enquanto o terceiro site será usado exclusivamente para metadados. Ambos os sistemas serão configurados com uma regra ILM balanceada para armazenar sincronizadamente os objetos usando codificação de eliminação em cada um dos dois sites de dados. Os buckets serão configurados com o modelo de consistência Quorum Strong Global. Cada grade será configurada com replicação bidirecional entre grades em cada bucket. Isso fornece replicação assíncrona entre as regiões. Opcionalmente, um balanceador de carga global pode ser implementado para gerenciar solicitações aos grupos de alta disponibilidade do balanceador de carga integrado de ambos os sistemas StorageGRID para atingir um RPO zero.
A solução usará quatro locais divididos igualmente em duas regiões. A região 1 conterá os 2 locais de armazenamento da grade 1 como a grade primária da região e o local de metadados da grade 2. A região 2 conterá os 2 locais de armazenamento da grade 2 como a grade primária da região e o local de metadados da grade 1. Em cada região, o mesmo local pode abrigar o local de armazenamento da grade primária da região, bem como o local de metadados único da grade de outras regiões. O uso de nós somente de metadados como terceiro local fornecerá a consistência necessária para os metadados e não duplicará o storage de objetos nesse local.
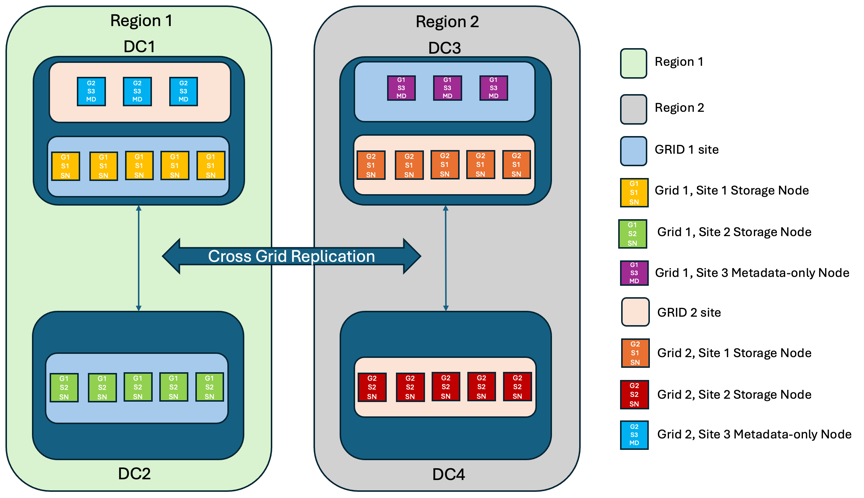
Essa solução com quatro locais separados oferece redundância completa de dois sistemas StorageGRID separados que mantêm um RPO de 0 e usará a replicação síncrona de vários locais e a replicação assíncrona de várias grades. Qualquer local pode falhar, mantendo operações de cliente ininterruptas em ambos os sistemas StorageGRID.
Nessa solução, há quatro cópias codificadas de apagamento de cada objeto e 18 réplicas de todos os metadados. Isso permite vários cenários de falha sem impactos nas operações do cliente. Após a falha, as atualizações de recuperação da falha serão sincronizadas automaticamente com o local/nós com falha.
Cenários de falha multisite e de várias grades
| Falha | Resultado |
|---|---|
Falha da unidade de nó único |
Cada dispositivo usa vários grupos de discos e pode sustentar uma falha de pelo menos 1 unidade por grupo sem interrupção ou perda de dados. |
Falha de nó único em um local em uma grade |
Nenhuma interrupção das operações ou perda de dados. |
Falha de nó único em um local em cada grade |
Nenhuma interrupção das operações ou perda de dados. |
Falha de vários nós em um local em uma grade |
Nenhuma interrupção das operações ou perda de dados. |
Falha de vários nós em um local em cada grade |
Nenhuma interrupção das operações ou perda de dados. |
Falha de nó único em vários locais em uma grade |
Nenhuma interrupção das operações ou perda de dados. |
Falha de nó único em vários locais em cada grade |
Nenhuma interrupção das operações ou perda de dados. |
Falha de um único local em uma grade |
Nenhuma interrupção das operações ou perda de dados. |
Falha de um único local em cada grade |
Nenhuma interrupção das operações ou perda de dados. |
Um único local e falhas de nó único em uma grade |
Nenhuma interrupção das operações ou perda de dados. |
Um único local mais um nó de cada local restante em uma única grade |
Nenhuma interrupção das operações ou perda de dados. |
Falha de local único |
Nenhuma interrupção das operações ou perda de dados. |
Falha de localização única em cada grade DC1 e DC3 |
As operações serão interrompidas até que a falha seja resolvida ou a consistência do balde seja abaixada; cada grade perdeu 2 locais Todos os dados ainda existem em 2 locais |
Falha de localização única em cada grade DC1 e DC4 ou DC2 e DC3 |
Nenhuma interrupção das operações ou perda de dados. |
Falha de localização única em cada grade DC2 e DC4 |
Nenhuma interrupção das operações ou perda de dados. |
Isolamento de rede de um site |
As operações serão interrompidas para o local isolado, mas nenhum dado será perdido Sem interrupção das operações nos locais restantes ou perda de dados. |
Conclusão
Alcançar o objetivo de ponto de restauração (RPO) zero com o StorageGRID é uma meta essencial de garantir a durabilidade e a disponibilidade dos dados em caso de falhas no local. Ao aproveitar as estratégias robustas de replicação do StorageGRID, incluindo replicação síncrona em vários locais e replicação assíncrona em várias grades, as organizações podem manter operações ininterruptas dos clientes e garantir a consistência dos dados em vários locais. A implementação de políticas de Gerenciamento do ciclo de vida das informações (ILM) e o uso de nós somente metadados aumentam ainda mais a resiliência e o desempenho do sistema. Com o StorageGRID, as empresas podem gerenciar seus dados com confiança, sabendo que eles permanecem acessíveis e consistentes mesmo diante de cenários complexos de falhas. Essa abordagem abrangente para gerenciamento e replicação de dados ressalta a importância do Planejamento e execução meticulosos para alcançar RPO zero e proteger informações valiosas.